【预告】2022中国图象图形学学会青年科学家会议将于9月23-26日在长沙召开



主办单位:
承办单位:
湖南大学、中国图象图形学学会青年工作委员会
协办单位:
湖南工程学院、宝德计算机系统股份有限公司
赞助单位:

会议时间:2022年9月23-26日
会议主页:
http://youth.csig.org.cn/CSIG2022/index.html
参会须知
疫情防控:
1.所有外省来长参会人员请提前2天通过 “湖南省居民健康卡”微信公众号进行报备,关注湖南省确保本人防疫健康码和大数据行程码均为绿码,持48小时内核酸阴性证明且近21天内无境外旅居史,近14天内无中高风险地区旅居史,无发热、咳嗽、乏力、腹泻等症状。无48小时内核酸检测阴性证明或从有本土疫情发生省份来(返)长的人员应在第一入湘地实施落地核酸检测。从无本土疫情省份来长的人员,抵长后建议主动尽快开展一次核酸检测。
2.请参会人员会议期间切实做好个人防护,科学佩戴口罩,保持社交距离,配合会务组做好各项防疫工作。如有发热、咳嗽等症状应及时向会务组说明。
会场交通:
1.长沙黄花国际机场出发:距离酒店约26公里,驾车约40分钟,乘坐公共交通约70分钟。
2.长沙高铁南站出发:距离酒店约12公里,驾车约27分钟,乘坐公共交通约30分钟。
组委会
大会主席:
王耀南 湖南大学
胡德文 国防科技大学
高新波 重庆邮电大学
姚鸿勋 哈尔滨工业大学
程序委员会主席:
张 辉 湖南大学
董伟生 西安电子科技大学
阚美娜 中国科学院计算技术研究所
许倩倩 中国科学院计算技术研究所
组织委员会主席:
方乐缘 湖南大学
姬艳丽 电子科技大学
杨 欣 华中科技大学
杨 鑫 大连理工大学
苏 航 清华大学
宣传主席:
朱 磊 山东师范大学
舒祥波 南京理工大学
丛润民 北京交通大学
杨 鹏 华中科技大学
青托沙龙主席:
元 辉 山东大学
胡 鹏 四川大学
赵 健 军事科学院
黄 岩 中国科学院自动化研究所
优博论坛主席:
张鼎文 西北工业大学
马 超 上海交通大学
赞助主席:
刘 昕 国科智算科技有限公司
本地主席:
刘 敏 湖南大学
刘新旺 国防科技大学
网站主席:
大会议程
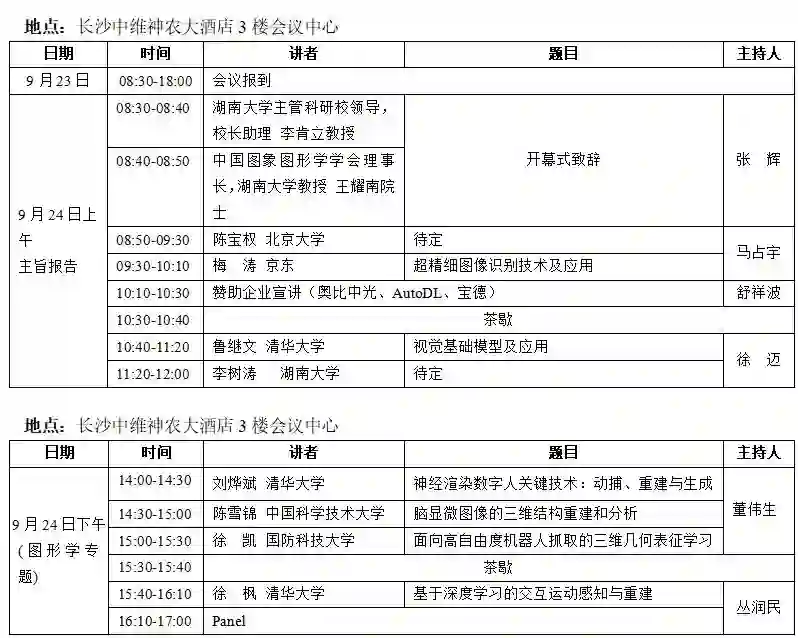
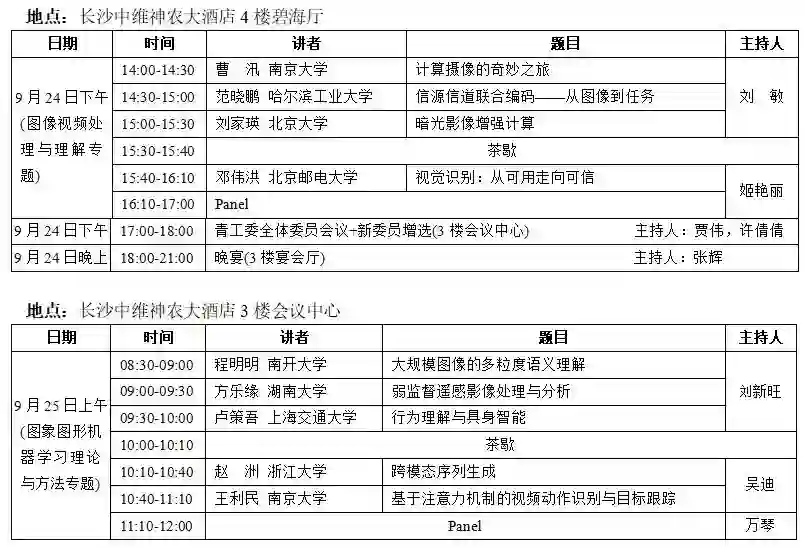
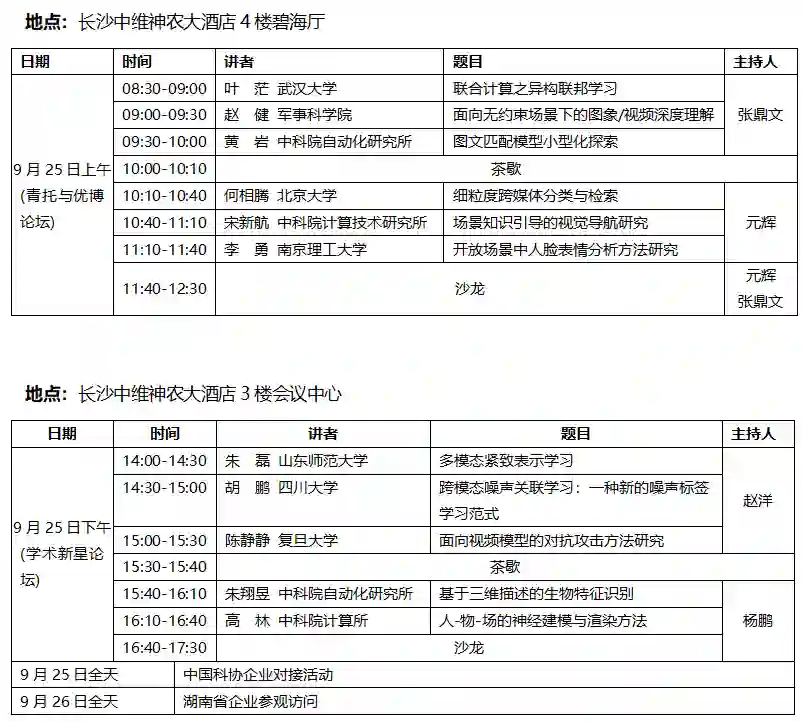
“青年科学家论坛”报告嘉宾
大会主题(Kyenote)报告
Keynote报告一
报告题目:待定
特邀讲者:陈宝权 北京大学

