CVPR 2019开源论文 | 基于“解构-重构”的图像分类学习框架

作者丨白亚龙
单位丨京东AI研究院研究员
研究方向丨表示学习、图像识别
基于深度卷积图像识别的相关技术主要专注于高层次图像特征的理解,而对于相似物体之间的细节差异和具有判别意义的区域(discrimination region)的定位和识别上仍有较大提升空间。而具有判别意义的局部区域的精细特征表示恰恰是解决精细图像分类任务的关键。例如,对于『花』的分类、『鸟』的分类,人类专家可以凭借其自身专业知识仅根据目标局部特征就可以区分细微差别的目标。
受此启发,本文提出了一种全新的基于“解构-重构”(Destruction and Construction Learning, DCL)的图像分类学习框架,来强化神经网络对于“专家”知识的学习。
在 DCL 框架中,除去基本的标准分类骨干网络(Backbone)以外,我们引入了两个全新的模块:解构模块以及重构模块。其中解构模块通过区域混淆机制(Region Confusion Mechanism, RCM)将图像中物体的结构信息进行“破坏”,即将原始图片划分为多个子区域,并对其进行随机打乱。通过将无物体结构信息的信号输入到骨干网络中的方式,迫使分类网络必须更多地关注具有判别意义的局部子区域来发现差异。
同时为了避免 RCM 引入的噪声视觉特征模板,我们使用能区分原始图像和破坏图像的对抗性损失,对噪声图像特征加以区分。最后,经过骨干网络得到的图像特征信息,会再一次经过“重构”模块,该模块使用一个区域对齐网络对被破坏掉的图像中的局部区域之间的语义相关性进行建模,试图恢复局部区域原本的空间布局(结构重建)。
通过这种自监督信号,我们在不需要使用额外监督信号的情况下,强化了分类网络对于具有判别意义子区域的特征表示学习。最终,DCL 在多个精细物体识别任务中取得 state-of-the-art 的性能,且在 CVPR 2019 FGVC 比赛中获得两项第一名(商品识别、蝴蝶蛾类识别)以及一项第二名(菜品识别)。
另外,值得注意的是,我们的方法非常轻量化,只在训练阶段两个新引入模块只带来了少量的可学参数,且在测试(实际模型部署、生产环境下)阶段只激活基本分类网络分支,非常具有实用性。
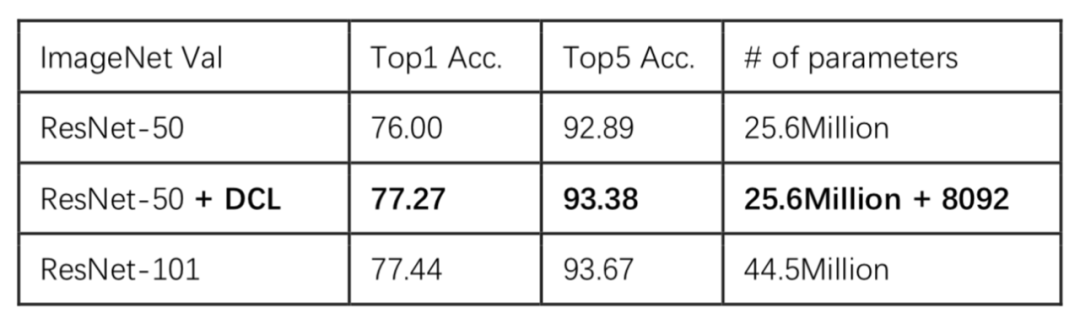
另外我们还将 DCL 算法拓展到通用物体识别任务中。实验结果表明,在只新增 8092 个参数(相当于 ResNet-50 的 0.03% 的参数规模)的情况下,基于 DCL 的方法在 ImageNet-1K 任务上可以将 ResNet50 的性能提升至 ResNet-101 的水准。

引言
在之前的工作中,为了提升精细类目上的物体识别模型的性能,研究人员提出了多种不同的方法。这些方法大致可以被分为两类:
基于目标物体检测以及目标物体分类的分步识别框架
基于注意力模型的识别框架

