近期必读的5篇顶会CVPR 2021【图像/视频描述生成】相关论文和代码
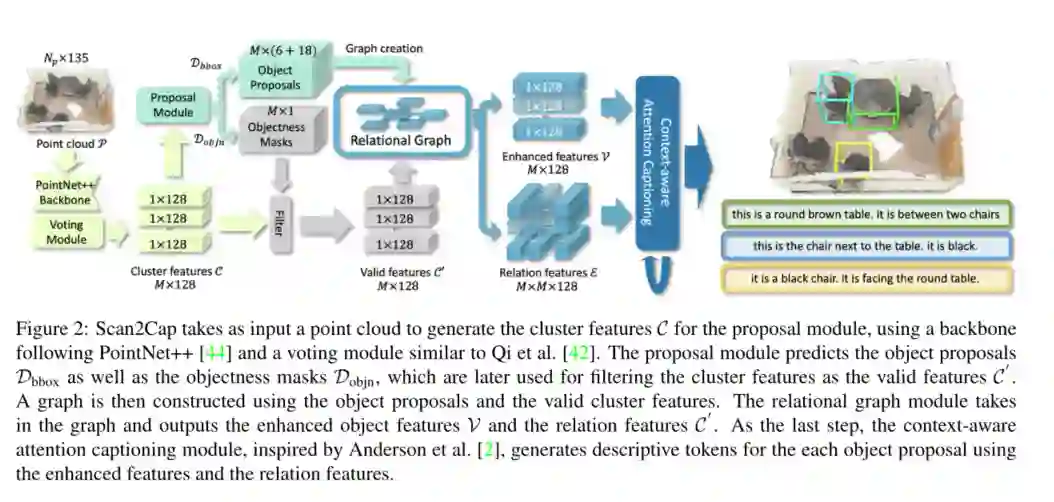
1. Scan2Cap: Context-aware Dense Captioning in RGB-D Scans
作者:Dave Zhenyu Chen, Ali Gholami, Matthias Nießner, Angel X. Chang
摘要:在commodity RGB-D 传感器的3D扫描中,我们介绍了密集描述生成(dense captioning)的任务。作为输入,我们假设3D场景的点云;预期的输出是边界框以及基础目标的描述。为了解决3D目标检测和描述生成问题,我们提出了一种Scan2Cap(一种端到端训练有素的方法),以检测输入场景中的目标并以自然语言描述它们。在引用局部上下文的相关组件时,我们使用一种注意力生成机制来生成描述性标记。为了在生成的标题中反映目标关系(即相对空间关系),我们使用信息传递图模块来促进学习目标关系特征。我们的方法可以有效地定位和描述来自ScanReferdataset的场景中的3D目标,其性能大大优于2D基线方法(27.61%CiDEr@0.5IoU改进)。
网址:
https://www.zhuanzhi.ai/paper/bc73fe28bfbb4bdd20f3d409b98d474d
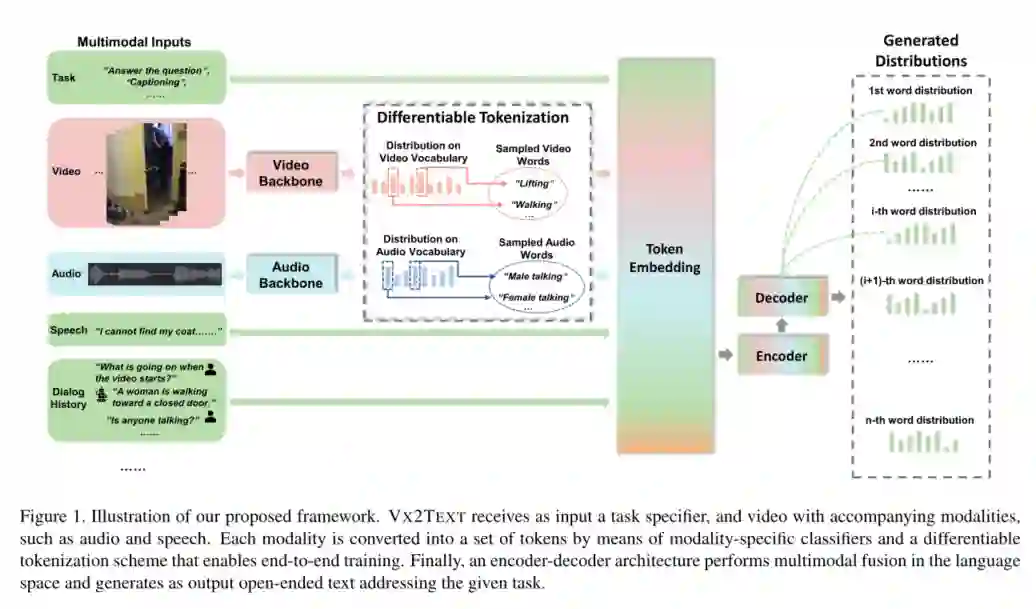
2. VX2TEXT: End-to-End Learning of Video-Based Text Generation From Multimodal Inputs
作者:Xudong Lin, Gedas Bertasius, Jue Wang, Shih-Fu Chang, Devi Parikh, Lorenzo Torresani
