三维感知与三维数据分析最新进展 - 3D传感&人工智能前沿科技论坛

AI 科技评论按:我们生活在一个三维立体的世界,三维信息的感知也就总是一件有趣的事,三维感知也能带来比平面感知带来更多信息。全民 AR / VR /立体视觉的热潮虽然暂时过去了,但这个领域的学术研究和学术交流还在持续进行着。

1 月 23 日,学术交流活动「AI 之眼,智见未来——3D 传感&人工智能前沿科技论坛」在深圳南山举行。论坛由奥比中光承办,中国自动化学会模式识别与机器智能专委会、中国人工智能学会模式识别专委会主办,指导单位是深圳市南山区科技创新局。论坛邀请了清华大学、浙江大学、国防科技大学、上海交通大学、厦门大学、四川大学、北京航空航天大学等知名大学的7位顶尖专家学者发表主题演讲,分享他们在三维计算机视觉领域的最新科研成果,也给参会的各知名 AI 企业的技术骨干、科研机构重要研发人员、相关专业的高校学生等提供了一个交流讨论的机会。

参会专家合影留念
论坛承办方奥比中光是深圳的 3D 感知技术企业,提供软件、硬件的全套解决方案。OPPO Find X 手机上使用的三维人脸识别模组就来自奥比中光。借着承办论坛的机会,奥比中光的许多研发技术人员在座聆听并参与讨论。多位演讲嘉宾在论坛间隙参观了奥比中光的展厅,而后在演讲中提到不同企业的 3D 感知解决方案间的对比时也对奥比中光表示了认可。
AI 科技评论记者现场参与了全天的学术交流活动,我们把七个论坛报告的梗概内容介绍如下。

奥比中光联合创始人 & CTO 肖振中,深圳市南山区科协常务副主席张汉国,中国自动化学会模式识别与机器智能专委会副秘书长、合肥工业大学计算机与信息学院副研究员贾伟发表开幕致辞,预祝论坛成功。
刘烨斌 - 「人体动态重建技术前沿」

论坛第一个学术报告来自清华大学自动化系副教授、博导刘烨斌。他的报告题目是「人体动态重建技术前沿」。报告对人体动态重建这一研究课题,围绕便捷性和实时性两大目标的学术界相关研究成果回顾了技术发展历程,做了全方位的技术介绍。

刘烨斌副教授首先介绍了人体动态重建课题中的一些基本概念。在人体动态重建中,需要捕捉的信息有三维的几何+纹理,还有它们的运动;运动包括几何体表面的运动和内部骨架的运动。

人体动态重建技术的应用包括:全息通信与全息直播,三维虚拟试衣,智能便捷娱乐(信息采集重建、便携发布),自由视角视频,实时三维运动捕捉,高精度数字内容记录与制作等。
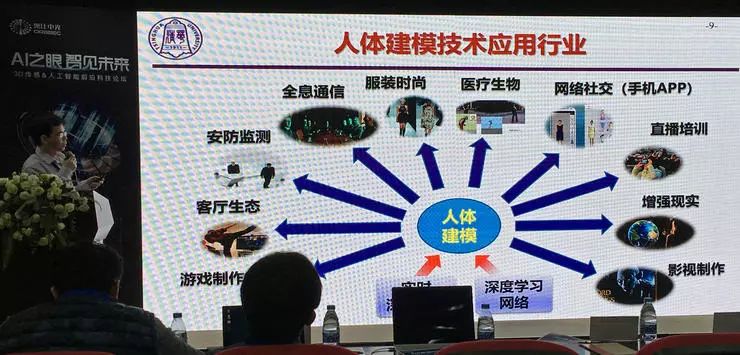
人体建模需要的核心技术是实时深度数据采集以及深度数据处理。
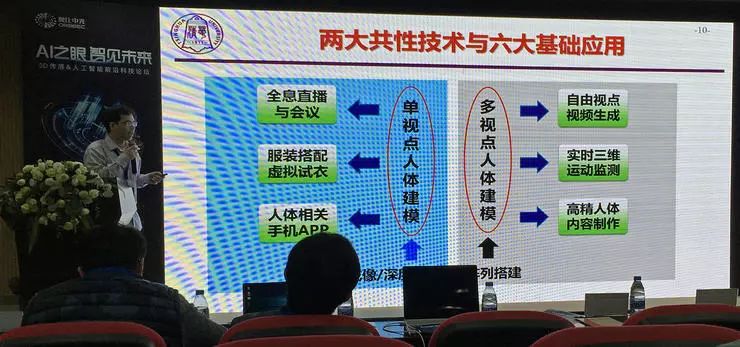
根据输入数据不同,可以分为单视点人体建模和多视点人体建模两大共性技术,对应六大基础应用。刘烨斌副教授从十几年前开始做这方面的研究,单视点、多视点技术都有涉及。
人体动态重建技术可以分成几类:

早期的做法是不做先验约束,基于多视角数据求取点云;

然后发展出了基于三维模版的方法,这类方法需要先人工建立骨架模版或非刚性形变模版(作为先验),三维点云的求解可以依托模版,降低了求解的难度、提高了稳定性;

基于统计模版的方法无需提前由人工建模,系统根据数据学习统计模版然后应用。这种方法的问题是难以重建复杂几何拓扑形状的表面,比如裙子等。

最后还有表面动态融合的方法,用深度相机采集点云并进行融合。
刘烨斌副教授介绍了重建技术中的六大目标:精准重建、规模采集(多人,大采集范围)、便捷获取、实时计算、语义建模(以便建模后结果的迁移)、真实生成。

精准重建需要复杂的相机阵列+多光照,需要采集大量的高精度数据。刘烨斌副教授的早期研究就是在精准重建方面,他们设计了包含 40 个相机、680 个光源的采集装置。精准重建对采集设备体系的高要求也限制了它的实际应用。

规模采集的难点在于处理多视角交叠的区域,也就是紧密交互的人体动作,比如左图中三人腿部交叉。有更多视角、更高精度的采集系统自然可以更好地处理交叠区域,但这同时又限制了系统采集的规模(人数以及空间大小)。

多红外相机(多视角)的动态三维重建可以进行实时的点云融合,解决拓扑变化难题;单深度相机则无法支持拓扑变化与快速运动。图中研究动态融合重建的论文《DynamicFusion: Reconstruction and Tracking of Non-rigid Scenes in Real-Time》获得了 CVPR 2015 的最佳论文奖。
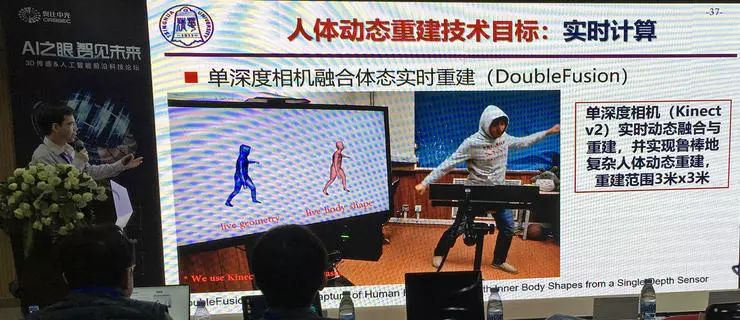
刘烨斌副教授团队在此基础上进行了改进,他们用单深度相机实现实时动态融合重建,不使用模版,可以支持和物体交互,可以任意视点重建。最新成果可以鲁棒地进行复杂人体动态重建,3x3米采集空间,5%到10%测量精度。

下一个技术目标是便捷获取,其中一种是从单个相机视角进行动态三维重建。这时需要先扫描获得静态人体模版(具体做法可以是在镜头前以指定动作原地转一圈),计算得到人体模型,之后用单个相机的视频输入就可以追踪动作并进行重建。不过这有较高的计算复杂度,精度也有限。

