上线周期缩短上百倍!NLP流水线系统发布,10分钟搭建检索、问答等复杂系统
伴随着产业智能化升级的浪潮,企业对灵活可定制的智能NLP系统有着广泛需求。例如,保险公司希望通过智能客服平台向客户提供24小时问答服务,同时也想建设企业内搜平台向员工提供精准、高效的搜索服务。然而众多企业自建这些复杂系统所耗费的人力成本和时间成本巨大,成为产业智能化升级的 “拦路虎” 。
为了解决上述难题,PaddleNLP推出NLP流水线系统———PaddleNLP Pipelines,将各个NLP复杂系统的通用模块抽象封装为标准组件,支持开发者通过配置文件对标准组件进行组合,仅需几分钟即可定制化构建智能系统,让解决NLP任务像搭积木一样便捷、灵活、高效。同时,Pipelines中预置了前沿的预训练模型和算法,在研发效率、模型效果和性能方面提供多重保障。
本文将对Pipelines三大特色进行解读,全文约2.7k字,预计阅读时长1分半。
插拔式组件设计,灵活可扩展
企业的NLP系统需求多种多样,例如智能客服、智能检索、文档信息抽取、商品评论观点分析等,虽然这些系统的外在形态千差万别,但是从技术基础设施角度看:
NLP系统都可以抽象为由多个基础组件串接而成的流水线系统;
多个NLP流水线系统可共享使用相同的基础组件。
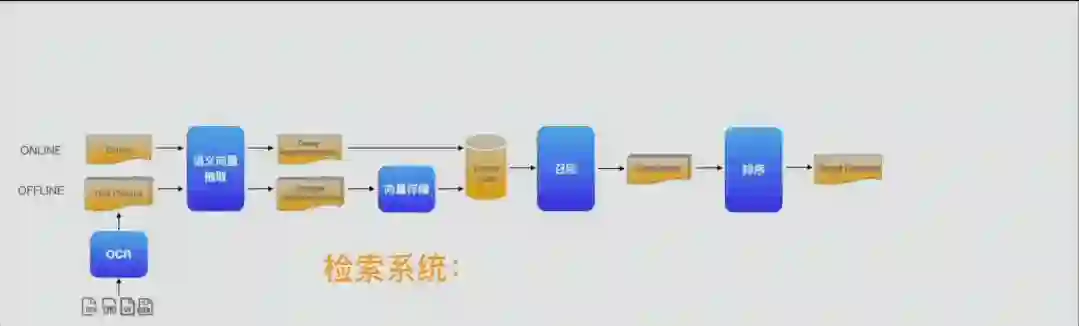
图1:通过增删基础组件实现多个复杂系统的迁移
如上图,举例来说:
语义检索系统可以抽象为文档解析、语义向量抽取、向量存储、召回、排序5个基础组件;
在此基础上,只需串接1个答案定位模型组件即可构成阅读理解式问答系统。
更进一步,在问答流水线的起点和终点分别加入ASR(语音转换文本)和TTS(文本转换语音)2个模型组件即可构成智能语音客服系统。
由以上示例可以看出,面向各种场景的NLP系统本质上都是由一些可复用的基础组件串接而成的流水线系统。基于此,Pipelines提出通过丰富、强大的基础组件灵活、快速地构建NLP全场景智能系统,主要包括以下四类重要组件。
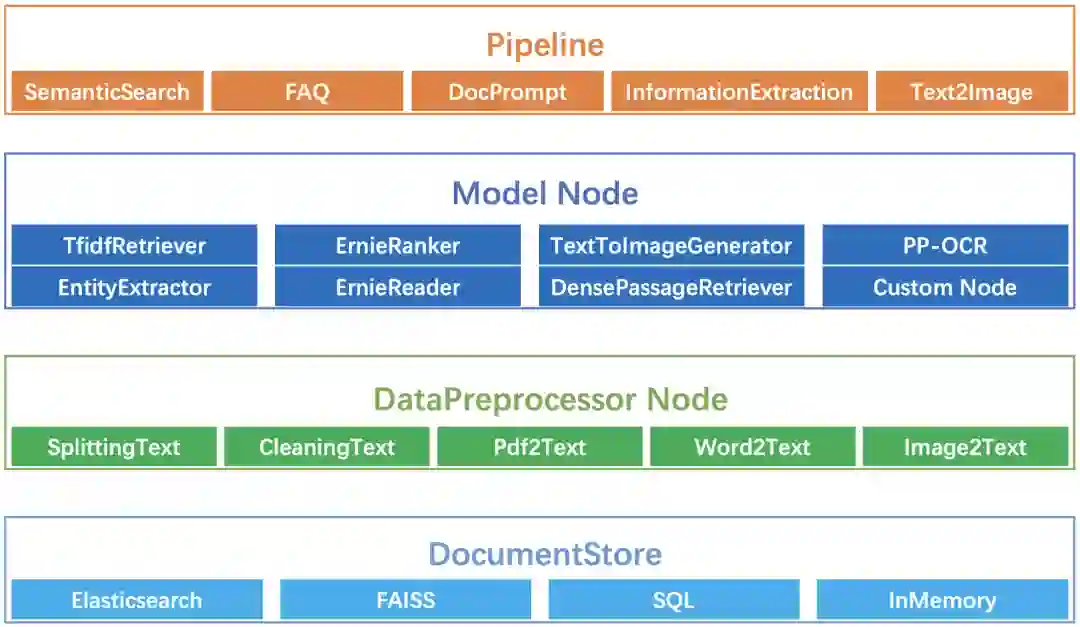
图2:Pipelines基础组件示例
Pipelines 除深度兼容 PaddleNLP中的模型外,还可兼容飞桨生态下任意模型、AI 开放平台算子、其它开源项目如 Elasticsearch 等作为基础组件。用户可通过对基础组件进行扩展来满足个性化需求,从而实现任意复杂系统的灵活定制开发。

