赛尔原创 | 结合贪心搜索和蒙特卡洛随机游走的面向DBpedia的实体链接方法

作者:哈工大SCIR硕士生刘一仝 ,哈工大SCIR副教授刘铭
摘要
互联网中存在着大量的命名实体,实体链接技术因而发挥了越来越大的作用。实体链接可以通过将名称指称与外部知识的特定实体对应起来,来帮助用户理解名称指称的含义。然而,一个名称指称可能对应多个可能的实体。经常共现的多个名称指称彼此相关是一个显而易见的事实,因此可以将这些名称指称一起考虑来获得最佳的对应关系,这种方法也被称作集体实体链接(collective entity linking),并且通常被应用在基于图的实体链接任务上。但是,传统的集体实体链接方法要么会因为图规模巨大导致耗费过长的时间,要么会因为图的简化导致链接精度较低。为了同时提升准确率和效率,本文提出一种全新的集体实体链接方法。首先,将任意两个相关实体连接起来以构建实体图;之后在构建的图上,利用一个基于概率的目标函数来保证链接结果的准确性。基于此目标函数,我们将实体链接任务转化为一个寻找具有最高PageRank值的节点的搜索过程,并利用贪心搜索和调整过的蒙特卡洛随机游走方法来解决此任务。实验结果表明,我们的方法比传统的实体链接方法具有更好的效果。
注:此文章的内容节选自TOIS 2017的论文“DBpedia-Based Entity Linking via Greedy Search and Adjusted Monte Carlo Random Walk”和KAIS 2018的论文“Collective entity linking:a random walk-based perspective”。
简介
由于互联网技术的快速进步,网络上出现了大量的名称指称。大多数名称指称是人名、地名、产品名、机构名等等。在不考虑上下文的情况下,一个名称指称可能会有多个解释。许多互联网技术-比如信息检索和数据挖掘[13,21]-性能提升的关键就是获得一个名称指称的实际含义。获取一个名称指称的含义的通常方法是将这个指称链接到外部资源(如维基百科)的一个实体上。例如,有这样一句话“史蒂夫·乔布斯是苹果有限公司的创始人。”,其中的名称指称“史蒂夫·乔布斯”可以被链接到维基百科的页面http://en.wikipedia.org/wiki/Steve_Jobs上。这种链接可以帮助用户了解句子中的“史蒂夫·乔布斯”是谁。不幸的是,就好比词语具有歧义一样,一个名称指称可以链接到多个实体上。例如不考虑上下文,“史蒂夫·乔布斯”可能会与其他很多人有关联,甚至可能是一部电影或一本书。