NIPS 2018 | 哪种特征分析法适合你的任务?Ian Goodfellow提出显著性映射的可用性测试
选自arXiv
作者:Julius Adebayo、Ian Goodfellow等
机器之心编译
参与:Geek AI、张倩
显著性方法被广泛应用于突出输入中与学到的模型的预测结果相关的特征。现有的显著性方法通常是以图像数据的视觉吸引作为指导的。本文提出了一种可行的方法来评估一个给定的方法能够/不能提供什么样的解释。研究发现,仅仅依赖于视觉的评估可能会产生一些误导性的结果。通过大量实验,研究人员证明了一些现有的显著性方法独立于模型和数据生成过程。因此,在本文测试中表现较差的方法不能够胜任那些对数据或模型敏感的任务。
随着机器学习的复杂度和影响力不断提升,许多人希望找到一些解释的方法,用于阐释学得模型的重要属性 [1, 2]。对模型的解释可能有助于模型满足法规要求 [3],帮助从业人员对模型进行调试 [4],也许还能揭示模型学到的偏好或其他预期之外的影响 [5, 6]。显著性方法(Saliency method)是一种越来越流行的工具,旨在突出输入(通常是图像)中的相关特征。尽管最近有一些令人振奋的重大研究进展 [7-20],但是解释机器学习模型的重要努力面临着方法论上的挑战:难以评估模型解释的范围和质量。当要在众多相互竞争的方法中做出选择时,往往缺乏原则性的指导方针,这会让从业者感到困惑。
本论文提出了一种基于随机化检验(randomization test)的可行方法来评估解释方法的性能。作者在神经网络图像分类任务上分析了一些显著性方法。实际上,本论文提出的方法论适用于任何解释方法。而且本文提出的随机化检验是很容易实现的,可以帮助人们评估某个解释方法对手头任务的适用性。
研究者在大量实验研究中,将该方法论应用到了大量现有的显著性方法、模型架构和数据集上。令人吃惊的是,一些被广泛采用的显著性方法是独立于训练数据和模型参数的。因此,这些方法对依赖模型的任务(如调试模型)或依赖数据显示出的输入和输出之间关系的任务没有太大帮助。
为了说明这一点,图 1 将标准显著性方法的输出和一个边缘检测器的输出进行了对比。边缘检测器不依赖于模型或训练数据,但它会产生与显著图(saliency map)在视觉上相似的结果。这表明,基于视觉效果的检查方法在判断某种解释方法是否对底层的模型和数据敏感时指导意义较差。
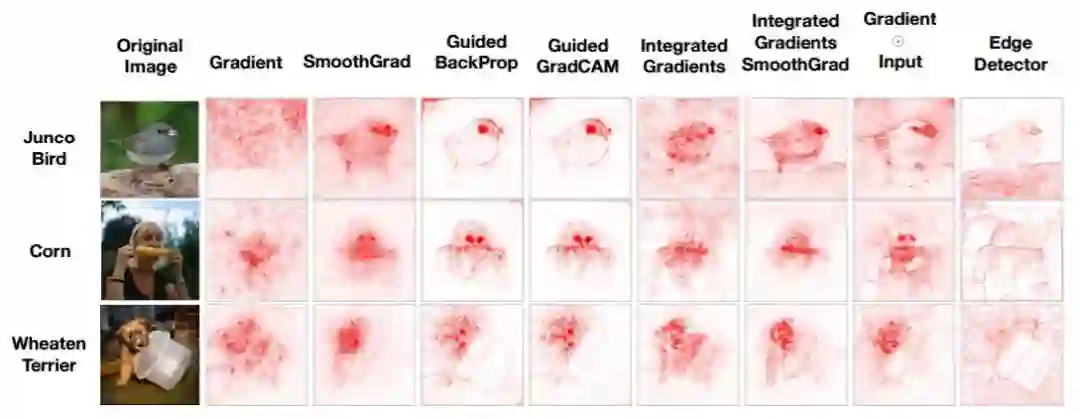
