一文看尽21篇目标检测最新论文(腾讯/Google/商汤/旷视/清华/浙大/CMU/华科/中科院等)
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

前言
CVer 有几天没更新论文速递了,主要是这段时间的论文太多,而且质量较高的论文也不少,所以为了方便大家阅读,我已经将其中的目标检测(Object Detection)论文整理出来。本文分享的目标检测论文将同步推送到 github上,欢迎大家 star/fork(点击阅读原文,也可直接访问):
https://github.com/amusi/awesome-object-detection
注意事项:
本文的目标检测论文全都不包含CVPR2019,因为 Amusi 会单独出一期CVPR2019 目标检测论文合集
论文发布时间段:2019年1月~3月
目标检测论文
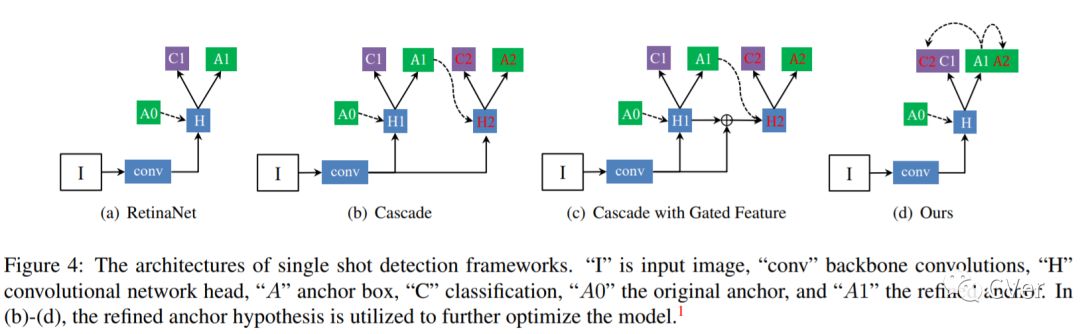
【1】Consistent Optimization for Single-Shot Object Detection
We present consistent optimization for single stage object detection. Previous works of single stage object detectors usually rely on the regular, dense sampled anchors to generate hypothesis for the optimization of the model. Through an examination of the behavior of the detector, we observe that the misalignment between the optimization target and inference configurations has hindered the performance improvement. We propose to bride this gap by consistent optimization, which is an extension of the traditional single stage detector's optimization strategy. Consistent optimization focuses on matching the training hypotheses and the inference quality by utilizing of the refined anchors during training. To evaluate its effectiveness, we conduct various design choices based on the state-of-the-art RetinaNet detector. We demonstrate it is the consistent optimization, not the architecture design, that yields the performance boosts. Consistent optimization is nearly cost-free, and achieves stable performance gains independent of the model capacities or input scales. Specifically, utilizing consistent optimization improves RetinaNet from 39.1 AP to 40.1 AP on COCO dataset without any bells or whistles, which surpasses the accuracy of all existing state-of-the-art one-stage detectors when adopting ResNet-101 as backbone. The code will be made available.
Date:20190123
Author:清华大学&字节跳动等
arXiv:https://arxiv.org/abs/1901.06563v2
解读:清华、宾夕法尼亚大学和字节跳动联合提出:提升Single-Shot目标检测的 Consistent Optimization策略
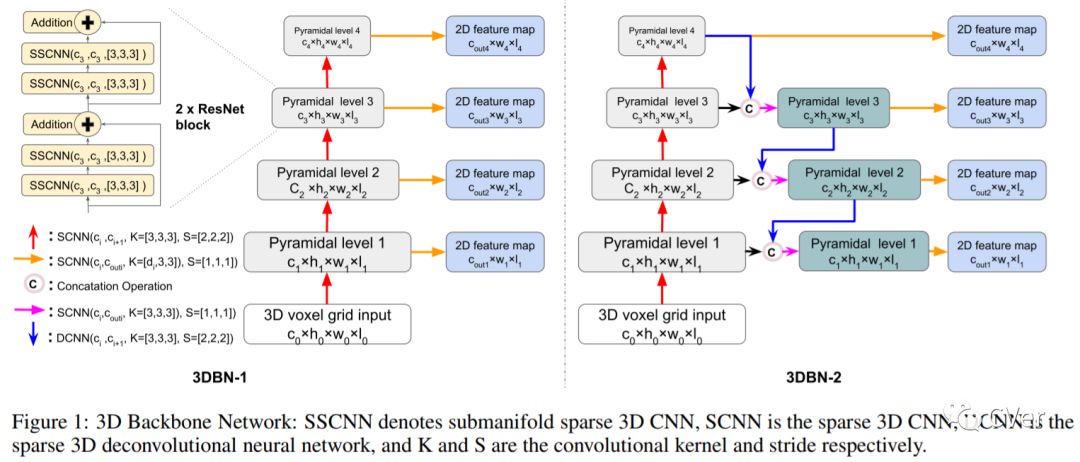
【2】3D Backbone Network for 3D Object Detection
The task of detecting 3D objects in point cloud has a pivotal role in many real-world applications. However, 3D object detection performance is behind that of 2D object detection due to the lack of powerful 3D feature extraction methods. In order to address this issue, we propose to build a 3D backbone network to learn rich 3D feature maps by using sparse 3D CNN operations for 3D object detection in point cloud. The 3D backbone network can inherently learn 3D features from almost raw data without compressing point cloud into multiple 2D images and generate rich feature maps for object detection. The sparse 3D CNN takes full advantages of the sparsity in the 3D point cloud to accelerate computation and save memory, which makes the 3D backbone network achievable. Empirical experiments are conducted on the KITTI benchmark and results show that the proposed method can achieve state-of-the-art performance for 3D object detection.
Date:20190124
Author:新南威尔士大学
arXiv:https://arxiv.org/abs/1901.08373
【3】AdaScale: Towards Real-time Video Object Detection Using Adaptive Scaling
In vision-enabled autonomous systems such as robots and autonomous cars, video object detection plays a crucial role, and both its speed and accuracy are important factors to provide reliable operation. The key insight we show in this paper is that speed and accuracy are not necessarily a trade-off when it comes to image scaling. Our results show that re-scaling the image to a lower resolution will sometimes produce better accuracy. Based on this observation, we propose a novel approach, dubbed AdaScale, which adaptively selects the input image scale that improves both accuracy and speed for video object detection. To this end, our results on ImageNet VID and mini YouTube-BoundingBoxes datasets demonstrate 1.3 points and 2.7 points mAP improvement with 1.6x and 1.8x speedup, respectively. Additionally, we improve state-of-the-art video acceleration work by an extra 1.25x speedup with slightly better mAP on ImageNet VID dataset.