正由于此,在寻找与名称指称匹配的最佳实体时,本文提出的方法会同时考虑出现在同一上下文中的所有名称指称。这种方法也被称为集体实体链接,并且与其他实体链接方法相比,集体实体链接具有更好的精度[8,9,18]。以刚刚的例句为例,在这句话中“史蒂夫·乔布斯”和“苹果有限公司”是一对共现的名称指称。在维基百科中,“史蒂夫·乔布斯”会被链接到3个实体中,其中一个是人,另一个是电影,最后一个是一本书。“苹果有限公司”仅仅会链接到一个跟公司相关的实体。如果我们将两个名称指称同时考虑,在“史蒂夫·乔布斯”链接到的3个实体中,只有与人相关的那一个具有一个URL可以重定向到公司命名实体“苹果有限公司”。因此可以很容易地确定,在刚刚那句话中,史蒂夫·乔布斯是一个人。几乎所有的集体实体链接方法都将共现指称所对应实体间使用一条路径连接起来。这样可以形成一个反映不同指称所对应的实体之间的关系的实体图。通过实体图,可以清晰刻画指称与实体之间的关系。但是由于实体图的巨大尺寸,传统的集体实体链接方法非常耗时,使得传统集体实体链接方法无法被应用到现实应用中[14]。在这种背景下,本文提出了一个具有高准确度和低运行时间的集体实体链接算法。具体贡献如下:
(1)为了获得高准确度,本算法构建了一个可以全面覆盖实体之间关系的实体图。并且,本文设计了一个基于概率的损失函数来为名称指称寻找最佳实体。实验结果表明,基于此实体图的链接结果与精确结果十分接近。
(2)通过概率损失函数来寻找全局最优解非常耗时。因此,我们将实体链接问题转化为图搜索问题,通过贪心搜索寻找局部最优解来缩短运行时间。为了给每一个名称指称寻找一个命名实体,通过PageRank算法为图中的每一个节点赋权,并且将贪心搜索的过程转化为寻找具有最高PageRank值的节点的过程。
(3)由于我们的实体图具有一些特殊的性质,比如没有悬节点(dangle node)、没有沉没圆(sink circle)、没有个性化向量(personalized vector),无法使用传统的方法为实体图中的节点计算PageRank值。基于此,我们提出了一个调整过的蒙特卡洛随机游走方法来计算图中每个节点的PageRank值。实验结果表明,通过贪心搜索和调整过的蒙特卡洛随机游走方法,我们的算法比传统的集体实体链接方法运行更快。
模型描述
在介绍我们的链接算法之前,需要弄清几个在后面篇章中会经常出现的概念。
(1)候选实体:一个候选实体可能是一个名称指称在外部知识库中可能链接到的实体。例如“史蒂夫·乔布斯”可能会链接到维基百科中的三个候选实体。使用编辑距离来选择一个名称指称的候选实体集。
(2)中间实体(或者实体图中的中间节点):一条路径中可以连接两个相关候选实体的实体叫做中间实体(或中间节点)。