讲者简介:陈宝权,北京大学博雅特聘教授,前沿计算研究中心执行主任,博士生导师,IEEE Fellow和中国计算机学会会士。研究领域为计算机图形学与可视化,在 ACM SIGGRAPH 、 IEEE VIS、ACM TOG等国际会议和刊物发表论文 100 余篇。曾担任973项目“城市大数据计算理论与方法”首席科学家。现任/曾任ACM Transactions on Graphics(TOG)/IEEE Transactions on Visualization and Graphics (TVCG)编委,并多次担任计算机图形与可视化领域几乎所有重要国际会议的PC成员;曾任 SIGGRAPH ASIA和IEEE VIS指导委员会委员,SIGGRAPH ASIA 2014和 IEEE Visualization 2005会议主席及IEEE Visualization 2004 程序委员会主席。获 2003 年美国 NSF CAREER Award、2005 年 IEEE可视化国际会议最佳论文奖、2014年中国计算机图形学大会杰出奖,入选2008年中科院百人计划、 2010 年国家杰出青年科学基金资助、2013年国家“百千万人才”工程计划和“中青年领军人才”、2015年教育部长江学者特聘教授。兼山东大学特聘教授,北京电影学院未来影像高精尖创新中心首席科学家。任中国计算机学会(CCF)常务理事,第七届教育部科技委信息学部委员,曾任CCF青工委主任。获电子工程学士(91年西安电子科技大学)、硕士(94年清华大学),和计算机科学博士(99年纽约州立大学石溪分校)。因为在空间数据(建模)与可视化方面的贡献,入选IEEE Fellow(2020)。
报告摘要:待定
Keynote报告二
报告题目:超精细图像识别技术及应用
特邀讲者:梅涛 京东

讲者简介:梅涛,京东集团副总裁、京东探索研究院副院长、IEEE/IAPR Fellow、加拿大工程院院士(外籍)、科技部科技创新2030人工智能重大项目“智能供应链人工智能开放创新平台”首席科学家,负责京东科技计算机视觉与多媒体领域的技术创新和产品研发,在多媒体分析和计算机视觉领域发表论文300余篇,先后15次荣获国际论文奖,并拥有50余项美国和国际专利。他担任多个国际学术期刊的编委和国际学术会议的大会主席。因在大规模多媒体分析与应用领域的杰出贡献,梅博士先后当选加拿大工程院外籍院士,国际电气电子工程师学会会士(IEEE Fellow),国际模式识别学会会士 (IAPR Fellow),国际计算机协会杰出科学家,并担任中国科学技术大学和香港中文大学(深圳)兼职教授和博士生导师。加入京东之前,曾担任微软亚洲研究院资深研究员。
报告摘要:超精细图像识别是一种针对细微目标(~1‱目标占比)、全域物体(十万~百万类别)、全面语义(~50%语义覆盖率)的图像识别技术,旨在分析给定图像中占比小的区域、种类多的物体、以及全面的语义。例如,电商平台有超10亿种商品类别,病虫害防治中有超万种害虫,消费电子产品上的缺陷误差在微米级(千万像素图像上不超过10个像素),遥感测绘误差范围需要在0.1~1个像素之间,这些问题都需要依靠超精细图像识别技术来解决。针对超精细图像识别中的“目标难检测”、“类别难区分”和“语义难表达”三大技术挑战,本报告探索超精细图像解析(看得细)、超精细图像分类(看的全),以及超精细图像语义描述(看得懂)。在应用方面,本报告聚焦图像识别技术在落地中的难点,让机器看得细、看得全、看得懂,推动图像识别技术在零售、消费电子、智能制造等场景的规模化应用。
Keynote报告三
报告题目:视觉基础模型及应用
特邀讲者:鲁继文 清华大学

讲者简介:清华大学自动化系长聘副教授,博导,国家杰出青年科学基金获得者,IAPR Fellow,主要研究领域为计算机视觉、模式识别、无人系统。发表PAMI、CVPR、ICCV、ECCV论文130余篇,获授权国家发明专利50余项,主持基金委优秀青年科学基金、联合重点基金、海外高层次青年人才计划、科技部重点研发计划课题等项目10余项,获中国电子学会自然科学一等奖(排名1)、中国自动化学会高等教育教学成果一等奖(排名3)。担任国际期刊Pattern Recognition Letters主编,IEEE T-IP、T-CSVT、T-BIOM编委,国际会议ICME2022大会主席,FG2023、VCIP2022、ICME2020程序委员会主席,IEEE图像视频高维信号处理、多媒体信号处理、信息取证与安全、多媒体系统与技术、视觉信号处理与通信技术委员会委员,中国计算机学会计算机视觉专委会、中国人工智能学会模式识别专委会、中国自动化学会模式识别与机器智能专委会、中国图象图形学学会视觉大数据专委会常务委员。
报告摘要:基础模型是人工智能领域的研究热点,在计算机视觉和自然语言处理等领域中均取得了优异的性能,是视觉监控、自动驾驶、智能终端等重要应用的支撑性技术。报告将从模型架构和学习范式两个方面回顾视觉基础模型近年来的研究进展,同时介绍清华大学智能视觉实验室在视觉基础模型方面所开展的一些工作,主要包括高阶交互模型、动态稀疏模型、全局滤波模型、球面分形模型等,以及它们在目标检测与分割、物体分类与识别、图像与视频检索、三维重建与理解等视觉任务中的应用。
计算机图形学专题
特邀报告一
报告题目:神经渲染数字人关键技术:动捕、重建与生成
特邀讲者:刘烨斌 清华大学

讲者简介:刘烨斌,清华大学长聘教授,国家杰青。分别于2002年和2009年在北京邮电大学、清华大学自动化系获得工学学士和工学博士学位。主要研究方向为三维视觉。发表PAMI/ SIGGRAPH/CVPR/ICCV等论文近70篇,其中CVPR/ICCV/ECCV口头报告论文12篇。担任CVPR及ICCV Area Chair,SIGGRAPH Asia技术委员会委员。任中国图象图形学学会三维视觉专委会副主任。获2012年国家技术发明一等奖(排名3),2019年中国电子学会技术发明一等奖(排名1)。
报告摘要:当前元宇宙和人工智能热潮下,基于神经网络的数字人三维重建与生成技术受到学术界和产业界的广泛关注。围绕真实人物对象的三维重建、运动捕捉和智能生成成为构建现实世界和虚拟世界间的桥梁技术。本报告围绕智能数字人的3I技术,即人的行为感知实现交互性(Interaction),人的外观重建实现沉浸性(Immersion),赋予人的思想实现创作性(Imagination)分别介绍报告人在人体运动捕捉、人体动态三维重建、人体视频高质量生成等三方面科研工作,涵盖人体、人脸、人手的相关视觉图形学前沿。报告同时对沉浸式全息通信技术、AI数字人等热点前沿进行展望和探讨。
特邀报告二
报告题目:脑显微图像的三维结构重建和分析
特邀讲者:陈雪锦 中国科学技术大学

讲者简介: 陈雪锦,中国科学技术大学信息学院特任教授,教育部“青年长江学者”。2003和2008年于中国科学技术大学获得学士和博士学位。2008-2010年于耶鲁大学计算机系从事博士后研究。2010年加入中国科学技术大学。曾在斯坦福大学、微软亚洲研究院任访问学者。主要研究方向为计算机图形学、三维视觉、脑显微图像分析。在ACM SIGGRAPH、IEEE TVCG、TMI、ACM Multimedia等期刊会议上发表学术论文60余篇,承担国家科研项目10余项,曾获CVM期刊2019年度最佳论文提名、安徽省教学成果特等奖。个人主页:http://staff.ustc.edu.cn/~xjchen99/
报告摘要:近年来,微米、纳米分辨率的显微成像技术支持对大脑进行神经元级别到突触级的观测,大力推动了脑科学的发展,然而,TB级甚至PB级脑显微影像数据的处理和分析成为了制约神经科学发展的瓶颈。利用人工智能技术,对脑显微图像中神经元、线粒体等亚细胞结构进行自动三维重建和准确形态分析成为了必要手段。然而,脑显微图像中的三维目标形态各异,结构精细,标注代价及其高昂。为缓解该问题,我们研究了一系列自学习方法,利用神经元全局结构先验,挖掘图像样本间的结构关联,实现无需人工标注的高精度三维重建和三维形态表达。
特邀报告三
报告题目:面向高自由度机器人抓取的三维几何表征学习
特邀讲者:徐凯 国防科技大学