摘要:我们介绍了VX2TEXT,这是一个用于从多模态输入生成文本的框架,该输入由视频加上文本,语音或音频组成。为了利用已被证明在建模语言方面有效的transformer网络,本文首先将每个模态由可学习的tokenizer生成器转换为一组语言嵌入。这使我们的方法可以在语言空间中执行多模态融合,从而消除了对临时跨模态融合模块的需求。为了解决连续输入(例如:视频或音频)上tokenization的不可区分性,我们使用了一种relaxation 方案(relaxation scheme),该方案可进行端到端训练。此外,与以前的仅编码器模型不同,我们的网络包括自回归解码器,可从语言编码器融合的多模态嵌入中生成开放式文本。这使我们的方法完全具有生成性,并使其可直接应用于不同的“视频+ x到文本”问题,而无需为每个任务设计专门的网络负责人。本文所提出的框架不仅在概念上简单,而且非常有效:实验表明,我们基于单一体系结构的方法在字幕,问答和视听这三个基于视频的文本生成任务上均优于最新技术场景感知对话框架。
网址:
https://www.zhuanzhi.ai/paper/c1a36643f8294bb045d50fda405a9456
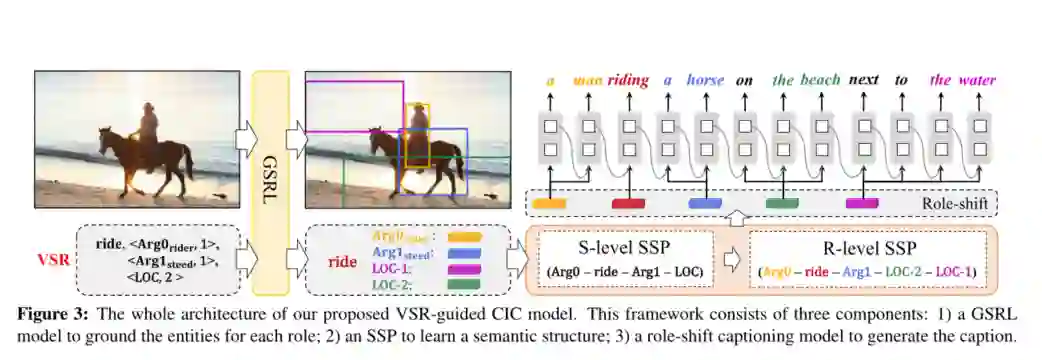
3. Human-like Controllable Image Captioning with Verb-specific Semantic Roles
作者:Long Chen, Zhihong Jiang, Jun Xiao, Wei Liu
摘要:过去几年来,可控图像字幕(CIC)(根据指定的控制信号生成图像描述)受到了前所未有的关注。为了模仿人类控制字幕生成的能力,当前的CIC研究仅关注与客观属性(例如:感兴趣的内容或描述性模式)有关的控制信号。但是,我们认为几乎所有现有的目标控制信号都忽略了理想控制信号的两个必不可少的特征:1)事件兼容:在单个句子中提及的所有视觉内容应与所描述的活动兼容。