在我们的算法中,需要用一条路径来连接相关候选,从而形成一个实体图。维基百科不具有明确的链接结构。基于此,我们选择DBpedia作为链接的外部知识库。选择DBpedia的原因主要有以下两点:其一是维基百科是一种与Freebase和YAGO类似的百科全书,其包含的实体项每天都在增加。其二是DBpedia和维基百科具有相同的实体,唯一的不同是维基百科中的一个实体使用一个网页来表示,而DBpedia使用一个节点来表示。总而言之,DBpedia是维基百科的结构化表示。如果两个实体在DBpedia中使用一条弧相连,那么这两个实体就是相关的。例如“史蒂夫·乔布斯”和“苹果商店”两个候选实体(一个的链接是http://dbpedia.org/page/Steve_Jobs,另一个的链接是http://dbpedia.org/page/Apple_Store),显然他们之间是相关的,但是在DBpedia中并没有直接相连,他们只能使用一条通过“苹果有限公司”或“蒂姆库克”的路径相连。一条路径是(史蒂夫乔布斯、苹果有限公司、苹果商店),另一条路径是(史蒂夫乔布斯、蒂姆库克、苹果商店)。像“苹果有限公司”和“蒂姆库克”这种能形成一条路径来连接两个候选实体的实体就是中间实体。本文关注于实体链接,因此假定我们的链接算法是在文章中的实体都能被正确识别和标准化的假设下运行的。例如,将“史蒂夫.保罗.乔布斯”,“史蒂夫.P.乔布斯”,“乔布斯”等等统一为“史蒂夫·乔布斯”。事实上,对于一篇文章中毗邻的两个实体指称,它们的链接实体也可能是相关的。这意味着,我们不需要同时处理一篇文本中的所有实体指称,只需使用滑动的窗口来分割文本,并且将处于同一窗口中的名称指称放入一个标签为“NM”的集合中。在NM中的名称指称会被同时处理。窗口的大小被设置为50,这个数值是文献[12]提出的一个有意义的句子的平均长度。
图1是一个实体图的例子。它通过下面的句子构建而来:“人们总是谈论苹果发布的成功产品,例如iPhone。事实上,以麦金托什机为例,乔布斯也会发布不成功的产品。”(“People only talk about the successful products released by Apple, such as iPhone. In fact, taking Macintosh as example, Jobs also produced many unsuccessful products.”)这句话里有四个名称指称(通过预处理过程提取出四个名称指称,在预处理过程中,一些常见的指称不会被提取出来,比如“人们”和“产品”),已加粗标示。