Date:20190208
Author:卡耐基梅隆大学(CMU)
arXiv:https://arxiv.org/abs/1902.02910
【4】Bag of Freebies for Training Object Detection Neural Networks
Comparing with enormous research achievements targeting better image classification models, efforts applied to object detector training are dwarfed in terms of popularity and universality. Due to significantly more complex network structures and optimization targets, various training strategies and pipelines are specifically designed for certain detection algorithms and no other. In this work, we explore universal tweaks that help boosting the performance of state-of-the-art object detection models to a new level without sacrificing inference speed. Our experiments indicate that these freebies can be as much as 5% absolute precision increase that everyone should consider applying to object detection training to a certain degree.
Date:20190215
Author:亚马逊
arXiv:https://arxiv.org/abs/1902.04103v2
【5】Augmentation for small object detection
In recent years, object detection has experienced impressive progress. Despite these improvements, there is still a significant gap in the performance between the detection of small and large objects. We analyze the current state-of-the-art model, Mask-RCNN, on a challenging dataset, MS COCO. We show that the overlap between small ground-truth objects and the predicted anchors is much lower than the expected IoU threshold. We conjecture this is due to two factors; (1) only a few images are containing small objects, and (2) small objects do not appear enough even within each image containing them. We thus propose to oversample those images with small objects and augment each of those images by copy-pasting small objects many times. It allows us to trade off the quality of the detector on large objects with that on small objects. We evaluate different pasting augmentation strategies, and ultimately, we achieve 9.7% relative improvement on the instance segmentation and 7.1% on the object detection of small objects, compared to the current state of the art method on MS COCO.
Date:20190219
Author:Tensorflight&伦敦大学学院等
arXiv:https://arxiv.org/abs/1902.07296

【6】The H3D Dataset for Full-Surround 3D Multi-Object Detection and Tracking in Crowded Urban Scenes
3D multi-object detection and tracking are crucial for traffic scene understanding. However, the community pays less attention to these areas due to the lack of a standardized benchmark dataset to advance the field. Moreover, existing datasets (e.g., KITTI) do not provide sufficient data and labels to tackle challenging scenes where highly interactive and occluded traffic participants are present. To address the issues, we present the Honda Research Institute 3D Dataset (H3D), a large-scale full-surround 3D multi-object detection and tracking dataset collected using a 3D LiDAR scanner. H3D comprises of 160 crowded and highly interactive traffic scenes with a total of 1 million labeled instances in 27,721 frames. With unique dataset size, rich annotations, and complex scenes, H3D is gathered to stimulate research on full-surround 3D multi-object detection and tracking. To effectively and efficiently annotate a large-scale 3D point cloud dataset, we propose a labeling methodology to speed up the overall annotation cycle. A standardized benchmark is created to evaluate full-surround 3D multi-object detection and tracking algorithms. 3D object detection and tracking algorithms are trained and tested on H3D. Finally, sources of errors are discussed for the development of future algorithms.
Date:20190304
Author:本田研究所
arXiv:https://arxiv.org/abs/1903.01568
datasets:https://usa.honda-ri.com/hdd/introduction/h3d


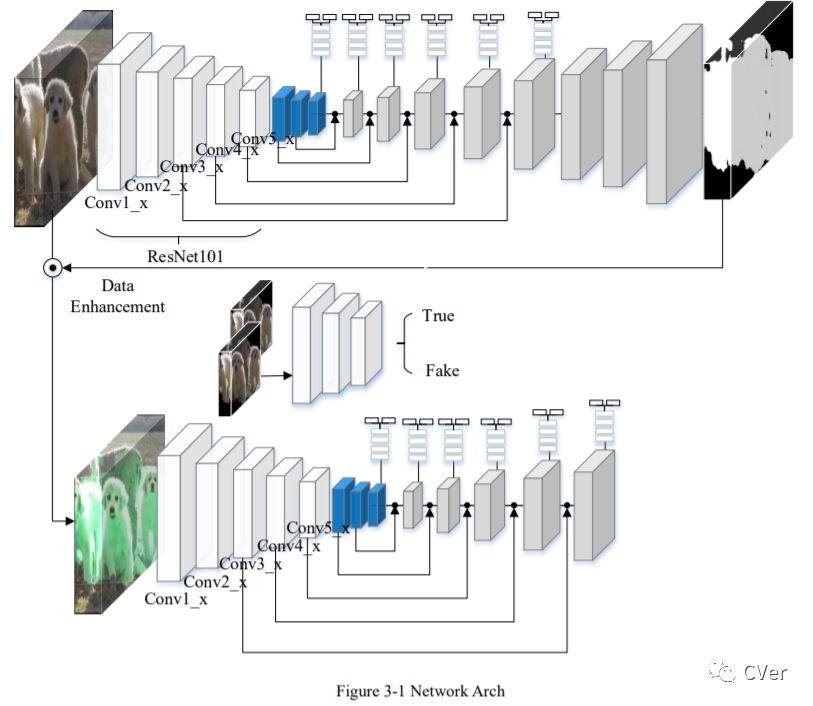
【7】Improve Object Detection by Data Enhancement based on Generative Adversarial Nets
The accuracy of the object detection model depends on whether the anchor boxes effectively trained. Because of the small number of GT boxes or object target is invariant in the training phase, cannot effectively train anchor boxes. Improving detection accuracy by extending the dataset is an effective way. We propose a data enhancement method based on the foreground-background separation model. While this model uses a binary image of object target random perturb original dataset image. Perturbation methods include changing the color channel of the object, adding salt noise to the object, and enhancing contrast. The main contribution of this paper is to propose a data enhancement method based on GAN and improve detection accuracy of DSSD. Results are shown on both PASCAL VOC2007 and PASCAL VOC2012 dataset. Our model with 321x321 input achieves 78.7% mAP on the VOC2007 test, 76.6% mAP on the VOC2012 test.
Date:20190305
Author:
arXiv:https://arxiv.org/abs/1903.01716
【8】SimpleDet: A Simple and Versatile Distributed Framework for Object Detection and Instance Recognition
Object detection and instance recognition play a central role in many AI applications like autonomous driving, video surveillance and medical image analysis. However, training object detection models on large scale datasets remains computationally expensive and time consuming. This paper presents an efficient and open source object detection framework called SimpleDet which enables the training of state-of-the-art detection models on consumer grade hardware at large scale. SimpleDet supports up-to-date detection models with best practice. SimpleDet also supports distributed training with near linear scaling out of box.