另一种便捷获取任务是从单图像恢复体态模型,通过对图像深度的学习重建体态模型以及同步恢复纹理。刘烨斌副教授团队的近期工作 DeepHuman 有着不错的效果。

语义建模是对人体与服装分离建模,这样可以进行转移(把一个人的衣服转移到另一个人身上),但同时还要保留高度的真实感。这样,对象建模的内容就包括了纹理、几何、材质、物理动力学属性等等。衣物的物理动力学建模始终是一大挑战。在刘烨斌副教授团队的研究成果中,他们先采集人体模型,经过计算后以单视角输入,服装可以独立解析,然后为服装加入动力学仿真,服装背侧使用动力学计算生成;光影也可以重新重新布置。
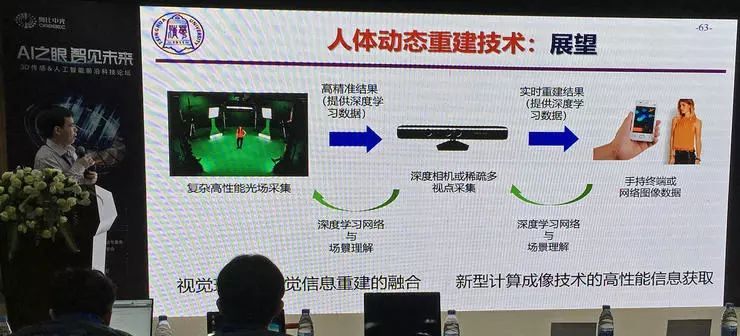
最后,刘烨斌副教授介绍了自己对这项课题的展望。
卢策吾 - 「Behavior Understanding meets 3D Representation」

上午的第二个学术报告来自上海交通大学研究员、博导卢策吾。他演讲的主题是三维表征以及行为理解(Behavior Understanding meets 3D Representation),主要介绍了自己团队在这两个方向上的几项近期工作。

卢策吾的演讲内容主要分为两个部分,介绍了自己团队对三维表征以及对行为感知的一些研究成果。
三维表征部分

首先对于三维表征,一种基础的框架是取点的表征,PointNet 就是一种常用的方法,但它无法编码不同的点之间的关系。

对于临近的点表征问题,PointNet 和 PointCNN 有各自的处理思路,但也有各自的不足。

对于点的结构的表征,有一些特点是我们希望它具备的,比如尺度不变性,比如空间方向编码(从而可以在不同方向进行卷积)。SIFT 算子的引入就可以保留这些信息。
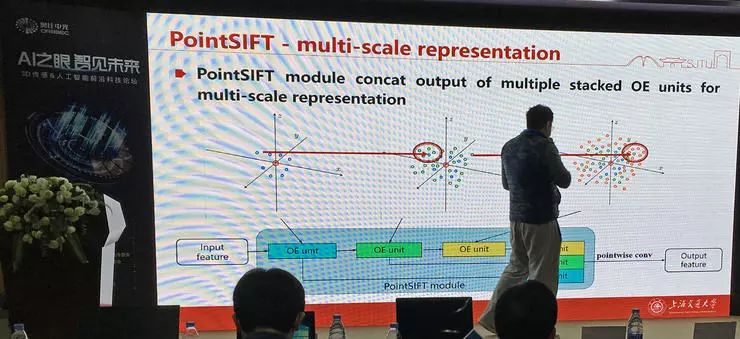
卢策吾团队提出的 PointSIFT 就是利用了 SIFT 算子的一种多尺度表征方式,克服了 PointNet++ 只取最近邻的问题。
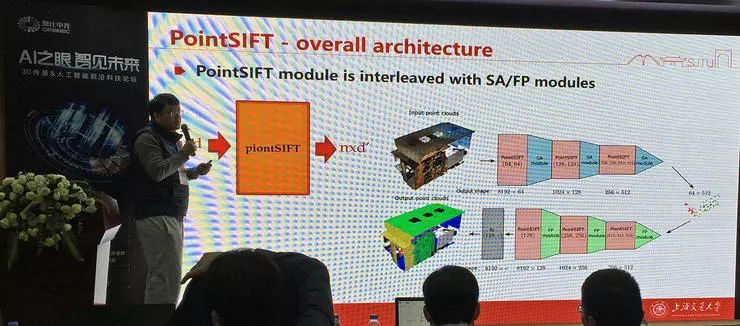
对于网络架构的设计,他们使用了一个类似 U-Net 的结构,尺度先减小后增加。网络有自动尺度选择能力,其中也可以使用不同的模块设计。PointSIFT 在多种测试中都取得了优秀的表现。
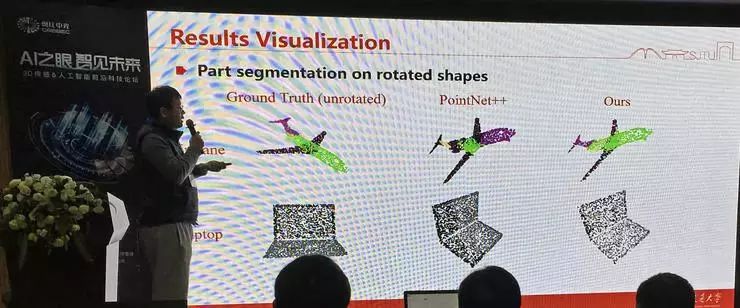
下一个问题是点的表示在空间旋转不变性方面的表现。在基于点云的物体部件分割任务中,PointNet++ 一般能取得不错的效果,但是由于方法的设计没有考虑空间旋转不变性,对于旋转/未见过的角度就效果不好。

PointNet 中的处理思想是寻找点到点之间的对应关系,但对应关系并不具有旋转不变性;另一种思路是把点云映射到球面上,这样具有了旋转不变性,但点与点之间的对应关系就无法保留,这是球面 CNN 的做法。
卢策吾团队提出的 Pointwise Rotation-Invariant Network 就结合了点对点方法和球 CNN 的优点,在有空间旋转的情况下也取得了良好表现。
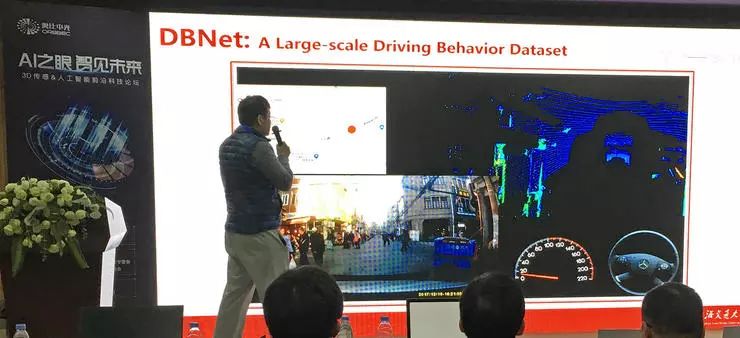
卢策吾还介绍了基于三维点云的端到端自动驾驶学习方面的计划。他和其他研究人员合作采集了一个包含视频、激光雷达点云、驾驶员行为的驾驶数据集 DBNet,对应的论文《LiDAR-Video Driving Dataset: Learning Driving Policies Effectively》也被 CVPR 2018 收录。在这个数据集上训练端到端自动驾驶系统,就是把三维点云(或者二维录像)作为输入,通过模型预测人类驾驶员会有怎样的驾驶行为。
目前这个数据集已经被 Facebook、谷歌、NVIDIA 等企业以及 MIT、斯坦福、CMU 等学校使用,卢策吾未来还计划依托这个数据集在 ICCV 2019 举办大规模 SLAM 比赛以及在 CVPR 2020 举办大规模驾驶数据分割比赛。
行为识别部分

报告的第二部分是关于行为识别。此前他们的实时姿态估计系统 AlphaPose 兼具高表现和高运行速度,在学术研究和应用实践中都非常火热,许多工业界企业都向他们购买了使用许可。不仅如此,AlphaPose 还可以作为许多不同领域、面向多类不同物体的通用型关键点检测器。