每一个名称指称都具有一个候选实体集,为了简化图的表示,我们使c_en**代表一个候选实体,并且使in_en**代表一个中间实体(或者一个中间节点),表1列出了名称指称的实际意义和对应的候选实体。在图1中,一个椭圆包含了一个名称指称的全部候选实体。例如,c_en11, c_en12, c_en13都是m1的候选实体。两个在DBpedia中直接相连的实体,在图中用一条边直接连接。每一条边均有一个标记集。此集合包含通过这条边的所有路径能连接的所有候选实体。例如边(in_en3,in_en4)的标记集为{c_en13,c_en21,c_en42}。这些候选实体所对应的结点可以被穿过(in_en3,in_en4)的路径连接在一起。此标记集合可以用来计算图中边的权值。
表1. 图1中所有结点的真实含义
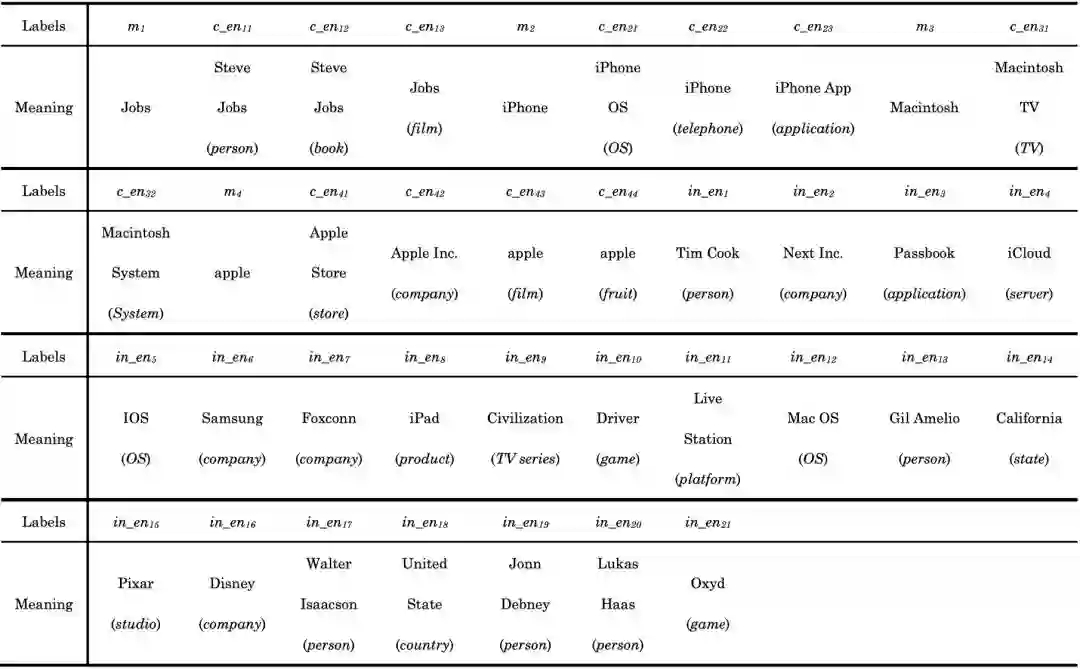
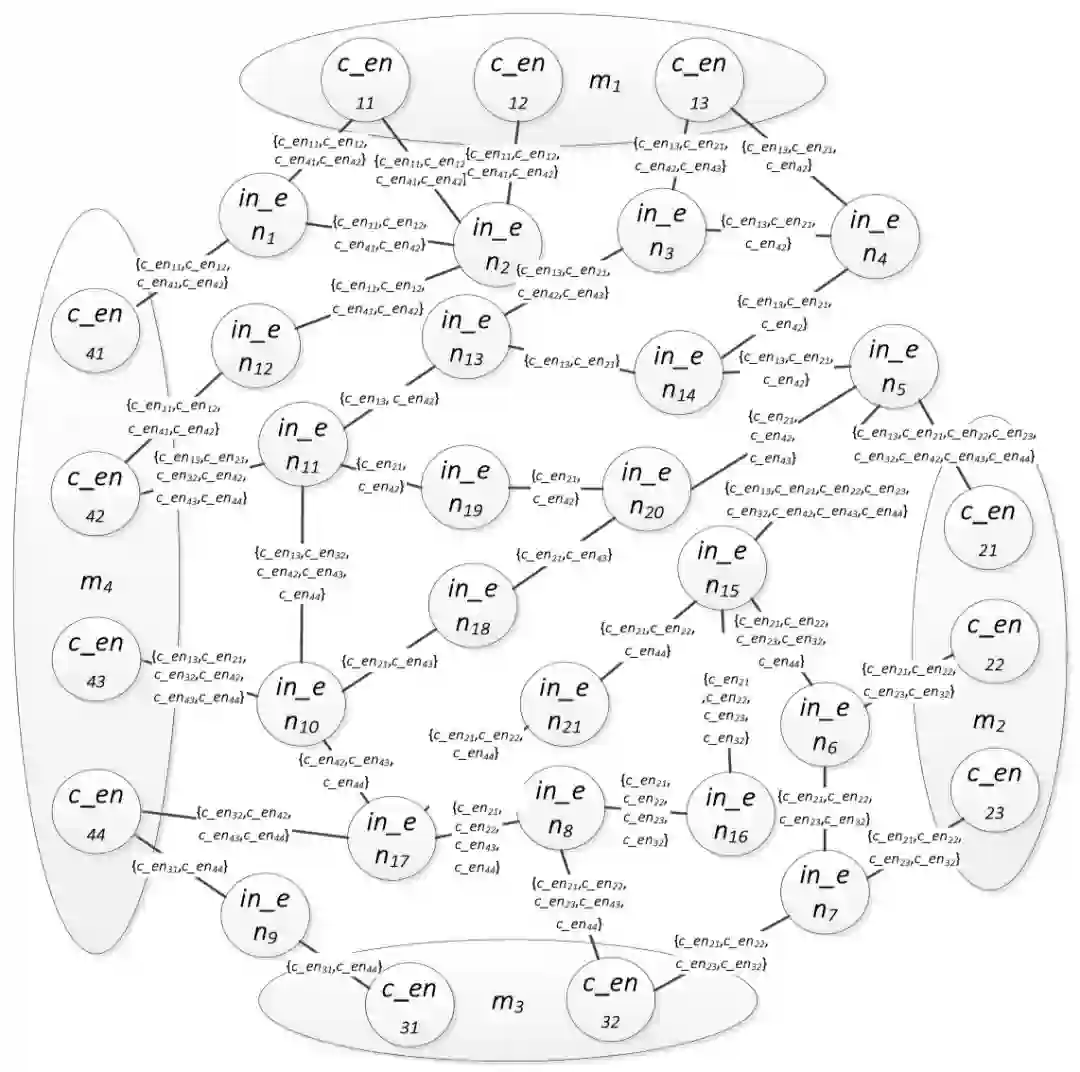
图1. 依据文中句子所构建的图模型
既然四个名称指称(i.e. m1, m2, m3, m4)在上下文中共现,那么可以假设这四个名称指称是相关的。本文使用一个联合概率分布来函数来计算将每一个候选实体分别分配给每个指称的联合概率。
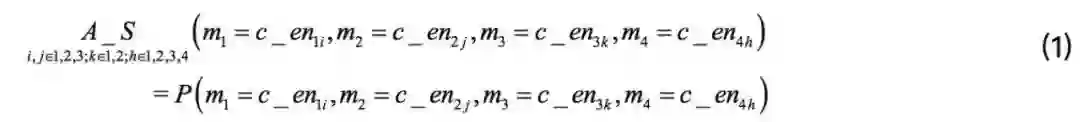
(m1=c_en1i,m2=c_en2j,m3=c_en3k,m4=c_en4h)即代表一种分配,这种分配将c_en1i分配给m1,c_en2j分配给m2,c_en3k 分配给m3,c_en4h分配给m4。
在式(1)中,一个名称指称的分配会影响其他分配。寻找最优的分配等同于在所有的联合概率中寻找一个具有最大值的分配。在图1中利用这种暴力搜索方法需要扫描3*3*2*4种组合。也就是说一旦名称指称集合十分巨大,暴力搜索方法会非常耗时。正是由于此原因,我们使用贪心搜索来获得最佳分配的近似解。
通过贪心搜索,式(1)可以被改写成下式:
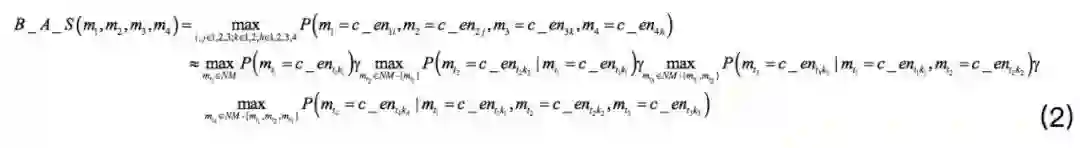
基于式(2)的搜索过程如下:
步1:在NM={m1,m2,m3,m4}中寻找一个名称指称的具有最大概率的分配。这一步符合式(2)中的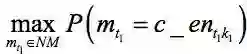
步2:假设c_ent1k1是步1找到的候选实体,把它当作名称指称mt1的最佳分配。
步3:当c_ent1k1被分配给mt1时,在NM-{mt1}中找到一个名称指称具有最大概率的分配,这一步对应式(2)中的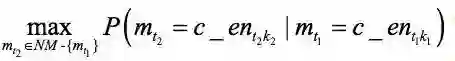