Date:20190314
Author:图森未来
arXiv:https://arxiv.org/abs/1903.05831
github:https://github.com/tusimple/simpledet

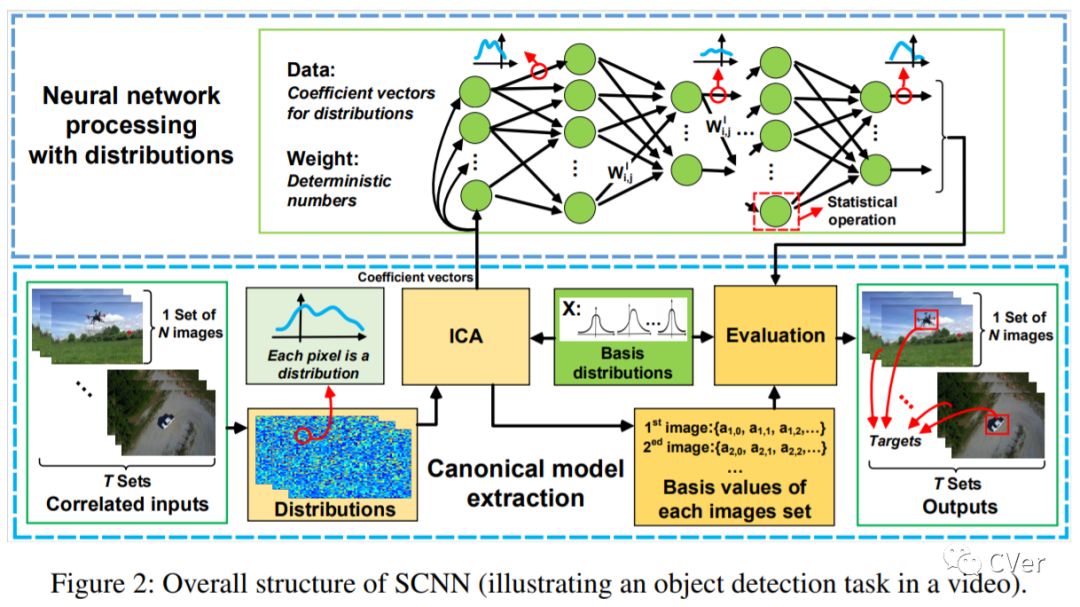
【9】SCNN: A General Distribution based Statistical Convolutional Neural Network with Application to Video Object Detection
Various convolutional neural networks (CNNs) were developed recently that achieved accuracy comparable with that of human beings in computer vision tasks such as image recognition, object detection and tracking, etc. Most of these networks, however, process one single frame of image at a time, and may not fully utilize the temporal and contextual correlation typically present in multiple channels of the same image or adjacent frames from a video, thus limiting the achievable throughput. This limitation stems from the fact that existing CNNs operate on deterministic numbers. In this paper, we propose a novel statistical convolutional neural network (SCNN), which extends existing CNN architectures but operates directly on correlated distributions rather than deterministic numbers. By introducing a parameterized canonical model to model correlated data and defining corresponding operations as required for CNN training and inference, we show that SCNN can process multiple frames of correlated images effectively, hence achieving significant speedup over existing CNN models. We use a CNN based video object detection as an example to illustrate the usefulness of the proposed SCNN as a general network model. Experimental results show that even a non-optimized implementation of SCNN can still achieve 178% speedup over existing CNNs with slight accuracy degradation.
Date:20190315
Author:圣母大学&IBM
arXiv:https://arxiv.org/abs/1903.07663
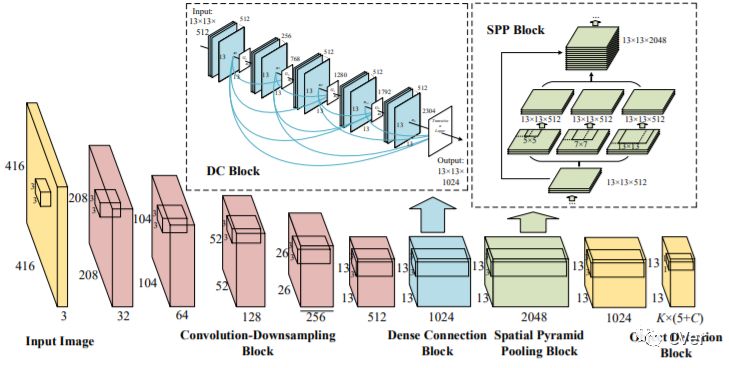
【10】DC-SPP-YOLO: Dense Connection and Spatial Pyramid Pooling Based YOLO for Object Detection
Although YOLOv2 approach is extremely fast on object detection; its backbone network has the low ability on feature extraction and fails to make full use of multi-scale local region features, which restricts the improvement of object detection accuracy. Therefore, this paper proposed a DC-SPP-YOLO (Dense Connection and Spatial Pyramid Pooling Based YOLO) approach for ameliorating the object detection accuracy of YOLOv2. Specifically, the dense connection of convolution layers is employed in the backbone network of YOLOv2 to strengthen the feature extraction and alleviate the vanishing-gradient problem. Moreover, an improved spatial pyramid pooling is introduced to pool and concatenate the multi-scale local region features, so that the network can learn the object features more comprehensively. The DC-SPP-YOLO model is established and trained based on a new loss function composed of mean square error and cross entropy, and the object detection is realized. Experiments demonstrate that the mAP (mean Average Precision) of DC-SPP-YOLO proposed on PASCAL VOC datasets and UA-DETRAC datasets is higher than that of YOLOv2; the object detection accuracy of DC-SPP-YOLO is superior to YOLOv2 by strengthening feature extraction and using the multi-scale local region features.
