开源的语音合成系统WORLD介绍以及使用方法

题图:桑德罗·波提切利《维纳斯的诞生》
WORLD是一个基于C语言的开源语音合成系统,语音合成主要包括波形拼接和参数合成两种方法,WORLD是一种基于vocoder的参数合成方法,它相比于STRAIGHT的优势是减少了计算复杂度,并且可以应用于实时的语音合成。由于STRAIGHT不是开源的系统,并且在WORLD论文中已经对比了WORLD相比于STRAIGHT无论是在合成的音频质量上还是合成速度上都处于领先优势,所以这里我不准备介绍STRAIGHT,我们今天主要讲一下WORLD语音合成系统的原理以及使用方法。
WORLD系统如下图所示,包含三个模块,分别是DIO、CheapTrick、PLATINUM,其中DIO的作用是用来估计一段波形的Fundamental Frequency(简称F0),CheapTrick算法是根据波形和F0来计算spectral envelope,PLATINUM算法是基于波形、F0和spectral envelope来计算aperiodic parameter,下面我们来分别看这些参数的计算原理。
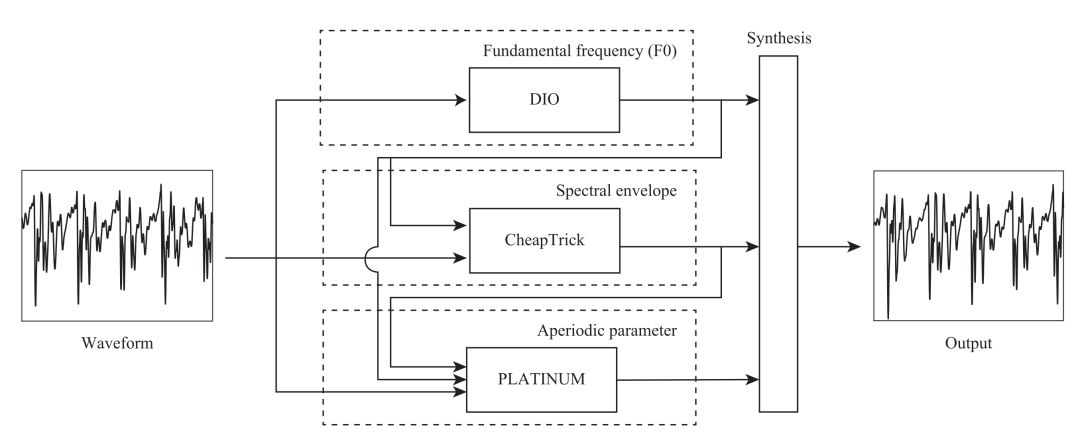
1. F0的计算
F0在维基百科中的定义是:当发声体由于振动而发出声音时,声音一般可以分解为许多单纯的正弦波,所有的自然声音基本都是由许多频率不同的正弦波组成的,其中频率最低的正弦波即为基音,而其他频率较高的正弦波则为泛音,即这些不同正弦波中的最低频率称为基频。F0是一种非常常用的可以表示声音的特征,在WORLD中,F0的计算是基于DIO算法,DIO算法主要包含如下三个步骤:
第一步:使用不同的截止频率的低通滤波器,如果滤波后的信号只包含基频,那么它就是一个正弦波,由于事先我们对F0并不知晓,需要多次试探,所以在这一步中会有很多不同截止频率的滤波器被使用;