步4:假设c_ent2k2是步3找到的一个候选实体,把它当成名称指称mt2的最佳分配。
步5:重复步1到步4直到找到NM-{mt1,mt2}中包含的名称指称的分配。
式(1)和式(2)可以很容易扩展到包含任意指称数目的情况上。现在的问题是怎样计算式(1)和式(2)中的概率。给定NM中的指称mt1,让c_ent1k1代表它的一个候选实体。既然NM中的指称是共现的,如果c_ent1k1与其他的很多候选实体相关,分配给(mt1=c_ent1k1)的概率就应该很大。如果很多条路径都通过某个候选实体,则可以说这个候选实体和许多其他的候选实体相关,在这种情况下,这个候选实体可以被认为是一个名称指称的最佳分配的可能性应该是很大的。如果一个节点被很多条路径通过,那他的PageRank值就应该很高。因此,我们可以使用PageRank值来衡量把这个候选实体分配给一个名称指称的概率。使用PageRank来计算分配概率的另一个原因是,一个节点的PageRank值可以传递到其他节点。图2展示了图1中每个节点的PageRank值。
注:限于篇幅原因,具体的PageRank值计算方法可参见TOIS 2017的论文“DBpedia-Based Entity Linking via Greedy Search and Adjusted Monte Carlo Random Walk”,此处不做过多介绍。
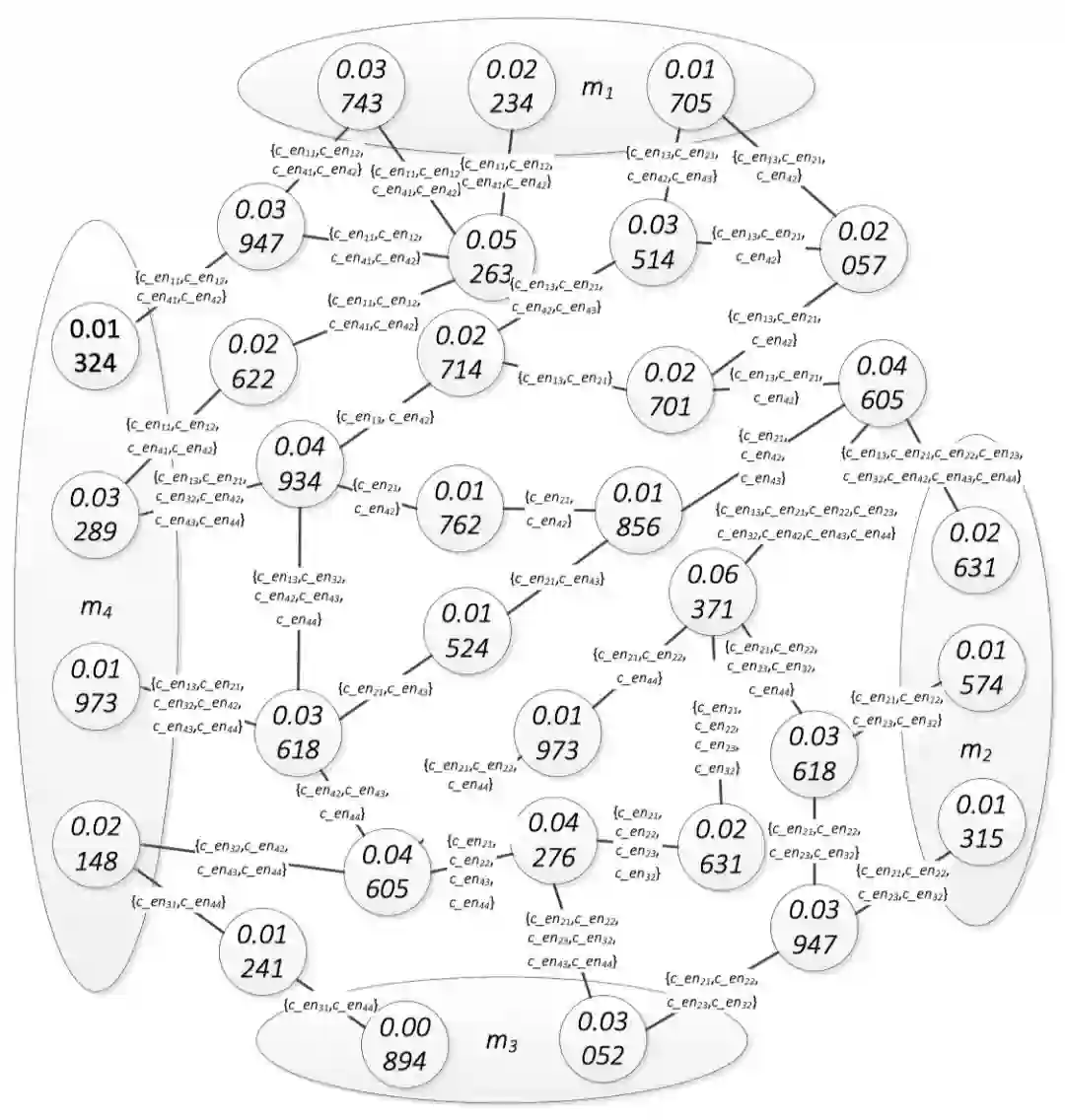
图2. 图1中各节点的PageRank值
当将某个候选实体被分配给某个名称指称后,该指称对应的其他候选实体即可以从图中予以移除。当然,移除候选实体后会影响整个实体图的结构。一旦一个候选实体被移除,这个候选实体即需要从图中每一条边的标记集合中移除。例如,在图2中,当c_en12被移除时,c_en12也会从所有的标记集合中移除。当一条边的标记集合为空时,这条边也从实体图中移除。图3是从图2中移除了c_en12和c_en13后的实体图。根据图3中的PageRank值,c_en32是m2的最佳分配。
不断重复以上过程n次(n代表NM中的名称指称数),可以找到NM中所有的名称指称的链接实体。图3和图4是在成功找到m2和m4的最佳分配过程中形成的图。通过图3,c_en42分配给m4。通过图4,c_en22分配给m2。
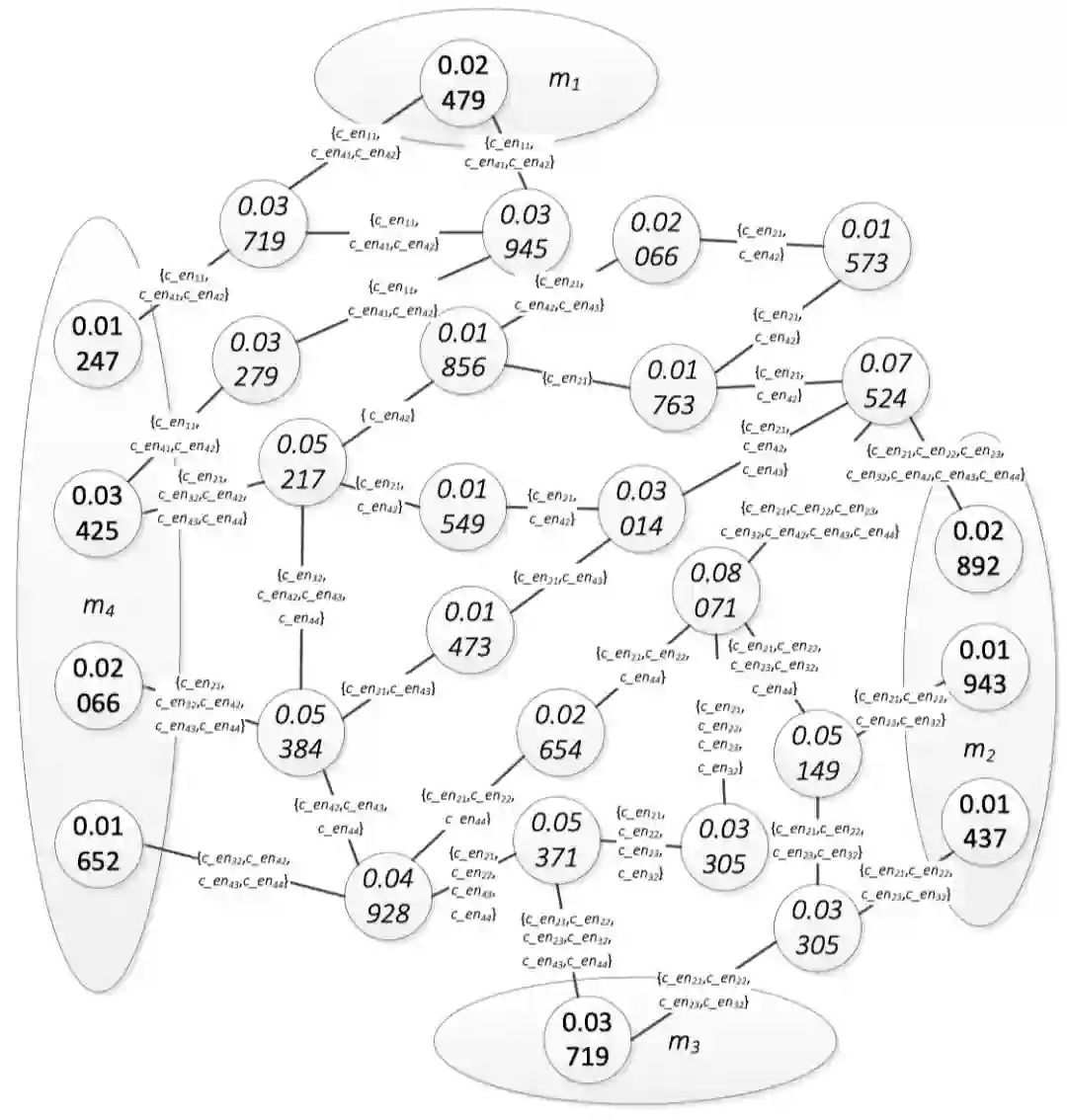
图3. 将与m3无关的候选实体移除后图中各节点PageRank值
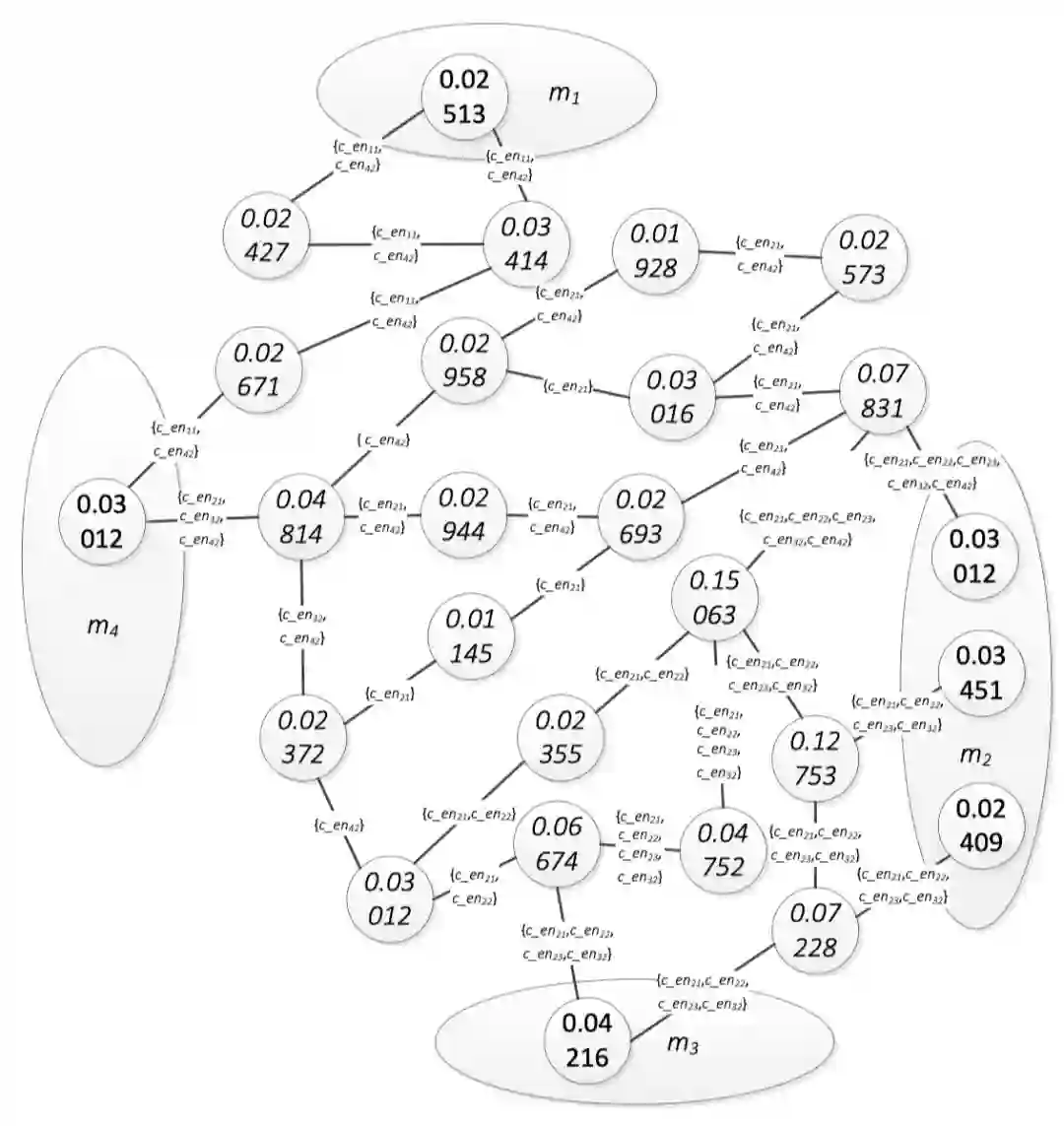