图 1:一些常用方法与边缘检测器的显著图对比。上图显示了在 ImageNet 上训练的 Inception v3 模型 3 个不同输入的显著性掩码(saliency mask)。可以看到边缘检测器产生的输出与一些显著性方法的输出极为相似。实际上,边缘检测器也可以产生突出与模型类别预测相关特征的掩码。有趣的是,研究者发现与边缘检测器最类似的显著性方法(即 Guided Backprop 及其变体)对本研究的随机化检验最不敏感。
本论文提出的方法源于统计随机化检验,它将自然实验和人为的随机试验进行了对比。研究者重点关注通用框架的两种实例化:模型参数随机化检验及数据随机化检验。
模型参数随机化检验将显著性方法在训练好的模型上的输出与显著性方法在一个随机初始化的、结构相同的未训练网络上的输出进行对比。如果显著性方法依赖于模型学习到的参数,我们应该期望它的输出在这两种情况下会有很大的差异。但是,如果输出类似,我们可以推断出显著性映射对模型的属性(本例中为模型参数)是不敏感的。特别地,显著性映射的输出对于诸如模型调试这样不可避免地依赖于模型的任务是没有帮助的。
数据随机化检验将应用于在带标签的数据集上训练的模型的显著性方法与应用于架构相同但是在我们随机排列所有标签的数据集副本上训练的模型的显著性方法进行了对比。如果显著性方法依赖于数据标签,我们也应该期望它的输出在这两种情况下会有很大的差异。然而,显著性方法对重新排列的标签的不敏感表明,该方法不依赖于实例(例如图像)和原始数据中存在的标签之间的关系。
从更大的范畴上说,任何解释方法都遵循一系列不变的特性,即不改变方法的输出的数据和模型的变换。如果我们发现了一种不符合当前任务需求的不变特性,我们可以拒绝该方法。因此,我们的测试可以看作是实际部署方法之前要执行的可用性测试。
本文的贡献:
我们提出了 2 种易于实现的具体检验方法,用于评估解释方法的范围和质量:模型参数随机化检验和数据随机化检验。这两种检验方法可以广泛应用于各种解释方法。
我们对不同的数据集和模型架构上应用的解释方法进行了广泛的实验。并发现一些被检验的方法独立于模型参数和训练模型所使用的数据的标签。
因此,我们的发现表明,那些在我们提出的测试中表现不好的显著性方法没有能力为那些需要对任何模型和数据都适用的解释方法的任务提供支持。
我们通过一系列对于线性模型和一个简单的 1 层卷积求和池化(sum pooling)架构的分析来说明我们的发现,同时也与边缘检测器进行了对比。
论文:Sanity Checks for Saliency Maps

论文链接:https://arxiv.org/pdf/1810.03292v1.pdf
