多特征:实体识别不是一个特别复杂的任务,不需要太深入的模型,那么就是加特征,特征越多效果越好,所以字特征、词特征、词性特征、句法特征、KG表征等等的就一个个加吧,甚至有些中文 NER 任务里还加入了拼音特征、笔画特征。。?心有多大,特征就有多多
多任务:很多时候做 NER 的目的并不仅是为了 NER,而是服务于一个更大的目标,比如信息抽取、问答系统等等的,如果把整个大任务做一个端到端的模型,就需要做成一个多任务模型,把 NER 作为其中一个子任务;另外,如果单纯为了 NER,本身也可以做成多任务,比如实体类型多的时候,单独用一个任务来识别实体,另一个用来判断实体类型
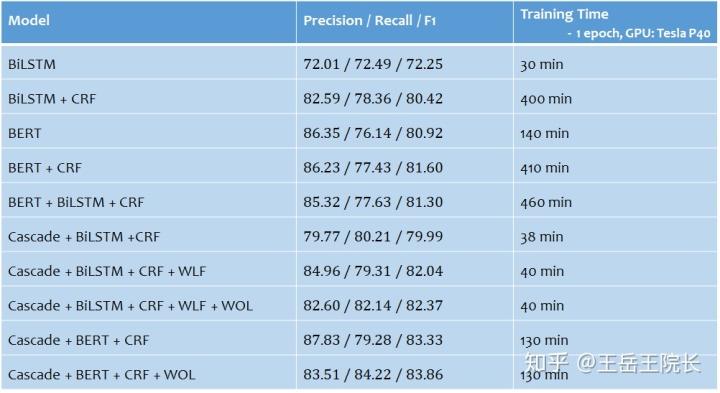
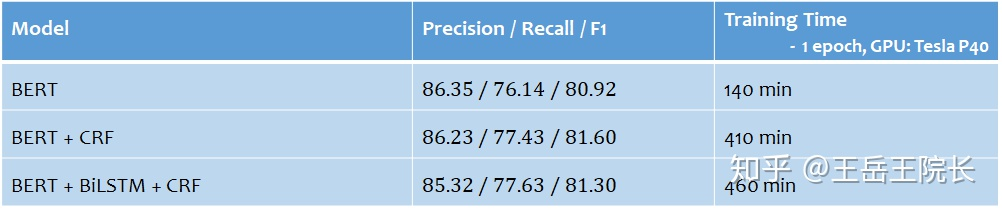
用纯 HMM 或者 CRF 做 NER 的话就不讲了,比较古老了。从 LSTM+CRF 开始讲起,应该是2015年被提出的模型[1],模型架构在今天来看非常简单,直接上图
BI-LSTM 即 Bi-directional LSTM,也就是有两个 LSTM cell,一个从左往右跑得到第一层表征向量 l,一个从右往左跑得到第二层向量 r,然后两层向量加一起得到第三层向量 c
如果不使用CRF的话,这里就可以直接接一层全连接与softmax,输出结果了;如果用CRF的话,需要把 c 输入到 CRF 层中,经过 CRF 一通专业缜密的计算,它来决定最终的结果
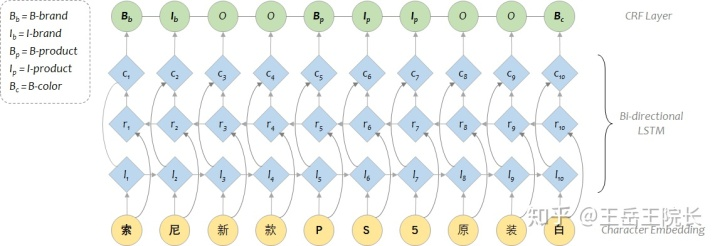
这里说一下用于表示序列标注结果的 BIO 标记法。序列标注里标记法有很多,最主要的还是 BIO 与 BIOES 这两种。B 就是标记某个实体词的开始,I 表示某个实体词的中间,E 表示某个实体词的结束,S 表示这个实体词仅包含当前这一个字。区别很简单,看图就懂。一般实验效果上差别不大,有些时候用 BIOES 可能会有一内内的优势
另外,如果在某些场景下不考虑实体类别(比如问答系统),那就直接完事了,但是很多场景下需要同时考虑实体类别(比如事件抽取中需要抽取主体客体地点机构等等),那么就需要扩展 BIO 的 tag 列表,给每个“实体类型”都分配一个 B 与 I 的标签,例如用“B-brand”来代表“实体词的开始,且实体类型为品牌”。当实体类别过多时,BIOES 的标签列表规模可能就爆炸了
「基于 Tensorflow 来实现 LSTM+CRF 代码也很简单,直接上」
self.inputs_seq = tf.placeholder(tf.int32, [None, None], name="inputs_seq") # B * S self.inputs_seq_len = tf.placeholder(tf.int32, [None], name="inputs_seq_len") # B self.outputs_seq = tf.placeholder(tf.int32, [None, None], name='outputs_seq') # B * S
with tf.variable_scope('embedding_layer'): embedding_matrix = tf.get_variable("embedding_matrix", [vocab_size_char, embedding_dim], dtype=tf.float32) embedded = tf.nn.embedding_lookup(embedding_matrix, self.inputs_seq) # B * S * D