提出 AlphaPose 之后,卢策吾团队关注的下一个难题是密集姿态检测。相比于稀疏分布的物体的姿态检测(比如 COCO 数据集中的图像),密集人体识别实际上已经是另一种问题,它的难点在于不同目标的互相遮挡形成同构噪声,所以人密集时各种算法的表现都有明显的下降。

卢策吾团队提出一个新的 CrowdPose 数据集,其中有大量密集人体场景,带来很大的挑战。传统物体检测方法此时就误报率高,关节检测容易错误。

根据卢策吾介绍,同样是基于热力图辨别人体,传统方法中对于主体和障碍物的置信度取值是二值化的,这样的后果就是临近主体的障碍物在辨别时容易取而代之。
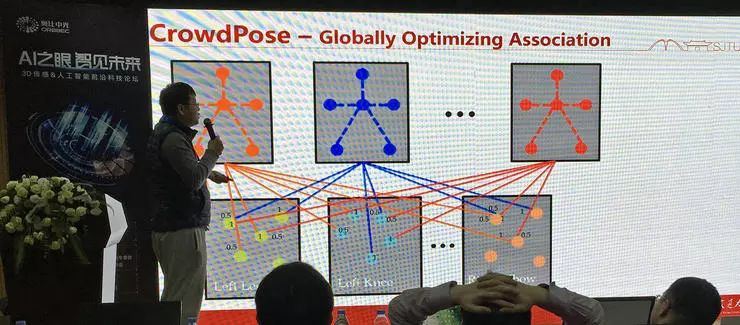
他们提出的新方法中不再使用二值化的取值,并且用竞争式的框选择整体优化,从而得到更好的表现。

运动识别的下一个问题是时间序列图像作为输入的识别。序列输入我们很容易想到使用 RNN,但它难以直接用于图像输入的检测。卢策吾团队提出的方法是深度 RNN 架构的时序模型:RBM,它可以看作是一种通用型的 LSTM/RNN,根据一定条件简化后就得到了我们熟悉的 LSTM。这种方案可以做到 15 层甚至更深的 RNN 叠加。
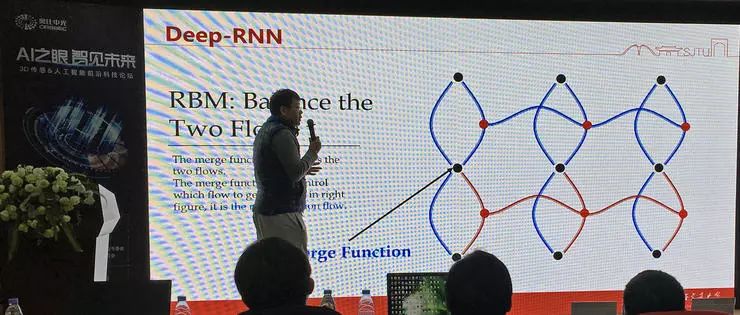
他们的改进思路是:时序信息和特征分别学习;先学习空间表征,再让表征在时间上流动(两个方向的流动在图中用两个方向的连线表示)。

为了便于网络的训练,他们提出了 Temporal Dropout 等训练加速技巧。在实验中也取得了表现的明显提升。

物体间的交互关系也是运动识别中需要关注的重要方面。卢策吾团队提出的一种思路是把「是否有交互」的二值信息利用起来,辅助判断交互类型,起到用先验信息提高整体性能的效果。这也是一种通用可迁移到 Inter-Actioness Prior。
总结
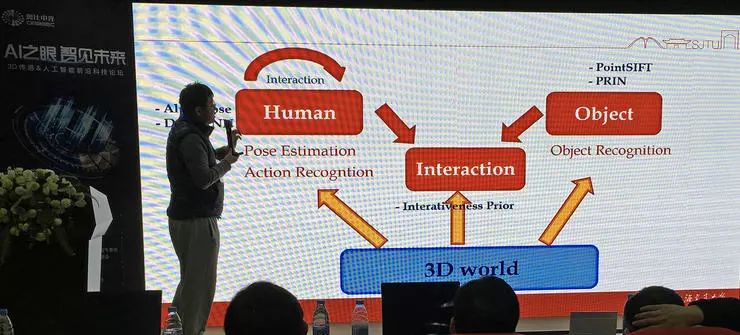
卢策吾认为,目前虽然在运动理解和三维表征方面都各自有不少的研究成果,但它们之间的结合还很少,还没有产生有潜力的成果,这是未来的一个可能的方向。

目前的技术可以做交互判断,而学习到的交互关系可以发展推理引擎。在这里卢策吾展示了一个视频,一个机械臂可以在与三维物体的互动(尝试抓取)中学习先验。对三维世界的理解可以辅助机器人工作,机器人与世界的交互也可以增进视觉理解。

对于整个 AI 范围的总体看法,卢策吾认为目前我们取得了明显成果的都属于 Physical AI(视觉、语音、图像、机器人),这些技术确实可以解决大多数问题;而未来更大的挑战在于对抽象概念的理解和运用。
章国锋 - 「视觉 SLAM 技术及应用」

浙江大学 CAD&CG 国家重点实验室教授、博导章国锋的报告主题是「视觉 SLAM 技术及应用」。报告中综述介绍了视觉定位地图重建跟踪技术及应用的各方面研究工作。
基础知识与技术

SLAM,同时定位与地图构架,是机器人和计算机视觉领域的基本问题。
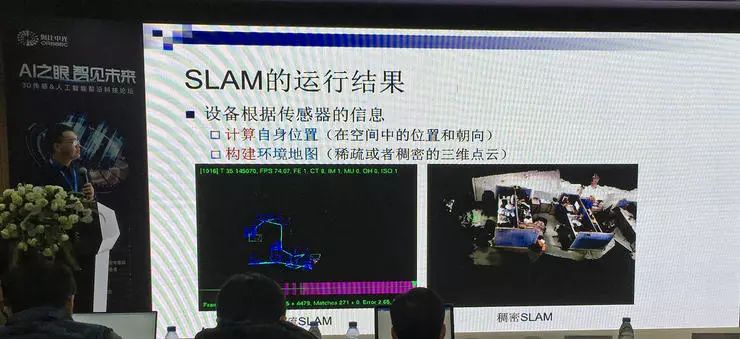
SLAM 技术的运行结果要计算设备自身在空间中的位置和朝向,同时还要构建周围环境的地图。根据构建的环境地图包含的信息不同,可以分为稀疏 SLAM 和稠密 SLAM,前者只包含三维点云,后者同时也要采集重建几何和纹理。
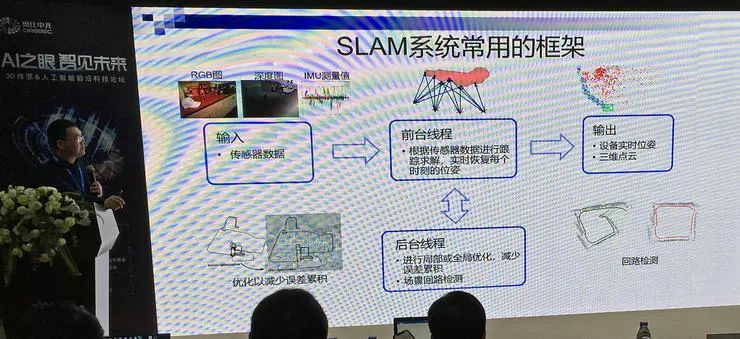
经过几十年的发展,SLAM 系统常用的技术框架已经基本成熟,主要可以分为输入、前台线程、后台线程、输出四个组成部分。