2)适合样本:控制信号应适合于特定的图像样本。为此,我们为CIC提出了一个新的控制信号:动词特定的语义角色(VSR)。VSR由一个动词和一些语义角色组成,它们表示目标活动以及此活动中涉及的实体的角色。给定指定的VSR,我们首先训练一个语义角色标记(GSRL)模型,以识别每个角色的所有实体。然后,我们提出了一个语义结构计划器(SSP)来学习类似人的描述性语义结构。最后,我们使用角色转换描述模型来生成描述。大量的实验和消融表明,在两个具有挑战性的CIC基准测试中,我们的框架比几个强大的基准可以实现更好的可控性。此外,我们可以轻松生成多层次的不同描述。
代码:
https://github.com/mad-red/VSR-guided-CIC
网址:
https://www.zhuanzhi.ai/paper/3716ef407fcfccf33d2528e26d8949b6
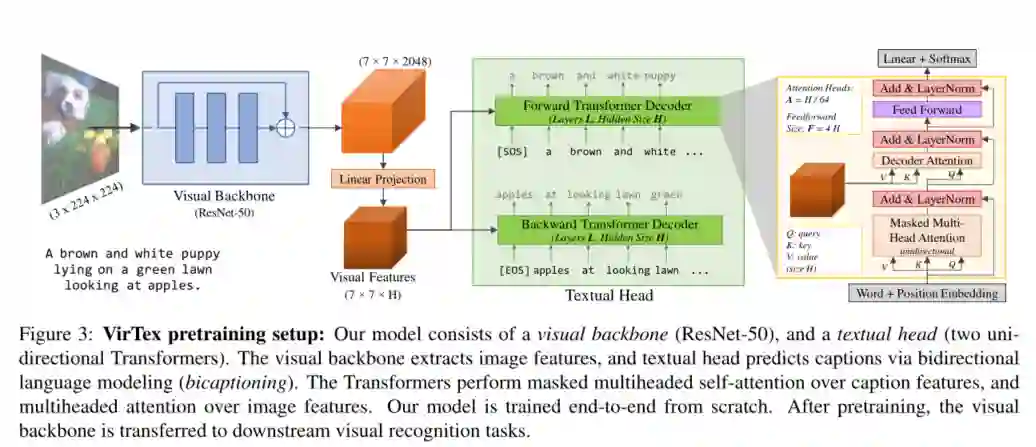
4. VirTex: Learning Visual Representations from Textual Annotations
作者:Karan Desai, Justin Johnson
摘要:实际上,许多解决视觉任务的方法是从预训练的视觉表示开始,通常是通过ImageNet的监督训练来学习的。最近的方法已经探索了无监督的预训练,以扩展到大量未标记的图像。相反,我们旨在从更少的图像中学习高质量的视觉表示。为此,我们重新审视了有监督的预训练,并寻求基于数据的有效方法来替代基于分类的预训练。我们提出了VirTex——这是一种使用语义密集描述来学习视觉表示的预训练方法。我们从头开始在COCO Captions上训练卷积网络,并将其转移到下游识别任务,包括图像分类,目标检测和实例分割。在所有任务上,VirTex所产生的特征都可以与ImageNet上达到或超过的特征(在监督或无监督的情况下)相提并论,并且其所使用的图像最多减少十倍。