讲者简介:徐凯,国防科技大学教授。国家优青,湖南省杰青。普林斯顿大学访问学者,西蒙弗雷泽大学客座教授。研究方向为数据驱动的三维感知与建模、三维视觉及其机器人应用等。发表CCF A类论文60余篇,其中包括领域顶级会议和期刊ACM SIGGRAPH/Transactions on Graphics论文27篇。担任图形学顶级期刊ACM Transactions on Graphics,以及重要期刊Computer Graphics Forum、Computers and Graphics、The Visual Computer等的编委。担任GMP 2023等国际会议的论文共同主席,以及SIGGRAPH、Eurographics等会议的程序委员。担任中国图象图形学学会三维视觉专委会副主任,中国工业与应用数学学会几何设计与计算专委会秘书长,中国图学学会理事。获湖南省自然科学一等奖2项(排名第1和第3)、中国计算机学会自然科学一等奖(3)、军队科技进步二等奖等。
报告摘要:高自由度抓取是机器人灵巧操作的重要研究问题,具有广泛的应用前景。我们提出基于三维几何表征学习的高自由度灵巧抓取。本次报告将汇报我们在该方向的三项工作,包括基于三维深度学习的高自由度抓取合成,可微分高自由度抓取规划,以及基于三维交互表征学习的高自由度抓取及运动联合规划。其中在三维交互表征学习方面,我们将交互二分面(Interaction Bisector Surface,IBS)引入机械手与物体之间的抓取交互表示,用于建模和学习抓取过程中手和物体间的三维空间动态交互,实现了手的接近和抓取连贯规划。IBS可以很好地刻画高自由度机械手的每个手指与物体之间的细粒度空间交互关系,是一种非常有效的三维交互状态表示。结合深度强化学习,可以较高的样本效率学习高自由度抓取控制模型,且习得的模型具有动态适应性和跨类别泛化性。
特邀报告四
报告题目:基于深度学习的交互运动感知与重建
特邀讲者:徐枫 清华大学

讲者简介:徐枫,清华大学软件学院长聘副教授,博士生导师,中国人工智能学会副秘书长,国家优秀青年科学基金,北京市杰出青年基金获得者。研究方向包括人工智能、智慧医疗、虚拟/增强现实等。近年来致力于三维重建、图像分析及其与医学、生命科学的交叉问题研究。相关工作发表在Lancet Digital Health, Cell Patterns,PRL,ACM Siggraph, ACM Siggraph Asia, CVPR等国际权威期刊和会议上。多次担任国际重要期刊和会议的审稿人和程序委员,担任中国人工智能学会副秘书长。获得中国图象图形学学会技术发明一等奖(第1发明人),电子学会技术发明一等奖1项(第2发明人),获授权发明专利11项,其中美国专利1项。
报告摘要: 针对人的运动感知和重建是计算机图形学、计算机视觉领域的热点研究问题,以人脸、人体、人手以及全身为研究对象的相关技术,对影视、游戏、虚拟/增强现实等应用场景具有重要意义。随着技术的不断发展,在纯人感知与重建的基础上,人与物体的交互场景受到越来越多研究者的关注,成为这一领域的前沿方向之一,有望对未来机器人、人机交互等技术的发展注入新的活力。然而交互运动中人与物体互相遮挡,物体复杂运动的引入等,都给问题的解决增加了新的困难,本报告将针对这些新的困难,探讨可能的解决思路和方法。
图像视频处理与理解专题
特邀报告一
报告题目:计算摄像的奇妙之旅
特邀讲者:曹汛 南京大学

讲者简介: 主要从事计算摄像学的交叉领域研究,提出了棱镜-掩模调制的光谱视频成像方法(PMVIS)并研制了系列光谱相机装置,被国际上广泛报道为光谱视频成像的三种代表性技术之一,光谱融合的关键技术被写入M.I.T.最新出版教材<Computational Imaging, 2022>。研究成果成功应用于安全侦察、工业检测等重点行业领域,因“光谱视觉预警技术在监控化工介质泄漏、保障安全生产的重要贡献”获第26届中国青年五四奖章。近年来在Nature子刊、信号处理(IEEE SPM、T-PAMI)、光学(Light、Optica)、视觉和图形学(CVPR、IJCV、SIGGRAPH)等交叉领域发表论文37篇,授权国内外发明专利51项,受邀撰写Springer视觉大百科全书《多光谱/高光谱成像》章节。担任 IEEE T-CSVT、IEEE SPL 期刊编委、CVPR 领域(计算摄像)主席。
报告摘要:视觉占据了人类和客观世界交互总信息量的80%左右,从公元前400年墨子描述“小孔成像”到哈勃望远镜、显微镜/显纳镜,再到现在数以十亿计的手机摄像头和车载摄像头,超越人眼的视觉信息获取和处理能力,一直是人类孜孜以求的目标,形成了一系列璀璨夺目的变革式技术。计算摄像学是视觉信息获取的前沿交叉方向,旨在综合运用电子、计算机/人工智能、光学等多学科知识,拓展全新成像理论与方法,构建新型成像技术及装置,实现“看得更远、看得更清、看得更广”等目标。本报告从多维度视觉信息获取的国内外前沿向大家呈现计算摄像的奇妙之旅。
特邀报告二
报告题目:信源信道联合编码——从图像到任务
特邀讲者:范晓鹏 哈尔滨工业大学

讲者简介: 哈尔滨工业大学计算学部长聘教授、博导、智能接口与人机交互研究中心主任、国家重点研发计划项目负责人,入选教育部长江学者、新世纪优秀人才、哈工大青年拔尖人才、哈工大百人计划、微软亚研院铸星计划等。2009年于香港科技大学电子与电机工程系获博士学位;2013年获IEEE标准杰出贡献奖。主要研究兴趣包括数字媒体技术、人工智能等,发表IEEE TIP、IEEE TVCG、IEEE TCSVT、ACM MM、DCC等国际期刊和会议论文150余篇。获得发明专利20余项,18项技术被IEEE1857(AVS)标准采纳,主持开发了AVS第一个3D视频编码平台。2013年作为副主编及主要起草人之一,制定了IEEE视频编码标准《IEEE 1857.2》。作为程序主席主办了CCF推荐会议PCM2017。
报告摘要:图像视频已占互联网流量的90%,且仍在不断增长。随着视频编码技术进步以及标准迭代,视频压缩效率不断提升。然而经过压缩的视频对于比特错误比较敏感,如何提升无线传输条件下视频抗噪能力,是目前仍然需要解决的问题。本报告将首先回顾传统信源信道联合编码、数模混合视频通信等技术,然后介绍新兴的为视频编码带来较大效率提升的AI技术,包括基于深度学习的视频编码、基于深度学习的多任务编码等,并探讨这些技术应用于信源信道联合编码的新思路和新途径。
特邀报告三
报告题目:暗光影像增强计算
特邀讲者:刘家瑛 北京大学

讲者简介:刘家瑛,博士,北京大学王选计算机研究所副教授,博士生导师,教育部青年长江学者,北京大学博雅青年学者。2010年7月,毕业于北京大学计算机应用技术专业,获理学博士并留校任教,2012年8月晋升为副教授。2015年,在微软亚洲研究院任铸星计划访问研究员。研究领域为智能媒体计算与视觉理解。累计发表IEEE汇刊与CCF A类论文80余篇,谷歌学术引用9500余次,其中ESI高被引论文2篇,获得授权国家发明专利70余项。担任APSIPA杰出讲者,IEEE/CSIG/CCF高级会员,IEEE CASS-MSA/VSPC技术委员会委员,CSIG多媒体专委会秘书长。担任IEEE Trans. on Image Processing, IEEE Trans. on Circuit System for Video Technology等期刊编委,ACM ICMR/IEEE ICME指导委员会委员,ACM ICMR-2021/IEEE ICME-2021/IEEE VCIP-2019会议程序委员会主席,CVPR/ICCV/ECCV/AAAI会议领域主席等多个国际会议组织工作。获教育部科技进步二等奖、CSIG石青云青年女科学家奖、北京大学首届教学卓越奖、王选青年学者奖,IEEE ICME 2020最佳论文奖等。主讲的全球MOOC课程获教育部首批“国家精品在线开放课程”,教育部首批国家级一流本科课程。个人网页:http://www.wict.pku.edu.cn/struct/
报告摘要:在低光照场景下进行图像/视频拍摄会导致一系列的视觉降质问题,例如暗光、欠曝、低对比度以及强噪声等。这些视觉降质既对人眼主观视觉体验造成干扰,又对计算机视觉应用构成影响。我们的工作试图系统性地探究低光照增强方法在两类情境中面临的挑战,以及如何通过暗光照增强提升两类应用的可用性和鲁棒性。通过以暗光环境下重建和检测的Benchmark为切入点,探讨底层视觉增强与高层视觉感知之间的联合关系,以期进一步提升智能影像计算性能。
特邀报告四
报告题目:视觉识别:从可用走向可信
特邀讲者:邓伟洪 北京邮电大学