挖掘该工具更多的潜力和惊喜,请进传送门(STAR收藏起来,不易走丢~):
https://github.com/PaddlePaddle/PaddleNLP/tree/develop/pipelines
接下来,我们来看Pipelines中内置的各类SOTA模型。
飞桨SOTA模型,支持快速串联
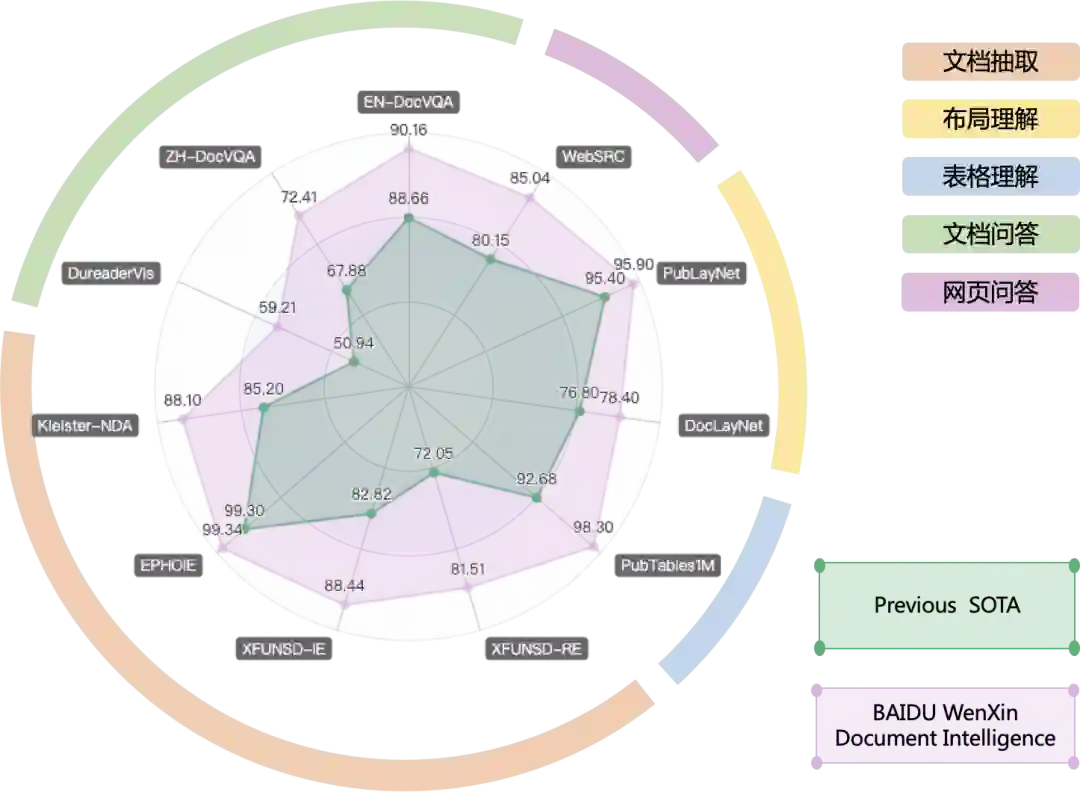
图3:文档智能技术指标
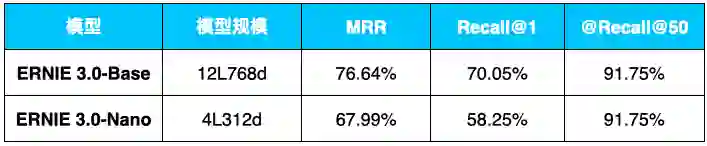
通用信息抽取技术UIE,其多任务统一建模特性大幅降低了模型开发成本和部署的机器成本,基于Prompt的零样本抽取和少样本迁移能力更是惊艳!例如,在金融领域的事件抽取任务上,仅仅标注5条样本,F1值就提升了25个点!
表1:UIE在信息抽取数据集上零样本和小样本效果(F1-score)
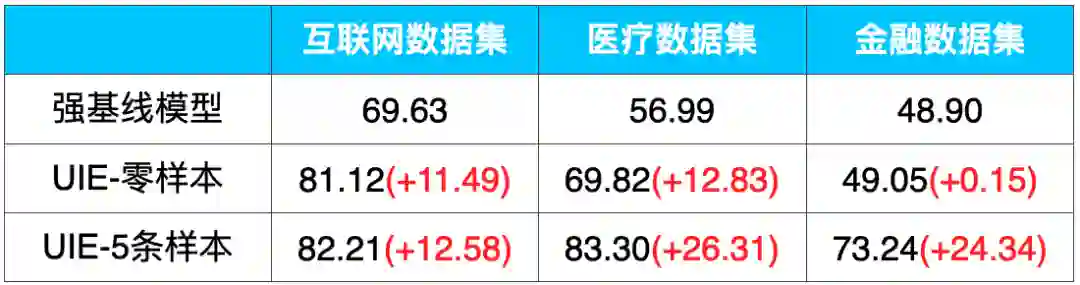