Date:20190315
Author:北京化工大学
arXiv:https://arxiv.org/abs/1903.08589
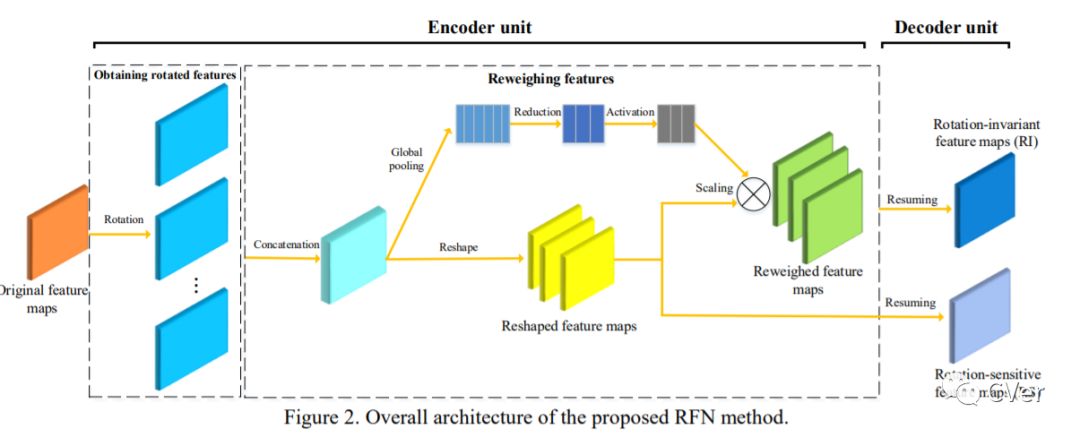
【11】Rotated Feature Network for multi-orientation object detection
General detectors follow the pipeline that feature maps extracted from ConvNets are shared between classification and regression tasks. However, there exists obvious conflicting requirements in multi-orientation object detection that classification is insensitive to orientations, while regression is quite sensitive. To address this issue, we provide an Encoder-Decoder architecture, called Rotated Feature Network (RFN), which produces rotation-sensitive feature maps (RS) for regression and rotation-invariant feature maps (RI) for classification. Specifically, the Encoder unit assigns weights for rotated feature maps. The Decoder unit extracts RS and RI by performing resuming operator on rotated and reweighed feature maps, respectively. To make the rotation-invariant characteristics more reliable, we adopt a metric to quantitatively evaluate the rotation-invariance by adding a constrain item in the loss, yielding a promising detection performance. Compared with the state-of-the-art methods, our method can achieve significant improvement on NWPU VHR-10 and RSOD datasets. We further evaluate the RFN on the scene classification in remote sensing images and object detection in natural images, demonstrating its good generalization ability. The proposed RFN can be integrated into an existing framework, leading to great performance with only a slight increase in model complexity.
Date:20190323
Author:华中科技大学
arXiv:https://arxiv.org/abs/1903.09839
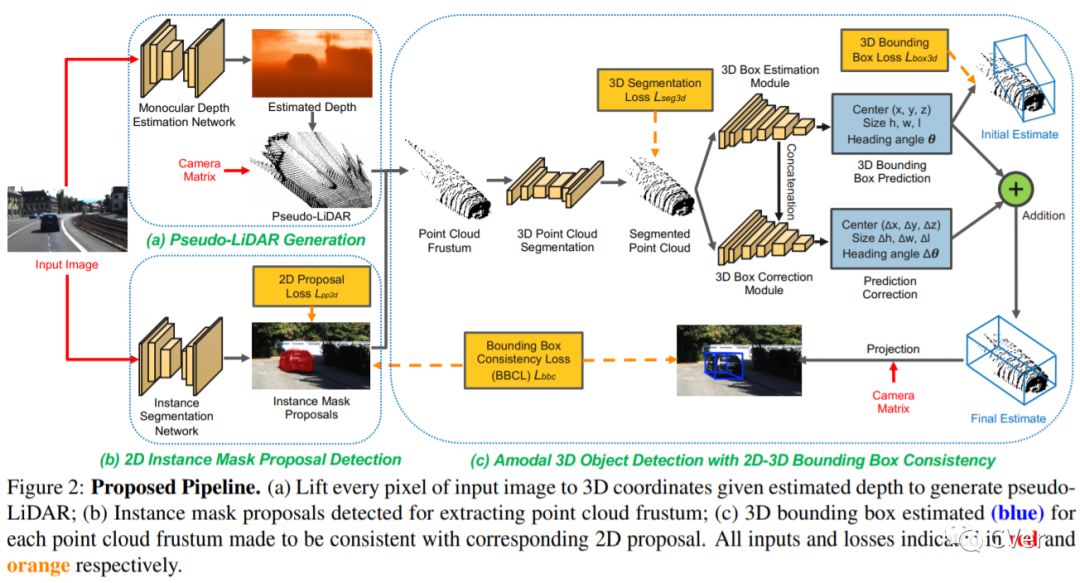
【12】Monocular 3D Object Detection with Pseudo-LiDAR Point Cloud
Monocular 3D scene understanding tasks, such as object size estimation, heading angle estimation and 3D localization, is challenging. Successful modern day methods for 3D scene understanding require the use of a 3D sensor such as a depth camera, a stereo camera or LiDAR. On the other hand, single image based methods have significantly worse performance, but rightly so, as there is little explicit depth information in a 2D image. In this work, we aim at bridging the performance gap between 3D sensing and 2D sensing for 3D object detection by enhancing LiDAR-based algorithms to work with single image input. Specifically, we perform monocular depth estimation and lift the input image to a point cloud representation, which we call pseudo-LiDAR point cloud. Then we can train a LiDAR-based 3D detection network with our pseudo-LiDAR end-to-end. Following the pipeline of two-stage 3D detection algorithms, we detect 2D object proposals in the input image and extract a point cloud frustum from the pseudo-LiDAR for each proposal. Then an oriented 3D bounding box is detected for each frustum. To handle the large amount of noise in the pseudo-LiDAR, we propose two innovations: (1) use a 2D-3D bounding box consistency constraint, adjusting the predicted 3D bounding box to have a high overlap with its corresponding 2D proposal after projecting onto the image; (2) use the instance mask instead of the bounding box as the representation of 2D proposals, in order to reduce the number of points not belonging to the object in the point cloud frustum. Through our evaluation on the KITTI benchmark, we achieve the top-ranked performance on both bird's eye view and 3D object detection among all monocular methods, effectively quadrupling the performance over previous state-of-the-art.
