ICLR 2021公开评审,这些信息点和高赞论文不可错过!

作者 | 陈大鑫
近日,机器学习顶会ICLR 2021投稿已经结束,最后共有3013篇论文提交。ICLR 采用公开评审(openreview)机制,任何人都可以提前看到这些论文。
ICLR 2021顶会openview网址:
https://openreview.net/group?id=ICLR.cc/2021/Conference
本文整理了来自ICLR 2021投稿概览以及一些高赞论文,其中有一篇将Transformer应用于图像识别的论文引起了NLP/CV模型跨界融合的热议。
ICLR 2021投稿概览
据Criteo AI Lab机器学习研究科学家Sergey Ivanov消息,本次ICLR 2021一共有3013篇论文提交,其中有856篇论文是来自NeurIPS 2020 Rejection 之后重新提交的。

以下是本次ICLR 2021提交论文的词云图:

之后Sergey Ivanov似乎在讽刺道:
双盲评审有多盲?
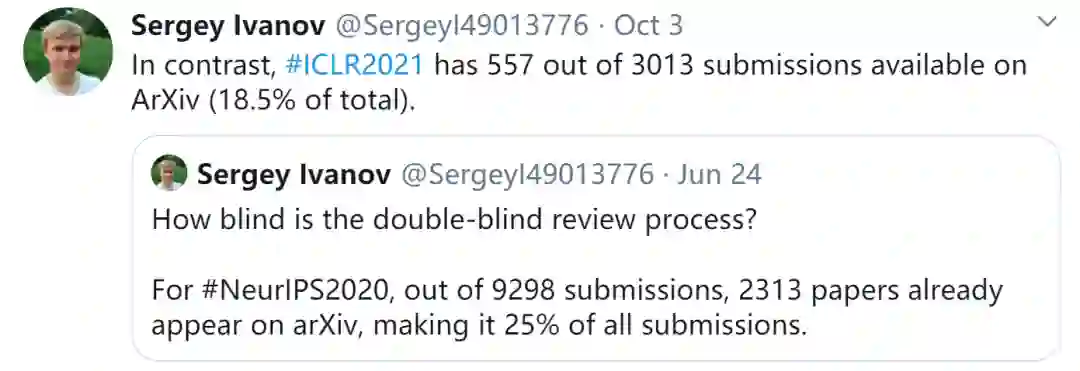
对NeurIPS 2020来说,在9298份提交的论文中,已有2313篇论文发在arXiv上,占所有提交论文的25%。
相比之下,ICLR 2021有557篇论文发在arXiv上,占所有提交论文的25%。