讲者简介:北京邮电大学鸿雁人才特聘教授,网络空间安全学院副院长,研究方向为计算机视觉与模式识别、可信人工智能、情感计算、多模态学习。近年来主持国家重点研发计划课题、国家自然科学基金等项目30余项,与华为、中兴通讯、滴滴出行、阿里巴巴、腾讯、中国移动、佳能信息技术公司等企业开展广泛的技术合作,在IEEE TPAMI、IJCV、TIP、 ICCV、CVPR等国际期刊和会议上发表论文100多篇,累计被引用万余次,曾担任ACM MM、ECCV、IJCAI、ICME、ICPR等会议的领域主席,入选北京市优秀博士学位论文、北京市科技新星、教育部新世纪优秀人才、教育部青年长江学者、Elsevier中国高被引学者等。
报告摘要:海量标注数据和深度学习技术推动了视觉识别的广泛应用,现有模型在数据集上的性能已经超越人眼。然而,在真实世界中,训练和测试的环境差异、地区差异、伪造和对抗攻击等挑战导致大部分视觉识别应用的稳定性仍不理想,甚至造成种族偏见等伦理问题和伪造人脸等安全问题等。同时,隐私保护和数据安全也引起了人们的广泛担忧。本报告将从数据集建设、深度学习算法和性能评价等角度,汇报近期在以下方面的研究进展:1)高精度识别模型的自主学习;2)识别鲁棒性及SL/CA/CPLFW数据集;2)安全及隐私保护和TALFW数据集;3)识别公平性及RFW数据集;4)连续空间细粒度情感识别及RAF-ML/RAF-AU数据集。
图像视频处理与理解专题
特邀报告一
报告题目:弱监督遥感影像处理与分析
特邀讲者:方乐缘 湖南大学

讲者简介:方乐缘,博士,湖南大学岳麓学者特聘教授,国家优青,科睿唯安(Clarivate Analytics)全球“高被引科学家”,自动化系系主任,担任IEEE Transactions on Image Processing、IEEE Transactions on Neural Networks and Learning System、IEEE Transactions on Geoscience and Remote Sensing、Neurocomputing等机器学习与计算机视觉领域国际知名期刊编委。研究成果在国际权威期刊和会议发表论文130余篇,其中SCI期刊发表论文90余篇,IEEE CVPR、ICIP等国际权威会议论文30余篇,Google scholar引用超过8000次,ESI高被引(1%)18篇,ESI热点论文(0.1%)4篇,获国家自然科学二等奖一项(排名第二),湖南省自然科学一等奖(排名第二)、湖南省优秀博士论文、IEEE Transactions on Geoscience and Remote Sensing最佳审稿人等奖项。近年来,主持了国家重点研发课题、JKW创新特区、湖南省重点研发等项目。
报告摘要: 深度学习因其出色的性能在遥感影像处理分析中已被广泛应用,但深度学习是数据驱动的监督学习方法,其性能严重依赖于海量高质量的数据。实际应用中,难以获得高质量遥感影像来训练深度学习模型;一方面遥感影像分辨率低,不利于观测并解译精细地物信息;另一方面完整标注的遥感影像获取难度大,需要相关专业背景,甚至是实地踏勘。这些严重制约了深度学习方法在遥感领域的应用。本报告首先针对遥感影像分辨率受限问题,提出盲空间超分辨率和盲光谱超分辨率方法;其次,针对遥感影像完整标注困难、时间代价昂贵的问题,提出基于点标签的解译方法;最后,针对遥感影像分辨率提升会大幅提高计算代价的问题,提出一种双支路并行网络结构,大幅度减少了训练时间,并不增加推理阶段的运算时间。
特邀报告二
报告题目: 行为理解与具身智能特邀讲者:卢策吾 上海交通大学

讲者简介: 卢策吾,上海交通大学教授,博士生导师,2016年或海外高层次青年引进人才,2018年被《麻省理工科技评论》评为35位35岁以下中国科技精英(MIT TR35),2019年获求是杰出青年学者,2020年获上海市科技进步特等奖(第三完成人),2021获中国高被引学者。以通讯作者或第一作者在《自然》,《自然·机器智能》,TPAMI等高水平期刊和会议发表论文100多篇;担任《Science》等审稿人,CVPR,ICCV ,ECCV,IROS 领域主席。研究兴趣包括计算机视觉,机器人学习 。
报告摘要:围绕人工智能中的行为理解问题展开讨论,从机器认知角度,如何让机器看懂行为?提出人类行为知识引擎等工作。从神经认知角度:机器语义理解与脑神经行为认知的内在关联是什么?阐释视觉行为理解与其脑神经的内在关联,并建立稳定映射模型。从具身认知角度,如何将行为理解知识迁移到机器人系统?提出PIE(perception- imagination-execution)方案,其中代表工作graspNet首次在未知物体抓取问题上达到人类水平。
特邀报告三
报告题目:大规模图像的多粒度语义理解
特邀讲者:程明明 南开大学

讲者简介:程明明,1985年生,南开大学教授,计算机系主任。主持承担了国家杰出青年科学基金、优秀青年科学基金项目、科技部重大项目课题等。他的主要研究方向是计算机视觉和计算机图形学,在SCI一区/CCF A类刊物上发表学术论文100余篇(含IEEE TPAMI论文28篇),h-index为64,论文谷歌引用3.2万余次,单篇最高引用4300余次,连续6年入选Elsevier中国高被引学者榜单。技术成果被应用于华为、推想、金风、和中化农业等。获得多项省部级科技奖励。现担任中国图象图形学学会副秘书长、天津市人工智能学会副理事长和SCI一区期刊IEEE TPAMI, IEEE TIP编委。
报告摘要: 从图像中快速准确地获取目标信息是计算机视觉的核心任务。鲁棒的目标检测与信息提取需要对不同粒度的信息进行高效的整合。本报告从多层次卷积特征融合、基于短连接的多尺度融合与深度监督、基于分层递进残差设计的层内多尺度特征表达、时序多层次信息提取、霍夫空间度尺度检测、多模型高效融合、多图像联系分析等角度入手,系统地介绍南开大学媒体计算团队在边缘检测、显著性物体检测、图像分类、语义分割、物体检测、关键点估计、视频动作分割,语义线检测、行人计数、年龄估计、图像超分辨率等领域的最新研究进展。同时,本次报告也将从实例、图像、以及整个数据集三个粒度出发,对大规模图像集合进行联合分析,以减少图像理解算法对大规模精确标注的依赖。
特邀报告四
报告题目:跨模态序列生成
特邀讲者:赵洲 浙江大学