图4:RocketQA 问答技术领先
再来介绍一个今年火遍全网的中文跨模态生成模型文心ERNIE-ViLG,该模型首次通过自回归算法将图像生成和文本生成统一建模,增强模型的跨模态语义对齐能力,显著提升图文生成效果。现在可以通过调用ImageGenerationPipeline很方便得体验文心ERNIE-ViLG的强大能力了!
from
pipelines
import
TextToImagePipeline
from
pipelines.nodes
import
ErnieTextToImageGenerator
erine_image_generator
=
ErnieTextToImageGenerator
(
ak
=
args.api_key,
sk
=
args.secret_key)
pipe
=
TextToImagePipeline
(erine_image_generator)
prediction
=
pipe.
run
(
query
=
args.prompt_text,
params
=
{
"
TextToImageGenerator
"
: {
"
topk
"
: args.topk,
"
style
"
: args.style,
"
resolution
"
: args.size,
"
output_dir
"
: args.output_dir
}
})
除面向特定任务的模型外,Pipelines中还集成了多任务通用的预训练模型——文心ERNIE 3.0轻量级模型,这一系列模型刷新了中文小模型的SOTA成绩。
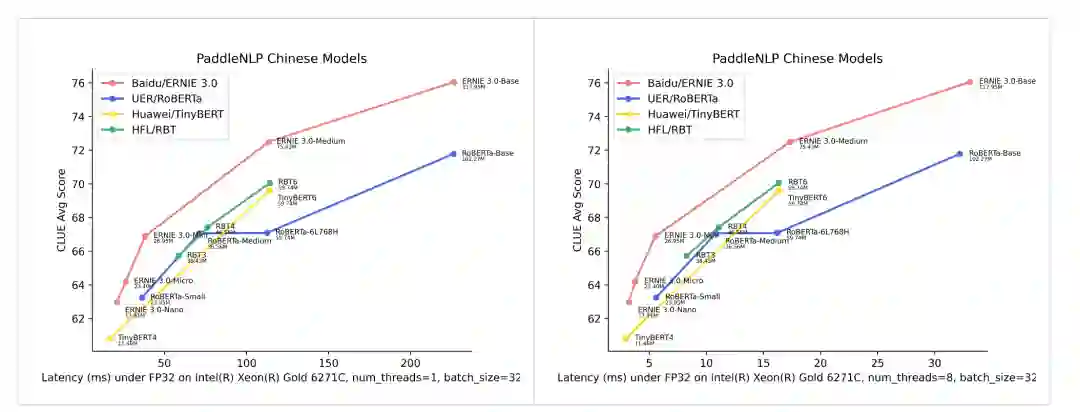
图5:ERNIE3.0 轻量级模型效果 SOTA
除小模型外,Pipelines中也可直接使用PaddleNLP中开源的24层模型ERNIE 1.0-Large-zh-CW,效果优于同等规模的RoBERTa-wwm-ext-large。
表2:ERNIE 1.0-Large-zh-CW和ERNIE 3.0-Xbase-zh效果领先