摘要:显著性方法已经成为了一种流行的工具,被用于突出输入中被认为与学到的模型的预测结果相关的特征。目前研究人员提出的显著性方法通常是以图像数据的视觉吸引作为指导的。本文提出了一种可行的方法来评估一个给定的方法能够提供/不能提供什么样的解释。我们发现,仅仅依赖于视觉的评估可能会产生一些误导性的结果。通过大量的实验,我们证明了一些现有的显著性方法独立于模型和数据生成过程。因此,在我们的测试中表现较差的方法不能够胜任那些对数据或模型敏感的任务(例如找出数据中的异常值、解释输入和模型学到的输出之间的关系以及对模型进行调试)。我们通过与图像的边缘检测器(一种既不需要训练数据也不需要模型的技术)进行类比对我们发现进行说明。线性模型和单层卷积神经网络场景下的理论能够支持我们实验中的发现。
研究方法和相关工作
在本文提出的方法的形式化定义中,输入为向量 x ∈ R^d。模型描述了一个函数 S : R^d → R^C,其中 C 是分类问题中的类别数。解释方法会提供一个解释映射 E : R^d → R^d,它将输入映射到形状相同的物体上。
现在,我们将简要描述一下我们所研究的一些解释方法。文章的补充材料包含了对这些方法更加深入的概述。我们的目的不是详尽地评估所有先前的解释方法,而是要强调我们的方法如何应用于一些我们很感兴趣的案例。
对输入 x 的梯度解释(gradient explanation)是 E_grad(x) = ∂S/∂x [21, 7]。梯度量化了在每个输入维度上的变化量会在输入的一个小的邻域内如何改变预测结果 S(x)。
梯度输入。另一种形式的解释是输入和梯度之间的内积,记做 x·∂S/∂x,它可以解决「梯度饱和」问题并减少视觉扩散 [12]。
积分梯度(IG)也通过对标准化后的输入求和来处理梯度饱和问题。对于输入 x 的 IG 可以表示为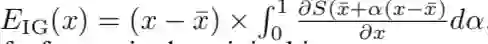
导向反向传播(GBP)[8] 建立在解释方法「DeConvNet」[9] 的基础上,并且和负梯度向设置为 0 、通过 ReLU 单元进行反向传播的梯度解释相一致。
由 Selvaraju 等人 [18] 提出的导向 GradCAM 解释对应于 DNN 最后的卷积单元的特征映射组成的分类得分(logit)的梯度。对于像素级力度的 GradCAM,可以通过元素积与导向方向传播结合在一起
SmoothGrad(SG,平滑梯度)[15] 试图通过对输入的带噪声的副本的解释进行平均,以减少显著性映射的噪声、缓解视觉扩散现象 [13,12]。对于给定的解释映射 E,SmoothGrad 被定义为 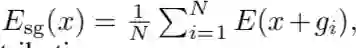
