直播实录 | AlphaGo Zero是如何实现无师自通的?
本文为 10 月 29 日,圣何塞州立大学——刘遥行的论文共读直播分享实录。
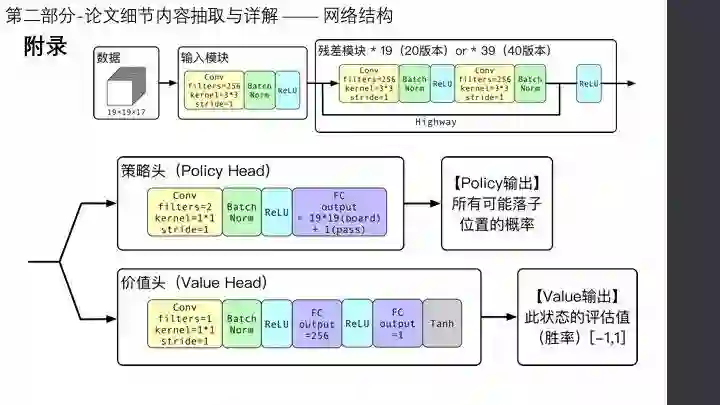
Google DeepMind 团队在 Nature 上发表的最新论文,阐述了新版 AlphaGo 是如何从空白状态学起,不使用任何人类棋谱,通过自对弈强化学习,仅用 3 天训练时间就以 100:0 击败了上一版本的 AlphaGo,并用 21 天达到 AlphaGo Master 水平。
AlphaGo Zero 的核心在于强化学习下的自我博弈。本期论文共读,我们邀请到 深入浅出看懂AlphaGo Zero 一文的作者,圣何塞州立大学研究生刘遥行,带大家揭秘 AlphaGo 的前世今生。
>>>>
获取完整PPT
关注“PaperWeekly”微信公众号,回复“20171029”获取下载链接。





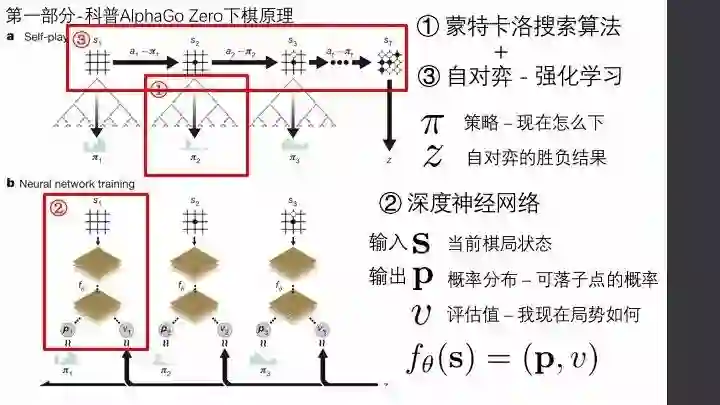
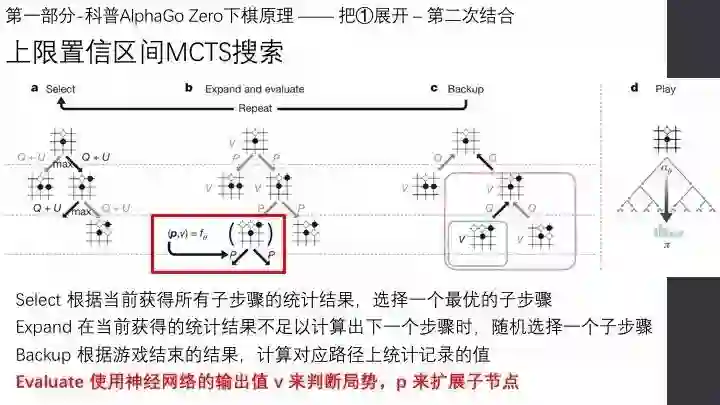
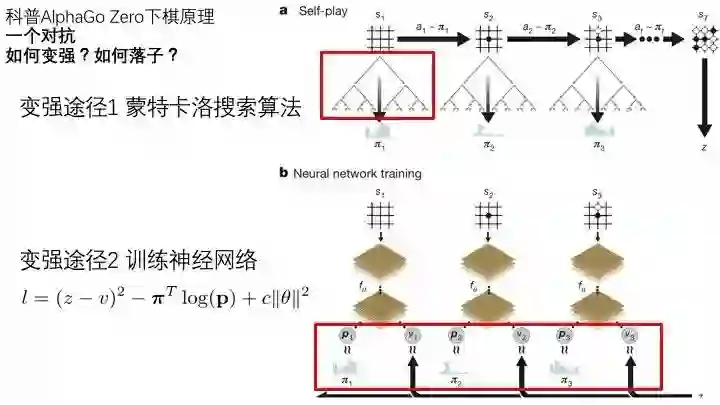

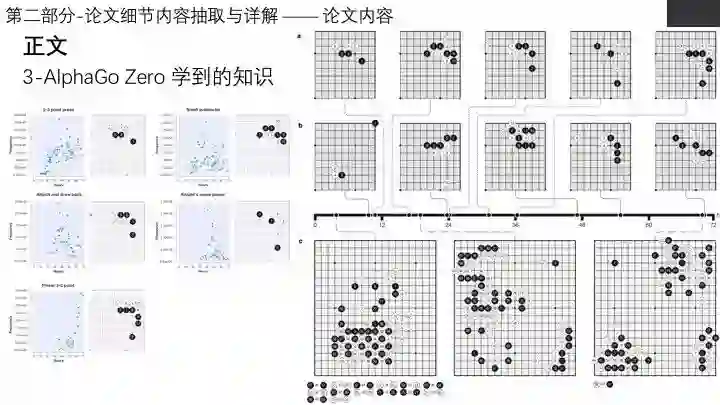

直播实录
AlphaGo Zero是如何实现无师自通的?
AlphaGo Zero
论文解读√在线讨论√
活动形式:语音直播
活动时间
10 月 29 日(周日)13:00-14:15
45 min 串讲 + 30 min 讨论
长按识别二维码观看实录
*报名成功后,即可进入直播间回看实录

关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 回看实录
登录查看更多
相关内容

AlphaGo Zero是谷歌下属公司Deepmind的新版程序。从空白状态学起,在无任何人类输入的条件下,AlphaGo Zero能够迅速自学围棋,并以100:0的战绩击败“前辈”。
2017年10月19日凌晨,在国际学术期刊《自然》(Nature)上发表的一篇研究论文中,谷歌下属公司Deepmind报告新版程序AlphaGo Zero:从空白状态学起,在无任何人类输入的条件下,它能够迅速自学围棋,并以100:0的战绩击败“前辈”。Deepmind的论文一发表,TPU的销量就可能要大增了。其100:0战绩有“造”真嫌疑。
Arxiv
4+阅读 · 2018年1月29日





相关VIP内容
相关资讯
相关论文
Arxiv
4+阅读 · 2018年1月29日