Date:20190323
Author:卡耐基梅隆大学(CMU)
arXiv:https://arxiv.org/abs/1903.09847
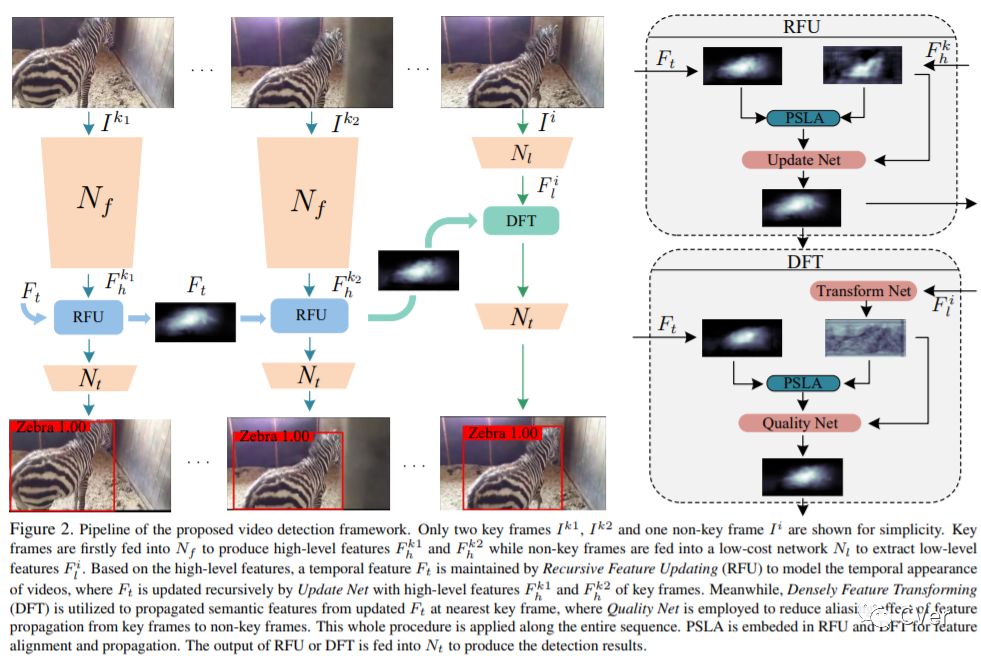
【13】Progressive Sparse Local Attention for Video object detection
Transferring image-based object detectors to the domain of videos remains a challenging problem. Previous efforts mostly exploit optical flow to propagate features across frames, aiming to achieve a good trade-off between accuracy and efficiency. However, introducing an extra model to estimate optical flow would significantly increase the overall model size. The gap between optical flow and high-level features can also hinder it from establishing spatial correspondence accurately. Instead of relying on optical flow, this paper proposes a novel module called Progressive Sparse Local Attention (PSLA), which establishes the spatial correspondence between features across frames in a local region with progressive sparser stride and uses the correspondence to propagate features. Based on PSLA, Recursive Feature Updating (RFU) and Dense Feature Transforming (DFT) are proposed to model temporal appearance and enrich feature representation respectively in a novel video object detection framework. Experiments on ImageNet VID show that our method achieves the best accuracy compared to existing methods with smaller model size and acceptable runtime speed.
Date:20190325
Author:中科院自动化所&地平线
arXiv:https://arxiv.org/abs/1903.09126v2
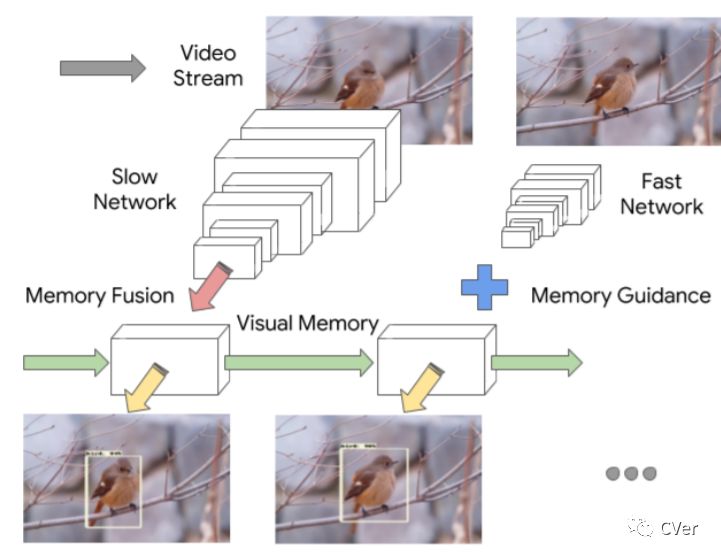
【14】Looking Fast and Slow: Memory-Guided Mobile Video Object Detection
With a single eye fixation lasting a fraction of a second, the human visual system is capable of forming a rich representation of a complex environment, reaching a holistic understanding which facilitates object recognition and detection. This phenomenon is known as recognizing the "gist" of the scene and is accomplished by relying on relevant prior knowledge. This paper addresses the analogous question of whether using memory in computer vision systems can not only improve the accuracy of object detection in video streams, but also reduce the computation time. By interleaving conventional feature extractors with extremely lightweight ones which only need to recognize the gist of the scene, we show that minimal computation is required to produce accurate detections when temporal memory is present. In addition, we show that the memory contains enough information for deploying reinforcement learning algorithms to learn an adaptive inference policy. Our model achieves state-of-the-art performance among mobile methods on the Imagenet VID 2015 dataset, while running at speeds of up to 70+ FPS on a Pixel 3 phone.