如上图所示,(a) 主要依靠目标物体检测模型从图像中提取目标物体图像与背景图像信息进行区分,然后再基于目标物体图像的特征进行分类。方法 (a) 主要是考虑去掉背景信息对于物体分类带来的干扰。
而 (b) 对应的基于注意力模型的系统,则依靠大量额外参数来学习目标物体在图像中的注意力得分,从而在图像中对目标物体主体与背景区分,或者对目标物体的各个不同部分进行区分。
综合上述技术,不难看出现有的面向精细物体识别的目前的方法主要都是基于将背景信息与目标物体的视觉信息进行区分,避免引入背景信息干扰的思路。但是众所周知,区分精细类目的关键在于对于局部的细微视觉差异以及全局的整体物体轮廓的综合考量。这类方法并不能直接优化局部细微视觉差异的识别。另外,上述的方法都需要引入大量额外的运算。
本文提出的分类算法,在不使用额外数据标注和额外测试结构的前提下,强化局部精细特征的学习,从而达到保证实际部署环境下计算资源消耗不变甚至是更小的情况下大幅提升精细图像识别的准确率。
方法
本文提出的基于“解构-重构”的分类模型框架图 2 所示。需要注意的是,在 DCL 的目标是强化 Classification Network 分支的学习,其他新引入的分支在 test 阶段不参与运算。所以在实际模型部署、生产环境下不会引入额外的计算和存储消耗。
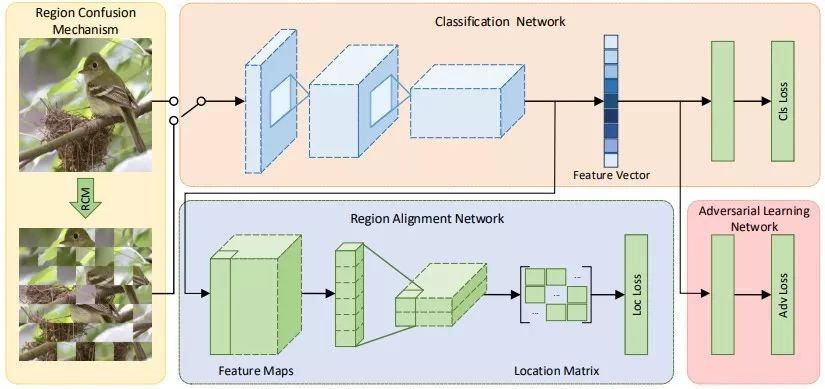
▲ 图2. DCL分类框架图
如图 2 所示,DCL 中主要包含以下四个主要模块:
1. 解构模块(Region Confusion Mechanism):将图像划分为若干个子区域,并进行一定范围内的随机扰乱(如图 3 所示),在通过将子区域的空间位置顺序进行随机打乱,迫使分类模型只基于局部图像特征对图像进行识别,从而提升了分类模型对于局部图像细节特征的表征能力。

2. 分类模块(Classification Network):分类模型被训练能够同时将扰乱后的图像和原图分类正确。而将扰乱后图像分类正确则需要分类模块可以有效的对图像中涉及识别类别的关键区域检测到并学习到其精细特征表示。这种特征表示会反过来提升原图上分类模型的准确率。同时无用的背景信息通过这种随机扰乱的方式变的杂乱无规律,且分类模块无法只基于背景视觉信息进行区分,进一步消减了复杂背景信息对于分类的负面影响。
3. 特征对抗模块(Adversarial Learning Network):该模块基于分类模块得到的特征向量判断输入的图片是原图还是扰乱的图片。如果我们将原图中的特征表示与扰乱图中的特征表示看成两个不同领域的特征表示,公有的分类模块决定了这两个不同领域中的特征空间中间是有一定重合的,这部分重合主要是关于局部关键区域的图像特征,而原图独有的特征表示主要是关于全局图片中整理轮廓的,最后扰乱图独有的特征表示则大多是关于一些噪声的视觉模板的(因为扰乱图像会引入视觉噪声)。如图 4 所示,这里通过特征对抗模块,将这三类特征表示加以区分,避免了噪声特征表示对于原图分类时的影响。
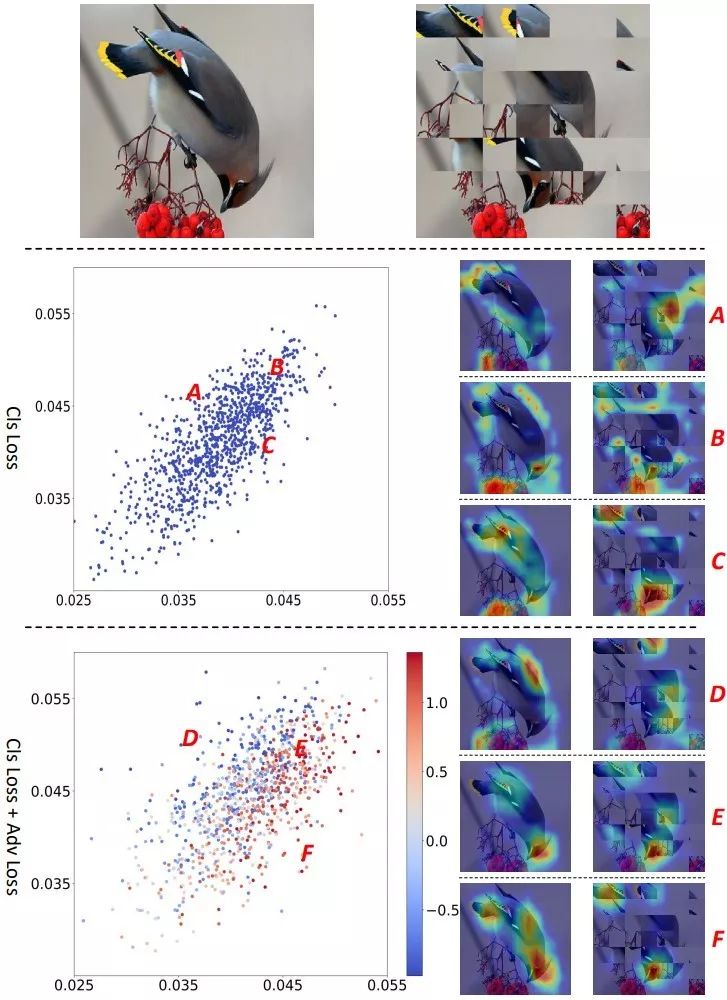
