熬过深宫十几载,深度学习上位这五年

转自:大数据文摘|bigdatadigest
作者 | Thimira Amaratunga
编译 | 宁云州、吴双、张伯楠
【深度学习】这个几年前还鲜为人知的术语,近期迅速蹿红,成为人尽皆知的大IP。不过在火起来之前,这个技术已经发展了十几年。人尽皆知前,深度学习是如何一步一步自我演化并走进公众视野的?
1998年,Yann LeCun 发表Gradient-Based Learning Applied to Document Recognition,至今,深度学习已经发展了十几年了。以大家熟知的CNNs为代表的技术在近几年内取得了跨越式的发展,但理解深度学习的技术细节往往需要深入的数理知识,导致我们对于深度学习的理解一直停留在较浅的程度。本文就将带你回顾深度学习近些年来的里程碑式成果,就算看不懂技术细节,也可以一睹深度学习的前世今生。
2012年-AlexNet
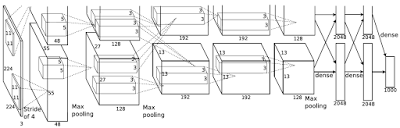
AlexNet的结构图(图片来自于论文:《基于ImageNet图像识别的深度卷积神经网络》)
这篇文章被称为深度学习的开山之作。当然,也有很多人坚称Yann LeCun 1998年发表的Gradient-Based Learning Applied to Document Recognition才是开山之作,即便这样, 这篇文章使得深度学习进入主流科学界的视野也是毋庸置疑的。事实上,有人的地方就有江湖,这种争论与当年牛顿和莱布尼茨争论微积分的发明权一样都无损于我们作为学习者领略这些成果美妙的思想和灿烂的智慧,这篇文章的作者Alex Krizhevsky, Ilya Sutskever, 和 Geoffrey E. Hinton同Yann Lecun都是最杰出的学者。
特点:
在结构上,AlexNet由8层神经网络组成:其中有5层卷积层和3层全连接层(相比较现在的神经网络,这真是太简单了,但即便是这样,它也足以用来分类1000类图片了)。
AlexNet使用ReLU作为非线性函数,而不是此前一直广泛使用的常规tanh函数。
AlexNet还首次提出了使用Dropout Layers(降层)和Data Augmentation (数据增强)来解决过度匹配的问题,对于误差率的降低至关重要。
这篇文章之所名留青史与其在应用方面的优异表现分不开(时间果然是检验真理的唯一标准啊),AlexNet赢得了2012年的ILSVRC(ImageNet大规模视觉识别挑战赛),误差率为15.4%。甩了当时的第二名十条大街(26.2%) 。
论文:《基于ImageNet图像识别的深度卷积神经网络》- Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton
2013年-ZF Net
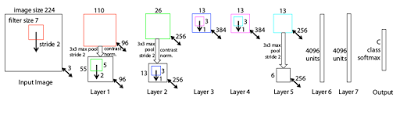
ZF net 结构图(图片来自论文:《卷积网络的可视化与理解》)
学术界的反映其实总要比我们想象地要快得多,在2013年的ILSVRC(ImageNet大规模视觉识别挑战赛)上,就出现了大量的CNN模型,而其中夺得桂冠的就是ZF Net(错误率进一步降低到11.2%),其实ZF Net更像是一个AlexNet的升级版,但它仍然有以下特点:
推出了反卷积网络(又名DeConvNet),一种可查看卷积网络(CNN)内部运作的可视化技术。
激活函数用了ReLu,误差函数用了交叉熵损失(cross-entropy loss),训练使用批量随机梯度下降方法。
大大减少了训练模型使用的图片数量,AlexNet使用了1500万张图片做训练,而ZF Net只用了130万张。
论文:《卷积网络的可视化与理解》- Matthew D. Zeiler, Rob Fergus
2014年-VGG Net
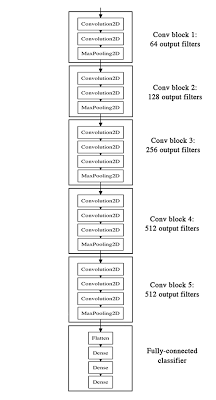
VGG结构图(图片来自Keras的博客:https://blog.keras.io)
看到这里我们已经可以发现深度学习和ILSVRC深深的纠葛,接下来我们要介绍的VGG Net正是ILSVRC 2014“图像识别+定位”组别的获胜者,误差率为7.3%。
VGG Net具有以下特点:
VGG结构在图像识别和定位两个方面都表现出色。
使用了19层网络,3x3的滤波器。 (而不是AlexNet的11x11滤波器和ZF Net的7x7滤波器相比)
提供了可用于分层特征提取的简单深度结构。
利用抖动(scale jittering)作为训练时数据增强的手段。
VGG Net成为里程碑的主要原因除了它在定位和图像识别两方面都表现突出外,还因为它强调了卷积神经网络需要用到深度网络结构才能把图像数据的层次表达出来,为之后深度学习的发展提供了指导。
论文:《用于大规模图像识别的超深度卷积网络》- Karen Simonyan, Andrew Zisserman
2014/2015年-GoogLeNet
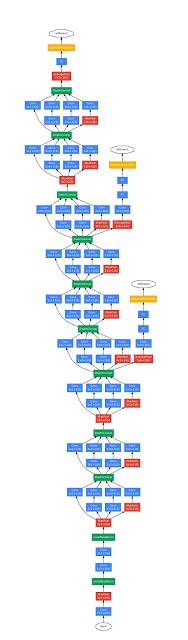
GoogleNet结构图(图片来自于论文:《深入探索卷积》)
读到这里的读者应该已经能把ILSVRC这个大赛当作老朋友了。在2014年的ILSVRC大赛中,我们刚才介绍的VGG Net只是“图像识别+定位”组别的冠军,而GoogLeNet则凭借6.7%的误差率赢得了ILSVRC 2014图像识别的冠军。
它具有以下特点:
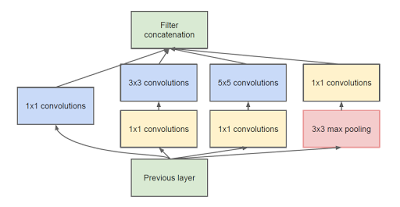
引入了“初始模块”,强调了CNN的层次并不总是必须顺序堆叠的。
初始模块(图片来自论文《深入探索卷积》)
22层深的网络(如果独立计算则总网络超过100层)。
没有使用全连接层,而是以使用平均池化代替,将7x7x1024的输入量转换为1x1x1024的输入量。 这节省了大量的参数。
证明了优化的非顺序结构可能比顺序结构性能更好。
GoogLeNet 的创新主要在于这是第一个真正不通过简单顺序叠加卷积层和池化层来构建的CNN架构之一,为后来CNN在架构上的创新打下了基础。
论文:《深入探索卷积》- Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, Andrew Rabinovich, 谷歌公司,北卡罗来纳大学教堂山分校,密歇根大学安娜堡分校,Magic Leap公司
2015年—微软ResNet