视觉 SLAM 自然是以视觉输入为主,单目、双目、多目摄像头方案都有。如今也可以结合其他的辅助传感器的信号,进一步提高解算精度。
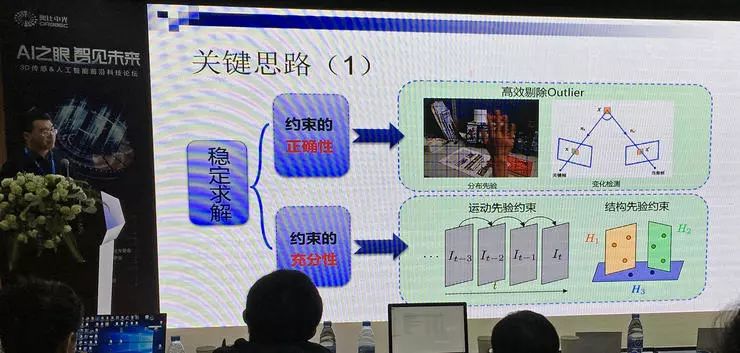
视觉 SLAM 从视觉信号输入,重建场景三维信息的基本原理是多视图几何方程求解。不过,高效、稳定的求解有一定难度,尤其在动态 SLAM 中,场景在变化,有outliner,甚至场景有遮挡。章国锋教授介绍了几个关键思路。
视觉 SLAM 研究工作
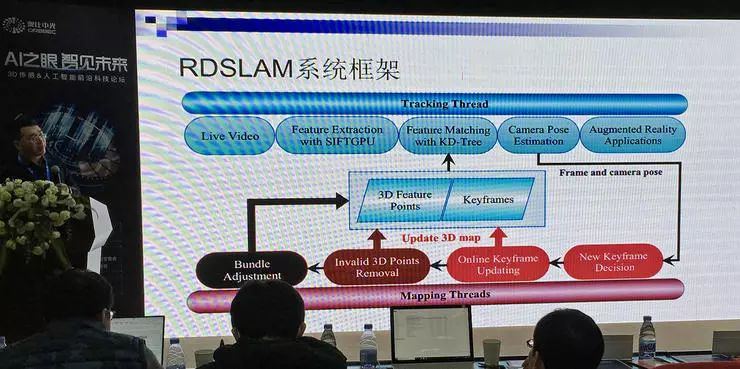
章国锋教授设计的视觉 SLAM 解决方案是 RDSLAM。这个系统可以根据实时视频信号输入检测、追踪场景中的动态变化。

相比于更传统的基于滤波器的 SLAM 方法,基于关键帧的方法有较多优点,但对强旋转很敏感。RDSLAM 就是一种基于关键帧的方法。

机器人领域的应用中大量使用视觉惯性 SLAM,就是结合机器人 IMU (惯性测量单元)采集的数据计算视角运动,在它的帮助下提高鲁棒性。那么没有搭载 IMU 的设备能否借鉴这种思路呢?由于绝大多数情况下摄像头的移动线速度较低(米/秒 级),影响不大,重点计算角速度即可,章国锋教授认为这种思路是可行的。也就是在没有真实 IMU 数据时,通过采集的数据数据模拟计算 IMU 数据。
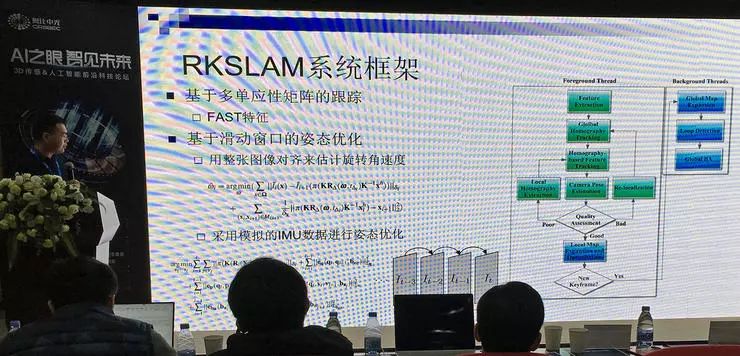
根据这个思路,他们针对移动场景提出 RKSLAM。
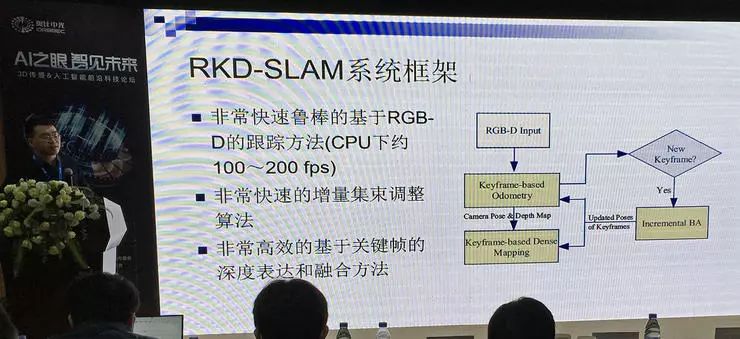
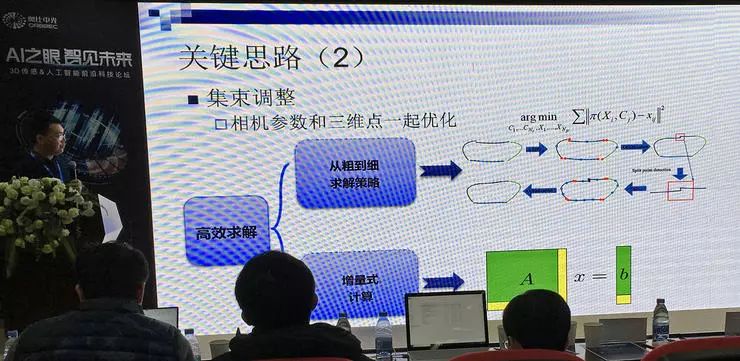
而后还衍生出基于 RGB-D 输入系统的视觉 SLAM 系统 RKD-SLAM,除 RGB 视觉信息之外增加的深度信息可以大幅提高鲁棒性,得以实现非常快速的增量集束调整;基于关键帧的重融合,消除累积误差;其中还使用了多种降低计算复杂度的方法,速度可以快一个数量级。
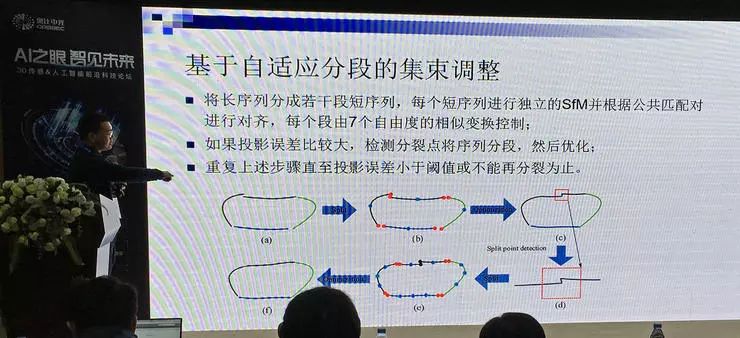
章国锋教授着重介绍了系统中使用的集束调整方法,把长序列分成多个短序列,分段优化,收敛快。在演示视频中,章国锋教授在自家小区中一边行走,一边随意用手机拍摄视频,他们的方法就能很好地重建出周围环境的三维模型,效果优于此前的方法。
视觉 SLAM 技术应用
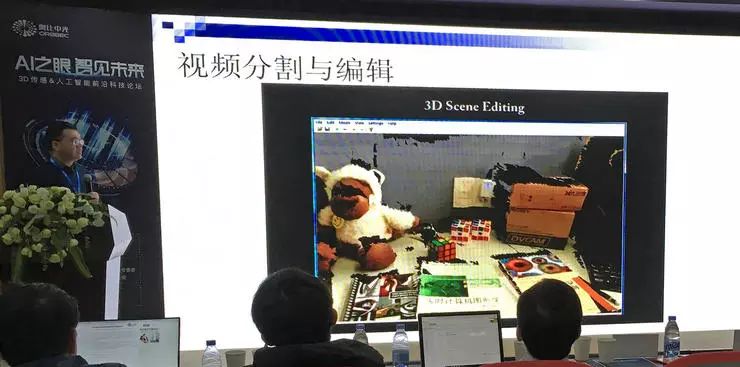
视觉 SLAM 技术的应用有很多。对于视频剪辑,可以移动、复制画面中的对象,隐藏或者添加对象,还可以增加时间停止特效,进行景深变换等。(上图视频中,在桌面上复制了一个同样的魔方)。
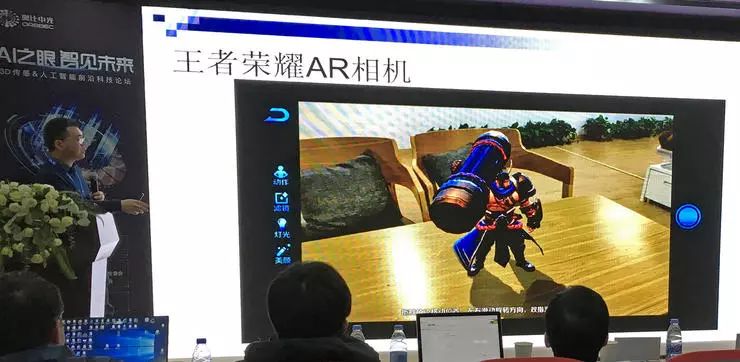
增强现实应用也是大家喜闻乐见的应用形式。图中演示的是王者荣耀 AR 人物,可以让游戏中的英雄在真是桌面上做出各种动作;高德地图有 AR 导航,可以在路面上显示一个助手带着你行走。AR 尺子也已经具备了一定的实用性,基于 RGB-D 惯性 SLAM 的 AR 测量,平均测量误差只有 2.6%。基于 TOF (飞行时间)的技术还可以具有遮挡处理的能力。