4. 重构模块(Region Alignment Network):该模块基于分类模块输出的特征图,来预测各个图像子模块在原图中的坐标位置。通过该模块的约束,使得分类模块加强了对于局部图像的语义信息表示的能力。即迫使分类模块对图像有了更加深入的理解,诸如物体结构的组成以及物体各个子结构之间的相互关系等。
实验
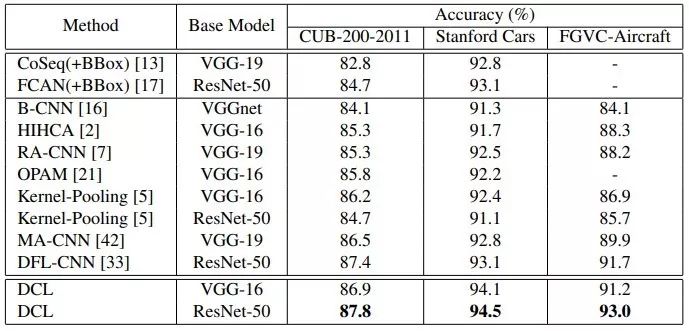
我们在精细物体分类的多个数据集上取得了 state-of-the-art 的性能:
DCL 还在 imageNet-1K 任务上取得了非常显著的提升:
基于 DCL 的算法框架在 CVPR 2019 FGVC 比赛中取得两项第一名(backbone的选择从 ResNet50, SEResNet,ResNeXT 到 SEResNext,均证明了 DCL 的有效性)。分别是:
iMaterialist Challenge on Product Recognition
Fieldguide Challenge: Moths & Butterflies
结论
整体与细节同样重要,本文提出的 DCL 分类框架,强化了分类网络对于物体细节特征认知的同时,保留了原有其高层视觉表征能力,从而大幅提升了物体识别准确率。DCL 作为一个训练过程“轻量化”,测试过程“零负担”的全新分类学习框架,已经被证明可以同时适用于精细物体分类和通用物体识别,且可以有效嵌入到各种不同的基础分类网络结构中。
专注于图像识别、检测以及深度理解。在物体分类、Scene Graph 关系建模、视觉问答、图像生成、跨领域学习、半监督学习等多个方向上取得良好进展。多篇论文被 CVPR、ICCV、ECCV 等顶会录用。并在包括 CVPR 2019 FGVC 在内的多项国际学术竞赛中取得第一名的成绩。
工作内容:
以学术研究为主,配合工程落地;
探索计算机视觉领域尤其是图像识别与理解的各种前沿问题,推动领域创新;
针对各种实际应用场景提供最优算法方案。
岗位要求:
中国及海外知名高校计算机科学,电子信息工程,数学,统计学或相关专业学历;
全职实习期 3 个月以上,需要导师开具外出实习同意函;
精通 Python,有 PyTorch 开发经验,编程能力强,编程习惯好;
能根据项目需求熟练使用和改进常用人工智能算法;
符合以下条件者加分:
可稳定实习 6 个月以上;
在计算机视觉领域顶级会议如 CVPR、ICCV、ECCV 等投稿过论文;
在权威学科竞赛上作为核心成员获得过前三名以上的成绩;
有国内外知名 AI 研究院工作经验。
发送简历至 baiyalong@jd.com,并请注明具体申请岗位。邮件建议标题格式为姓名-学校-计算机视觉算法工程师-实习(paperweekly)。
点击以下标题查看更多往期内容:
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 下载论文 & 源码



