滴滴研究院副院长叶杰平亲授:大规模稀疏和低秩学习(下)
AI科技评论按:本文根据叶杰平教授在中国人工智能学会AIDL第二期人工智能前沿讲习班【机器学习前沿】所作报告《大规模稀疏和低秩学习》编辑整理而来。以下内容是本次报告的下篇,主要讲解优化的算法、稀疏筛选等问题。本文已经由叶教授亲自矫正。

叶杰平 滴滴研究院副院长 美国密歇根大学终身教授,密歇根大学大数据研究中心管理委员会成员,美国明尼苏达大学博士毕业,现任滴滴研究院副院长。他担任Data Mining and Knowledge Discovery, IEEE Transactions on Knowledge and Data Engineering, IEEE Transactions on Pattern Analysis and Machine Intelligence的编委. 2004年获得ICML最佳学生论文奖。2010年获得NSF CAREER Award。2010,2011,2012年分别获得KDD最佳论文提名,2013年获得KDD最佳学生论文奖。
Part 4、优化的算法

从Lasso到结构的稀疏,再到Trace Norm,我们处理的问题都是连续、不可导的凸问题。那么,大规模的问题怎么去解呢?下面我会讲几个流行的解法,以及一些加速算法。
我们遇到的大部分问题,基本上都可以分解为loss 和penalty。
假设loss是可微的凸问题,penalty是不可导的凸问题,目前主要有以下6种解决方法:
将不光滑的问题转化为光滑的问题,
坐标下降方法,
ADMM算法,
次梯度下降,
梯度下降,
加速梯度下降等等。
下面,我主要讲解坐标下降(Coordinate Descent)以及ADMM和梯度下降三种方法。
1、坐标下降法(Coordinate Descent)

它的思路比较简单,假设模型有100万维,每次都假设N-1个是不动,然后求解这个变化的一维,以此类推一直到收敛。很多大规模的问题用这种方法都能够快速解决。
下面举个例子:
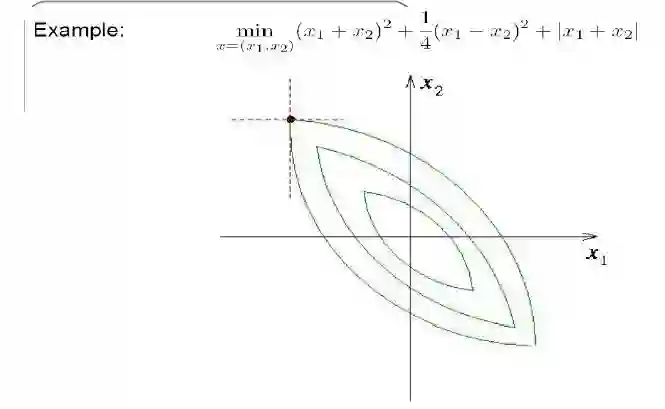
这个两维的函数的最优解是0,这个问题收敛是没有问题的,但它可能会慢一些。但对于一般问题,用CD还要注意一下,它不一定会收敛。
在什么情况下收敛?如果目标函数是光滑而且凸的,就一定会收敛。但很多问题不光滑,比如Lasso就不光滑,那怎么办?如果是不光滑的,只要光滑部分可分就可以了。在很多稀疏问题上,CD是可以保证是收敛的。
总结来说,当问题是光滑且凸的时候,坐标下降算法一定可以收敛,当问题不光滑的时候,当不光滑的部分是可分的,那么坐标下降算法也可以收敛。
坐标下降算法的优点是容易计算,同时收敛很快;缺点是当loss比较复杂时,会很明显的降低速度。
2、交替方向乘子法(ADMM)

假设有两个变量f(x)+g(z),然后给定一个约束,将其放入两组变量,我们可以首先生成增广拉格朗日,再增加penalty,然后就可以通过反复、依次对x、z、y优化,对模型求解。
ADMM对于大规模的问题非常有效,它能够将复杂问题变成很多个较为容易求解的问题。
我们以lasso为例,一个传统的LASSO是有一个loss加一个一范数约束,我们将x变成z,所以约束为z=x,就可以生成如下增广拉格朗日模型:

可以看出,求解x、z、u都非常容易,通过几个简单的更新就能将lasso,一个复杂的非凸问题对齐求解。
因此,ADMM的优点是解释非常简单,对于复杂模型也能够进行有效的处理,同时可以分布式的进行计算,并对低秩可以很快的学习;缺点是收敛比较慢。
3、梯度下降法(Gradient Descent)

梯度下降法可以有效求解光滑问题。通过不断的沿着梯度方向迭代,该方法就能求出凸光滑问题的解。
但是我们需要关注的问题是如何将梯度下降将其推广到非光滑的问题上面,这就要考虑梯度下降算法——
通过换一种表达方式,对其进行低阶的逼近,用一个低阶的taylor展开,做一个一阶的逼近,再利用正则项使得x在可行域范围内,对M函数找到最优的x,然后不断迭代。

通过数学验证可以发现,最优的x刚好等于梯度下降的值,也就是说,这种方式是梯度下降的另外一种表达方式,即将梯度下降转化为了一个有优化问题。
对于稀疏问题,我们每一步只需要最小化M函数和penalty之和。梯度下降的关键问题在于penalty。如果penalty简单,那么每一步最小化问题可能有解析解,如果penalty复杂,那么模型会很复杂,每一步的成本会很大。这个算法的另外一个好处是稍作变化后就可以加速。

