重磅!谷歌等推出基于机器学习的数据库SageDB

你或许还记得 17 年底 AI 前线发布的热点报道 《Jeff Dean 出品:用机器学习索引替代 B-Trees,3 倍性能提升,10-100 倍空间缩小》 。当时谷歌 Jeff Dean 等人出品的一篇题为《学习索引结构的案例》的论文让整个业界为之振奋,同时也引发了大量的争论。在 17 年的论文中,谷歌研究团队尝试通过实验论证:与基于缓存优化的 B-tree 结构相比,使用神经网络在速度上可以提高 70%,并且大大节省了内存。“机器学习模型有可能比目前最先进的数据库索引有更显著的好处”。而今天我们要介绍的 SageDB,就是研究团队在该研究基础之上得出的更进一步的成果。
更多优质内容请关注微信公众号“AI 前线”(ID:ai-front)
SageDB 背后的核心思想是构建一个或多个关于数据和工作负载分布的模型,并基于它们自动为数据库系统的所有组件构建最佳数据结构和算法。我们称之为“数据库融合”的这种方法,将使我们能够通过将每个数据库组件的实现专门化到特定的数据库、查询工作负载和执行环境来实现前所未有的性能。
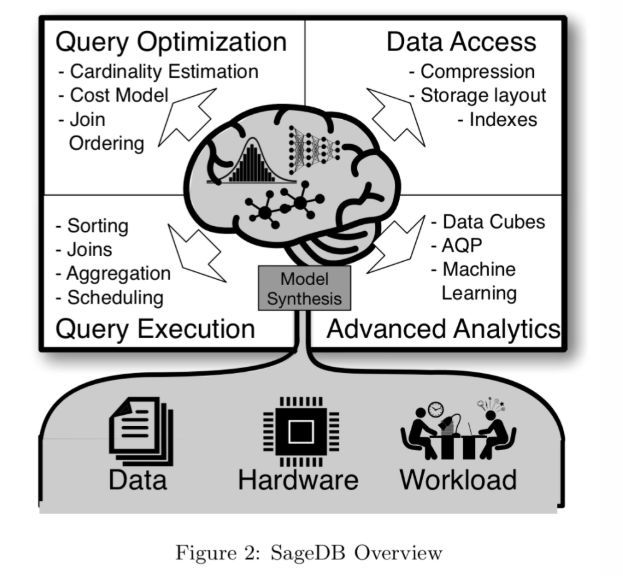
在缺乏运行时学习和适应的情况下,数据库系统是为通用目的而设计的,不能充分利用现有工作负载和数据的特定特性。SageDB 的出现能够弥补二者之间的鸿沟,它在了解数据分布和工作负载的情况下,可以在特定时间设计一种可能的专用解决方案。
考虑一个极端的案例:我们希望使用连续整数键来存储和查询固定长度记录。这里使用传统索引没有意义,因为键本身可以用作偏移量。AC 程序将 100M 整数加载到一个数组中,并在一个范围内求和,运行时间约为 300ms。在 Postgres 中执行相同的操作大约需要 150 秒,这是通用设计开销的 500 倍。
... 我们可以利用精确数据分布的知识,来优化数据库使用的几乎任何算法或者数据结构。这些优化有时甚至可以改变众所周知的数据处理算法的复杂性。
数据分布的知识以学习模型的形式出现。有了这样的模型,作者认为我们可以自动合成索引结构、排序和连接算法,甚至整个查询优化器,利用数据分布模式来提高性能。
什么样的模型有意义?举个例子,直方图是一个非常简单的模型,但对于这里讨论的用例,要么太粗糙,要么太大而无法使用。另一方面,深度和宽度神经网络的成本很高(尽管随着硬件的进步,这些成本可能会降低)。结合这个事实,对于这个使用场景,“过渡拟合”是好的!我们希望尽可能精确地捕捉精确数据的精确细微差别。(迄今为止的研究计划主要集中在分析工作负载上,一旦我们开始考虑更新,一定程度的概括显然是有益的)。
截至今天,我们发现我们经常需要生成特殊模型才能看到显著的效益。
例如,考虑一下论文《学习索引结构的案例》中的 RMI 模型:
在数据上拟合简单模型(线性回归、简单神经网络等)
使用模型的预测来挑选另外一个模型,即专家,它可以更准确地模拟数据子集合
重复该过程,直到叶模型进行最终预测
