学界 | 全局最优解?为什么SGD能令神经网络的损失降到零
选自 arXiv
机器之心编译
参与:思源
昨日,reddit 上一篇帖子引发热议,该帖介绍了一篇关于梯度下降对过参数化神经网络影响的论文,该论文只用单个非常宽的隐藏层,并证明了在一定条件下神经网络能收敛到非凸优化的全局最优解。这是对深度学习的复古?到底是否有效?社区中很多人对此发表了看法。机器之心简要介绍了该论文,更详细的推导过程与方法请查看原论文,不过这样的证明读者们都 Hold 住吗。
用一阶方法训练的神经网络已经对很多应用产生了显著影响,但其理论特性却依然成谜。一个经验观察是,即使优化目标函数是非凸和非平滑的,随机初始化的一阶方法(如随机梯度下降)仍然可以找到全局最小值(训练损失接近为零)。令人惊讶的是,这个特性与标签无关。在 Zhang 等人的论文 [2016] 中,作者用随机生成的标签取代了真正的标签,但仍发现随机初始化的一阶方法总能达到零训练损失。
关于神经网络为什么能适应所有训练标签,人们普遍认为是因为神经网络过参数化了。例如,Wide ResNet [Zagoruyko and Komodakis] 使用的参数数量是训练数据的 100 倍,因此必须存在一个这种架构的神经网络,能够适应所有训练数据。然而,这并不能说明为什么由随机初始化的一阶方法找到的神经网络能够适应所有数据。目标函数是非凸和非平滑的,这使得传统的凸优化分析技术在这种情况下没有用。据我们所知,理论只能保证现有的方法收敛到一个驻点 [Davis et al., 2018]。
在本文中,作者将解释这一令人惊讶的现象,即带有修正线性单元(ReLU)激活函数的两层神经网络能收敛到全局最优解。形式化的,我们可以考虑有以下形式的神经网络:
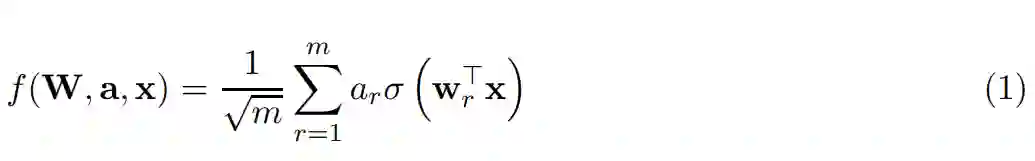
其中 x ∈ R^d 为 d 维实数向量输入,w_r ∈ R^d 为第一层的权重向量,a_r ∈ R 为输出权重。此外,σ (·) 表示 ReLU 激活函数:σ (z) = z if z ≥ 0、 σ (z) = 0 if z < 0。
随后我们可以根据二次损失函数(欧式距离)定义经验风险最小化问题,若给定 n 笔数据的训练集 {(x_1, y_1), ..., (x_i, y_i), ..., (x_n, y_n) },我们希望最小化:
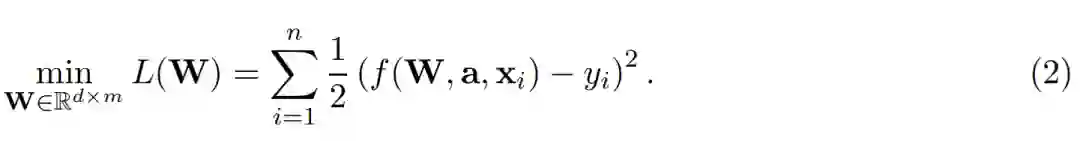
为了实现经验风险最小化,我们需要修正第二层并针对第一层的权重矩阵应用梯度下降(GD):
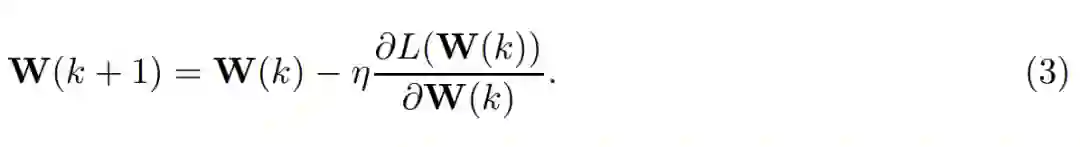
其中η > 0 为学习率(在本论文中为步长),因此每一个权重向量的梯度计算式可以表示为:
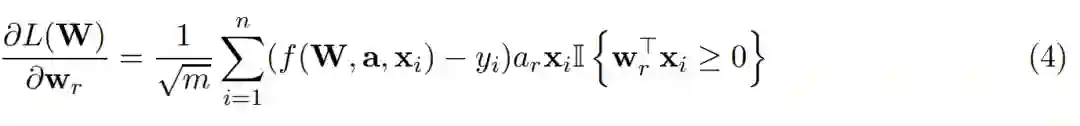
尽管这只是一个浅层全连接网络,但由于使用了 ReLU 激活函数,目标函数仍然是非凸和不平滑的。不过即使针对这样简单的目标函数,为什么随机初始化的一阶梯度方法能实现零的训练误差仍然不太清楚。实际上,许多先前的研究工作都在尝试回答这个问题。他们尝试的方法包括损失函数面貌分析、偏微分方程、算法动力学分析或最优传输理论等。这些方法或研究结果通常都依赖于标签和输入分布的强假设,或者并没有明示为什么随机初始化的一阶方法能实现零的训练损失。
在这一篇论文中,作者们严格证明了只要 m 足够大,且数据是非退化的,那么使用适当随机初始化的 a 和 W(0),梯度下降能收敛到全局最优解,且收敛速度对于二次损失函数是线性的。线性速率也就是说模型能在 K = O(log (1/ε)) 次迭代内搜索到最优解 W(k),它能令 L(W(K)) ≤ ε。因此,作者理论结果并不仅仅展示了全局收敛性,同时还为达到期望的准确率提供了量化的收敛率。