讲者简介:赵洲,浙江大学计算机学院副教授、博导,2015年博士毕业于香港科技大学。主要研究方向是面向多模态序列的理解、生成和泛化学习,在NIPS、ICLR、ICML、ACL、CVPR、ACM MM等论文发表50余篇,被引用6000多次(Google Scholar)。主持多个国家自然基金项目和浙江省杰青项目,担任上海高等研究院-海康威视联合研究中心主任。获得2021年中国电子学会科技进步一等奖、入选2020年杭州市十大青年科技英才、2018年福布斯中国科学领域30U30、浙江省151人才工程第二层次。
报告摘要: 随着信息技术的飞速发展,多模态数据近年来成为人机交互场景中数据的主要形式。跨模态序列生成是实现人机智能交互的关键技术之一。现有跨模态序列生成方法在人机交互场景下,存在着跨模态序列生成的实时性不足、模型序列推理的并行性缺乏和生成高质量序列内容的模型轻量化等挑战。针对面向智能人机交互场景中跨模态序列生成的上述挑战,本次报告主要介绍人机交互场景中的跨模态序列合成研究成果以及在手语、唇语、语音等不同模态序列合成的应用。
特邀报告五
报告题目:基于注意力机制的视频动作识别与目标跟踪
特邀讲者:王利民 南京大学

讲者简介:王利民,南京大学教授,博士生导师。2011年在南京大学获得学士学位,2015年香港中文获得博士学位,2015年至2018在苏黎世联邦理工学院(ETH Zurich)从事博士后研究工作。主要研究领域为计算机视觉和深度学习,专注视频理解和动作识别,在IJCV、T-PAMI、CVPR、ICCV等重要学术期刊和会议发表论文50余篇。根据Google Scholar统计,论文被引用 14000余次,两篇一作论文取得了单篇引用超过3000的学术影响力。提出的TSN网络获得首届ActivityNet比赛冠军,已经成为动作识别领域基准方法。2018年入选国家高层次青年人才计划,曾获得广东省技术发明一等奖,世界人工智能大会青年优秀论文奖。入选AI 2000人工智能全球最具影响力学者榜单(计算机视觉方向),2022年度全球华人AI青年学者榜单,2021爱思唯尔中国高被引学者榜单。
报告摘要:视频内容理解已经成为人工智能研究的热点和难点,其中动作识别和目标跟踪已经成为视频理解领域的关键技术。在本次报告中,我们主要介绍南京大学媒体计算课题组MCG在视频动作识别和目标跟踪方面的系列工作。首先,针对视频数据的表征与建模,我们提出了基于注意力机制的时序建模网络TAM和TDN,在计算效率和识别精度方面都取得了较优效果。其次,针对视频模型的高效学习,我们提出了基于掩码自编码器的视频自监督学习方法VideoMAE,验证了MAE一种数据高效的Transformer自监督训练框架,并且在下游动作识别和检测基准数据库上取得优异性能。针对视频目标的跟踪技术,我们提出了更加简洁的单目标跟踪框架MixFormer,统一了特征提取和特征融合模块,在5个主流跟踪数据集都取得了目前最好的跟踪精度。最后将总结和展望基于注意力机制的视频表征学习和内容理解技术的发展趋势。
青托与优博论坛
特邀报告一
报告题目:联合计算之异构联邦学习
特邀讲者:叶茫 武汉大学

讲者简介:叶茫,武汉大学教授,国家优青(海外)、中国科协青年托举人才、湖北省百人计划创新人才。主要研究方向计算机视觉、联邦学习等,发表国际期刊会议论文 70 余篇,其中第一/通讯作者发表 CCF-A 类论文30余篇,谷歌学术引用 3400 余次,9篇第一作者论文引用过百。主持湖北省重点研发计划、国家自然科学基金面上项目等10余项科研项目。获谷歌优秀奖学金、计算机视觉顶会 ICCV2021 无人机特定行人检索赛道冠军、2021年斯坦福排行榜 “全球前2%顶尖科学家”、2022年度百度AI华人青年学者(计算机视觉领域)等荣誉。
报告摘要:联邦学习在保证数据隐私及合法合规的基础上,实现多方共同建模,联合提升模型性能。然而现有联邦学习方法在面临模型结构不一致、训练样本少、多方样本噪声等问题时,性能急剧下降。本次报告主要分享团队近期在异构联邦学习方面的一些进展:1)小样本的异构联邦学习, 实现少样本下模型异构的多方合作;2)噪声鲁棒的异构联邦学习:缓解各模型在本地更新时对噪声的过拟合,同时避免了合作学习时噪声参与者的过度学习;3)互相关蒸馏的异构联邦学习,提升联邦学习的跨域泛化能力,为面向复杂世界的大数据联合计算提供技术支撑。
特邀报告二
报告题目:面向无约束场景下的图象/视频深度理解
特邀讲者:赵健 军事科学院

讲者简介:赵健,中国图象图形学学会高级会员、北京图象图形学学会理事,博士毕业于新加坡国立大学,导师为冯佳时教授和新加坡工程院院士、AAAI/ACM/IEEE/IAPR Fellow颜水成教授。赵博士近5年受理国家专利5项(序1),发表高水平学术论文40余篇,单篇影响因子最高24.314,其中,以第一/通讯作者发表CCF A类论文11篇(含2篇T-PAMI、2篇IJCV)。他曾作为第一作者获得PREMIA'19 Lee Hwee Kuan奖和ACM MM'18最佳学生论文奖,并多次获得权威国际竞赛全球冠军。他的研究成果被包括图灵奖得主Yoshua Bengio和多位国内外院士、AAAI/ACM/IEEE/IAPR Fellow在内的权威学者引用和正面评价。赵博士有近8项技术在国家部委单位和科技行业领军企业得到应用,此外,他还开放了学界首个大规模无约束人脸识别平台(face.evoLVe),已被同行Star 3k余次、Fork 700余次,并被百度PaddlePaddle官方引入。赵博士曾入选北京市科协&中国科协“青年人才托举工程”,主持/参与科技委项目3项(序1/1/3),国自然青年科学基金项目1项。同时,他还担任CSIG高级会员、CSIG-BVD/CCF-CV委员、CSIG/BSIG青工委委员、BSIG理事会理事、VALSE资深领域主席和PRL/Electronics特刊客座编辑,T-PAMI、NeurIPS等本领域主流国际期刊/会议受邀审稿人。
报告摘要:近年来,深度学习算法和技术在学术界与工业界的众多领域取得了诸多突破性进展。在计算机视觉领域,深度学习算法和技术在很多基准数据集都极大改善并提升了图象/视频理解的性能。然而,在涉及视频监控、区域安防、自动驾驶、群体行为分析等实际场景时,图象/视频理解的性能表现还是不尽如人意,有关问题还需不断做出改进与完善,寻求更优解决方案。我们多年来围绕“面向无约束场景下的图象/视频深度理解”进行研究,形成了连贯清晰的研究思路与渐成体系的研究方法,并在复杂环境下基于多光谱多模视频目标融合感知和无约束人物图像/视频深度理解等关键科学问题和实际应用领域取得了较大技术突破,相关研究成果在北京2022年冬奥会中进行了创新、转化和应用,助力科技冬奥。
特邀报告三
报告题目:图文匹配模型小型化探索
特邀讲者:黄岩 中科院自动化研究所

讲者简介:黄岩,中科院自动化所副研究员,研究方向为视觉-语言理解和视频分析。在相关领域的国内外期刊和会议上发表论文共计80余篇,曾获CVPR Workshop最佳论文奖、ICPR最佳学生论文奖等,并担任CVPR和ICCV上3次多模态主题研讨会的共同组织主席。曾入选中国科协青年人才托举工程、北京市科技新星计划和微软铸星计划。获得中国人工智能学会优秀博士论文奖、中国科学院院长特别奖、百度奖学金、NVIDIA创新研究奖。
报告摘要:图文匹配(Image-Text Matching)是视觉-语言理解领域的基础任务之一。近年来,大量研究人员围绕此任务进行了深入研究,特别是在视觉-语言预训练模型出现之后,该任务的精度被迅速提升到高位,甚至开始接近饱和。本报告首先梳理该任务的发展历程及代表性方法,然后重点介绍课题组在图文匹配模型小型化方面的最新进展,最后将简要展望未来研究方向。
特邀报告四
报告题目:细粒度跨媒体分类与检索
特邀讲者:何相腾 北京大学