图4. 将与m4无关的候选实体移除后图中各节点PageRank值
实验分析
以下实验将我们的链接算法和不同的基线算法在准确度和运行时间上做比较。基线算法包含实体对实体(entity to entity)的方法,例如Spotlight [3],BEL [23],LIMES [15],Swoosh [1]和AIDA-Light [16];基于机器学习的方法,例如SHINE [19],DNNEL [5],LISTSVM [10]和GEML [22];基于集体实体链接的方法,例如EMLC [6],AGDISTIS [20],LGD2W [17],AIDA [7],ELPH [4],GSEL [2],和FHCEL [11]。在表2和表3中,把本文提出的算法称为(ELGA)。所有的基线算法都在都在一个具有2.4G Hz CPU和16G内存的电脑上运行。
表2. 不同算法的链接结果F1值 (*代表显著性检测,其中***代表显著性检测达到0.01水平,**代表达到0.05水平,*代表达到0.1水平)
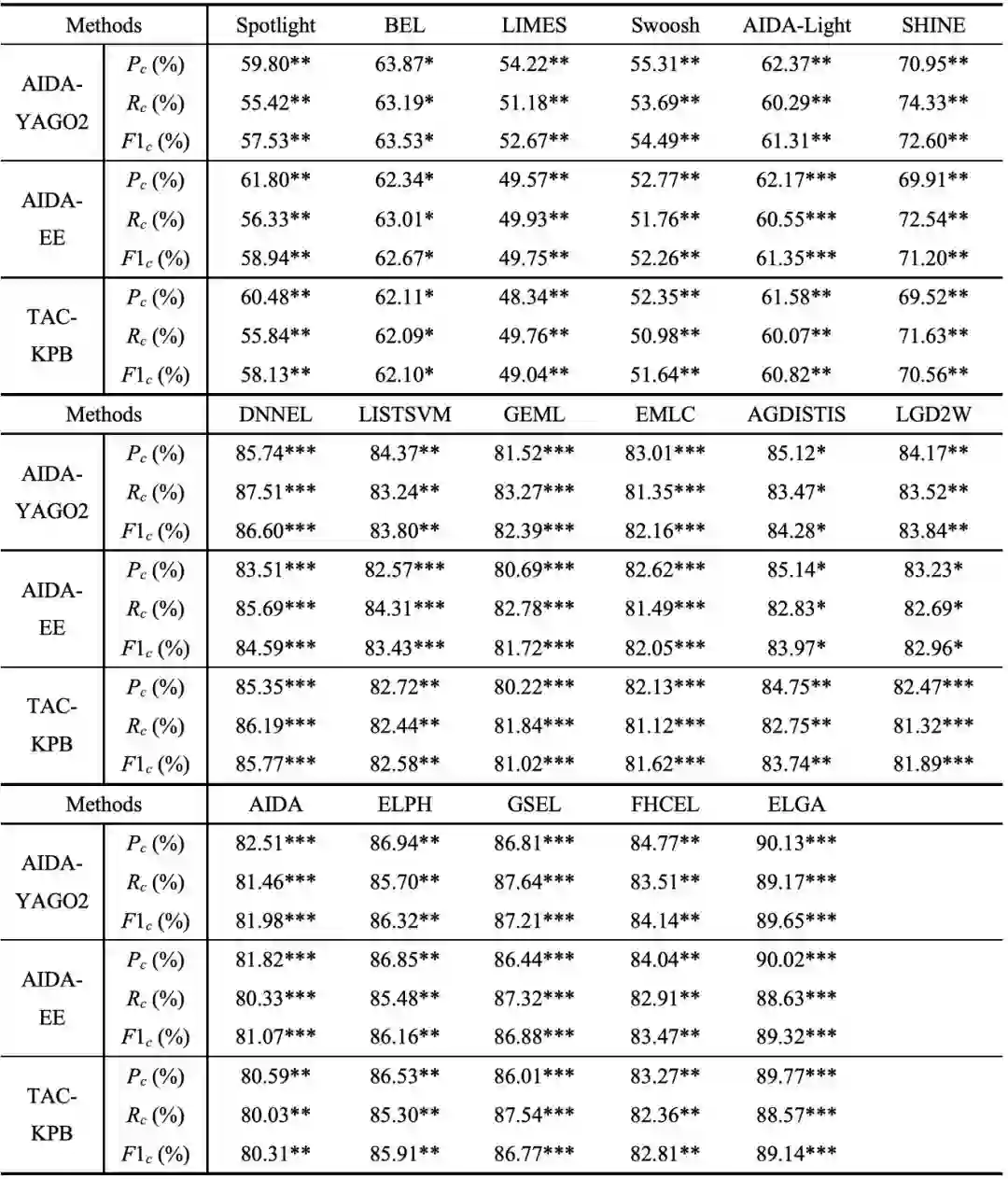
表3. 不同算法对单个名称指称处理的平均时间
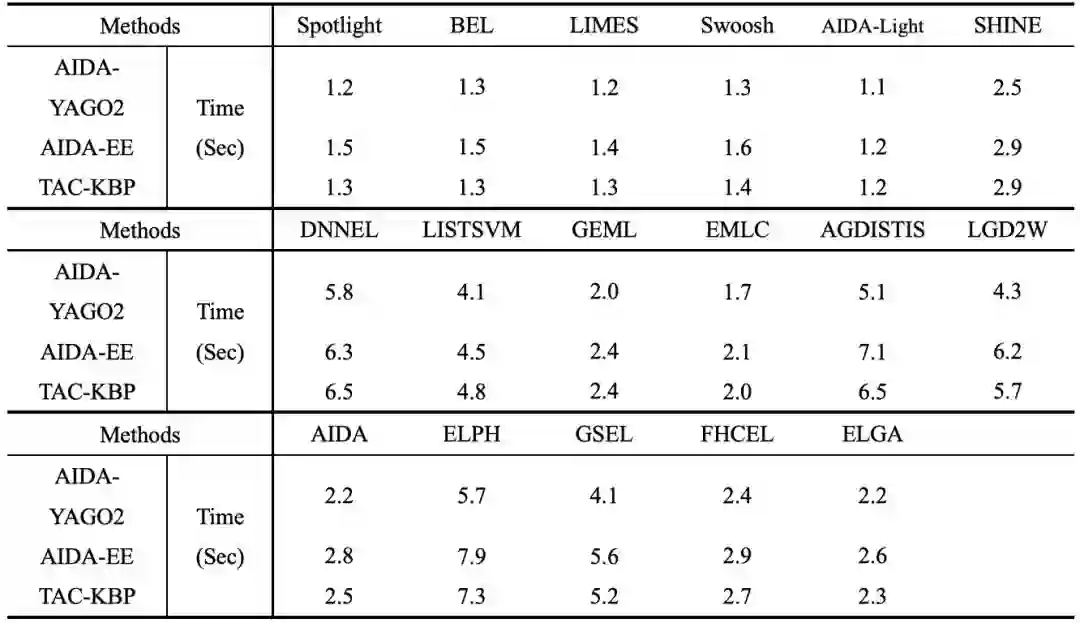
通过观察表2和表3,可以很容易看出实体对实体的方法比其他方法运行速度要快很多。事实上,实体对实体方法就是为线上使用特别设计的。为了减少运行时间,这类方法引入了一些限制。例如,LIMES需要相似度满足三角不等式,Swoosh需要相似度满足偏序。由于这些限制,实体对实体方法可以大幅度缩减运行时间。以AIDA-Light为例,它只需要1秒钟就可以处理1个名称指称。而另一方面,因为它们从不考虑实体之间的关系,而且一些限制在实际应用中过于严格,所以它们的准确度非常低。正是由于此原因,它们的F1值也很低。相反的,基于集体链接的方法在所有测试集上都具有较高准确度。这是由于基于集体链接的方法构建了一个可以捕获实体之间关系的图,并且在图中不具有额外的限制。因此,具有很高的准确度。然而,基于集体链接的方法需要为图中的节点赋权(EMLC和AGDISTIS),或分析图的结构 (ELPH,GSEL和FHCEL),或将实体之间的关系整合到一个目标函数中(LGD2W和AIDA)。这些过程都是耗时的。EMLC和AIDA试图通过减少图的规模来减少运行时间,FHCEL使用爬山优化算法来解决NP问题,然而这些方法都会降低准确度。基于机器学习的方法取得的效果介于实体对实体方法和基于集体链接的方法之间。