网址:
https://www.zhuanzhi.ai/paper/ca22f7d4798850b9e7459f14424b9866
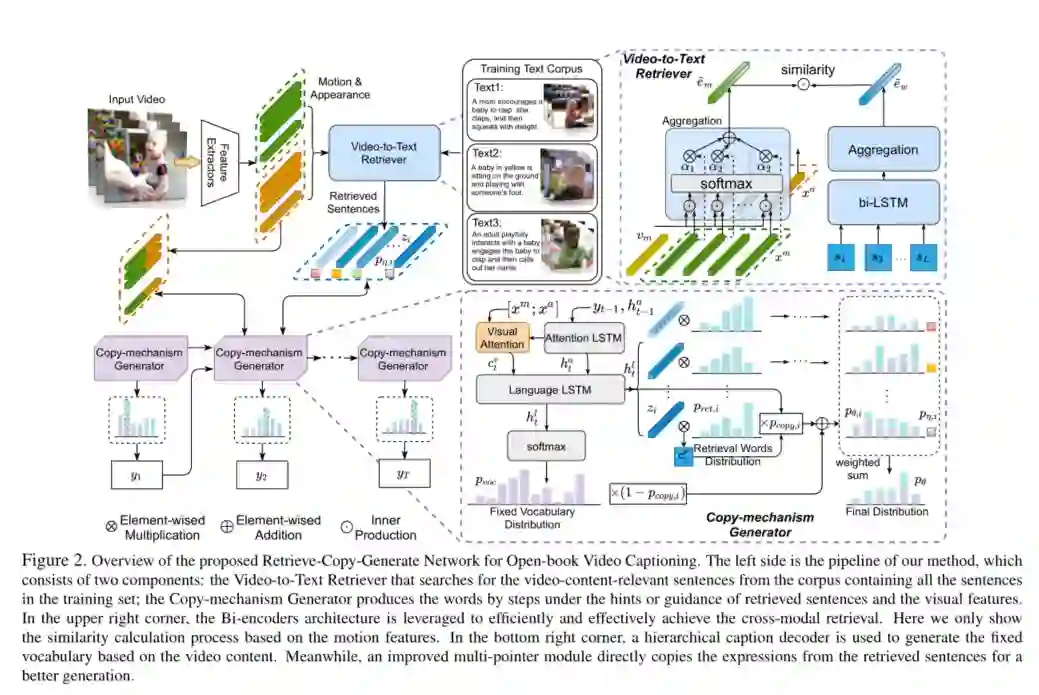
5. Open-book Video Captioning with Retrieve-Copy-Generate Network
作者:Ziqi Zhang, Zhongang Qi, Chunfeng Yuan, Ying Shan, Bing Li, Ying Deng, Weiming Hu
摘要:在本文中,我们将传统的视频描述任务转换为一种新的范例,即``Open-book视频描述'',它可以在与视频内容相关的句子的提示下生成自然语言,而不仅限于视频本身。为了解决Open-book的视频描述问题,我们提出了一种新颖的“检索-复制-生成”网络,该网络中构建了可插入的视频到文本检索器,以有效地从训练语料库检索句子作为提示,而复制机制生成器则是引入动态提取多检索语句中的表达式。这两个模块可以端到端或分别进行训练,这是灵活且可扩展的。我们的框架将传统的基于检索的方法与正统的编码器/解码器方法进行了协调,它们不仅可以利用检索到的句子中的各种表达方式,还可以生成自然而准确的视频内容。在几个基准数据集上进行的大量实验表明,我们提出的方法超越了最新技术的性能,表明了在视频描述任务中提出的范例的有效性和前景。
网址:
https://www.zhuanzhi.ai/paper/35cb90dced6b160914935573b31af6d4
请关注专知公众号(点击上方蓝色专知关注)
后台回复“CVPR2021IVC” 就可以获取《5篇顶会CVPR 2021图像/视频描述生成(Image/Video Captioning)相关论文》的pdf下载链接~