from pipelines.nodes import DensePassageRetriever
retriever = DensePassageRetriever(
document_store=document_store,
query_embedding_model=“rocketqa-zh-dureader-query-encoder”,
passage_embedding_model=“rocketqa-zh-dureader-query-encoder”,
max_seq_len_query=args.max_seq_len_query,
max_seq_len_passage=args.max_seq_len_passage,
batch_size=args.retriever_batch_size,
use_gpu=use_gpu,
embed_title=False
)
一键部署端到端系统,超低门槛
为了进一步降低开发门槛,提供最优效果,Pipelines针对高频场景内置了产业级端到端系统。目前已开源语义检索、MRC(阅读理解)问答、FAQ问答、跨模态文档问答等多个应用,未来会持续丰富语音问答、舆情分析、文本分类等各类场景。
接下来,一起看看Pipelines内置的端到端系统有多强!下面以检索系统展开。
3.1 端到端全流程

图6:检索系统流水线示意图

图7:检索系统前端Demo
3.2 效果领先速度快
该检索系统基于端到端问答技术RocketQA,该模型结合知识增强的预训练模型ERNIE 3.0和百万量级的人工标注数据集 DuReader训练得到,效果优异。该模型可以在Pipelines一键调用,大大降低问答系统模型建模成本。
表3:Pipelines检索系统精度(数据集:DuReaderretrieval)
性能方面,Pipelines直接集成Elasticsearch、Milvus等高性能ANN(近似最近邻)引擎,支持海量文本高效建库和相似查询。采用ERNIE 3.0轻量化模型,提升语义向量抽取速度,单个Query在CPU上的检索速度从2.2s缩减到了0.4s,内存占比进一步降低,适用于低资源环境。
3.3 低门槛一键部署
用户可以基于Docker采用如下命令默认一键部署端到端语义检索系统。
# 启动GPU容器
docker-compose -f docker-compose-gpu.yml up -d
小编找PaddleNLP内部人士了解到,Pipelines下一步将向以下两个方向扩展,对学术研究和工业应用都非常友好。
预置更丰富的基础组件库
例如支持飞桨语音模型库PaddleSpeech的PP-TTS和PP-ASR各类语音模型串联;支持PaddleNLP通用信息抽取UIE、文本分类等NLP组件直接调用。
预置更多流水线系统
例如预置多模态信息抽取系统、智能语音指令系统等。

入群福利:
获取直播课程链接。
获取PaddleNLP团队整理的10G重磅NLP学习大礼包。
入群方式:
微信扫描下方二维码,关注公众号,填写问卷后进入微信群
-
查看群公告领取福利。

更多精彩直播
注:如果已经通过上一张海报扫码进群,无需重复操作。
PaddleNLP项目地址:
GitHub: https://github.com/PaddlePaddle/PaddleNLP
Gitee: https://gitee.com/paddlepaddle/PaddleNLP