第二步:计算每一个滤波后的信号中的候选基频以及可信度,由于只包含基频的信号应该是一个正弦波,因此如下图所示,四个区间的跨度应该基本相等,我们可以计算四个跨度的平均值,用这个值的倒数来表示候选基频。同时,计算这四个跨度的标准差来作为衡量基频可信度的指标,标准差越大,说明跨度长短差异较大,那么取此频率作为基频的可信度就较低。
第三步:选取可信度最高的候选基频作为最终的基频。
2. 用于估计频谱包络的CheapTrick算法
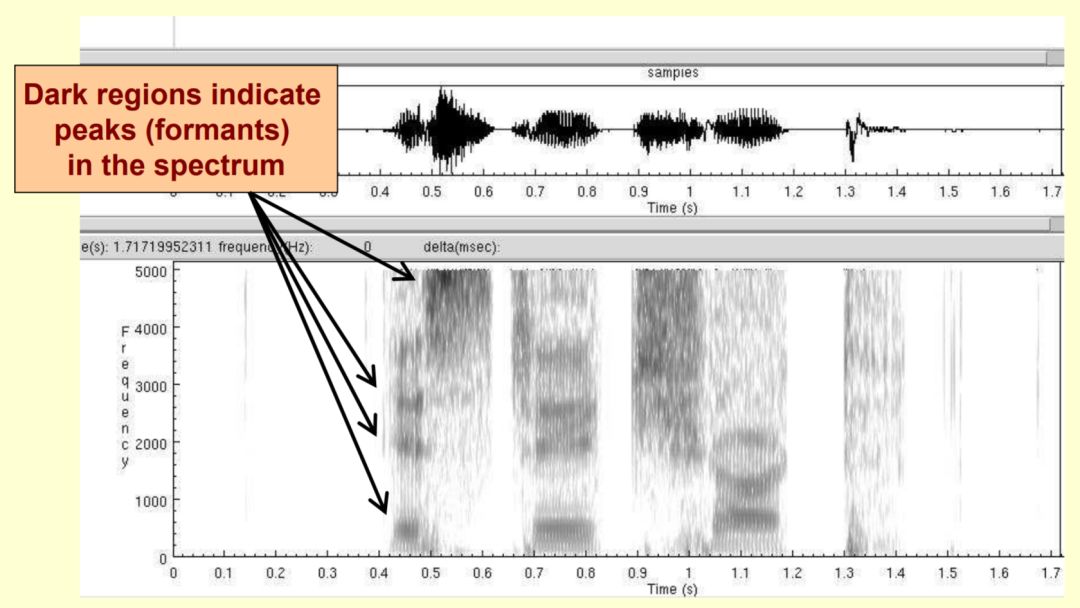
首先,我们需要明白什么是语音的频谱包络,语音是一个时序信号,例如对于一个采样频率为16kHz的音频文件,意味着在这个音频中,每一秒包含16000个采样点,这些采样点在计算机中以某种数据形式进行存储着(例如常见的有16bit整型),当我们使用矩形窗函数对一段音频进行处理,它就被划分成多个帧,于是得到了多个子序列,然后对每个子序列进行傅里叶变换操作,就得到了频率-振幅图,将这些图在时间维度上展现出来,就得到了这个语音文件的spectrogram。一张实际的spectrogram如下图所示。
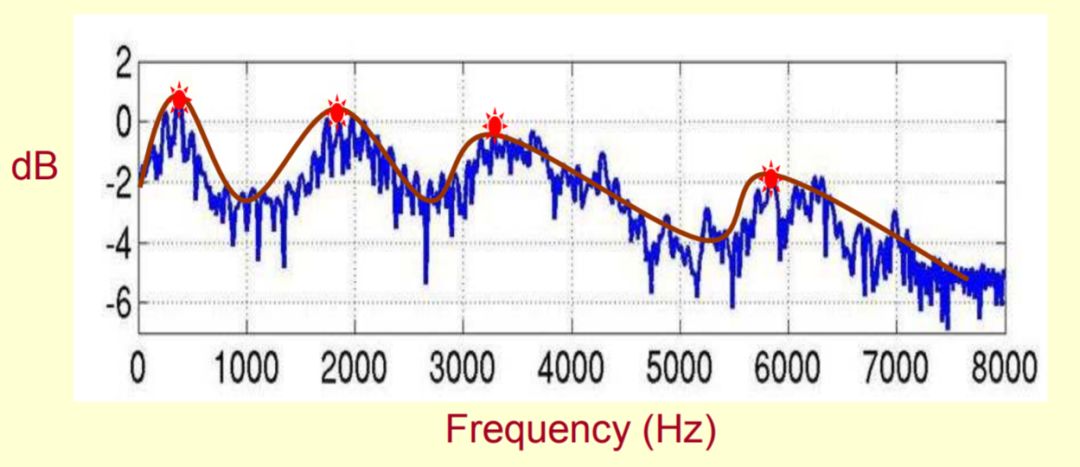
频谱包络实际上是在一个频率-振幅图中,将每个频率共振峰用平滑的曲线连接起来,而这个平滑的曲线就是语音的频谱包络,下图展示了频谱包络在频谱图中的位置。
确定这个频谱包络的算法有很多,例如常见的是倒谱法(Cepstrum,有趣的是,cepstrum与spectrum两个单词只是开头四个字母翻转了位置而已,这其实也暗示了它们的物理含义有某种巧合的关联...),在WORLD中,使用的是CheapTrick算法来估计频谱包络,该算法工作流程如下:
首先,对信号添加Hanning window,然后对windowed之后的信号计算其功率,公式如下(1)所示;
其次,使用矩形窗函数对功率谱进行平滑化,公式如下(2)所示;
最后,计算功率谱的倒谱,并做倒谱提升,公式如下(3)(4)(5)(6)所示;