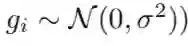
模型参数的随机性检验
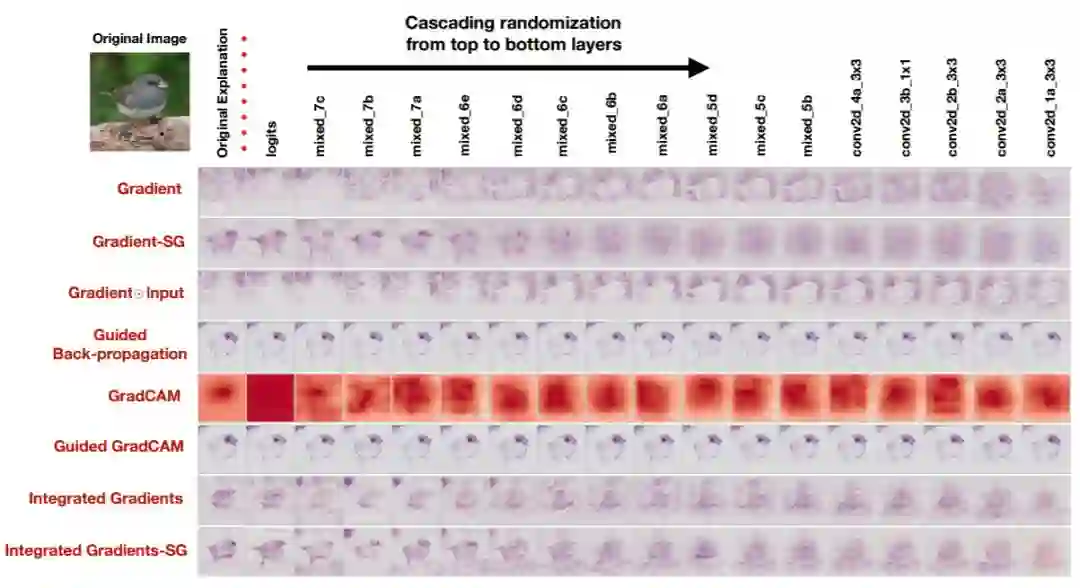
图 2:在 Inception v3(ImageNet)上的级联随机性。此图显示了 Junco 鸟的原始解释结果(第一列)以及每种解释类型的标签。从左到右的过程显示了网络权值(以及其他可训练的变量)全部的随机性,直到包含「块」。我们展示了随机性的 17 个块。坐标(Gradient,mixed_7b)显示的是从 Logits 开始直到 mixed_7b 的顶层已经被重新初始化的网络的梯度解释。最后一列对应于一个权值完全重新初始化的网络。更多示例请参见附录。
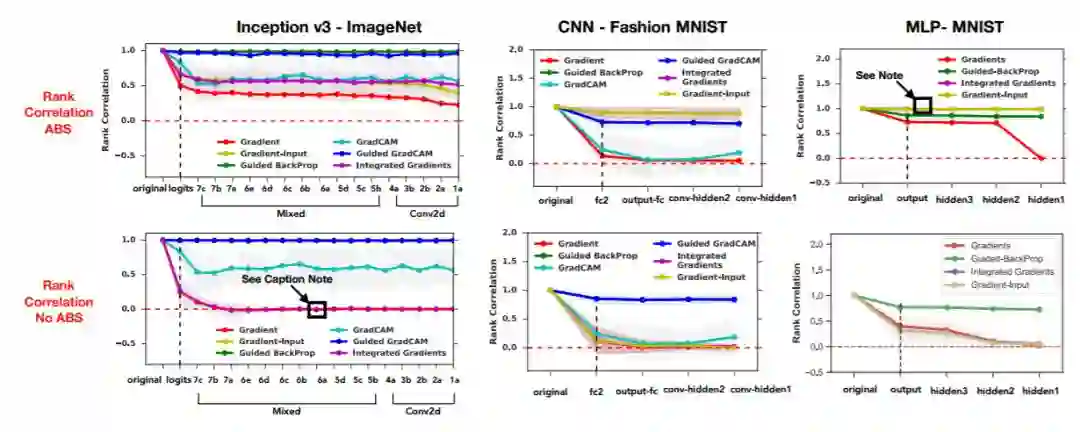
图 3:级联随机性。对于 ImageNet 上的 Inception v3 模型、 Fashion MNIST 数据集上的卷积神经网络、MNIST 数据集上的多层感知机的从顶层开始的权值连续重初始化过程。在所有的图中,y 坐标是原始解释和由直到该点所代表的层/块的随机性所推导出的随机解释之间的秩相关性,而 x 坐标则与 DNN 从输出层开始的层/块相对应。黑色的虚线代表网络的连续随机化由此开始,它处于模型的顶层。上面一排是带绝对值的 Spearman 秩相关性,下面一排是不带绝对值的 Spearman 秩相关性。说明:对于不带绝对值的 ImageNet 上的 Inception v3 模型,积分梯度、梯度输入和梯度重合。对于 MNIST 数据集上的多层感知机模型,积分梯度和梯度输入重合。
数据的随机性检验
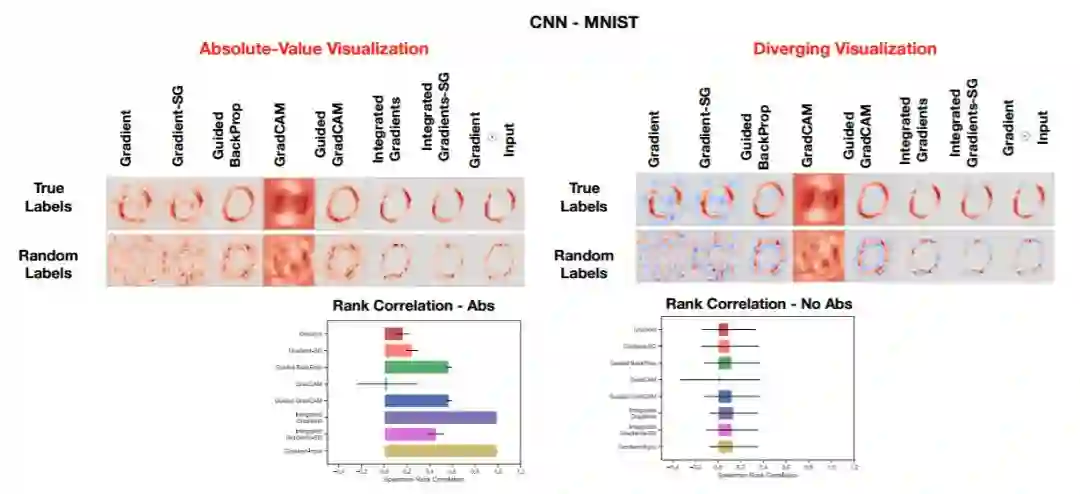
图 5:对真实模型和用随机标签训练的模型的解释的对比。左上角:将 用于卷积神经网络的 MNIST 测试集中数字 0 的掩膜的绝对值可视化结果。右上角:用各种颜色显示的用于卷积神经网络的 MNIST 测试集中数字 0 的显著性掩膜。

图 21:对 Corn 进行独立随机性测试
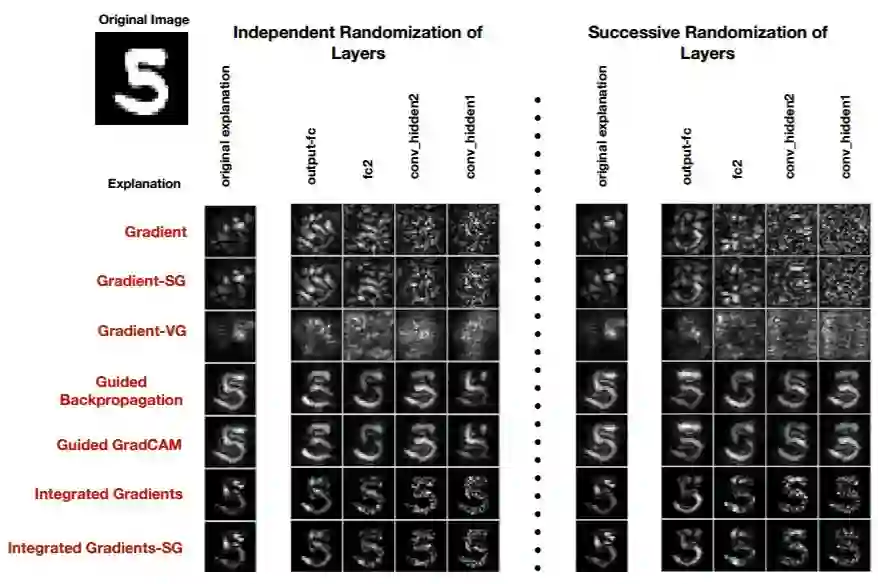
图 23:对在 MNIST 数据集上训练的 CNN 分别进行独立、连续的重初始化工作。

图 27:应用在一维卷积求和模型上的显著性方法。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com