原因是基于机器学习的方法收集名称指称的上下文作为训练语料,训练了一个分类器来区分候选实体。此方法可以最大程度地应用名称指称上下文中的有用信息。例如名称指称的位置、名称指称的长度以及名称指称的词性等。基于此,基于机器学习的方法比实体对实体的方法具有更高的准确度,但是同样由于基于机器学习的方法没有考虑实体之间的关系,它的准确度要比基于集体链接的方法低。至于训练时间,既然基于机器学习的方法有一个训练过程并且这个过程是很耗时的,它的运行时间比实体对实体的方法要长。和基于集体链接的方法比较,基于机器学习的方法的训练过程只对一个实体进行。因此它们的运行时间比基于集体链接的方法的运行时间要短。在基于机器学习的方法中有一个例外,那就是DNNEL。这个方法将名称指称的稀疏上下文向量通过神经网络转化为稠密的向量,此向量可以在一定程度上反映实体之间的关系。但是这种转换是非常费时的,因此虽然DNNEL耗时很长,但它拥有和基于集体链接的方法类似的准确度。我们的算法(ELGA)也是一种基于集体链接的算法,并且它通过用路径连接所有相关的候选实体来构建了一个相对完整的实体图。基于实体图我们提出了一个基于概率的目标函数,这个目标函数考虑了实体之间的关系以保证获取精确的链接结果。除此之外,如表2所示,我们的链接算法在三个测试集上的显著性测试结果都达到了0.01水平。这意味着我们的链接算法比其它基线算法表现得更加出色。关于运行时间,由于我们的算法采用贪心策略和调整过的蒙特卡洛随机游走来加快速度,使得算法比其他的基于集体链接的算法的运行时间更短,它甚至短于一些基于机器学习的方法的运行时间,与实体对实体的方法接近。
后期展望
虽然我们的算法采用了贪心算法和被调整过的蒙特卡洛随机游走来缩短运行时间,但是此算法仍然无法在线上运行。为了使它具有更高的效率,我们打算将实体图分割成几个部分,而仅对某一部分更新PageRank值来进一步缩短运行时间。除此之外,我们的算法需要重构实体图并且多次运行PageRank算法,这个重计算过程也是十分耗时的。为解决此问题,我们打算分析实体图的结构并且找到很少变化的部分,然后保持很少变化部分节点的PageRank值,只重新计算其他部分的节点。
参考文献
[1] Omar Benjelloun, Hector Garcia-Molina, David Menestrina, Qi Su, Steven Euijong Whang, and Jennifer Widom. 2009. Swoosh: A generic approach to entity resolution. Int. J.VLDB 18, 1(2009), 255–276.