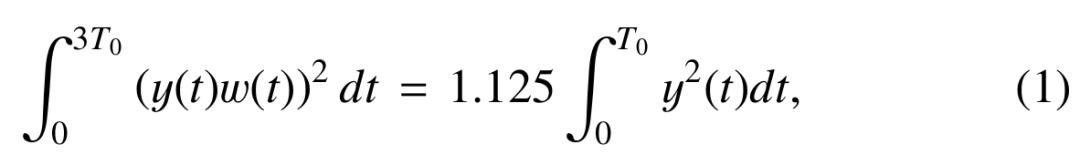
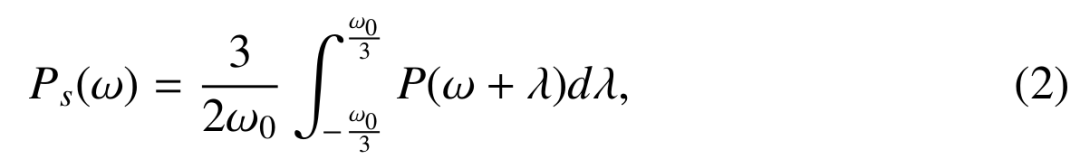
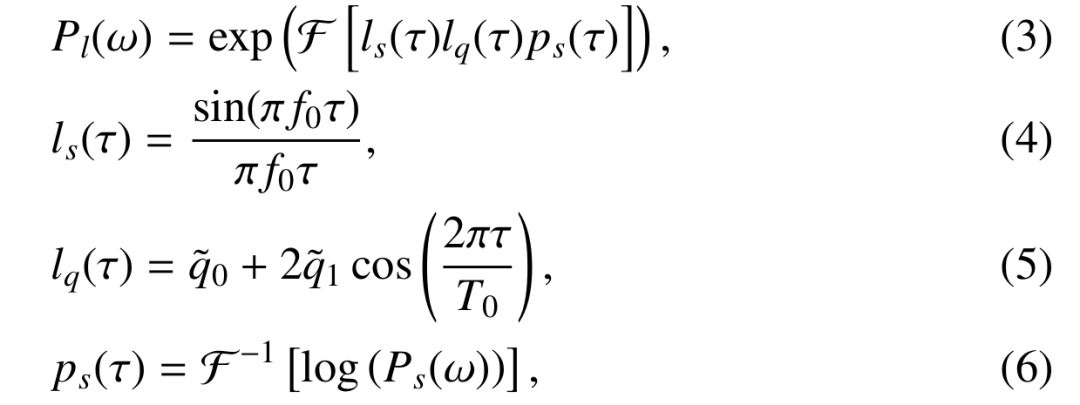
最终得到的Pl(w)就是我们所需要的频谱包络。
3. Aperiodic参数提取算法
aperiodic是与混合激励相关的参数,为了获得自然的声音,激励源不能只使用周期信号,也需要包含一些非周期信号。在WORLD中,aperiodic参数可以直接基于波形、F0、频谱包络来计算得到。这种算法叫做PLATINUM,它的工作流程如下:
首先,对波形添加宽度为2T0的窗函数,并计算得到其频谱X(w);
将X(w)除以最小相谱Sm(w)得到Xp(w),公式如(11)所示;
对Xp(w)进行逆iFFT,即可得到激励信号,公式如(10)所示;
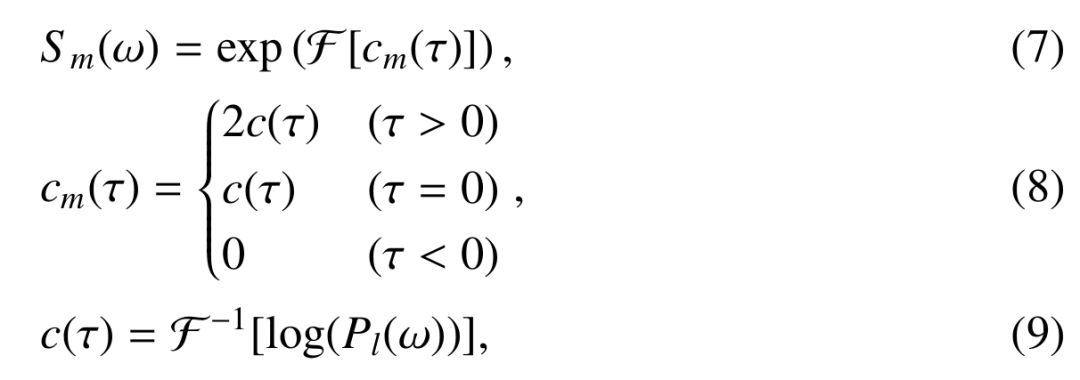

最终的语音合成是通过将最小相谱与激励信号进行卷积得到。
最后,来看一下如何调用WORLD来合成一段语音以及合成的效果。WORLD源代码是基于C语言的,但是WORLD也有一个Python wrapper库——PyWorld,为了代码简洁起见,这里我们使用PyWorld来演示。
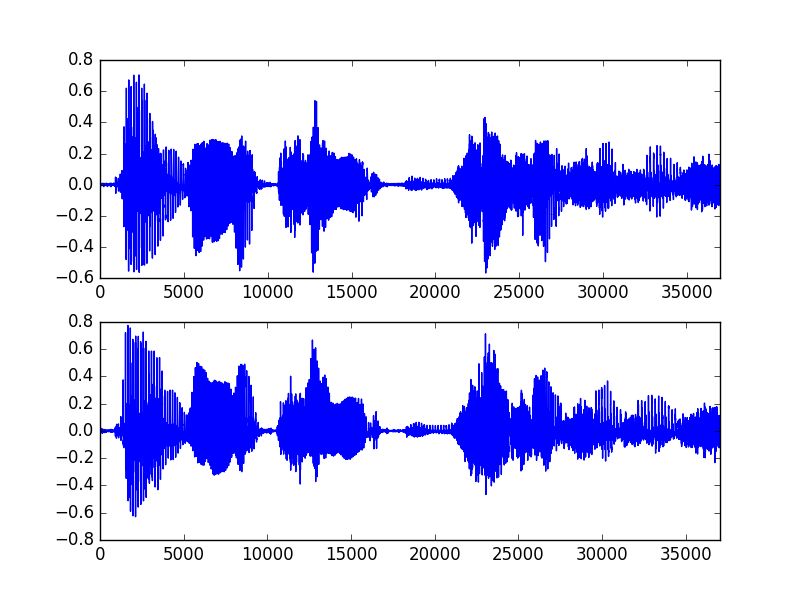
在终端运行pip install pyworld以及pip install soundfile即可安装PyWorld库,该库中提供了一个demo代码,可以用来演示语音合成。下面一段代码就是使用WORLD库来提取音频特征,并将此特征基于vocoder合成新的音频,原始音频和新的音频的波形图对比如下图所示。
#获取音频的采样点数值以及采样率
x, fs = sf.read('utterance/vaiueo2d.wav')
#使用DIO算法计算音频的基频F0