分析技术概览:
首先作者直接分析了每一次独立预测的动力学特征,即 f(W, a, x_i) for i = 1, . . . , n。他们发现预测空间的动力学是由格拉姆矩阵(Gram matrix)谱属性决定的,且只要格拉姆矩阵的最小特征值是下界,那么梯度下降就服从线性收敛速度。
其次作者观察到格拉姆矩阵仅和激活模式相关(ReLU 输入大于零的情况),因此他们就能使用矩阵微扰分析探索是否大多数的模式并没有改变,因此格拉姆矩阵仍然接近于初始化状态。
最后作者发现过参数化、随机初始化和线性收敛联合限制了权重向量 w_r 仍然接近于初始值。
最后作者根据这三个观察结果与方法严格证明了他们的论点,此外他们还表示整个证明仅使用了线性代数与标准概率边界,因此能推广到其它深度神经网络。以下我们展示了他们证明出的两个定理(Theorem 3.1 和 Theorem 4.1),证明过程请查阅原论文。
论文:Gradient Descent Provably Optimizes Over-parameterized Neural Networks

论文链接:https://arxiv.org/abs/1810.02054
摘要:神经网络一个最神秘的地方是梯度下降等随机初始化的一阶优化方法能实现零的训练损失,即使目标函数是非凸和不平滑的。本论文揭秘了这一现象,即带有 ReLU 激活函数的两层全连接网络为什么能实现零的训练损失。对于有 m 个隐藏神经元的浅层神经网络(ReLU 激活函数)和 n 项训练数据,我们的实验表示只要 m 足够大,且数据是非退化的,那么随机初始化的梯度下降能收敛到全局最优解,且收敛速度对于二次损失函数是线性的。
我们的分析基于以下观察:过参数化和随机初始化联合限制了每一个权重向量在所有迭代中都接近于它的初始值,这令我们可以利用比较强的类凸属性,并展示梯度下降能以全局线性的速率收敛到全局最优解。我们相信这些观点同样能用于分析深度模型和其它一阶梯度优化方法。
3 连续型时间分析
本章展示了分析梯度流(gradient flow)的结果,即将步长设置为无穷小量的梯度下降。在后一部分的离散型时间分析中,我们将进一步修正这一部分的证明,并为带正下降步长的梯度下降设定一个定量边界。
形式化而言,我们考虑常微分方程,公式如下所示:
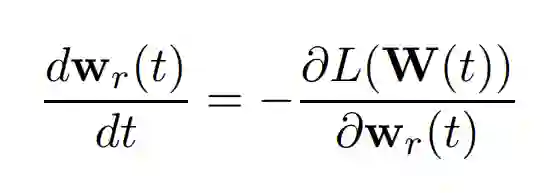
其中 r 属于 1 到 m。我们将 u_i(t) = f(W(t), a, x_i) 指定为输入 x_i 在时间 t 上的预测,u(t) = (u_1(t), . . . , u_n(t)) ∈ R^n 指定为时间 t 上的预测向量。本章的主要结果见以下定理:
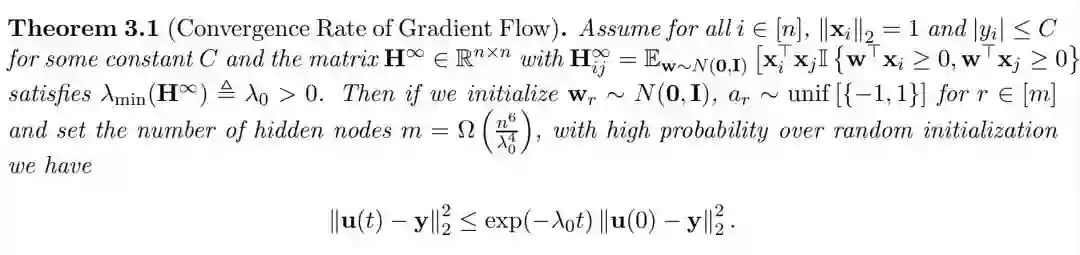
4 离散型时间分析
本章展示了具有正常数项步长的随机初始化梯度下降以线性速率收敛到全局最小值。我们首先介绍主要定理:

定理 4.1 表明,即使目标函数是非平滑和非凸的,具有正常数步长的梯度下降仍然具有线性收敛速度。我们对最小特征值和隐藏节点数的假设与梯度流定理完全相同。值得注意的是,与之前的研究 [Li and Liang, 2018] 相比,我们对步长的选择与隐藏节点 m 的数量无关。
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com