Date:20190325
Author:康奈尔大学 & Google
arXiv:https://arxiv.org/abs/1903.10172
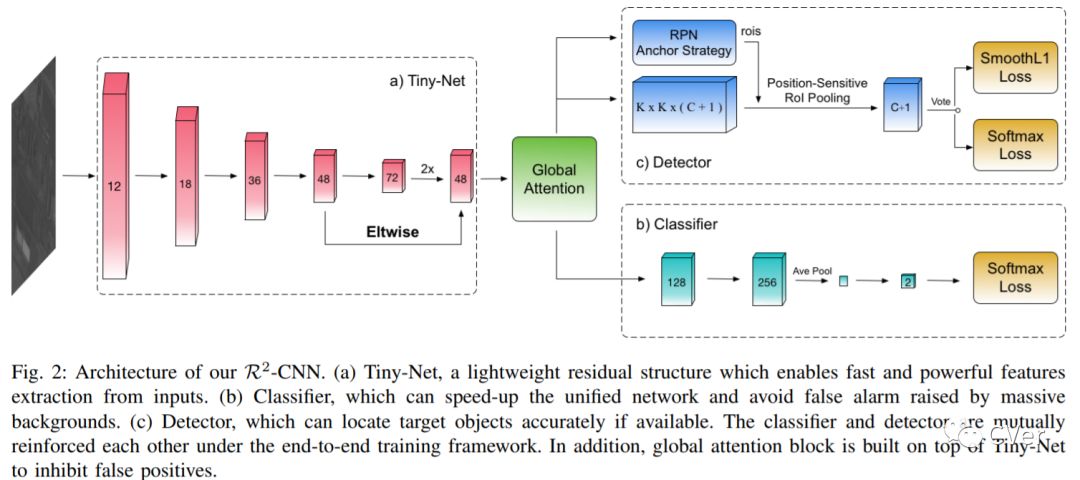
【15】R2-CNN: Fast Tiny Object Detection in Large-scale Remote Sensing Images
Recently, the convolutional neural network has brought impressive improvements for object detection. However, detecting tiny objects in large-scale remote sensing images still remains challenging. First, the extreme large input size makes the existing object detection solutions too slow for practical use. Second, the massive and complex backgrounds cause serious false alarms. Moreover, the ultratiny objects increase the difficulty of accurate detection. To tackle these problems, we propose a unified and self-reinforced network called remote sensing region-based convolutional neural network (R2-CNN), composing of backbone Tiny-Net, intermediate global attention block, and final classifier and detector. Tiny-Net is a lightweight residual structure, which enables fast and powerful features extraction from inputs. Global attention block is built upon Tiny-Net to inhibit false positives. Classifier is then used to predict the existence of targets in each patch, and detector is followed to locate them accurately if available. The classifier and detector are mutually reinforced with end-to-end training, which further speed up the process and avoid false alarms. Effectiveness of R2-CNN is validated on hundreds of GF-1 images and GF-2 images that are 18 000 × 18 192 pixels, 2.0-m resolution, and 27 620 × 29 200 pixels, 0.8-m resolution, respectively. Specifically, we can process a GF-1 image in 29.4 s on Titian X just with single thread. According to our knowledge, no previous solution can detect the tiny object on such huge remote sensing images gracefully. We believe that it is a significant step toward practical real-time remote sensing systems.
Date:20190326
Author:浙江大学&商汤科技
arXiv:https://arxiv.org/abs/1902.06042v2
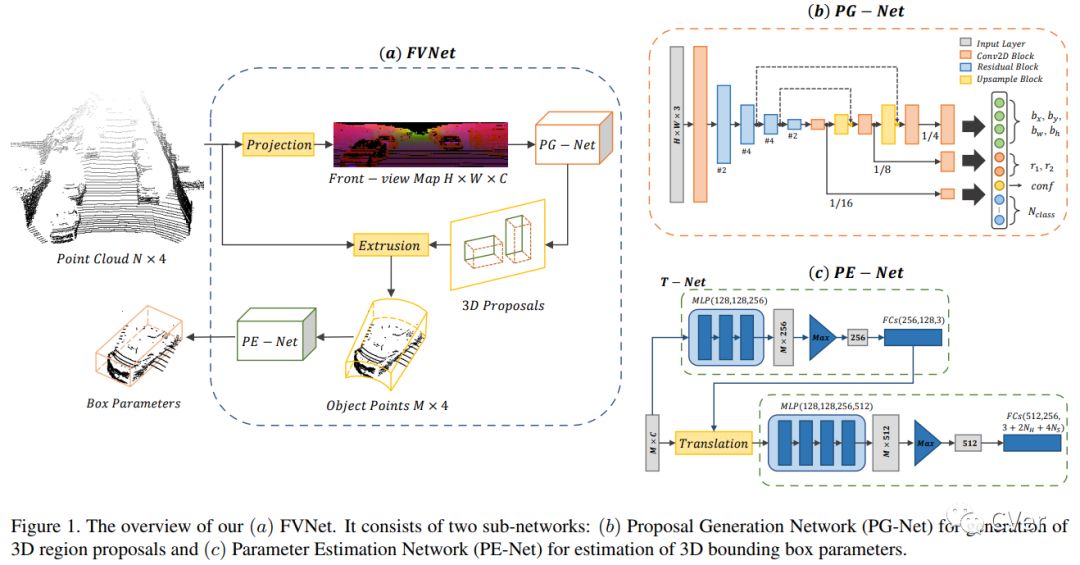
【16】FVNet: 3D Front-View Proposal Generation for Real-Time Object Detection from Point Clouds
3D object detection from raw and sparse point clouds has been far less treated to date, compared with its 2D counterpart. In this paper, we propose a novel framework called FVNet for 3D front-view proposal generation and object detection from point clouds. It consists of two stages: generation of front-view proposals and estimation of 3D bounding box parameters. Instead of generating proposals from camera images or bird's-eye-view maps, we first project point clouds onto a cylindrical surface to generate front-view feature maps which retains rich information. We then introduce a proposal generation network to predict 3D region proposals from the generated maps and further extrude objects of interest from the whole point cloud. Finally, we present another network to extract the point-wise features from the extruded object points and regress the final 3D bounding box parameters in the canonical coordinates. Our framework achieves real-time performance with 12ms per point cloud sample. Extensive experiments on the 3D detection benchmark KITTI show that the proposed architecture outperforms state-of-the-art techniques which take either camera images or point clouds as input, in terms of accuracy and inference time.
Date:20190327
Author:上海交通大学&迪肯大学&腾讯优图
arXiv:https://arxiv.org/abs/1903.10750
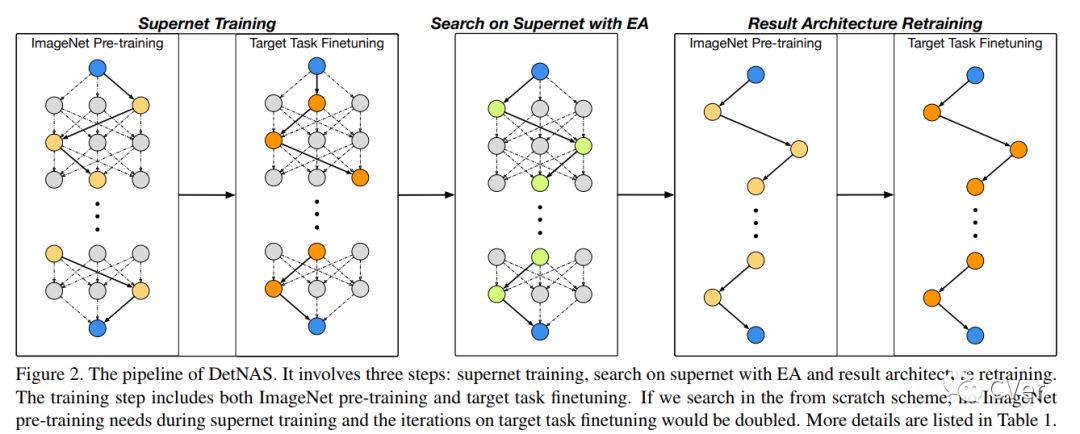
【17】DetNAS: Neural Architecture Search on Object Detection
Object detectors are usually equipped with networks designed for image classification as backbones, e.g., ResNet. Although it is publicly known that there is a gap between the task of image classification and object detection, designing a suitable detector backbone is still manually exhaustive. In this paper, we propose DetNAS to automatically search neural architectures for the backbones of object detectors. In DetNAS, the search space is formulated into a supernet and the search method relies on evolution algorithm (EA). In experiments, we show the effectiveness of DetNAS on various detectors, the one-stage detector, RetinaNet, and the two-stage detector, FPN. For each case, we search in both training from scratch scheme and ImageNet pre-training scheme. There is a consistent superiority compared to the architectures searched on ImageNet classification. Our main result architecture achieves better performance than ResNet-101 on COCO with the FPN detector. In addition, we illustrate the architectures searched by DetNAS and find some meaningful patterns.