_f0, t = pw.dio(x, fs, f0_floor=50.0, f0_ceil=600.0,
channels_in_octave=2,
frame_period=args.frame_period,
speed=args.speed)
#使用CheapTrick算法计算音频的频谱包络
_sp = pw.cheaptrick(x, _f0, t, fs)
#计算aperiodic参数
_ap = pw.d4c(x, _f0, t, fs)
#基于以上参数合成音频
_y = pw.synthesize(_f0, _sp, _ap, fs, args.frame_period)
#写入音频文件
sf.write('test/y_without_f0_refinement.wav', _y, fs)下图是原始波形与合成后音频的波形对比,上图是原始波形,下图是合成后的音频波形,可以看到,基本保持一致。由于公众号文章只能上传一段音频,因此这里我只能上传合成后的音频。
WORLD语音合成系统可以根据F0、spectral envelope、aperiodic三个参数来合成一段语音,因此,在前沿的语音合成研究中,会通过深度学习技术学习到一段文本所对应的这三个特征,然后借助WORLD合成为语音。
你可能会感兴趣的文章有:
动态层归一化(Dynamic Layer Normalization)
详述DeepMind wavenet原理及其TensorFlow实现
Layer Normalization原理及其TensorFlow实现
Batch Normalization原理及其TensorFlow实现
Maxout Network原理及其TensorFlow实现
Network-in-Network原理及其TensorFlow实现
如何基于TensorFlow实现ResNet和HighwayNet
TensorFlow seq2seq中的Attention机制(续)
深度学习每日摘要|坚持技术,追求原创