讲者简介:何相腾,北京大学王选计算机研究所助理研究员。主要研究方向为跨模态分析、细粒度图像分类、计算机视觉和人工智能等,已发表论文18篇,包括国际顶级的IEEE Trans.和CCF A类论文14篇,其中IEEE TIP 2018入选ESI高被引论文;连续三年参加由美国国家标准技术局举办的国际评测TRECVID视频样例搜索比赛,均获第一名。担任中国计算机学会多媒体技术专业委员会执行委员、中国图象图形学学会多媒体专委会委员、北京图象图形学学会青年工作委员会委员,人工智能领域国际会议IJCAI 2021高级程序委员(SPC),CVPR 2022细粒度视觉分类Workshop共同组织者,IEEE TIP、TNNLS、TMM、TKDD、TCSVT、CVPR、IJCAI、AAAI、ACM MM等国际期刊和会议审稿人。获2020年CCF优秀博士学位论文奖(全国每年不超过10名获奖者)、2018年百度奖学金(全球每年不超过10名获奖者),2020年北京大学优秀博士学位论文奖,2020年北京大学优秀毕业生、2020年北京市普通高等学校优秀毕业生。
报告摘要: 互联网数据具有图像、文本、视频、音频等跨媒体并存的特点,而现有跨媒体分类与检索技术通常聚焦于粗粒度的大类,难以满足医疗、交通等诸多领域的精细化需求。而细粒度跨媒体分类与检索旨在使计算机能够对跨媒体内容进行精细化分析。如何借鉴人脑的认知机理,模拟注意力机制学习多粒度的辨识性特征,突破细粒度跨媒体分类与检索难题,对于提高计算机的感知和认知能力至关重要。本报告将梳理细粒度跨媒体分类与检索方向的研究现状与进展,并探讨未来研究方向。
特邀报告五
报告题目:场景知识引导的视觉导航研究
特邀讲者:宋新航 中科院计算技术研究所

讲者简介:宋新航,男,中国科学院计算技术研究所副研究员,于2017年博士毕业于中国科学院大学,获中科院院长特别奖,中国图象图形学学会优博,也曾获博新计划支持。主要研究方向为多模态场景理解与视觉导航,曾在IEEE TPAMI, TIP, CVPR, ICCV, NeurIPs, AAAI, IJCAI, ACM MM等CCF-A期刊与会议发表论文,其中一作CCF-A类论文10篇。相关技术曾获ImageCLEF2013多模态视觉理解竞赛,ACM Multimedia 2016图像描述竞赛,CVPR2021具身智能视觉导航竞赛等多项竞赛冠军,也曾获中国图象图形学学会自然科学二等奖、北京市科技进步二等奖。
报告摘要: 物体导航任务要求智能体在不同环境中找到给定的目标物体。传统方法一般基于建图与定位技术实现导航,虽然在已知环境中效率较高,但对于未知环境需重复建图则效率不佳。面向未知环境,我们从视觉到行为的端到端可学习模型研究出发,利用强化学习训练深度模型以实现智能体的导航行为预测。端到端深度强化模型一般需要大量数据驱动,由于在未知环境的大部分区域中智能体无法观测到目标物体,会导致奖惩函数稀疏,所训练模型一般难以规划最优路径,会导致导航效率较低等问题。为提升未知环境下的导航能力,我们提出了场景知识引导的目标导航模型,在模拟器\真实环境中通过研究RGB-D多模态场景理解及物体识别技术,以构建场景-区域-物体-属性等多维度场景知识图,基于知识图预测并规划到目标的语义拓扑路径,以指导智能体的行为输出。知识图可基于已知环境预训练,并在未知环境导航过程中在线更新,以快速适应未知环境,我们在类别级和实例级目标导航任务中分别验证了所提出方法的有效性。
特邀报告六
报告题目:开放场景中人脸表情分析方法研究
特邀讲者:李勇 南京理工大学

讲者简介: 李勇,男,南京理工大学教师, 2021年中国图象图形学学会优博。2020年7月毕业于中国科学院计算技术研究所,博士阶段主要从事人工智能、模式识别与情感计算方面的研究工作。其研究成果以第一作者发表在IEEE T-PAMI,IEEE T-IP,《中国图象图形学报》,CVPR,TAC等国内外重要学术期刊和会议上,谷歌学术引用650余次,其中发表于T-IP 2019的工作入选IEEE T-IP 2020 Top 25下载文章。入选江苏省双创博士高校创新人才计划,曾以第一完成人获2017年ACM Multimedia 亲子关系验证国际竞赛冠军,2019年虑得企业冠名奖学金,2020年中国科学院朱李月华优秀博士毕业生奖学金,2022年ChinaMM最佳海报奖。
报告摘要: 自动化的人脸表情分析是人机交互的关键步骤,也是情感计算的重要研究内容。在开放场景中,由于受个体差异、遮挡、头部姿态等因素的影响,自动化的人脸表情分析依然存在若干挑战。此外,开放场景中很难收集大量包含丰富表情变化并且标注完整的训练数据,数据不足进一步加剧了开放场景中人脸表情分析的难度。本次报告将介绍利用增广的遮挡数据、无标签视频人脸数据、异质标注的人脸表情数据、基于反事实视频数据进行表情分析模型学习的方法。所提方法从人脸表情的定义和先验知识出发,将信号解耦于自监督学习相结合,提出了利用大规模无标注视频的表情特征自监督学习方法,并进一步引入注意力机制缓解部分遮挡带来的影响,有力地推动了表情识别问题的解决。相关方法不但能够有效提升开放场景中人脸表情分析精度,而且具有良好的可解性性,得到了国内外同行的广泛关注。
学术新星论坛
特邀报告一
报告题目:多模态紧致表示学习
特邀讲者:朱磊 山东师范大学

讲者简介: 朱磊,山东师范大学教授,博士生导师,IEEE高级会员。主要研究方向是跨模态分析与检索。共发表或录用论文中国计算机学会(下简称CCF)推荐A类会议长文、ACM/IEEE的汇刊论文百余篇(第一作者或通讯作者35篇)。Google Scholar引用4400多次,H-index为36,ESI高被引论文7篇。获得CCF A类会议ACM SIGIR 2019的唯一最佳论文提名奖,CCF A类会议ACM MM 2019的最佳论文提名(5篇最佳候选论文之一),ADMA 2020的最佳论文奖,ChinaMM 2022最佳学生论文奖,1篇论文入选2019年中国百篇最具影响国际学术论文。拥有授权专利22件(第一发明人6件)。担任期刊IEEE Transactions on Big Data、Information Sciences的编委,任多媒体领域权威国际会议ACM MM领域主席,CIKM、AAAI高级程序委员会委员。主持基金委青年/面上项目、山东省优秀青年基金项目,参与基金委重点项目、山东省自然科学基金重大基础研究项目等10余项横纵课题。获得ACM中国SIGMM新星奖,山东省留学回国人员创业奖、山东省人工智能优秀青年奖等。
报告摘要: 哈希是一种紧致表示学习技术。它可以将高维数据转换为紧致的二值哈希码。由于二值汉明空间的嵌入,哈希技术在相似度计算和存储方面具有明显的效率优势。因此,哈希已成为支撑大规模多媒体检索的一种有效技术。多媒体数据具有多模态、异构、存在噪声、模态易缺失、流式生成等特点。如何高效地学习包含多媒体语义的紧凑二值哈希码具有一定的挑战性。在本次报告中,我将介绍面向多模态数据的哈希表示方法,介绍如何深度建模多模态潜在语义和高效学习二值哈希码的方法。
特邀报告二
报告题目:跨模态噪声关联学习:一种新的噪声标签学习范式
特邀讲者:胡鹏 四川大学