最后,章国锋教授展望了视觉 SLAM 的技术发展趋势。一方面,我们需要更先进的方法缓解视觉 SLAM 中的特征依赖,提高稳定性;另一方面,稠密 SLAM、TOF 做得还不够好、应用还不多。最后,多传感器融合也是一大发展方向。
黄迪 - 「基于三维人脸数据的身份识别与表情分类」

北京航空航天大学计算机学院院长聘副教授、博导黄迪的报告主题是「基于三维人脸数据的身份识别与表情分类」。报告从背景、三维人脸识别、三维表情识别、三维人脸分析的新挑战几个方面综述介绍了这个领域的主要研究和应用脉络。
背景

三维人脸分析的处理流程可以分为数据采集、预处理(移除尖点、填充孔洞等)、形状表示、测量与匹配几步。如今进入深度学习时代,传统三维分析流程四步中的后两步可以合二为一。

三维人脸分析的应用场景不外乎身份验证、4D 表情分析,还可以分析身份和表情之外的额外信息,比如人种、性别、年龄等。一个典型应用是 iPhone FaceID,它采集人脸的三维数据进行记录和比对。FaceID 的出现表明三维人脸已经可以在一些定制化的产品上进行应用,回应了一些对三维技术质疑的声音。

二维、三维人脸分析技术的表现有较大不同。二维人脸分析解决不了光照问题;二维人脸识别无法很好解决姿态变化的问题(对于不同表情的人脸,做身份识别之前需要尝试恢复到中性的表情,但信息的重加工可能会破坏身份信息);三维人脸分析对化妆的容忍度更高。以及,对于照片、视频、仿真面具三类攻击的容忍程度上,三维对前两种有天然的免疫(采集不到深度信息),而且对面具的抵抗性也要比二维方法好很多。

三维人脸分析起始于 1989年,2005年是三维人脸分析快速发展的一年。领域内的大牛 Kevin Bowyer 在 2006 年提出,三维人脸分析技术的发展面临的三大挑战是:更好的三维传感器、更好的算法以及更好的实验方法。
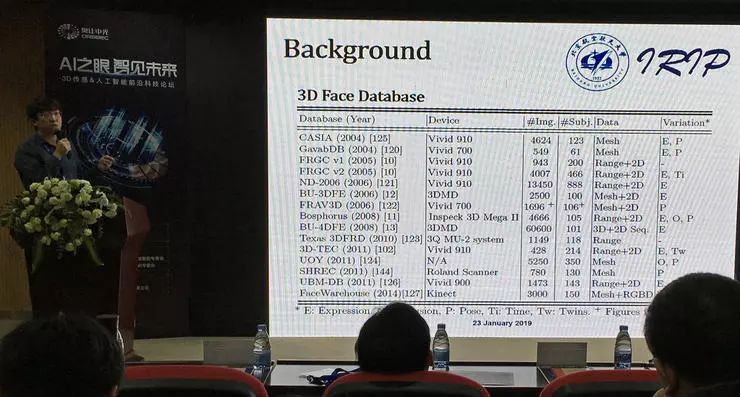
三维人脸分析的数据集有不少,常用数据集 FRGC、BU3DFE、BU-4DFE。不过所有这些数据集的数据量都不大,所以深度学习模型的表现并不突出。

三维人脸识别使用场景:纯三维形状对比,多模态人脸对比,以及二维三维不对称识别

黄迪副教授说道,三维人脸识别的挑战是,所有的人脸都很像!人脸这个大类的相似度很高,所有的脸人脸都有相同的结构。考虑不同身份的人构成的小类的话,类内有一定的变化,来自表情变化、姿态(收集时的不同姿态可能导致三维点云不完整)、遮盖、双胞胎、低质量数据等。而类内的差异无法保证小于类间(不同的人之间)的差异。如今,表情变化的处理已经比较成熟稳定,其他的挑战仍然等待解决。
三维人脸识别技术
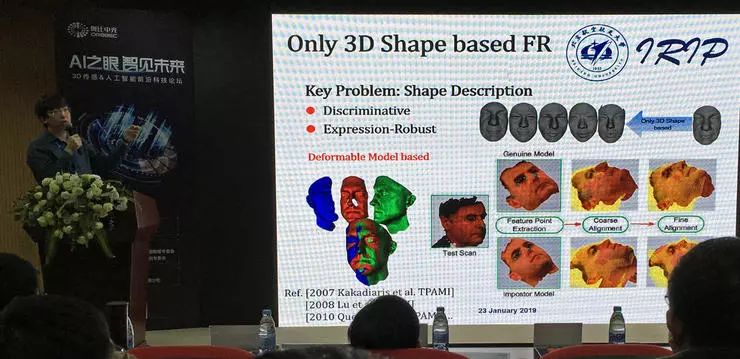
三维人脸识别中的关键问题:要找到比较好的形状表示。理想的表示要对不同的个体有区分度,也要能减少其他因素的干扰。形状表示有基于模版、等高线、刚体、不变区域等多种方法。后来公认使用 MeshSIFT 类等基于特征的方法。
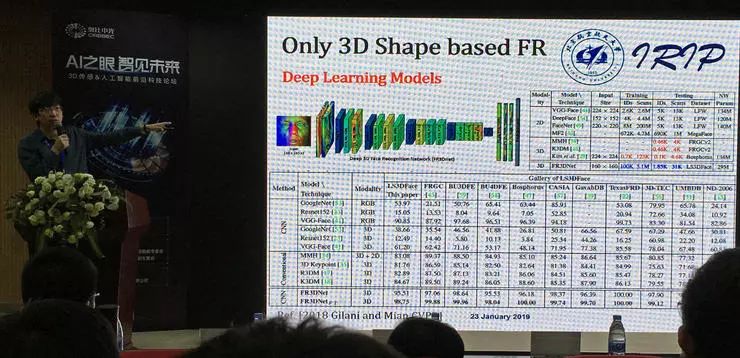
由于更早之前人脸数据集的样本太小(数据库中默认每张脸只有一个样本),所以基于深度学习的研究工作 2018 年才出现。这项工作微小地改动了已有的 VGG-Face 模型,而创新点在于数据扩增,作者们创造了更多的虚拟 ID、更多的姿态,保证有足够的数据,然后用二维卷积的方法得到比较好的结果。
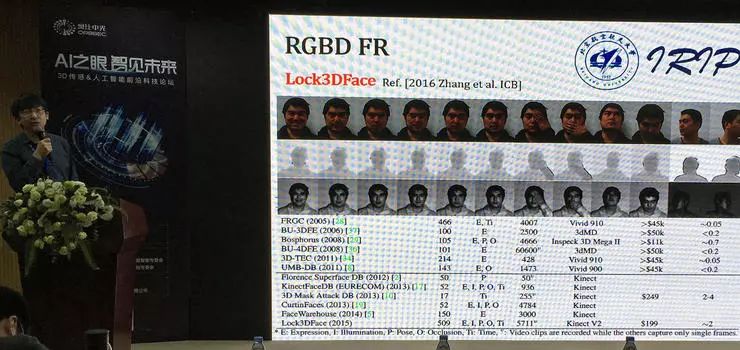
根据黄迪副教授介绍,三维人脸识别的难点,早期一般在于采集,高精度的采集设备过于昂贵,能采集的数据规模小;后来才有低成本的采集设备,而消费级的采集设备一般还是有比较多的噪声。