ResNet 结构图(图片来自于论文:《图像识别的深度残差学习》)
ResNet是2015年ILSVRC的获胜者(又是ILSVRC!),它的误差率达到了惊人的3.6%,首次在图像识别的准确率上超越了人类(5%-10%),它拥有以下特点:
真的很深,ResNet 具有152层的“极端深度”(原文作者用Ultra-deep这个词来描述它)的结构。
提出了使用残差模块以减轻过度匹配。
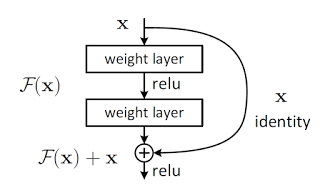
残差模块(图片来自于论文:《图像识别的深度残差学习》)
论文:《图像识别的深度残差学习》- Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun, 微软亚洲研究院
意义:超越人类还不算意义吗?
深度学习只有CNNs(卷积神经网络)吗?
当!然!不!是!现在我们终于能摆脱被ILSVRC支配的恐惧,谈点其他的了,事实上,深度学习的模型还包括:
Deep Boltzmann Machine(深度玻尔兹曼机)
Deep Belief Networks(深度信念网络)
Stacked Autoencoders(栈式自编码算法)
原文链接:https://medium.com/towards-data-science/milestones-of-deep-learning-1aaa9aef5b18




点击下方“阅读原文”下载同声译
↓↓↓