讲者简介:胡鹏,四川大学副研究员。2019年毕业于四川大学并获得博士学位。2019至2020年在新加坡信息通信研究所(I2R, A*STAR)担任研究员。主要研究兴趣包括表示学习及其在多媒体分析、图像处理等领域中的应用,目前在IEEE TPAMI, IEEE TIP, CVPR, NeurIPS, AAAI, ACM MM等国际期刊和会议上发表论文30余篇。
报告摘要: 深度神经网络的成功依赖于高质量标记的训练数据,而收集良好标注的大规模跨模态数据的成本高昂。为了降低数据收集的高成本,可从互联网上收集同时出现的跨模态对(例如图像和文本)作为大规模的跨模态数据集。然而,这将不可避免地会在训练数据中引入噪声(即不匹配的对),称为噪声关联。毫无疑问,这种噪声会使监督信息不可靠/不确定,并显著降低性能。针对这一问题,本次报告将汇报一种新的噪声标签学习范式,称为噪声关联学习(Learning with Noisy Correspondence)。传统的噪声标签学习主要围绕分类任务展开,旨在消除训练样本的错误类别标签所带来的负面影响。不同于标准的噪声标签学习,噪声关联学习旨在削弱甚至消除成对训练数据中的错误关联关系造成的影响,例如多模态训练数据中的图文不匹配,对话系统中的答非所问等。具体地,本次报告将详细汇报一种广义的深度证据跨模态学习框架。该框架将基于跨模态相似性的双向证据建模并参数化为Dirichlet分布,以捕获噪声关联引起的不确定性,这不仅提供了准确的不确定性估计,而且还赋予了对噪声关联扰动的弹性。
特邀报告三
报告题目:面向视频模型的对抗攻击方法研究
特邀讲者:陈静静 复旦大学

讲者简介: 陈静静,复旦大学计算机科学技术学院副教授。上海浦江人才计划入选者。2018年在香港城市大学获得博士学位,2018年9 月~2019年7月在新加坡国立大学从事博士后工作,2019年7月被复旦大学计算机科学技术学院引进为青年副研究员。主要研究领域为多媒体内容分析、计算机视觉、多媒体模型安全等。主持/参与了包括国家自然科学基金、科技部科技部2020年“科技创新2030-新一代人工智能”重大项目、上海市行动创新计划等多项科研项目。在 ACM Multimedia, CVPR, ICCV,AAAI,ICMR,IEEE TIP,IEEE TMM等重要国际会议、期刊上发表论文 40 余篇,曾获得ACM Multimedia 2016最佳学生论文奖、Multimedia Modeling 2017 最佳学生论文奖。担任多个国际知名期刊审稿人、国际会议领域主席/程序委员会委员。
报告摘要:随着以深度学习为代表的新一代人工智能的发展,智能视频技术取得了突破性进展,并广泛应用于生活的方方面面。但是现有的智能视频系统并不安全:恶意生成的细微扰动便可以欺骗智能视频识别系统。因此研究智能视频系统在对抗样本攻击下的安全性已经吸引了大量关注,成为一个重要的研究方向。一方面,研究针对视频模型的对抗样本有助于帮助发现模型的安全漏洞,提高智能视频模型在实际应用中的安全性;另一方面,研究对抗样本的攻防理论有助于加深对深度学习技术机理的理解,以设计更加鲁棒的机器学习算法。本报告将对面向视频识别模型的对抗攻击算法最新进展进行介绍,包括基于启发式搜索的黑盒场景攻击算法,基于时序平移的视频迁移对抗攻击方法以及面向视频识别模型的弹幕攻击等。
特邀报告四
报告题目:基于三维描述的生物特征识别
特邀讲者:朱翔昱 中科院自动化研究所

讲者简介:朱翔昱,中国科学院自动化研究所模式识别国家重点实验室副研究员。长期从事从事三维人脸重建、人脸识别、人脸防伪等方面的相关理论研究与应用,在国际顶级期刊和会议(T-PAMI, IJCV, CVPR, ECCV, ICLR)发表论文50余篇,Google总引用次数6000余次,单篇引用超过2000次。中科院青促会成员,入选百度学术全球华人AI青年学者榜单,担任ACM MM(CCF:A类)领域主席。相关成果获中国电子学会科技进步二等奖,ICCV人脸识别、FG人脸微表情等国际赛事冠军,中国图象图形学学会优秀博士论文提名奖,授权国家发明专利6项。研发的全姿态三维人脸重建受到国内外同行的广泛关注(谷歌学术引用1200余次),相关开源代码在Github上收获4700星,并被PyTorch官方Twitter报道。CCF-CV及CSIG-MV专委会委员,IJCV、IEEE TIP、IEEE TCSVT等国际期刊审稿人。主持北京科协青年人才托举工程、腾讯犀牛鸟专项研究计划、基金委面上及青年项目。
报告摘要:三维辅助视觉分析通过拟合三维模型使视觉系统获得对物体的三维理解,从而提高鲁棒性和泛化性的方法,是生物特征识别领域的前沿热点之一。本次分享将基于三维重建和三维辅助两个主题,介绍我们在三维人脸重建、三维辅助人脸分析、基于三维描述的生物特征识别上的最新成果,探讨如何在实际场景下快速准确地重建目标三维结构,并基于三维结构辅助视觉分析任务。
特邀报告五
报告题目:人-物-场的神经建模与渲染方法
特邀讲者:高林 中科院计算所

