干脆面君,你给我站住!你已经被TensorFlow盯上了

大数据文摘作品,转载要求见文末
作者 | Dat Tran
编译 | 康璐、元元、宁云州
谁动了我最爱的干脆面?!
美好的周五,大数据文摘的办公室居然出现了一起偷窃事件。查看监控后,伟大的文摘菌很快用TensorFlow抓住了凶手,TA就是——一只蠢萌的小浣熊!
来,一起听文摘菌讲讲,这一简易浣熊识别器是如何实现的吧~
文摘菌的这个浣熊识别器到底长啥样呢?先给你看看最终效果~

小偷浣熊独白:文摘菌,我不是故意要吃你的干脆面的 ><
想知道这是如何实现的?在这篇文章中,我会详细说明制作这个浣熊识别器的所有步骤。
为什么要选择浣熊???
不为什么,就是可爱!!!

建立数据集
让我们开始吧!我们需要做的第一件事是建立自己的数据集:
TensorFlow物体识别器API使用TFRecord文件格式,所以我们需要把最终数据集转化成这种文件格式。
有几种方法可以生成TFRecord文件。如果你的数据与PASCAL VOC数据集或者Oxford Pet数据集结构类似,可以利用现成的脚本(参考create_pascal_tf_record.py和create_pet_tf_record.py)。如果你的数据集不是上述的数据结构,你需要自己写一个脚本来生成TFRecords(官网上有此做法的解释)。我就是这么做的。
为了准备API的输入文件,你需要解决两个问题。第一,你需要用jpeg或者png编码的RGB的图片,第二,你需要一个图片的边界框(xmin, ymin, xmax, ymax)并标识物体类别。我的所有图片都只有一个类别,所有对我而言,这很简单。
我从Google Images和Pixabay爬取了200张浣熊的图片(主要是jpeg格式,也有个别是png格式),并且确保了图片在大小、姿势和光线方面有所区别。下面是我收集的一部分图片。

一部分浣熊图片
然后,我用LabelImg手动给图片打上了标签。LabelImg是一个用Python编写和用Qt做图形交互的图像标注工具。它可以支持Python2和3,但是我使用的是Python2和Qt4来从头编译,因为我用不了Python3和Qt5 。LabelImg非常好用,标注可以保存为PASCAL VOC格式的 XML文件。虽然我可以用create_pascal_tf_record.py脚本生成TFRecord文件,但我还是想自己编写脚本。
不知道为什么,在MAC OSX系统上LabelImg无法打开jpeg格式的图片,所以我不得不把他们转化成png格式然后再转化回jpeg格式。实际上,因为API也能支持png格式,我不需要再转化为jpeg格式,但是当时我还不知道这一点。下次我会直接使用png格式图片。
最终,在标识了这些图片后,我写了一个脚本把XML文件转化成csv格式并建立了TFRecord。我使用160张图片来训练(train.records),40张图片来测试(test.records)。
注意:
我发现另外一个很好用的标注工具叫做FIAT (Fast Image Data Annotation Tool)。以后我可能也会试试它。
ImageMagick可以在命令行上进行图片处理,例如图片格式转换。假如你从未使用过,这个软件值得一试。
通常来说,建立数据集是最费事的部分。我用了整整两个小时来分类和标注图片,这还是在我只需要分出一个类的前提下。
确保图片是中型号的(参考google图片来看什么是中型图片)。如果图片太大了,你又没有更改默认的批量大小设置,很可能会在训练时因内存不足而报错。
训练模型
在建立好符合要求的API输入文件后,就可以训练模型了。
在训练中,你需要下述部分:
一个物体识别训练管道。Tensorflow官网上提供配置文件示例。我在训练过程中使用ssd_mobilenet_v1_pets.config作为基础配置。我需要把num_classed参数调整为1,并且为模型检查点、训练和测试文件、标签映射设置路径(PATH_TO_BE_CONFIGURED)。对于其他的配置,比如学习率、样本量等等,我都使用默认设置。
注意:如果你的数据集多样性不足,如比例、姿态等没有太多变化,data_augmentation_option的设置值得选择。完整的选线清单可以在这里找到(参考PREPROCESSING_FUNCTION_MAP)。
数据集(TFRecord文件)和相对应的标签映射。建立标签映射的例子可以在下面看到,因为我只有一个类所以非常简单。