黄迪副教授利用消费级的 Kinect v2 采集大规模数据,提出 Lock3DFace 数据集,包含了 500 个人、每人 20 个视频,其中有 200 人的数据采集时间间隔 7 个月。这个数据集的目的除了为每个身份提供充足的数据之外,也包含了丰富的表情、姿态、遮挡,尤其时间间隔造成的变化是任何此前的数据集都不包括的。Kinect v2 虽然只能采集到低精度的原始数据,但可以用多帧数据联合重建,同样得到可靠的结果。

最新研究中,他们提出了一套采集系统 Led3DFR,用移动级硬件,利用前端计算、小模型,达到高准确率、高识别速度。
三维表情识别技术

三维方法研究表情有天然优势。传统表情方法中的一种是肌肉分割。目前还解决的不好的案例是一些近似表情的分割,强度小,混淆性高。
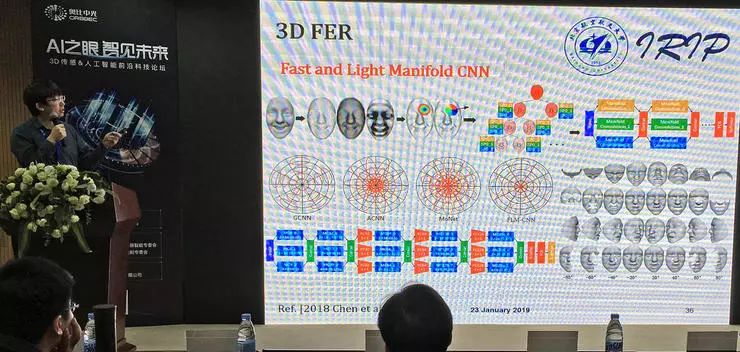
另一种思路是在流形上做卷积,但对内存大小和计算复杂度要求很高。黄迪副教授团队提出一种快速、轻计算量的新流形卷积方法,直接在 mesh 上计算,使用定制化的算法,手工定制的池化步骤,计算过程高效,得到的下采样结果准确。
对于各种基于深度学习的方法,黄迪副教授的感受是,受限于训练数据集大小,还是需要结合一些手工优化,但深度学习的方法仍有优势。
三维人脸分析的挑战

最后总结了三维人脸分析技术发展中遇到的挑战:首先,三维重建、特征计算都有高计算量,在移动设备上有计算时间的问题;点云数据是不规则分布的,空间中不同区域的点密度有很大区别,同时三维人脸数据集的数据量也不大,深度学习的应用就受到一定限制。

对于三维人脸识别,真实场景应用中也许多变异点,比如如何适应商业化的(低精度)深度传感器、如何在移动设备上运行、如何克服噪声和遮挡等问题,以及如何与二维RGB数据有更好的融合,高效地发挥各自的优势。

对于三维表情识别,也有表情的不确定性的问题,可以是不同的表情看起来很类似,也可以是不同的人对同样的表情有不同的理解。尝试其他表达形式,结合上下文、肢体语言判断是一种思路。
赵启军 - 「三维人脸建模:由图到形的人脸识别」

四川大学计算机学院副教授赵启军的报告主题是「三维人脸建模:由图到形的人脸识别」。这个报告也是关于三维人脸的,不过赵启军副教授关注的重点是从二维图像重建三维人脸,这不仅是二维三维信息之间的桥梁,也拓展了三维人脸技术的应用范围。

二维图像可以由三维实体生成,其中有很多因素影响;二维图像除了纹理之外也有很多三维信息,尤其是在结合了物体的常识模型之后。二维和三维相比之下,全视角的三维面部模型含有更多的信息,也更加鲁棒。
三维人脸一直不火热的原因,赵启军副教授认为是高成本。专业的三维采集设备自然非常昂贵、使用不便,即便现在出现了低价的消费级 RGB-D 传感器,但测量精度有限;其他原因还有,受限的应用场景(绝大部分三维应用在短距离测量和识别),带来的额外收益受限(二维图像在多数场景中都有足够好的效果,占据支配地位,不过实际上二维图像方法也需要使用环境中有一些约束,才能达到满意的性能)

赵启军副教授的科研路线围绕的就是三维数据的重建和应用:在采集新的三维数据的同时,也要利用已有的二维数据。从二维数据重建三维数据,可以辅助无限定的二维人脸识别(角度、光照、姿态不做严格要求)。这也是本次报告的主要内容。
单张图像人脸重建
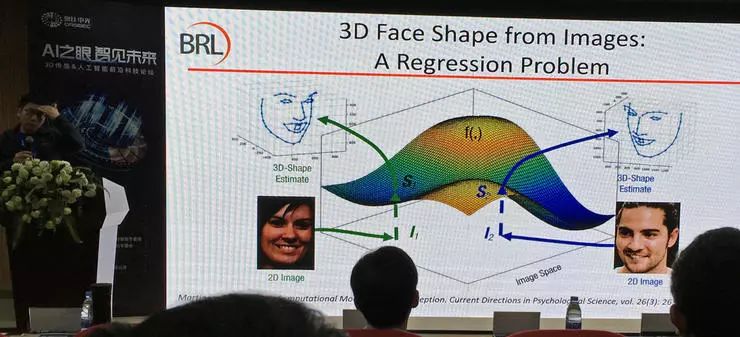
从一张到多张图像恢复完整的三维模型。这可以看作一个回归问题。

解决这个问题的经典方法是 3DMM,这是一种统计方法,做法是收集许多人脸模型,用 PCA (降维)求出统计模型,然后把统计模型拟合到待求人脸。如今的深度学习方法也是用的同样的核心思路,只是改变了求参过程。
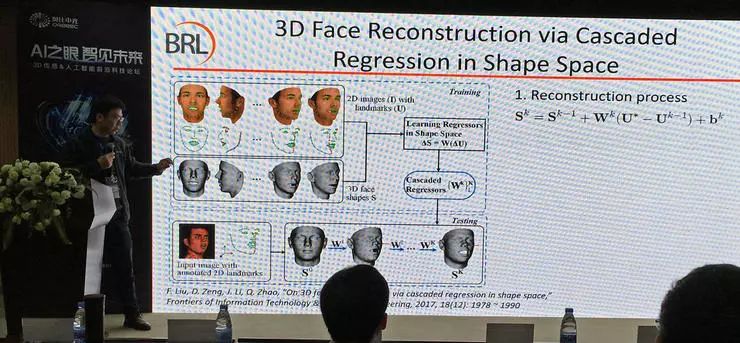
对于这项方法的后续改进,研究人员们希望可以避免求解统计模型,直接在三维空间中求回归,得到保留个性化特性的、而且有助于识别的人脸形状。简单直接的人脸重建有许多思路可以完成,但是我们希望重建结果能对人脸识别起到帮助,也就是保留有辨别性的细节。另外还希望这个过程可以是实时的。
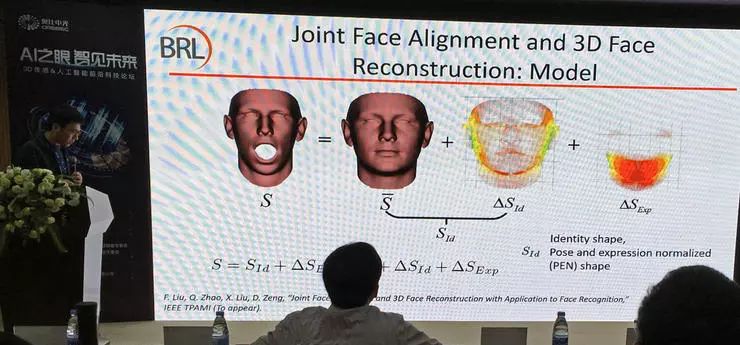
赵启军副教授介绍了自己团队的一项后续研究工作,从单张图像重建三维人脸,同时目标让重建结果帮助人脸识别,排除表情之类的对识别无帮助的信息。他们的思路是把每个面部三维模型看作平均模型+身份信息+表情信息的组合。他们把面部对齐(获得更准确的特征点)和面部重建(获得更准确的三维模型)作为联合任务,交替进行,多次迭代;最终输出的三维重建结果不包含表情信息,也就是一个表情中性的人脸。
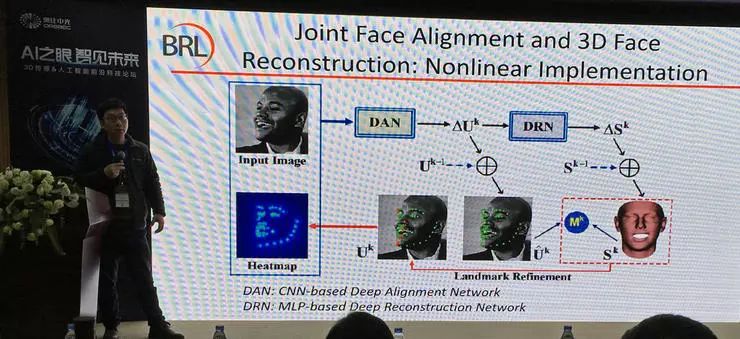
研究中他们也尝试了基于深度学习的非线性模型,效果并不突出。他们猜测原因也是测试数据集规模较小,不足以发挥出深度学习方法的优势。
经过三维重建得到了正面、表情中性的人脸模型之后,一种应用方式是辅助提升二维人脸识别的效果。重建后的三维模型与原始二维图像补充成为融合模型后,可以提升较大角度下识别的性能,减小了姿态和光照对纯二维方法人脸识别的影响。
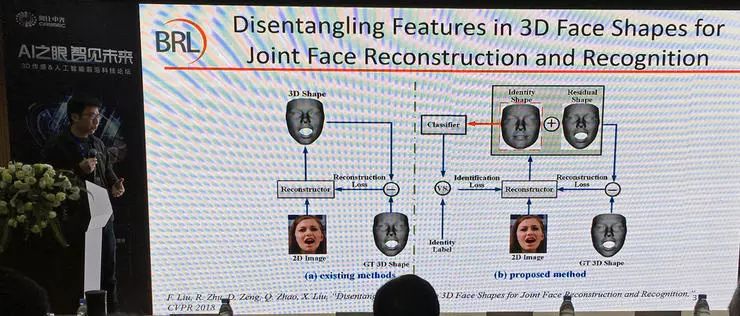
赵启军副教授还做了其他思路的进一步研究,他们尝试三维面部形状特征解耦,联合人脸重建任务和识别任务,希望可以强化识别人脸需要的身份信息;根据他们的想法,这些信息可以在隐空间进行分解建模。

经过端到端联合训练后实现了预想的引导结果,达到了身份信息和表情信息的分离,不同人的身份信息有足够的区分度。
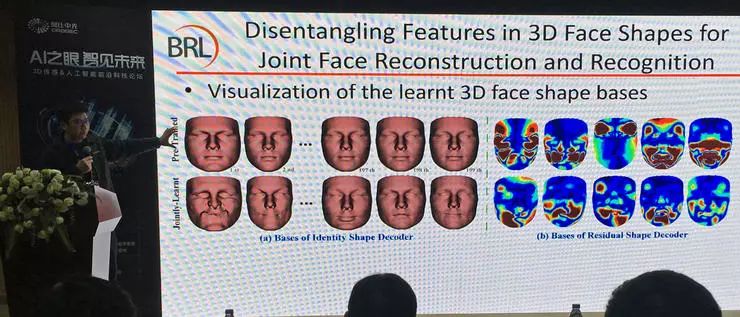
他们也做了许多验证研究,表明形状重建的精度也达到了较好水平;Alabation study 表明,多层感知机学习到的基向量之间也有很高的区分度(单个基向量表示的面部特征已经不可能在真实人脸上出现了,见上图左侧部分),说明了学习的有效性。
多图人脸重建
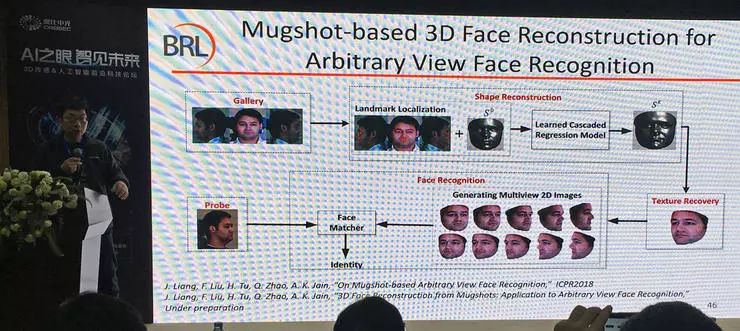
单张图像的人脸重建问题得到较好解决之后,多张图像带纹理重建也就是在单图任务基础上的自然延伸。一个典型的应用是,公安系统的罪犯存档照片包含正面、左、右三种视图,可以利用这些照片重建带有纹理的三维人脸模型,与现有的二维图像采集系统结合以后可以极大提升目标的前 n 位识别成功率,即便二维图像采集系统的图像可以是任意角度的人脸。赵启军副教授还介绍了一个三维人脸重建带来目标犯罪嫌疑人的识别排序大幅提升的真实案例。

多张图像的人脸重建也有一种令人十分头疼的应用场景,就是长时间跨度的多张无限制图像重建。如图,六张不同年龄的莱昂纳多,几乎可以认为是好几个不同的人了。这时我们希望重建出的人脸是一个平均形状,能够代表不同时期的面部特点。
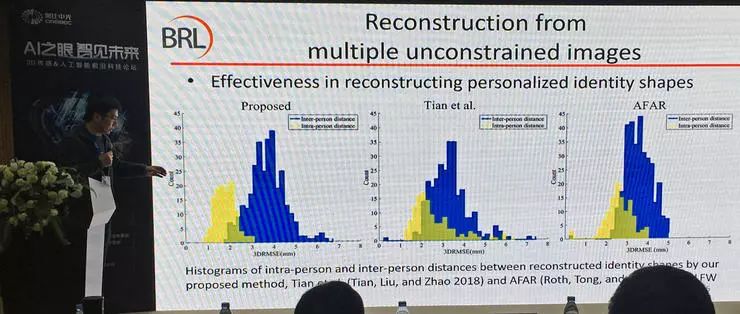
这个问题目前还无法完美地解决,毕竟类内就有很大差异。不过相比以往的方法,赵启军副教授团队提出的方法,减小了同类、类间区别的重叠(图中黄色和蓝色交叠部分)。
总结

赵启军副教授最后做了总结:三维人脸在许多任务中会有帮助,他们也提出了多种方法进行重建并应用重建成果。这个领域的挑战是:缺乏大规模的 benchmark;数据采集精度需要更高,重建时希望可以有更多的纹理细节(甚至到可以捕捉皮肤缺陷的程度);另外不同多种来源的数据可以用于多种不同的目的。
郭裕兰 - 「三维场景智能感知与理解」

国防科技大学电子科学学院讲师郭裕兰的报告「三维场景智能感知与理解」介绍了他所在的研究小组在双目深度估计、三维目标识别以及三维场景标注等方向的研究进展。

郭裕兰首先介绍了三维数据获取与处理的基本知识,介绍了双目视觉深度计算的基本技术,以及这个任务中传统算法的流程。

郭裕兰所在的研究小组有一些新的尝试,他们借助深度学习,用一个网络解决视差估计中的多个步骤。

在 CVPR 2018 的 ROB 挑战赛中,他们的方法在不同的数据集中取得了均衡的表现,由此获得了总成绩第一名。

他们也对视差超分辨率任务做了一些研究。视差超分辨率是要利用双目视觉两个输入之间的微小差异。

郭裕兰还介绍了多种基于三维数据的深度学习场景理解(对象识别)方法。
纪荣嵘 - 「基于学习的场景信息重构」

论坛的压轴报告嘉宾是来自厦门大学的“闽江学者”特聘教授、博导纪荣嵘。报告中介绍了课题组围绕场景信息重构的一些研究工作以及技术应用。

报告一开始,纪荣嵘教授就感慨道,「虽然现在是深度学习时代,但是只会深度学习是不行的」。报告的第一项内容也就是一种非深度学习的方法。
基于搜索的单图深度估计

单目视觉深度估计本身是一项比较简单、如今也被深度学习解决得比较好的问题,传统方法先估计初始深度图,再用 CRF 优化、端到端,以及继续加入各种技巧,也可以得到比较好的结果。
不过在这项研究中,纪荣嵘教授指导学生选择了一种基于搜索的方法:把深度估计问题作为搜索问题,把图片分为许多 patch(小块),每个patch在现有的图像-深度数据库中搜索,得到的结果做上下文平滑。
这种做法的难点在于:1,跨模态检索,2,大边缘结构分析。由于这是一种非深度学习方法,它不需要训练,只需要预先编码一个字典即可(用于快速搜索)。这篇论文时间较早,但也被 ECCV 录用。
基于序列预测的实时语义分割
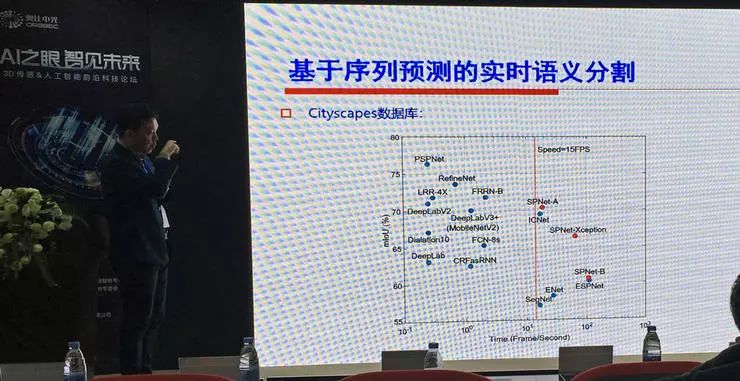
下面就进入了深度学习时代,在各种任务中大家都开始尝试基于深度学习的方法。纪荣嵘教授介绍的这项研究是针对视频语义分割的(也就是时间序列语义分割)。
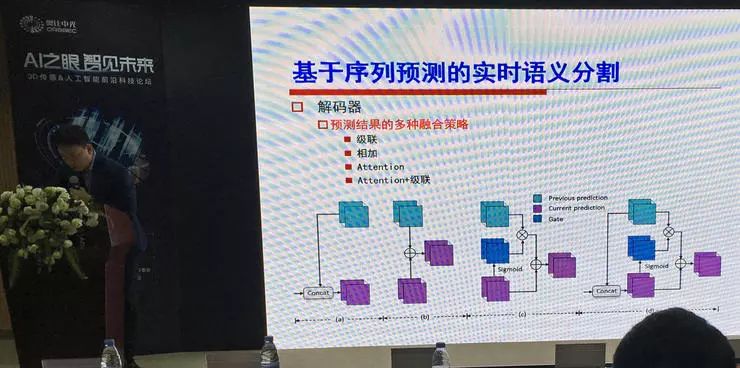
一般来说序列分割中都要考虑前后帧之间的联系,才能让分割结果更稳定、鲁棒,他们的思路是把编码器先前的输出用来预测,也尝试了级联、相加、Attention、Attention+级联等多种融合策略,编码器也使用了上下文残差卷积。最后配合一些提速技巧,取得了性能和速度的很好均衡(在 TITAN Xp 上,2048x1024 的图像分辨率输入,达到 18.5 帧/秒的运行速度;同时在精度上甚至优于一些不考虑速度的方法)。 这篇论文 CVPR2019 在投。
基于语义信息和生成对抗的视觉里程计
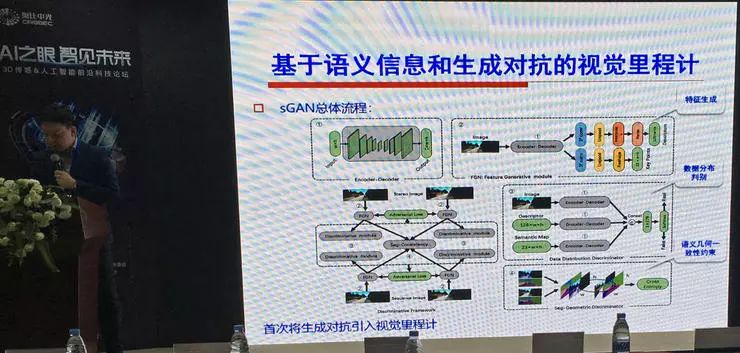
下一项研究是关于视觉里程计的。这是首次把生成式对抗引入视觉里程计的设计,但取得了不错的效果。
方法的总体流程是,用一个特征生成模块 FGN 生成特征,用一个 Discriminator 判别数据分布。这个 Discriminator 有三路输入,分别是图像、生成器输出的特征、语义图,然后把用 SIFT 方法生成的特征点和特征描述作为 Ground Truth。这样的做法解决了特征点检测和描述的问题。取特征部分比直接使用 SIFT 和 ORB 快,精度也更高。而且也解决了 SIFT 作为里程计时容易中断的问题。

他们的方法在许多场景下都取得了不错的表现,甚至最终的精度超过了作为监督信息的 SIFT 的精度。不过,由于方法中没有加入闭环检测,在高速、长路段的后期误差会升高。

最后,纪荣嵘教授还简单介绍了实验室在视觉场景理解方面的多个项目,包括头戴式显示装备、AR 快速定位、基于神经网络压缩的人工智能芯片设计、端到端实时室内物体语义分割等,也是产学研结合的范例。
结束语
七场学术报告下来,这些在三维数据分析、场景感知、人工智能技术方面有诸多经验的专家学者们之间就一些观点达成了共识,为台下听众讲解了重要的发展脉络、关键技术体系和最新进展;借着听众提问的机会,嘉宾们也在一些问题上更具体深入地表达了自己的观点。
三维数据的采集和表示、三维数据的分析和理解还有许多难点遗留,不过这同时也是巨大的空间,等待技术不断发展去填补。奥比中光在三维数据采集设备的普及化、小型化方面做出的探索得到了专家们的关注和认可,也将成为这个领域的学术研究和应用普及的一股推动力量。
未来更丰富的三维信息、对三维信息的更充分利用,也会像现阶段的人工智能技术一样带来更多机会和生活便利。 AI 科技评论也会持续关注相关学术研究和技术普及应用,期待下一次的专家学者聚首以及最新学术成果讨论。





