GTIC 2018 | 英伟达Simon See:揭秘增加AI芯片能效的两大法宝
看点:随着AI行业应用大幅铺开,各类新兴AI芯片也不断涌出。


3月9日,由智东西主办,极果和AWE联合举办的中国首场AI芯片峰会在上海浦东成功举办。本次大会共吸引近万名观众参加,到场人数比预计翻了3倍。即使是下午场,依然爆满,有的观众宁愿站着也要听完全场。在大会现场,近40位人工智能及AI芯片业界翘楚共聚一堂,系统地探讨了AI芯片在2018年的技术前景和产业趋势。

在上午场的演讲中,芯片巨头英伟达AI技术中心亚太首席技术官Simon See博士发表了主题为《端到端的AI计算》的演讲,深入探讨了深度学习在越来越多的行业中落地应用的同时,数据量也随之增加,由此对于AI芯片的打造者来说带来了不少新挑战;此外,Simon See博士还详细解读了两种压缩神经网络、增加芯片效率的方法:降低计算精度与剪枝网络(Purne)。

以下为Simon See博士演讲的要点精析。

AI行业应用大幅铺开,催生各类新兴AI芯片
Simon See博士首先介绍道,从2012年的ImageNet比赛开始,深度神经网络开始逐渐走进人们的的视线当中,并从此之后一直不断发展,以图像分类为首的深度学习应用准确度越来越高、性能越来越强、应用领域也越来越广。

基于这些技术,又逐渐衍生出来基于图像的物体检测、场景检测、风格检测等不同能力,并产生出智慧城市、智能医疗、安防监控等不同行业应用。
由于AI的广泛铺开,也催生了目前市场上一大批新兴AI芯片创业公司的出现。PPT里的大多是国外代表公司,中国也差不多有几十家公司在研发新型AI芯片。

深度神经网络日趋复杂,对芯片要求增加
那么为什么会需要这种芯片呢?第一我们需要看到算法。刚刚魏老师也说过,这个算法一直在改变,无论是CNN、DNN、GANs,还有其他Deep Q-Learning,尤其是用在AlphaGo这方面。
这些种种AI芯片兴起的另一个原因,则是AI对于算力要求的不断提升。在2014年的时候,10层神经网络的计算就需要30多个GPU;而AlphaGo的第一个版本(不是最新那个AlphaZero),在训练时则需要50个GPU训练超过三个星期才能做到。
而在这期间,CNN、RNN、GANs、Deep Q-Learning等算法不断变得复杂,更是对深度学习计算硬件提出了新挑战。与2015年相比,翻译神经网络的复杂度提高了10倍;与2014年相比,语音神经网络的复杂度提高了30倍;而与2012年相比,图像深度神经网络的复杂度则提高了350倍。
除了深度神经网络日趋复杂之外,数据量也在不断增加。举个例子,一个采集225×225图像、采用ResNet-50网络的无人驾驶车的摄像头需要230Gops/30fps的计算量,需要运行77.2亿次计算。而一台无人车需要12-24个摄像头,其计算量以指数级增加。

以上种种原因,使得AI对于硬件计算的要求越来越高。不过如果我们仔细研究神经网络,就会发现深度学习中的基本处理是最简单的矩阵运算,如果你可以把他们全部都放在一起的,你就可以高度并行化地计算。而最早由图像处理起家的英伟达,其GPU芯片设计本就是为了矩阵运算而生的,随后英伟达又在GPU中加入了深度学习相关加速。

神经网络压缩的两大发展方向
神经网络的压缩与简化则是一个学术界与工程界都在研究讨论的重要问题。目前的深度神经网络普遍较大,无论是在云端还是在终端,都会影响网络速度,增大功耗。
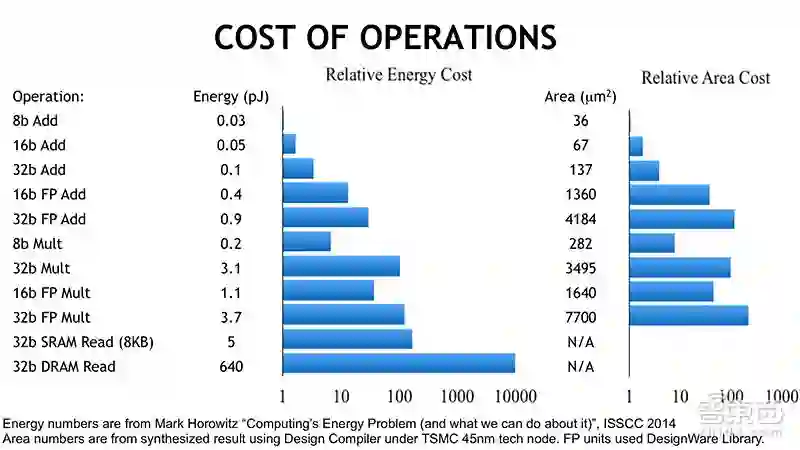
在演讲中,Simon See博士提到了优化AI芯片效率的这两大方向:一个是降低计算精度。图中不同精度的数值的计算功耗,可以看到精度越高、功耗越大。为此,英伟达推出TensorRT,它是一款可编程推理加速器,能加速现有和未来的网络架构,包含一个为优化在生产环境中部署的深度学习模型而创建的库,可获取经过训练的神经网络(32位或16位的数字),并通过降低精度来优化网络运算。
此外,还可以通过网络来进行网络剪枝(Purne),先构造好整个算法网络,然后再尝试消除多余的节点,压缩网络大小。

结语:从云到端、从硬到软
在演讲中,Simon See博士对于AI芯片保持着十分积极的态度,他认为,从交通到健康,越来越多的行业开始拥抱AI;而随着数据量的激增,AI芯片也变得越来越重要。
不过,由于AI芯片仍属于一个技术早期的前沿科技产品,在有了芯片硬件之后,配套的软件生态(如编译器器、模拟器、开发者套件等)也需要配合跟上,打造从云到端、从硬到软的AI环境。
在公众号回复“GTIC”,获取清华大学魏少军、英伟达Simon See、深鉴科技姚颂、腾讯叮当陈谦、宇视姚华、深思考杨志明的演讲PPT下载方式!更多嘉宾ppt将陆续对外公布!