Part5、大数据的稀疏筛选(Sparse Screening for Big Data)
刚刚讲了很多优化的解法,比如说CD、ADMM、GD等等,这些可以解小到中型的问题,非常有效,但是对于大规模的数据,做交叉检验,训练,代价就会很高,尤其当模型的特征非常多,模型复杂,并且需要对很多特征进行统计上的验证。
所以,自然的想法是对数据进行约减,将该问题压缩,从而把大问题变为小问题,加速算法。

最近有很多这方面的研究,比如说随机的选择特征,或者用heuristic,通过将相关性大的特征选择出来,从而压缩数据。但这些方法都不能获得精确的结果。这里我介绍一种没有误差的方法。
这种方法的核心思想是,将维度约减之后,保证和不screen之前的解一样。
用lasso做一个例子。假设大部分的特征系数等于零,那么我们可以直接去掉这些特征,从而有效实现对数据的压缩。screen的核心是在不求解lasso的情况下,尽可能找到系数为零的参数,实现对数据压缩。
主要步骤是:
第一步、找到对偶解。Lasso的对偶问题有很好的几何解释,即对数据做一个投影。Lasso 的对偶问题不好求解,但可以通过近似解对数据进行screen;
第二步、将系数可能为零的特征screen掉;
第三步、在小的数据上进行训练。
这样就能快速求解。

从primal到duel有一个KKT。我们给定一个KTT的θ是对偶变量,xi是特征。我们发现,当θx<1时,βi一定等于0,这也是我们需要利用的核心点。但是这里的θ是未知的,因此我们需要找到一个近似解。
当在一个邻域内(最优解在这个邻域内),maxθx<1,那么对应的βi一定等于0。这个邻域越简单、越小越好。
实验发现,在不加入新资源的情况下,这个运算可以加速几百倍,而精度不变化。而且该screen方法可以用在别的模型上,对其进行加速。
上面讲的是当特征很大时,我们要对其进行压缩。但更常见的情况是样本无穷大,但是特征并不多,这时候,我们需要screen样本数量。
比如说SVM,我们需要找到一个超平面,把数据分成两类。其中,最重要的是如何找到支持向量,具体地说,是如何在没有求解svm的时候找到支持向量。

我们的方法是,用screen找到很多非支持向量,去掉对问题没有影响的点,从而对数据进行压缩,快速找到超平面。
LASSO是在挑样本,SVM是用来挑样本,但都是通过screen来操作,去掉无用样本或者特征,问题减少,从而加快速度。
与lasso类似,我们首先要对对偶问题进行预估,然后解两个优化问题,找到一个邻域,从而找到解的判断,加快速度。当然,也会遇到特征和样本都大的问题,这种情况下,我们可以同时对样本和特征进行压缩,而且同时保证解一样。
观众提问
提问:滴滴的车辆在工作时,是如何评判路线好坏的?是用SVM,还是借助先进的视频网络?
叶杰平:路径规划有两种方法,一种是把北京所有道路分成,预测出来所有地方的路况,这样我们就知道任意AB两点需要花费多长时间。这是个很经典的算法。
另外一个是用机器学习预测A、B应该怎么走,方法类似于AlphaGo。用深度增强学习把北京变成一个图,每次找路就像下棋,用增强学习的方法,这个就比较复杂了。
提问:滴滴最重要的机器学习应用是什么?
我主要说下面几个:
第一个是路径规划,就是回答的上一个问题;
第二个是时间,即A到B需要多少时间;
第三是怎么做订单分配。知道时间、距离之后,就要匹配离你最近的乘客;
第四是拼车,即要保证拼车的乘客有好的乘车体验、要思考怎么定价等等。 ;
第五是判责,当遇到突发事件,司机和乘客意见不一致的时候,机器模型要判断是谁的责任。这个时候我们需要挖掘大量特征,尽量还原事情发生时的情况,然后做一个判断。这也是比较复杂,也很重要的一个问题。
以上为叶杰平老师的演讲全文,更多信息请关注“AI科技评论”了解。
AI科技评论招聘季全新启动!
很多读者在思考,“我和AI科技评论的距离在哪里?”,答案就是:一封求职信。
AI科技评论自创立以来,围绕学界和业界鳌头,一直为读者提供专业的AI学界,业界,开发者内容报道。我们与学术界一流专家保持密切联系,获得第一手学术进展;我们深入巨头公司AI实验室,洞悉最新产业变化;我们覆盖A类国际学术会议,发现和推动学术界和产业界的不断融合。
而你只要加入我们,就有机会和我们一起记录这个风起云涌的人工智能时代!
如果你有下面任何两项,请投简历给我们:
*英语好,看论文毫无压力
*计算机科学或者数学相关专业毕业,好钻研
*新闻媒体相关专业,好社交
*态度好,学习能力强
简历投递:
北京:lizongren@leiphone.com
深圳:guoyixin@leiphone.com
温馨提示:NLP实战特训班报名优惠时间只剩下最后一天,预购从速哟!