with tf.variable_scope('encoder'): cell_fw = tf.nn.rnn_cell.LSTMCell(hidden_dim) cell_bw = tf.nn.rnn_cell.LSTMCell(hidden_dim) ((rnn_fw_outputs, rnn_bw_outputs), (rnn_fw_final_state, rnn_bw_final_state)) = tf.nn.bidirectional_dynamic_rnn( cell_fw=cell_fw, cell_bw=cell_bw, inputs=embedded, sequence_length=self.inputs_seq_len, dtype=tf.float32 ) rnn_outputs = tf.add(rnn_fw_outputs, rnn_bw_outputs) # B * S * D
with tf.variable_scope('projection'): logits_seq = tf.layers.dense(rnn_outputs, vocab_size_bio) # B * S * V probs_seq = tf.nn.softmax(logits_seq) # B * S * V if not use_crf: preds_seq = tf.argmax(probs_seq, axis=-1, name="preds_seq") # B * S else: log_likelihood, transition_matrix = tf.contrib.crf.crf_log_likelihood(logits_seq, self.outputs_seq, self.inputs_seq_len) preds_seq, crf_scores = tf.contrib.crf.crf_decode(logits_seq, transition_matrix, self.inputs_seq_len)
with tf.variable_scope('loss'): if not use_crf: loss = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits_seq, labels=self.outputs_seq) # B * S masks = tf.sequence_mask(self.inputs_seq_len, dtype=tf.float32) # B * S loss = tf.reduce_sum(loss * masks, axis=-1) / tf.cast(self.inputs_seq_len, tf.float32) # B else: loss = -log_likelihood / tf.cast(self.inputs_seq_len, tf.float32) # B
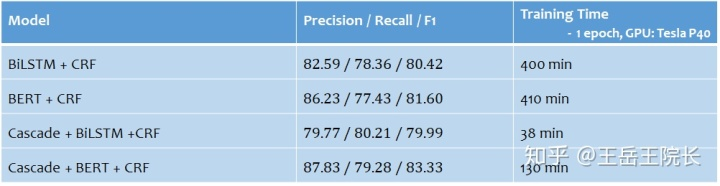
Tensorflow 里调用 CRF 非常方便,主要就 crf_log_likelihood 和 crf_decode 这两个函数,结果和 loss 就都给你算出来了。它要学习的参数也很简单,就是这个 transition_matrix,形状为 V*V,V 是输出端 BIO 的词表大小。但是有一个小小的缺点,就是官方实现的 crf_log_likelihood 里某个未知的角落有个 stack 操作,会悄悄地吃掉很多的内存。如果 V 较大,内存占用量会极高,训练时间极长。比如我的实验里有 500 个实体类别,也就是 V=500*2+1=1001,训练 1epoch 的时间从 30min 暴增到 400min
/usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/gradients_impl.py:112: UserWarning: Converting sparse IndexedSlices to a dense Tensor of unknown shape. This may consume a large amount of memory. "Converting sparse IndexedSlices to a dense Tensor of unknown shape. "
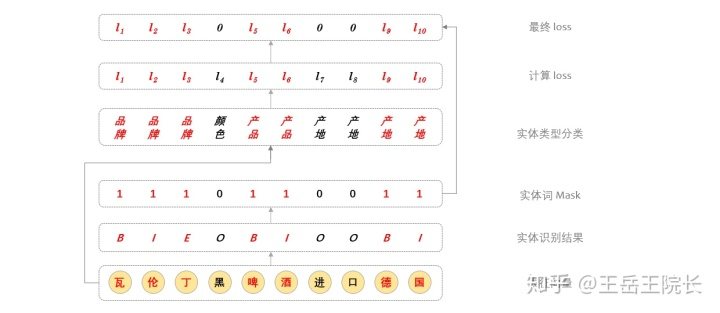
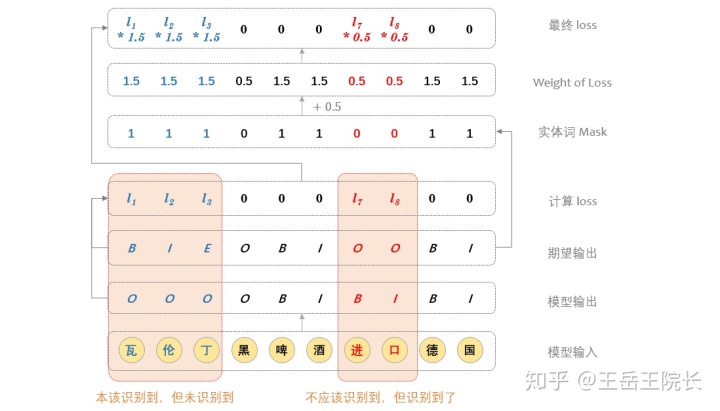
具体实现上这样写:在训练时,每个词,无论是不是实体词,都过一遍全连接,做实体类型分类计算 loss,然后把非实体词对应的 loss 给 mask 掉;在预测时,就取实体最后一个词对应的分类结果,作为实体类型。上图解释
代码不贴了,感兴趣的可以在 git 里看
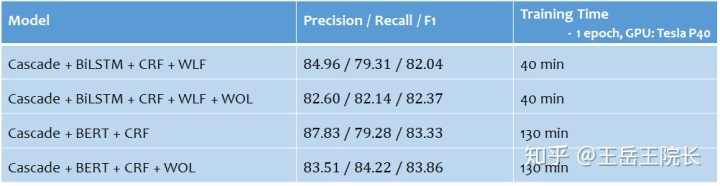
说一下效果。将单任务 NER 改成多任务 NER 之后,基于 LSTM 的模型效果降低了 0.4%,基于 BERT 的模型提高了 2.7%,整体还是提高更明显。另外,由于 BIO 词表得到了缩减,CRF 运行时间以及消耗内存迅速减少,训练速度得到提高
P.S. 另外,既然提到了 NER 中的实体类型标签较多的问题,就提一下之前看过的一篇文章[3]。这篇论文主要就是为了解决实体类型标签过多的问题(成千上万的数量级)。文中的方法是:把标签作为输入,也就是把所有可能的实体类型标签都一个个试一遍,根据输入的标签不同,模型会有不同的实体抽取结果。文章没给代码,我复现了一下,效果并不好,具体表现就是无论输入什么标签,模型都倾向于把所有的实体都抽出来,不管这个实体是不是对应这个实体类型标签。也可能是我复现的有问题,不细讲了,就是顺便提一句,看有没有人遇到了和我一样的情况
❝
Scaling Up Open Tagging from Tens to Thousands: Comprehension Empowered Attribute Value Extraction from Product Title. ACL 2019
❞
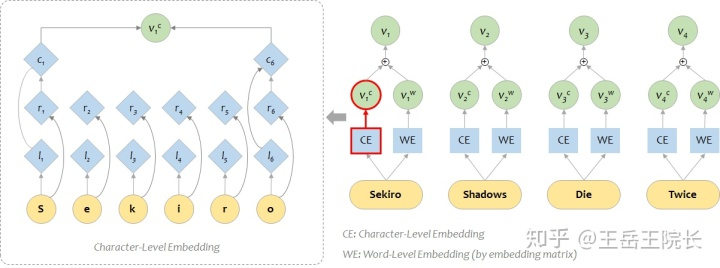
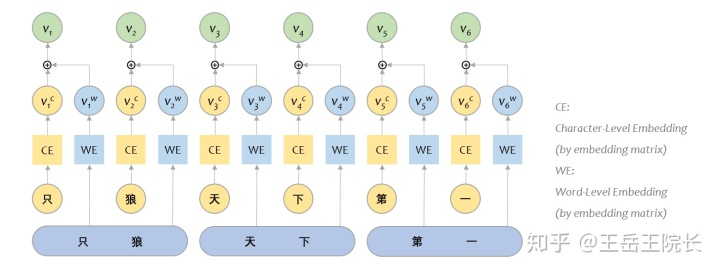
4. Word-Level Feature
中文 NER 和英文 NER 有个比较明显的区别,就是英文 NER 是从单词级别(word level)来做,而中文 NER 一般是字级别(character level)来做。不仅是 NER,很多 NLP 任务也是这样,BERT 也是这样
条件随机域(场)(conditional random fields,简称 CRF,或CRFs),是一种判别式概率模型,是随机场的一种,常用于标注或分析序列资料,如自然语言文字或是生物序列。
如同马尔可夫随机场,条件随机场为具有无向的图模型,图中的顶点代表随机变量,顶点间的连线代表随机变量间的相依关系,在条件随机场中,随机变量 Y 的分布为条件机率,给定的观察值则为随机变量 X。原则上,条件随机场的图模型布局是可以任意给定的,一般常用的布局是链结式的架构,链结式架构不论在训练(training)、推论(inference)、或是解码(decoding)上,都存在效率较高的算法可供演算。