注意:所有id编号都要从1开始,这是很重要的。0是一个占位索引。
(可选)训练前的模型检查点。推荐使用检查点,因为从零开始训练模型可能需要几天才能得到好结果,所以最好能从之前训练过的模型开始。官网上提供了几个模型检查点。在我的识别器中,我根据ssd_mobilenet_v1_coco模型开始训练,因为模型训练速度对我来说比准确度更重要。
开始训练!
训练可以在本地或者在云端完成(AWS,Google云等等)。如果你家有GPU(至少大于2GB),那你可以在本地完成工作,否则我建议使用云端。我这次用的是Google云,基本上是按照说明文档一步步完成的。
对于Google云,你需要定义一个YAML配置文件。官网提供有样例文件,而且我基本上使用了默认配置。
我也建议在训练时就开始评估工作。这样可以监控整个流程,并且通过在本地运行TensorBoard来评估你的工作。
设置TensorBoard路径: tensorboard — logdir=gs://${YOUR_CLOUD_BUCKET}
下面是我的训练和评估工作结果。总体来说,我以批量大小24运行了一个小时,约22000步。在大概40分钟时我已经得到了很好的结果。
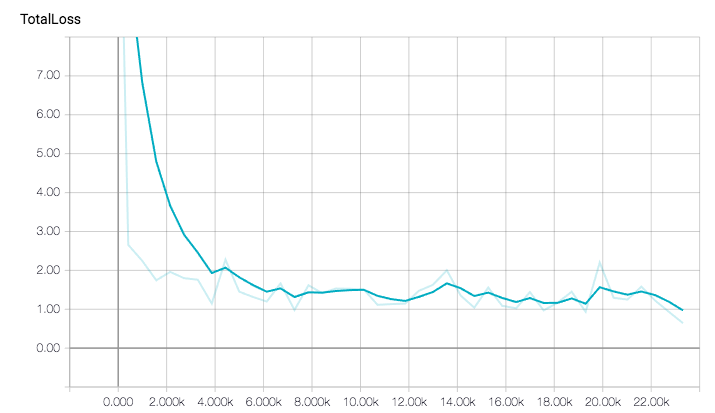
总误差的进展图
因为是从预训练模型开始训练的,总误差下降的很快。
因为我只有一个类,只需要看总体平均准确率就足够了。
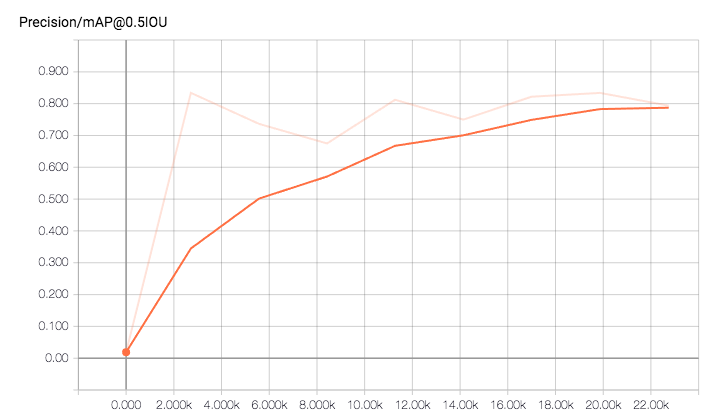
平均准确率在20000步的时候就达到了0.8,这个结果很不错。
下面是在训练模型的过程中,一个图像评估的例子。

框住浣熊的探测框越来越准确。
导出模型
在训练完成之后,我把模型导出到一个文件中(Tensorflow graph proto),便于我用这个模型进行推论。
在我的课题中,我只能从Google云中把模型检查点拷贝到本地,然后用官网提供的脚本来导出模型。
👇戳下方,可观看额外福利视频哦
我把训练后的模型用在了我在youtube找的视频上
看过这段视频后你会发现有一些浣熊被漏掉了,也有一些误判。这是合理的,因为我们只在一个小数据集上训练了模型。如果要建立一个通用且稳定的识别器,(比如你需要它能识别最有名浣熊——银河护卫队里面的火箭浣熊),我们需要的只是更多数据。这也是AI现在的局限性之一。

地球上最有名的浣熊
结论
在本文中,我只使用了一个类,因为我懒得标注更多数据。有很多公司比如CrowdFlower、 CrowdAI和Amazon’s Mechanical Turk均提供标注服务,但是本文还用不到这样的服务。
我用了很短的训练时间就得到了相当不错的结果,这也是由于识别器只需要训练一个类。对于多类别的情况,总平均准确率就不会这么高了,也需要更长的训练时间来获得好的结果。实际上,我也在Udacity提供的带标注的驾驶数据集上训练了识别器。训练一个能识别小汽车、卡车和行人的识别器花了很长时间。很多其他类似的案例中可能需要使用更复杂的模型。我们还要考虑在模型速度和模型准确度之间寻找平衡。
原文链接:https://medium.com/towards-data-science/how-to-train-your-own-object-detector-with-tensorflows-object-detector-api-bec72ecfe1d9
看完了文摘菌的教程,是不是也想亲手抓一只自己的小浣熊呢?如果你不满足只是抓一只干脆面君,那么可以跟我们一起来~~~
稀牛学院最新课程《深度学习与计算机视觉》
浣熊、哈士奇、喵星人
学完这门课程,想抓啥抓啥!
深度学习与计算机视觉
一门课程解决所有困惑
超高性价比,详情见文末
两个月,从理论到实战,从入门到入行
带你搭乘AI学习特快专列


关于转载
如需转载,请在开篇显著位置注明作者和出处(转自:大数据文摘 | bigdatadigest),并在文章结尾放置大数据文摘醒目二维码。无原创标识文章请按照转载要求编辑,可直接转载,转载后请将转载链接发送给我们;有原创标识文章,请发送【文章名称-待授权公众号名称及ID】给我们申请白名单授权。未经许可的转载以及改编者,我们将依法追究其法律责任。联系邮箱:zz@bigdatadigest.cn。
回复“志愿者”加入我们



点击图片阅读
DOTA2中打败Dendi的AI如何炼出?OpenAI公布两周集训细节(含实战视频)