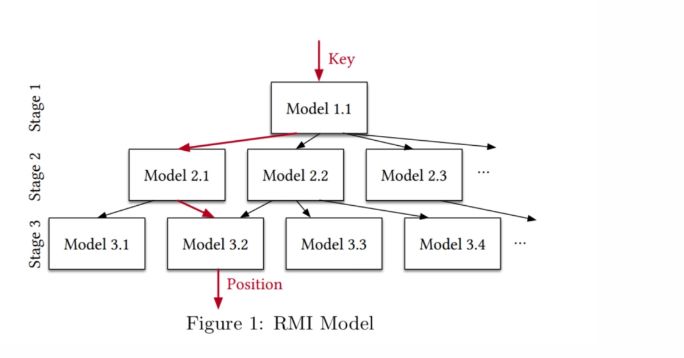
RMI 只是一个起点。例如,可以使顶部模型或底部模型更复杂,在特定级别阶段用其他类型的模型替换部分模型,使用量化方法、改变特征表示、将模型与其他数据结构组合等。因此,我们相信我们将看到关于如何最有效地为数据库组件生成一个模型来完成精度、低延迟、空间和执行时间之间平衡的新想法。
去年关于《学习索引结构的案例》的论文表明,基于 RMI 索引可以比最先进的 B-Tree 实现性能提高两倍,同时规模更小(注:研究人员已经更新了 arXiv 上的论文以包含最新测试结果,论文连接:https://arxiv.org/abs/1712.01208)。后续工作已将其扩展到存储磁盘、压缩插入和多维的数据。
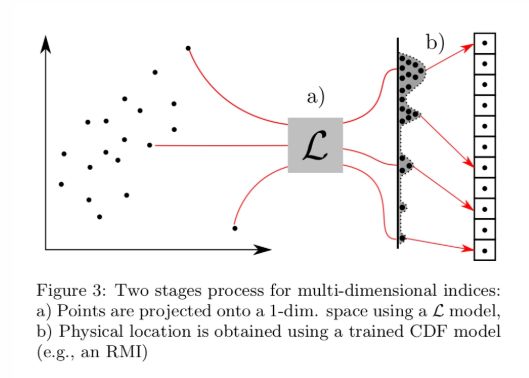
对于多维数据,基线是 R 树(与 B 树相对)。R-Tree 将矩阵映射到索引范围列表,使得位于矩阵中的每个点索引包含在这个范围的并集中。就像 B-Tree 一样,我们可以用学习模型替换 R-Tree。使 RMI B-Trees 替换工作得以实现的一个技巧是模型足以使我们“在正确的位置”,然后我们可以围绕预测完成本地搜索工作。对于 R-Trees,我们还需要一种能够实现高效本地化搜索的布局。
虽然存在许多可能的投影策略,但我们发现沿着一系列维度、连续排序和分割点到相同大小的单元格,这样计算、学习(例如,与 z-order 相比,这很难学习)、合成(即,索引范围联合中的几乎所有点都满足查询)起来非常高效。
作者通过压缩在内存中的列存储上实现了这样的学习索引,并将其与完整列扫描、聚簇索引(按提供最佳整体性能的列排序)和 R-Tree 进行了比较。使用 TPC-H 基准的 lineitem 表中的 6000 万条记录来作为基准测试,查询选择性为 0.25%。
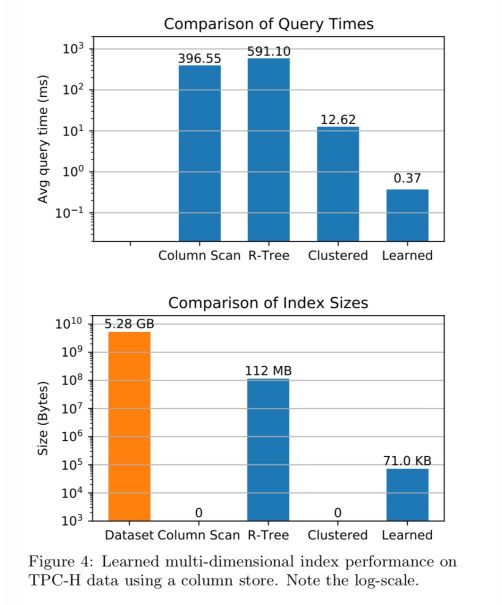
学习型索引以高达 34 倍的优势,击败了下一个性能最佳的实现(注意图表上的日志比例),与聚簇解决方案相比,其空间开销很小。
进一步的分析表明,学习型索引几乎可以在每种类型的查询中击败聚簇索引——当聚簇索引中的聚簇维度是查询中的唯一维度时除外。
这是论文中我最喜欢的一部分,因为它展示了学习模型如何能够帮助处理这种不起眼的古老的排序问题。排序方法是使用学习模型将记录大致按正确的顺序排列,然后在最后阶段再纠正为几乎完美的排序数据。为此,可以使用非常高效的局部排序算法,比如:插入排序。

下图显示了从正态分布中随机采样 64 位双精度数据,随着数据量越来越大,不同排序方法的结果比较。其中,Timsort 是 Java 和 Python 的默认排序,std::sort 来自 C++ 库。学习后的变体平均比下一个最佳(在这种情况下为 Radix 排序)快 18%。
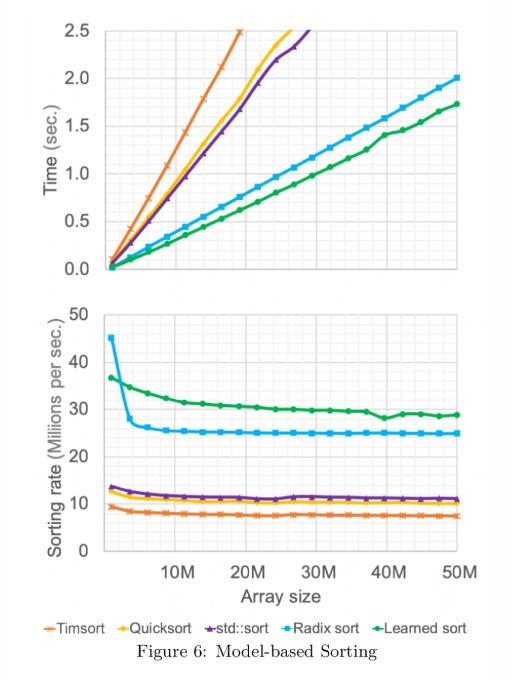
