最新版《机器学习数学基础》发布,417页PDF免费下载

新智元推荐
新智元推荐
来源:专知(ID: Quan_Zhuanzhi)
【新智元导读】《机器学习数学基础》最新版 417 页 pdf 版本已经放出,本书旨在激励人们学习数学概念,包括数学基础知识和使用数学基础知识进行机器学习算法示例两部分,值得收藏学习!
由 Marc Peter Deisenroth,A Aldo Faisal 和 Cheng Soon Ong 撰写的《机器学习数学基础》“Mathematics for Machine Learning” 最新版 417 页 pdf 版本已经放出,作者表示撰写这本书旨在激励人们学习数学概念。
这本书并不打算涵盖前沿的机器学习技术,因为已经有很多书这样做了。相反,作者的目标是通过该书提供阅读其他书籍所需的数学基础。
这本书分为两部分:数学基础知识和使用数学基础知识进行机器学习算法示例。值得初学者收藏和学习!

前言(Foreword)
随着机器学习变得越来越普遍,它的软件包也越来越容易使用。一些低级的技术细节被抽象出来,并对实践者隐藏起来,这是很自然的,也是可取的。然而,这带来了一些风险,即实践者不知道设计决策,因此不知道机器学习算法的局限性。
有兴趣了解机器学习算法背后机制的实践者需要具备如下的先验知识:
编程语言和数据分析工具
大规模计算和相关框架
数学和统计学知识,以及机器学习是如何基于这些知识构建的
在大学里,关于机器学习的入门课程往往会在课程的早期部分涉及到以上这些先验知识。由于历史原因,机器学习的课程倾向于在计算机科学系进行授课。在计算机科学系,学生通常在前两个知识领域受到的训练比较多,但在数学和统计学方面的训练较少。目前的一些机器学习教科书试图加入一到两章的内容来介绍数学背景知识,但是这些介绍要么在书的开头,要么作为附录。本书将机器学习中的数学基础知识放在首位,并且信息相对集中。
为什么要写一本关于机器学习的书?
机器学习建立在数学语言的基础上,用来表达直观上显而易见但却难以形式化的概念。一旦正确地形式化,我们就可以使用数学工具来得出我们设计选择的结果。这使我们能够深入了解我们正在解决的任务以及智能的本质。全球数学系学生普遍抱怨的一个问题是,数学所涵盖的主题似乎与实际问题没有太多关联。我们认为机器学习是人们学习数学的一个明显而直接的动机。
作者希望这本书可以成为一本指导机器学习大量数学基础的指南。作者通过直接指出数学概念在基本机器学习问题中的有用性来激发对数学概念的需求。为了使书简短,许多细节和更先进的概念都被省略了。书中介绍了一些基本概念,以及这些概念如何适用于机器学习的大背景,读者可以找到大量的资源进行进一步研究。对于有数学背景的读者,这本书提供了一个简短但精确的机器学习入门介绍。书中只提供四个代表性的经典的机器学习算法示例。作者关注的是模型本身背后的数学概念,目的是阐明它们的抽象美。作者希望所有的读者都能对机器学习的基本问题有更深入的了解,并将机器学习的实际问题与数学模型的基本选择联系起来。
谁是目标受众
随着机器学习在社会中的广泛应用,作者相信每个人都应该对它的基本原理有一些了解。这本书是用学术数学的风格来写的,这使读者能够精确地了解机器学习背后的概念。作者鼓励不熟悉这种简洁的风格的读者坚持阅读下去,并牢记每个主题的目标。作者在整篇文章中都有标记和评论,希望这些评论能对读者提供一些有用的指导。此外,本书假定读者具备高中数学和物理中常用的数学知识。例如,导数和积分,以及二维或三维的几何向量。因此,本书的目标受众包括普通大学生、夜校生和机器学习在线课程的学习者等等。
目录
Part I: 数据基础
Introduction and Motivation
Linear Algebra
Analytic Geometry
Matrix Decompositions
Vector Calculus
Probability and Distribution
Continuous Optimization
Part II: 机器学习问题
When Models Meet Data
Linear Regression
Dimensionality Reduction with Principal Component Analysis
Density Estimation with Gaussian Mixture Models
Classification with Support Vector Machines
简介(Introduction)
本书分为两部分,第一部分是数学基础的讲解,第二部分是将第一部分的数学概念应用于基本的机器学习问题中,从而形成 “机器学习四大支柱”,如下图所示:
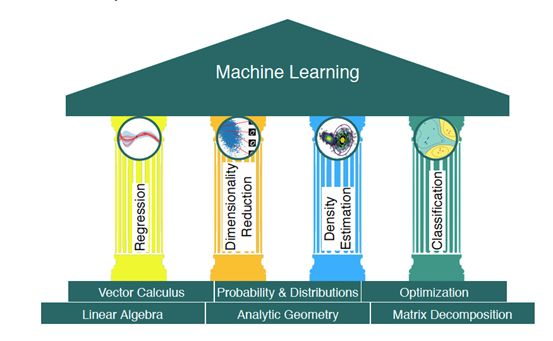
这本书的第一部分描述了关于机器学习系统的三个主要组成部分的数学概念和数学基础:数据、模型和学习。在本书中,作者假设数据已经被适当地转换成适合于阅读的数字表示形式,并被转换成计算机程序。在这本书中,作者认为数据是向量。模型是现实世界的简化版本,它捕获与任务相关的现实世界的各个方面。模型的用户需要理解模型没有捕捉到什么,从而理解模型的局限性。概括起来就是,作者使用领域知识将数据表示为向量。并选择一个合适的模型,要么使用概率方法,要么使用优化方法。采用数值优化的方法,对过去的数据进行学习,目的是它在看不见的数据上表现良好。
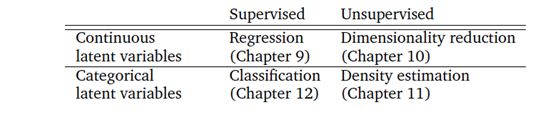
本书第二部分介绍了上图所示的机器学习四大支柱,如下表所示。表中的每一行区分了相关变量是连续的还是非连续的类别的问题。作者解释了如何将本书第一部分介绍的数学概念应用于机器学习算法的设计中。在第 8 章中,作者以数学的方式重述了机器学习的三个组成部分 (数据、模型和学习)。此外,作者还提供了一些建立实验设置的指南,以防止对机器学习系统过于乐观的评估。
此外,作者在第一部分提供了一些练习,这些练习大部分可以用笔和纸来完成。在第二部分中,作者提供了一些编程教程 (jupyter 记事本) 来探索在本书中讨论的机器学习算法的一些特性。
全书配套网站:https://mml-book.com