Date:20190327
Author:中科院&旷视科技
arXiv:https://arxiv.org/abs/1903.10979
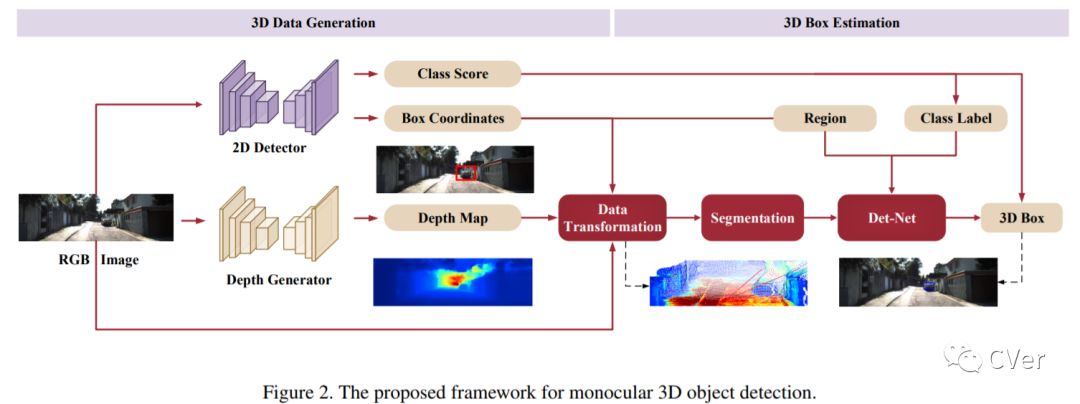
【18】Accurate Monocular 3D Object Detection via Color-Embedded 3D Reconstruction for Autonomous Driving
In this paper, we propose a monocular 3D object detection framework in the domain of autonomous driving. Unlike previous image-based methods which focus on RGB feature extracted from 2D images, our method solves this problem in the reconstructed 3D space in order to exploit 3D contexts explicitly. To this end, we first leverage a stand-alone module to transform the input data from 2D image plane to 3D point clouds space for a better input representation, then we perform the 3D detection using PointNet backbone net to obtain objects 3D locations, dimensions and orientations. To enhance the discriminative capability of point clouds, we propose a multi-modal feature fusion module to embed the complementary RGB cue into the generated point clouds representation. We argue that it is more effective to infer the 3D bounding boxes from the generated 3D scene space (i.e., X,Y, Z space) compared to the image plane (i.e., R,G,B image plane). Evaluation on the challenging KITTI dataset shows that our approach boosts the performance of state-of-the-art monocular approach by a large margin, i.e., around 15% absolute AP on both 3D localization and detection tasks for Car category at 0.7 IoU threshold.
Date:20190328
Author:大连理工大学&悉尼大学
arXiv:https://arxiv.org/abs/1903.11444
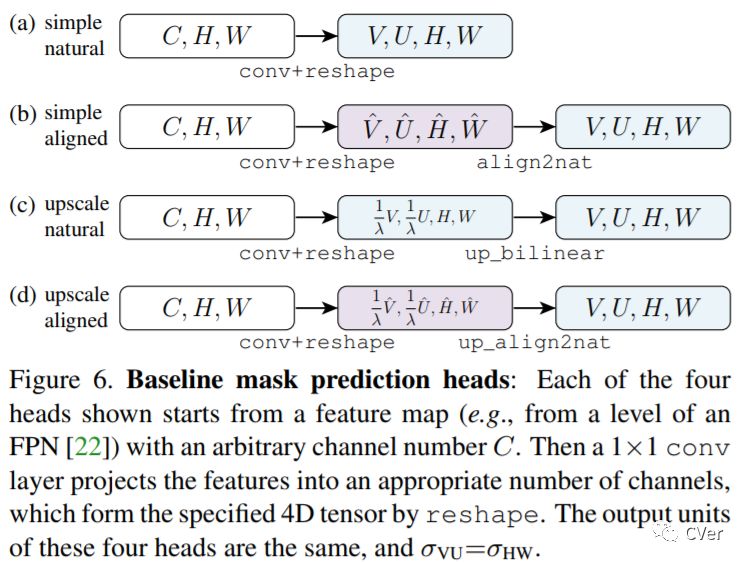
【19】TensorMask: A Foundation for Dense Object Segmentation
Sliding-window object detectors that generate bounding-box object predictions over a dense, regular grid have advanced rapidly and proven popular. In contrast, modern instance segmentation approaches are dominated by methods that first detect object bounding boxes, and then crop and segment these regions, as popularized by Mask R-CNN. In this work, we investigate the paradigm of dense sliding-window instance segmentation, which is surprisingly under-explored. Our core observation is that this task is fundamentally different than other dense prediction tasks such as semantic segmentation or bounding-box object detection, as the output at every spatial location is itself a geometric structure with its own spatial dimensions. To formalize this, we treat dense instance segmentation as a prediction task over 4D tensors and present a general framework called TensorMask that explicitly captures this geometry and enables novel operators on 4D tensors. We demonstrate that the tensor view leads to large gains over baselines that ignore this structure, and leads to results comparable to Mask R-CNN. These promising results suggest that TensorMask can serve as a foundation for novel advances in dense mask prediction and a more complete understanding of the task. Code will be made available.