报告摘要:随着数字经济和虚拟数字世界的发展,数字内容成产愈发成为数字经济的关键支撑技术。数字内容即可以来自对真实世界的复刻也可以来自于用户的个性化创作,其中数字内容主要包含人、物和场景,如何对人-物-场进行高效高质量的建模成为热点和重点的研究问题。在本次报告中,我们将分享基于可微分方法的数字内容的重建与创造方法,包括数字几何模型与场景的重建、建模与编辑和数字人的重建与创作方法以及数字场景的合成方法。
承办/协办/赞助单位介绍
湖南大学坐落于中国历史文化名城长沙,前临碧波荡漾的湘江,后倚秀如琢玉的岳麓山,素有“千年学府、百年名校”之称。
学校办学起源于公元976年创办的岳麓书院,是中国同址办学时间最长的高等学府。1903年改制为湖南高等学堂,1926年正式定名湖南大学,1937年成为全国16所国立大学之一。2000年,湖南大学与湖南财经学院合并组建成新的湖南大学。改革开放以来,学校先后进入全国重点大学、“211工程”、“985工程”和“世界一流大学”建设高校行列。2020年9月17日,习近平总书记来校考察调研,对学校人才培养、文化传承等给予高度评价,提出了岳麓书院是党的实事求是思想路线策源地的重大科学论断。
在长期的办学历程中,学校培育和熏陶了以王夫之、陶澍、魏源、贺长龄、曾国藩、左宗棠、郭嵩焘、谭嗣同、黄兴、蔡锷、杨昌济、毛泽东、何叔衡、蔡和森、邓中夏、李达等为代表的一大批彪炳史册的杰出人才。师生中涌现出39位学部委员和“两院”院士,“惟楚有材,于斯为盛”是学校人才辈出的生动写照。
学校下设27个学院,学科专业涵盖哲学、经济学、法学、教育学、文学、历史学、理学、工学、管理学、医学、艺术学等11大门类,形成了理科基础坚实、工科实力雄厚的学科布局。拥有本科专业74个,硕士学位授权一级学科35个、博士学位授权一级学科30个、博士后科研流动站28个。国家重点学科一级学科2个、国家重点学科二级学科14个。7个学科入选国防特色学科,化学、机械工程、电气工程学科进入 “世界一流学科”建设行列。
学校现有教职工4400余人,其中专任教师2293人,院士12人,国务院学位委员会学科评议组成员11人,国家级特殊人才65人,国家杰出青年科学基金获得者25人,国家优秀青年科学基金获得者31人,国家级教学名师7人,科技部创新人才推进计划中青年科技创新领军人才14人。拥有国家自然科学基金“创新研究群体”项目6个、国家级教学团队11个,教育部、国防科技工业局创新团队9个。入选中国高被引学者100人次,全球高被引学者32人次。
学校科研实力雄厚,科技成果突出。拥有国家重点实验室2个、国家工程技术研究中心2个、国家工程研究中心1个、国家级国际合作基地3个、国防科工局国防重点学科实验室1个、教育部重点实验室和工程研究中心9个、教育部高等学校学科创新引智基地5个。“十三五”以来,获国家科学技术奖16项(牵头11项),教育部人文社科奖9项。学校建有国家级大学科技园,获批教育部首批高等学校科技成果转化和技术转移基地,与33个省(市、区)和上千家企业建立了产学研合作关系。
学校校园环境优美,人文气息浓郁。位于国家5A级风景名胜区核心景区,校园占地面积241万平方米,校舍建筑面积134万平方米,典雅厚重的古建筑群与时尚新锐的新建筑体交相辉映,自然风光与人文景观深度融合,被誉为“中国最诗情画意的高校 ”。
中国图象图形学学会青年工作委员会旨在促进青年学者之间的交流与合作,提供学术交流的平台。青年工作委员会在中国图象图形学学会的领导下,主要的工作有:
1.组织青年会议/沙龙活动;
2.受中国图象图形学学会委托,制定和完善“青年人才托举”制度、推荐中国青年科学家奖候选人等;
宝德计算机系统股份有限公司(简称“宝德计算”)成立于2003年,是以服务器和PC整机的研发、生产、销售及提供相关的综合解决方案为主营业务的国家级高新技术企业和国家专精特新“小巨人”企业,致力于成为中国领先的IT产品和解决方案提供商,为政府、互联网、教育、金融、电力、交通、医疗、运营商、安平等行业客户持续提供先进的算力产品、解决方案和全栈服务。多年来,凭借不断创新的产品技术和独特的软硬件综合实力,宝德计算勇夺信创市场NO.1,稳居X86服务器国内品牌TOP5和全球TOP9、中国AI服务器NO.3。
宝德计算坚持以客户需求为驱动力,注重研发创新,拥有敏锐的市场洞察力和雄厚的技术实力,曾多次填补国内服务器技术空白,引领服务器先进技术发展方向。宝德拥有从板卡到整机系统的完全自主研发和灵活定制能力,并且坚持Level 0-Level 9算力产业链的自主研发,是国内最早从事自主安全产品研发的厂商之一,并且在独到的加固、保密和安全等产品技术领域有深厚的积累。目前,宝德计算已经完成了X86产品线、自强产品线、特种领域产品线、产品和行业综合解决方案等完善的算力布局,拥有服务器、存储、台式机、工控机、IOT、网络、大终端等产品和解决方案,赋能AI、云计算、大数据、5G、区块链、元宇宙等新兴技术创新和应用,为新基建、信创、东数西算、社会经济的数字化和智能化转型升级提供坚实的算力底座。
积极合作共谋发展。宝德计算坚持与产业链上下游生态伙伴的合作,打造多元化计算产业生态。在上游供应端,宝德与英特尔、英伟达、希捷等国际厂商和华为、飞腾、龙芯等国产厂商都保持紧密友好的战略合作关系,并加强渠道体系完善和对渠道合作伙伴的赋能,同时与成千上万SI\ISV伙伴携手合作,加速应用场景拓展和产品方案的适配,进一步夯实X86开放融合的生态和应用优势,并且构建逐步完善的安全可控计算产业生态,以满足宝德20多年来积累的千行百业数十万客户的多样性需求,共同为企业发展、城市治理、科研创新、行业信息化、产业转型升级、数字经济发展等积极贡献力量。
宝德计算拥有完善的营销服务网络,在全国设立44个营销机构,遍布全国31个省区,拥有北京、广州、深圳、杭州、上海、成都6大备件库,保证第一时间为客户提供全程无忧的售前、售中和售后服务,帮助客户聚焦自身核心业务增长。同时,宝德在全国布局了分布式计算产业基地,已经建成深圳永达、深圳观湖、四川乐山、湖南湘潭、广西南宁、陕西西安、河北张家口和江苏南京八大智能生产基地,全面整合优势资源,加速了交付速度,优化了客户体验。
宝德,计算驱动未来!
湖南工程学院坐落于一代伟人毛泽东的故乡湖南省湘潭市,是湖南省举办的本科院校。学校是教育部“服务国家特殊需求人才培养项目”硕士专业学位研究生教育试点高校、教育部首批“卓越工程师教育培养计划”“新工科研究与实践项目”“新文科研究与实践项目”实施高校;是湖南省首批硕士学位授予立项建设单位、首批“2011计划”入选高校、湖南省“双一流”建设高水平应用特色学院、湖南省本科一批招生单位。
湖南工程学院于2000年6月由原湘潭机电高等专科学校(始创于1951年,隶属于原国家机械工业部,是全国示范性高等工程专科重点建设学校)、湖南纺织高等专科学校(始创于1978年,隶属于原湖南省纺织工业厅)合并组建而成。学校2000年在全国地方高校中率先确立了应用型本科办学定位,形成了鲜明的工程应用型人才培养特色。2007年,以优异成绩通过教育部本科教学工作水平评估;2018年,通过教育部教学工作审核评估。
学校紧密对接区域经济和机电、纺织行业发展需要,以培养高素质应用型人才为目标,形成了电气、机械、纺织、化工、管理、信息等优势专业群,涵盖工、管、文、理、经、艺六个学科门类。现设有20个教学科研单位、53个本科招生专业、2个硕士专业学位类别。拥有湖南省“双一流”建设应用特色学科8个;教育部“卓越计划”实施专业8个;国家级、省级特色专业8个,国家级、省级专业综合改革试点专业6个,国家级一流本科专业建设点6个、省级一流本科专业建设点24个。学校现有国家级实践教育平台4个,国家级大学生科技创新团队1个,省级创新创业平台32个,教育部产学合作协同育人项目197项,国家级一流本科课程1门,省级精品课程11项,省级虚拟仿真实验中心、示范实验室(中心)9个,建有4个现代产业学院。金工实习基地是教育部确定的全国高校金工实习教学指导人员培训与考试中心。
学校坚持人才强校工程,现有教职工1384人,其中专任教师1198人,高级职称教师399人;具有博士、硕士学位教师996人,博士生、硕士生导师178人。全国模范(优秀)教师3人,享受国务院、省政府特殊津贴专家8人,教育部新世纪优秀人才3人,教育部、教育厅专业教学指导委员会委员6人;省级教学名师、省部级优秀教师12人,省级学科带头人14人,湖南省杰青、优青,“湖湘高层次人才”,省“百人计划”,省“新世纪121人才工程”人选等省级人才100余人;省级教学团队、省高校科技创新团队29个。
学校积极推进科学研究,大力提升科技创新和社会服务能力。拥有省“2011”协同创新中心、省重点实验室等省级科研平台25个;省级校地合作基地1个,省高校产学研合作示范基地3个。近五年,承担国家重点研发计划项目、国家自然科学基金等科研项目38项、省部级科研项目364项、横向科研项目1275项,科研经费总额5亿元,获科研成果奖励36项(其中省部级17项),授权专利765项,发表学术论文3214篇,出版学术专著45部。学校大力加强产学研合作,先后与653家企业开展了产学研合作,产生经济效益超过220亿元。2021年,列入全国科技成果转化100强高校。
面向未来,学校将在习近平新时代中国特色社会主义思想指引下,贯彻落实学校第四次党代会精神,继续弘扬“锲而不舍,敢为人先”的校训精神,秉承“团结、严谨、诚信、创新”的优良校风,坚持以立德树人为根本任务,不断深化应用型本科办学定位,坚定不移贯彻新发展理念,以推动高质量发展为主题,以改革创新为根本动力,为全面建成特色鲜明高水平工程应用型大学而努力奋斗。
奥比中光是行业领先的3D视觉感知整体技术方案提供商。公司已构建起“全栈式技术研发能力+全领域技术路线布局”的 3D视觉感知技术体系,在技术纵向上对包括深度引擎芯片、感光芯片、专用光学系统等在内的核心底层技术以及SDK、行业应用算法等全链路技术进行全栈式自主研发,在技术横向上对结构光、iToF、双目、dToF、Lidar、工业三维测量进行全领域布局。
视拓云团队来自山世光老师创建的中科视拓,专注云计算和 AI 开发者社区两个细分领域,面向“大 AI 圈”内的科研工作者运营 AutoDL.com 和 CodeWithGPU.com 两个产品。AutoDL 提供弹性、好用、省钱的 GPU 云算力;CodeWithGPU提供社区和算法复现服务。
来源:CSIG青年工作委员会