这不包含学习模型所花费的时间
学习的模型也可用于改善连接操作。例如,考虑一个具有两个存储连接列和一个模型列的合并连接。我们可以使用模型跳过不会连接的数据(作者没有详细说明“local patching”在这种情况下是如何工作的,这一点对于我来说理解的并不深刻)。
作者还尝试了工作负载感知调度程序,使用图神经网络实现基于强化学习的调度系统:
我们的系统将调度算法表示为神经网络,其采用关于数据的输入信息(例如,使用 CDF 模型)和查询工作负载(例如,使用在先前执行的查询上训练的模型)来做出调度决策。
在 10 个 TPC-H 查询的示例中,学习的调度程序比 Spark 的默认 FIFO 调度程序将平均作业完成时间提高了 45%。
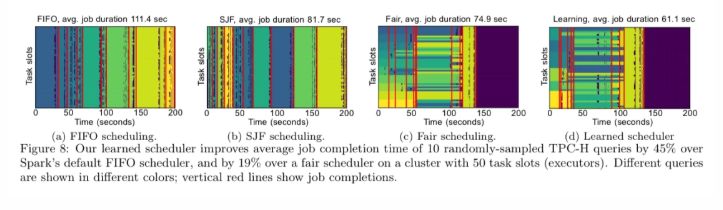
调度器学会的策略是将快速完成短任务与最大限度地提高集群效率相结合,学习在并行性“最佳点”附近运行作业。
传统的查询优化器非常难以构建,维护并且通常会产生次优的查询优化。优化器的脆弱性和复杂性使其成为一个很好的模型可学习的候选者…
最初的实验从传统的成本模型开始,并通过学习进行改进,结果表明模型质量可以得到改善,但要获得大幅收益,则需要对基数估算进行重大改进。目前的研究方向(尚未报告结果)是探索基于混合模型的基数估计方法。这些混合模型结合了底层数据模式和相关性的学习模型,以及使用监听器(exception/outlier)来捕获特定数据实例的极端(和难以学习)异常。
论文提出,未来学习模型可能在以下领域也会被证明是有益的,包括近似查询处理、预测建模和工作负载(包括插入和更新)。
SageDB 提供了一种构建数据库系统的全新方法,通过使用 ML 模型与程序合成相结合来生成系统组件。如果成功,我们相信这种方法将产生新一代大数据处理工具,可以更好地利用 GPU 和 TPU,在存储消耗和空间方面提供显著的优势,在某些情况下甚至可以改变某些数据操作的复杂性。
原文链接:
https://blog.acolyer.org/2019/01/16/sagedb-a-learned-database-system/
论文链接:
http://cidrdb.org/cidr2019/papers/p117-kraska-cidr19.pdf
今日荐文
点击下方图片即可阅读

动辄年薪百万招聘程序员的研究院都是什么来头?
吴恩达 Andrew Ng 发布了一份《人工智能转型指南》,建议公司通过“建立内部 AI 团队”“对员工 AI 技能培训”“制定 AI 战略”等,为企业实现 AI 转型。在 AI 冷静期,我们该怎么将 AI 真正落地到业务是重点工作。7 月 12 日深圳 ArchSummit 全球架构师峰会,将邀请业界专家来解答,包括 AI+ 医疗、AI+ 交通等。
大会 7 折报名中,欢迎咨询票务经理 Lachel- 灰灰,电话 / 微信:17326843116


喜欢这篇文章吗?记得点一下「好看」再走👇