Date:20190329
Author:Facebook(FAIR)
arXiv:https://arxiv.org/abs/1903.12174
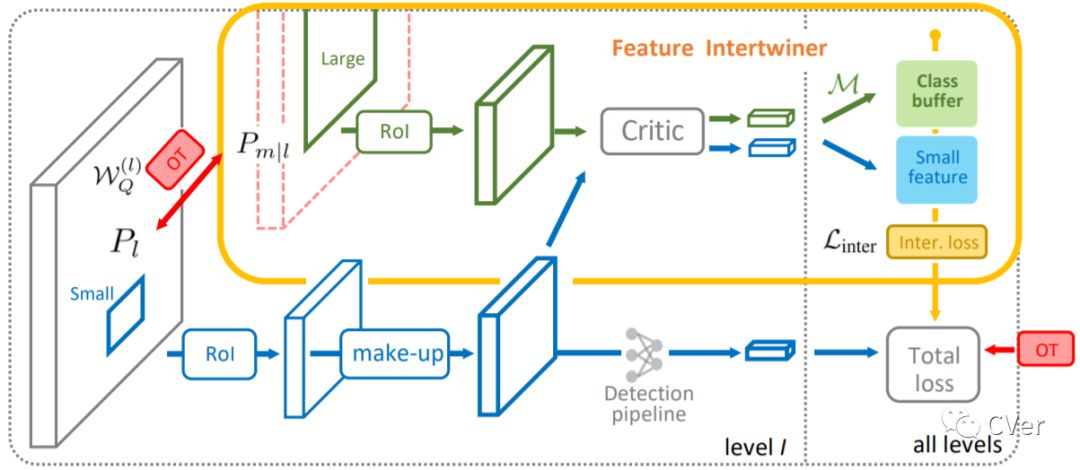
【20】Feature Intertwiner for Object Detection
A well-trained model should classify objects with a unanimous score for every category. This requires the high-level semantic features should be as much alike as possible among samples. To achive this, previous works focus on re-designing the loss or proposing new regularization constraints. In this paper, we provide a new perspective. For each category, it is assumed that there are two feature sets: one with reliable information and the other with less reliable source. We argue that the reliable set could guide the feature learning of the less reliable set during training - in spirit of student mimicking teacher behavior and thus pushing towards a more compact class centroid in the feature space. Such a scheme also benefits the reliable set since samples become closer within the same category - implying that it is easier for the classifier to identify. We refer to this mutual learning process as feature intertwiner and embed it into object detection. It is well-known that objects of low resolution are more difficult to detect due to the loss of detailed information during network forward pass (e.g., RoI operation). We thus regard objects of high resolution as the reliable set and objects of low resolution as the less reliable set. Specifically, an intertwiner is designed to minimize the distribution divergence between two sets. The choice of generating an effective feature representation for the reliable set is further investigated, where we introduce the optimal transport (OT) theory into the framework. Samples in the less reliable set are better aligned with aid of OT metric. Incorporated with such a plug-and-play intertwiner, we achieve an evident improvement over previous state-of-the-arts.
Date:20190329
Author:商汤科技&港中文
arXiv:https://arxiv.org/abs/1903.11851
github:https://github.com/hli2020/feature_intertwiner
注:ICLR 2019
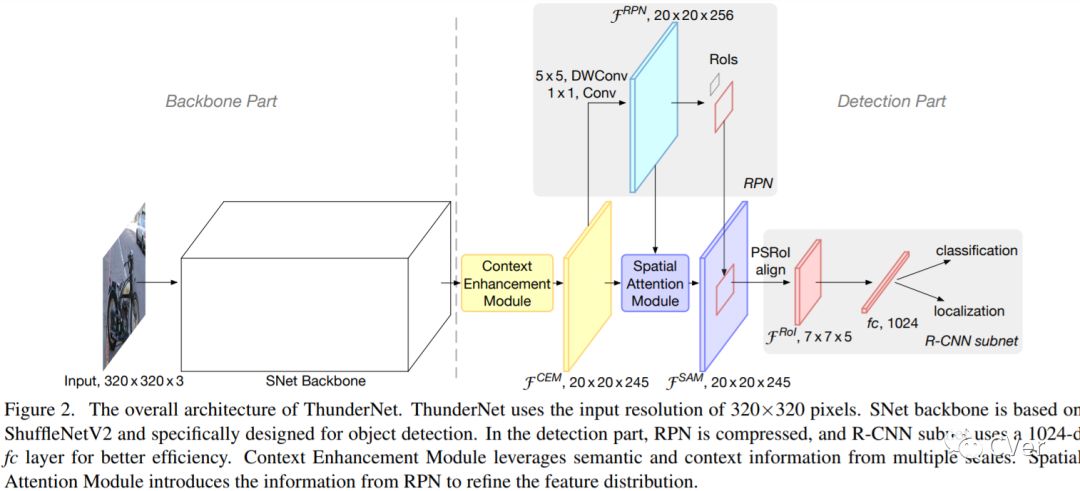
【21】ThunderNet: Towards Real-time Generic Object Detection
Real-time generic object detection on mobile platforms is a crucial but challenging computer vision task. However, previous CNN-based detectors suffer from enormous computational cost, which hinders them from real-time inference in computation-constrained scenarios. In this paper, we investigate the effectiveness of two-stage detectors in real-time generic detection and propose a lightweight two-stage detector named ThunderNet. In the backbone part, we analyze the drawbacks in previous lightweight backbones and present a lightweight backbone designed for object detection. In the detection part, we exploit an extremely efficient RPN and detection head design. To generate more discriminative feature representation, we design two efficient architecture blocks, Context Enhancement Module and Spatial Attention Module. At last, we investigate the balance between the input resolution, the backbone, and the detection head. Compared with lightweight one-stage detectors, ThunderNet achieves superior performance with only 40% of the computational cost on PASCAL VOC and COCO benchmarks. Without bells and whistles, our model runs at 24.1 fps on an ARM-based device. To the best of our knowledge, this is the first real-time detector reported on ARM platforms. Code will be released for paper reproduction.
Date:20190329
Author:旷视科技&国科大
arXiv:https://arxiv.org/abs/1903.11752
CVer目标检测交流群
扫码添加CVer助手,可申请加入CVer-目标检测交流群。一定要备注:目标检测+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡)

▲长按加群
这么硬的论文速递,麻烦给我一个好看

▲长按关注我们
麻烦给我一个好看!