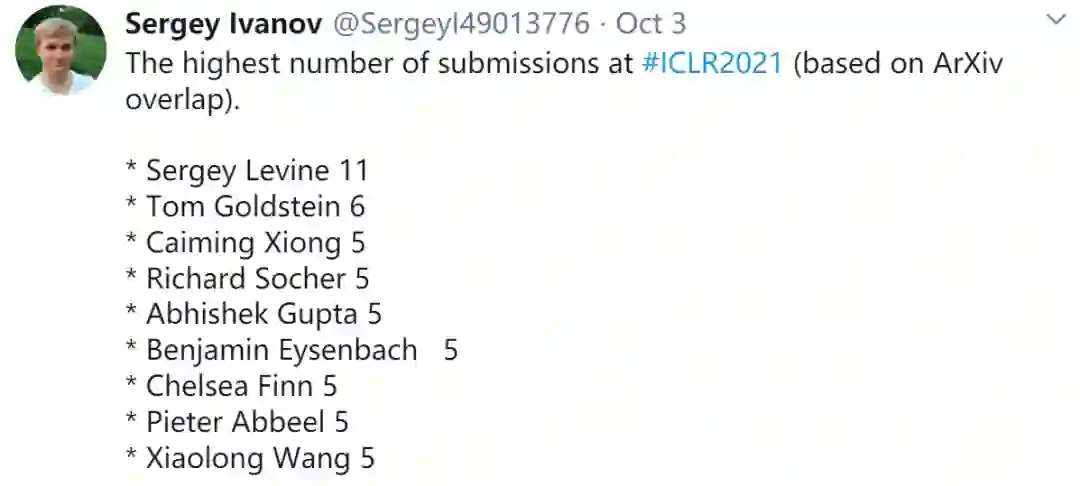
最后Sergey Ivanov公布了目前为止基于ArXiv统计的ICLR 2021个人投稿排行榜:
一篇论文引起NLP/CV模型跨界融合的热议
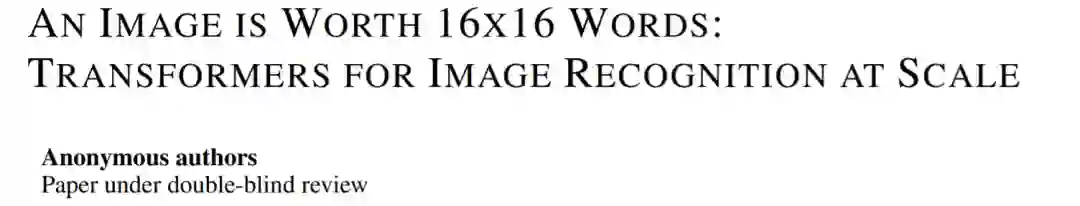
论文链接:https://openreview.net/pdf?id=YicbFdNTTy
以下是论文摘要:
【虽然Transformer架构已经成为自然语言处理任务的标准,但它在计算机视觉中的应用仍然有限。
在视觉上,注意力要么与CNN(卷积神经网络)结合使用,要么用来代CNN的某些组成部分,同时保持其整体结构不变。
我们证明这种对CNN的依赖是不必要的,当直接应用于图像块序列时,只用到Transformer也可以很好地执行图像分类任务。
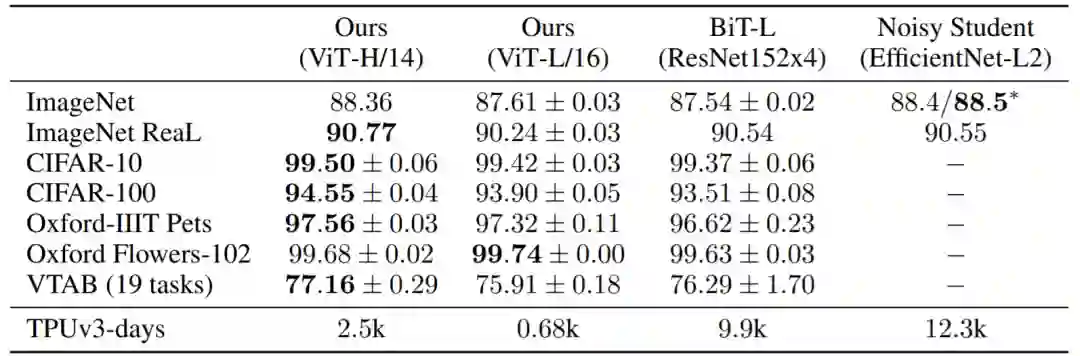
当对大量数据进行预训练并迁移到多个识别基准(ImageNet、CIFAR-100、VTAB等)时,与SOTA卷积网络相比,Vision Transformer取得了优异的结果,同时需要的计算资源要少得多。】
在推特上,斯坦福大学CS博士、特斯拉AI总监 Andrej Karpathy转发了该论文,并表示[乐意见到计算机视觉和NLP领域更高效/灵活的体系结构的日益融合]。