[2] Diego Ceccarelli, Claudio Lucchese, Salvatore Orlando, Raffaele Perego, and Salvatore Trani. 2013. Learning relatedness measures for entity linking. In Proceedings of the 22nd ACM International Conference on Information and Knowledge Management. ACM, 139–148
[3] Joachim Daiber, Max Jakob, Chris Hokamp, and Pablo N. Mendes. 2009. Improving efficiency and accuracy in multilingual entity extraction. In Proceedings of the 9th International Conference on Semantic Systems. ACM, Graz, Austria, 121–124
[4] Ben Hachey, Will Radford, and James R. Curran. 2011. Graph-based named entity linking with Wikipedia. In Proceedings of the 12th International Conference on Web Information System Engineering. ACM, 213–226.
[5] Xianpei Han and Le Sun. 2011. A generative entity-mention model for linking entities with knowledge base. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics. ACL, 945–954.
[6] Xianpei Han, Le Sun, and Jun Zhao. 2011. Collective entity linking in web text: A graph-based method. In Proceedings of the 34th International ACM SIGIR Conference on Research and Development in Information Retrieval. ACM, 765–774.
[7] Johannes Hoffart, Mohamed Amir Yosef, Ilaria Bordino, Hagen Furstenau, Manfred Pinkal, Marc Spaniol, Bilyana Taneva, Stefan Thater, and Gerhard Weikum. 2011. Robust disambiguation of named entities in text. In Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing. ACL, 782–792.
[8] Ben Hachey, Will Radford, Joel Nothman, Matthew Honnibal, and James R. Curran. 2013. Evaluating entity linking with wikipedia. Artif. Intell. 194(2013), 130–150.
[9] Zhengyan He, Shujie Liu, Yang Song, Mu Li, Ming Zhou, and Houfeng Wang. 2013. Efficient collective entity linking with stacking. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing. ACL, 426– 435.
[10] Zhengyan He, Shujie Liu, Mu Li, Ming Zhou, Longkai Zhang, and Houfeng Wang. 2013. Learning entity representation for entity disambiguation. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics. ACL, 30–34
[11] Sayali Kulkarni, Amit Singh, Ganesh Ramakrishnan, and Soumen Chakrabarti. 2009. Collective annotation of wikipedia entities in web text. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM, 457–465.
[12] Yuhua Li, David McLean, Zuhair A. Bandar, James D. OShea, and Keeley Crockett. 2006. Sentence similarity based on semantic nets and corpus statistics. IEEE Trans. Knowl. Data Eng. 18, 8(2006), 1138–1150.
[13] Edgar Meij, Krisztian Balog, and Daan Odijk. 2013. Entity linking and retrieval. In Proceedings of the 37th International ACM SIGIR Conference on Research and Development in Information Retrieval. ACM, 1127–1127.
[14] Galileo Mark Namata, Stanley Kok, and Lise Getoor. 2011. Collective graph identification. In Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM, 87–95.
[15] Axel-Cyrille Ngonga Ngomo and Sören Auer. 2011. LIMES: A time-efficient approach for large-scale link discovery on the web of data. In Proceedings of the 22nd International Joint Conference on Artificial Intelligence. AAAI, 2312–2317.
[16] Johannes Hoffart, Martin Theobald, and Gerhard Weikum. 2014. AIDA-light: High-throughput named-entity disambiguation. In Proceedings of the Workshop on Linked Data on the Web Co-Located with the 23rd International World Wide Web Conference. Vol. 1184.
[17] Lev Ratinov, Dan Roth, Doug Downey, and Mike Anderson. 2011. Local and global algorithms for disambiguation to wikipedia. In Proceedings of the 34th International ACM SIGIR Conference on Research and Development in Information Retrieval. ACM, 1374–1384.
[18] Prithviraj Sen. 2012. Collective context-aware topic models for entity disambiguation. In Proceedings of the 21st International Conference on World Wide Web. ACM, 729–738.
[19] Wei Shen, Jiawei Han, and Jianyong Wang. 2014. A probabilistic model for linking named entities in web text with heterogeneous information networks. In Proceedings of the 2014 ACM SIGMOD International Conference on Management of Data. ACM, 1199–1210.
[20] Ricardo Usbeck, Axel-Cyrille Ngonga Ngomo, Michael Röder, Daniel Gerber, Sandro Athaide Coelho, Sören Auer, and Andreas Both. 2014. AGDISTIS-agnostic disambiguation of named entities using linked open data. In Proceedings of the 21st European Conference on Artificial Intelligence. AAAI, 1113–1114.
[21] Wei Shen, Jianyong Wang, and Jiawei Han. 2015. Entity linking with a knowledge base: issues, techniques, and solutions. IEEE Trans. Knowl. Data Eng. 27, 2(2015), 443–460.
[22] Zhicheng Zheng, Fangtao Li, Minlie Huang, and Xiaoyan Zhu. 2010. Learning to link entities with knowledge base. In Proceedings of the 2010 Annual Conference of the North American Chapter of the ACL. ACL, Los Angeles, 483–491.
[23] Zhe Zuo, Gjergji Kasneci, Toni Grütze, and Felix Naumann. 2014. BEL: Bagging for entity linking. In Proceedings of 25th International Conference on Computational Linguistics. 2075–2086.
本期责任编辑:崔一鸣
本期编辑:吴 洋
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏