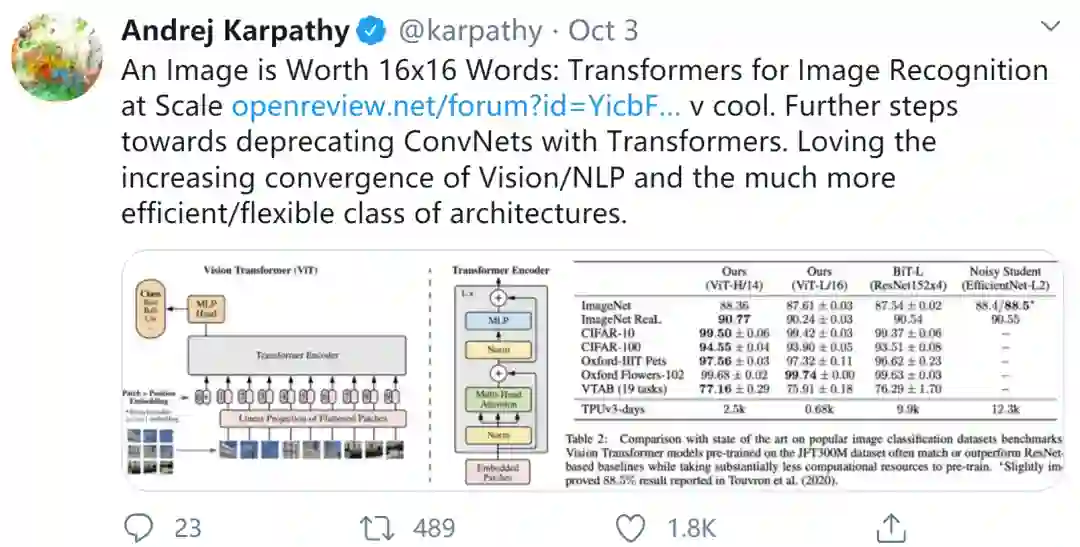
那么这篇论文到底有何神奇之处?
在知乎问题“ICLR 2021 有什么值得关注的投稿?”下,网友陶略对此论文发表了自己的一番见解,现经陶略本人授权把内容整理如下:
【这里把这篇论文的核心框架模型称作ViT:Vision Transformer。
一图胜千言?不,16x16个词顶一张图!(An Image is Worth 16x16 Words)
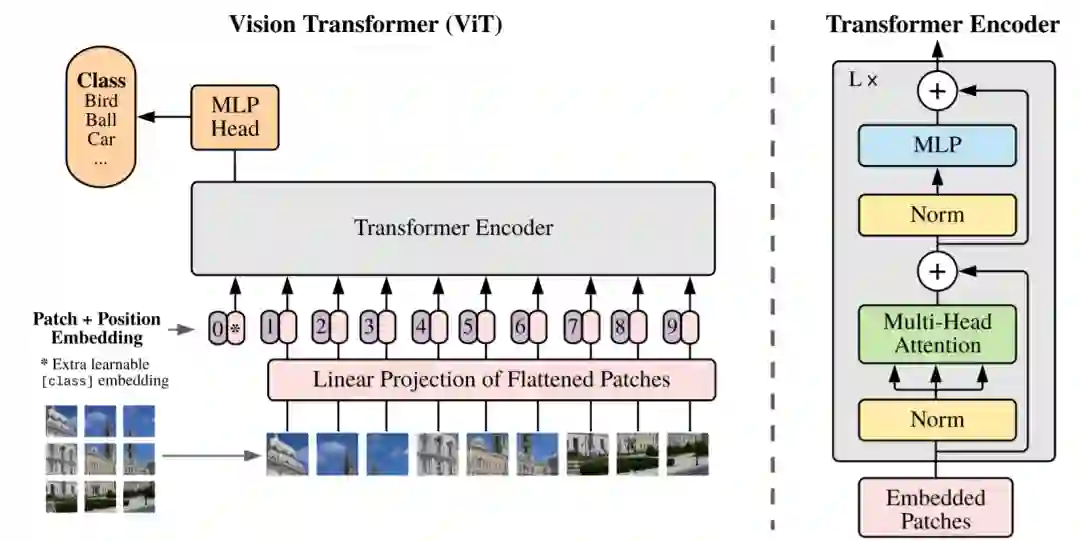
化难为易:把图片拆分成16*16个patches,每个patch做一次线性变换降维后再送入Transformer,避免像素级attention运算。
大道至简:降维后的向量直接送入Transformer,最大限度保留Transformer纯正的味道。
暴力美学:舍弃了CNN的归纳偏好之后(inductive biases such as translation equivariance and locality),反而更加有利于在超大规模数据上以自监督方式学习知识,即大规模训练胜于归纳偏好(large scale training trumps inductive bias),在众多图像分类任务上直逼SOTA。
感谢 @匿名用户的提醒:把image patch之后再每个patch做一次linear projection,这恰恰就是convolution。
但我觉得这个linear projection并不必要每个patch都共享同一个,其实是可以为每个patch学一个不同的linear projection出来的,这恰恰就是LeCun提出来的locally connected layers[1]。
更进一步,可以每个linear projection之间部分共享/软共享,以减少参数自由度。idea都有了,有卡的人拿去研(guan)究(shui)吧哈哈哈。可参考这篇《Locally Smoothed Neural Networks》[2]。
当然针对ViT的软共享应该需要根据Transformer的特点专门设计,直接把现存的软共享技巧拿来用会有问题。
关于locally connected layers与fully connected layer的区别:locally connected layer的连接性等于convolution layer,小于fully connected layer。
输入输出维度相同的情况下,可变参数量:convolution layer < locally connected layer < fully connected layer。
很早之前鄙人就思考过能否用locally connected layer替代convolution layer,也做过一点儿实验。但效果不好,因为我的数据量和算力太小,不足以弥补丢弃的归纳偏好。所以看见ViT这样的工作能做出来一点儿不一样的尝试,我内心还是很激动的。
在CNN的框架下,通常卷积核越小性能越好,这么大的卷积核往往被认为行不通。但ViT做到了,它用了16*16的卷积核。
这让我联想到了前段时间reddit上很火的那篇《Towards Learning Convolutions from Scratch》,也是舍弃了CNN的归纳偏好(translation equivalence and locality),但增加了很强的稀疏性偏好。
Surprisingly,从而使得全连接的网络从数据中学到了locality。

一个事件能引起争议,一个研究能引人关注,恰恰说明这个事件或这个研究的意义。我也是领略了点文章的皮毛之后有感而发,不吐不快,望海涵。】
望有朝一日,NLP与Vision架构收敛一致,天下大同。
NLP/Vision科研民工进入赛博躺平时代,每天等着大公司预训练的Transformer当救济粮。
要发展下线的时候就做一点花里胡哨的注意力热图吸引农民来淘金:
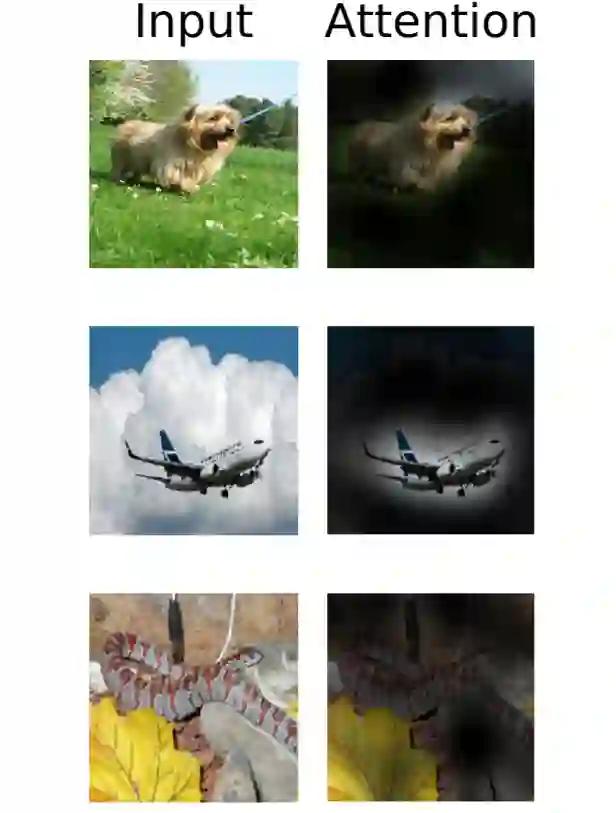
图注:上下两图均为从输出token到输入空间的注意力典型示例

更多高赞论文
港中文助理教授周博磊整理了一份自己关注论文的笔记,有GAN、强化学习、计算机视觉三个领域相关共30多篇论文。
GAN相关:
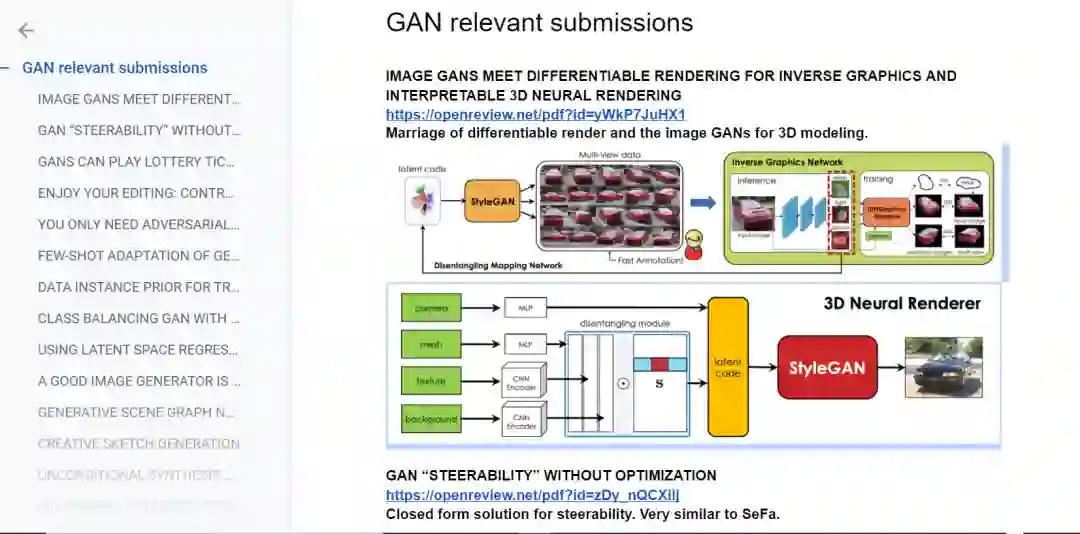
强化学习相关论文:
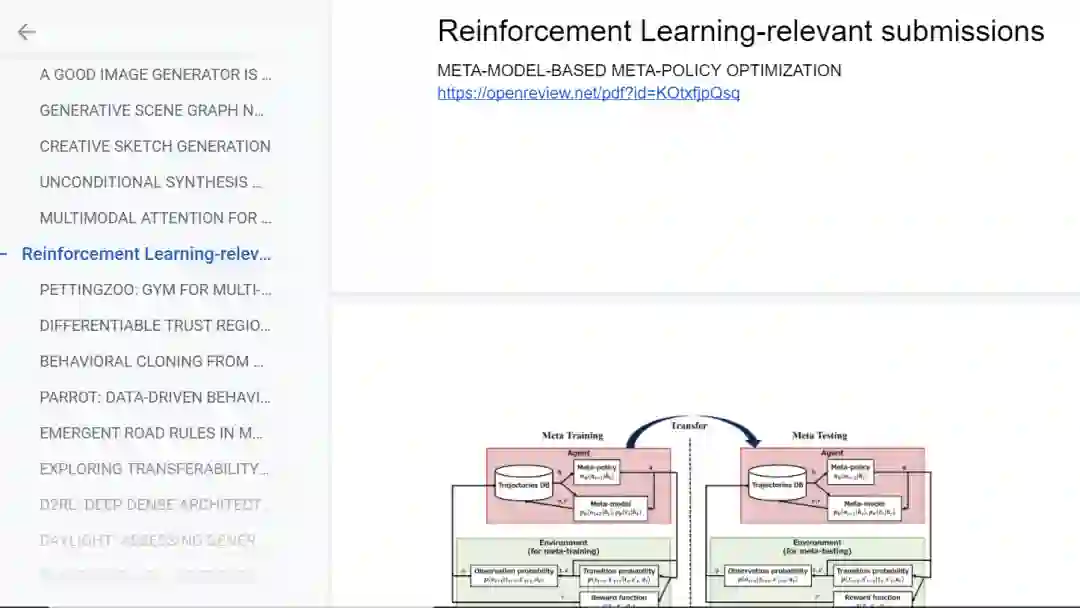

计算机视觉相关论文:

周博磊博士笔记在线链接:
https://docs.google.com/document/d/1Rk2wQXgSL-9XiEcKlFnsRL6hrfGNWJURufTST2ZEpIM/edit
1、《An Attention Free Transformer》
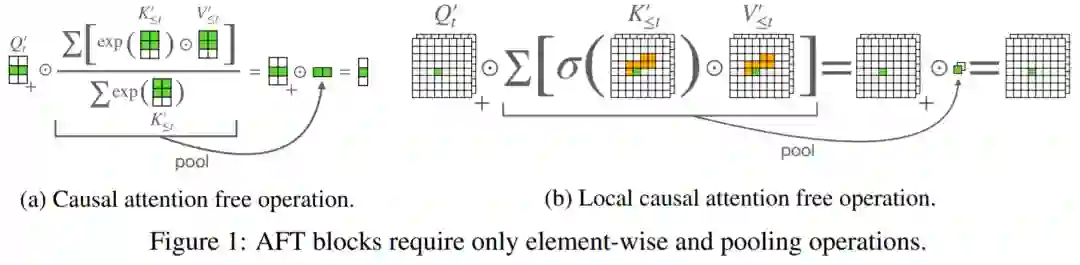
论文链接:https://openreview.net/pdf?id=pW--cu2FCHY
2、《A Good Image Generator Is What You Need for High-Resolution Video Synthesis》
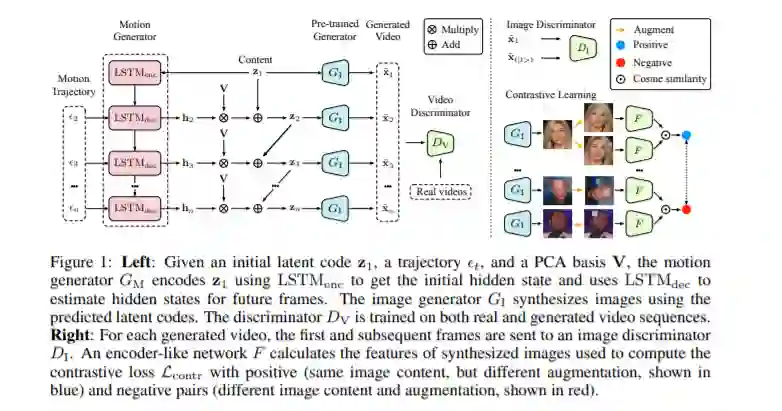
论文链接:https://openreview.net/pdf?id=6puCSjH3hwA
3、《Contrastive Learning with Stronger Augmentations》
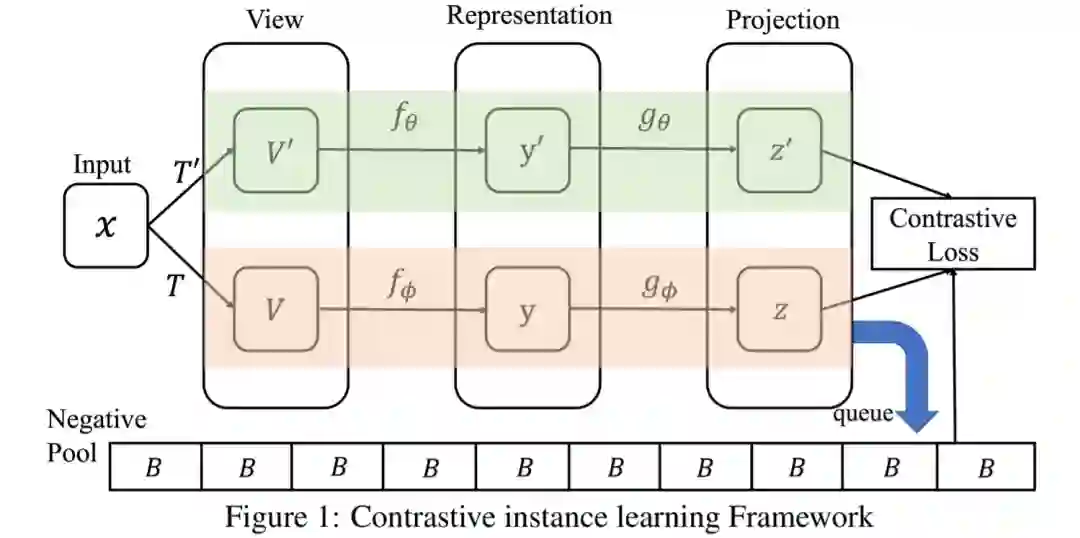
论文链接:https://openreview.net/forum?id=KJSC_AsN14
4、《Score-Based Generative Modeling through Stochastic Differential Equations》
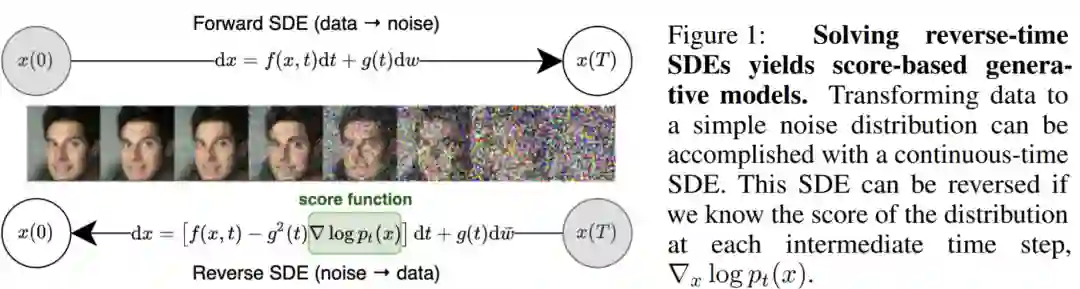
论文链接:
https://openreview.net/forum?id=PxTIG12RRHS¬eId=PxTIG12RRHS
https://www.zhihu.com/question/423975807/answer/1505968531
在10月1日头条《秋天的第一本AI书:周志华亲作森林书&贾扬清力荐天池书 | 赠书》留言区留言,谈一谈你对这两本书的看法或有关的学习、竞赛等经历。
AI 科技评论将会在留言区选出15名读者,送出《阿里云天池大赛赛题解析——机器学习篇》10本,《集成学习:基础与算法》5本,每人最多获得其中一本。
活动规则:
1. 在留言区留言,留言点赞最高的前 15 位读者将获得赠书,活动结束后,中奖读者将按照点赞排名由高到低的顺序优先挑选两本书中的其中一本,获得赠书的读者请添加AI科技评论官方微信(aitechreview)。
2. 留言内容会有筛选,例如“选我上去”等内容将不会被筛选,亦不会中奖。
3. 本活动时间为2020年10月1日 - 2020年10月8日(23:00),活动推送内仅允许中奖一次。




