学界 | NIPS2018最佳论文解读:Neural Ordinary Differential Equations

AI 科技评论按:不久前,NeurIPS 2018 在加拿大蒙特利尔召开,在这次著名会议上获得最佳论文奖之一的论文是《Neural Ordinary Differential Equations》,论文地址:https://arxiv.org/abs/1806.07366。Branislav Holländer 在 towards data science 上对这篇论文进行了解读, AI 科技评论编译整理如下:
这篇论文的作者隶属于著名的多伦多大学向量研究所。在这篇文章中,我将尝试解释这篇论文的主要观点,并讨论它们对深度学习领域的潜在影响。该论文涉及到了常微分方程(ODE)、递归神经网络(RNN)和归一化流(NF)等概念,但我会尽可能直观地解释它的观点,让您可以在不太深入了解技术细节的情况下理解主要概念。如果你感兴趣的话,你可以去论文原稿中阅读这些细节。文章分为多个部分,每个部分解释论文中的一个或多个章节。
从序列变换到神经微分方程
如今,多神经网络体系结构(如 RNN 或残差网络)包含重复的层块,这些层块能够有序保留信息,并通过学习函数在每一步中对其进行更改。一般来说,这种网络可以用下面的方程来描述:
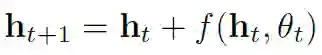
因此,ht 是时间步长 t 的「隐藏」信息,f(ht,θt)是当前隐藏信息和参数θ的学习函数。本文提出的核心问题是,我们是否可以通过逐步减小步长 [t,t+1] 来提升目前这些网络的最优性能。我们可以想象这是逐步增加 RNN 中的评估数量,或者增加残差网络中的残差层数量。如果我们这样做,我们最终会得到上述方程的微分版本:
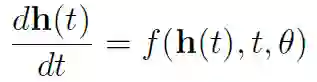
因为方程的解是一个函数(函数 h(t)),所以这种方程称为常微分方程(ode)。换句话说,通过求解方程,我们得到了所需的隐藏状态序列。我们必须在每次评估过程中,从初始状态 h0 开始求解方程。这种问题也称为初值问题。
用「伴随法」计算模式求解器的梯度
数值求解一个 ODE 通常是通过积分来完成的。多年来,人们发明了很多积分方法,包括简单的 Euler 方法和 Runge-Kutta 方法的高阶变种。然而,这些方法在计算上都是相当密集的。在训练过程中尤其如此,它需要对积分步骤进行微分,以便能将网络参数θ的所有梯度相加,这会导致较高的内存成本。
本文提出了一种用 Pontryagin 的「伴随法」计算 ODE 梯度的替代方法。该方法通过求解第二个时间向后增加的 ODE,可以与所有的 ODE 积分器一起使用,并且占用较小的内存。让我们考虑最小化 ODE 求解器结果的损失函数,即:

在第二步中,使用了 ODE 解的定义,在第三步中,将 ODESolve 作为求解 ODE 的操作符引入。正如我前面提到的,这个操作符依赖于初始状态 z(t0)、数 f、初始和结束时间 t0、t1 以及搜索的参数 θ。「伴随法」现在确定了损耗函数 w.r.t 的梯度,其隐藏状态为:
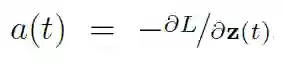
这个数量伴随着 ODE 的增加。
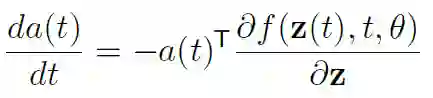
计算梯度 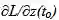
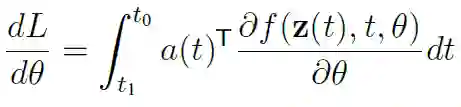
如作者所述,整个梯度计算算法过程如下:

用于监督学习的 ODE 网络
接下来是论文中最有趣的部分:相关的应用。作者在论文中提到的第一个应用是在监督学习领域,即 MNIST 书写数字分类。结果表明,该方法与参数较少的残差网络性能相当。本文中用于评估的网络对输入图像进行两次采样,然后应用于 6 个残差块。总之,网络包含大约 60 万个参数。ODESolve 网络使用单个 ODESolve 模块替换 6 层网络。此外,作者还对 RK 网络进行了测试,除了使用 Runge-Kutta 方法直接反向传播误差外,该网络与 RK 网络相似。如上所述,您可以将传统神经网络中的层数与 ODE 网络中的评估数联系起来。这两个网络的参数个数为 22 万个,重要的结果是,使用大约 1/3 的参数,RK 网络和 ODE 网络的性能与残差网络大致相同。此外,ODE 网络的内存复杂性是恒定的(见下图)。
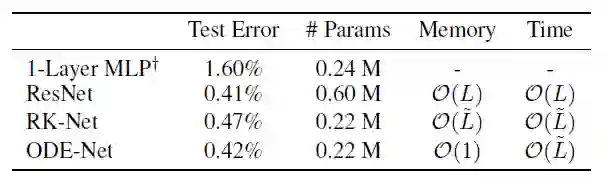
此外,可以调整 ODE 解的精度以最大限度地提高计算性能。例如,一个人可以进行高精度的训练,并降低评估准确性(更多详细信息,请参阅原文)。
连续归一化流
归一化流是分布的可逆变换。它们可以通过一系列非线性变换将简单的概率密度转换为复杂的概率密度,正如在神经网络中一样。因此,它们利用分布中的变量转换公式:
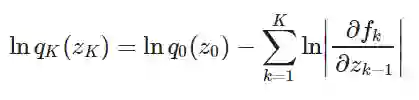
上式中,q0(z0)为初始分布,qk(zk)为转换分布,转换为 fk,k=0...K。上述和中的 Jacobi 行列式保证了整个转换过程中分布函数的积分保持为 1。不幸的是,除了一些简单的变换外,计算这个行列式代价太大。
归一化流的一个常见应用是变分自动编码器(VAE),它通常假定潜在变量是高斯分布的。这一假设使得 VAE 的输出结果变差,因为它不允许网络学习所需的分布。对于归一化流,高斯参数可以在「解码」之前转换成各种各样的分布,从而提高 VAE 的生成能力。这篇博文详细解释了归一化流:http://akosiorek.github.io/ml/2018/04/03/norm_flows.html
本文讨论了归一化流在连续域中的扩展。有趣的是,这简化了归一化常数的计算。如果我们让随机变量在时间上是连续的,用函数 f 描述时间的变化(f 是 Lipschitz 连续的),则概率的对数变化遵循简单的微分方程:
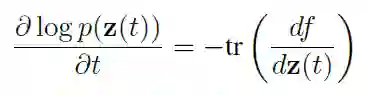
因此,行列式的计算在这里被简单的跟踪运算所取代。此外,如果我们使用一个转换的和,那么我们只需要对跟踪求和:
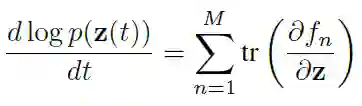
为了证明 CNF 的有效性,本文测试了概率密度从高斯分布到两个目标分布的转换,如下图所示。
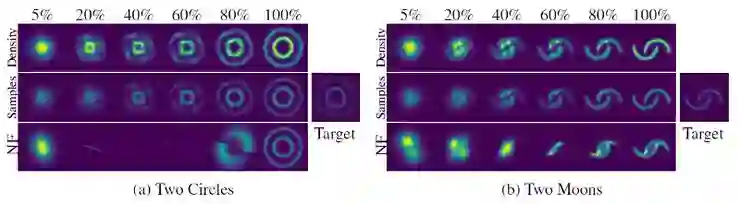
利用 CNF(上两行)和 NF(下一行)在高斯分布和目标分布之间进行转换(从 5% 到 100%)。
采用最大似然估计方法对神经网络和神经网络进行训练,使目标概率分布下的期望值最大化,然后将模型反演为已知分布的样本。
通过 ODE 生成时间序列模型
本文提到的第三个应用(可能是最重要的应用),是通过 ODE 进行时间序列建模。作者开始这项工作的动机之一是他们对不规则采样数据的兴趣,如医疗记录数据或网络流量数据。这种数据的离散化常常定义不明确,导致某些时间间隔内数据丢失或潜在变量不准确。有一些方法将时间信息连接到 RNN 的输入上,但这些方法并不能从根本上解决问题。
基于 ODE 模块的解决方案是一个连续时间生成模型,在给定初始状态 z0 和观测时间 t0…tN 的情况下,该模型计算潜在状态 z_t1…z_tN 和输出 x_t1…x_tN:
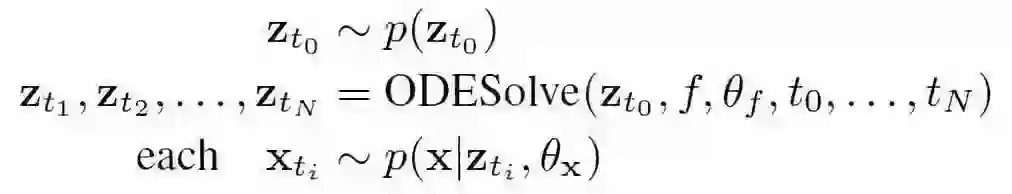
神经网络函数 f 负责计算从当前时间步长开始的任何时间 t 处的潜伏状态 z。该模型是一个变分自动编码器,它使用 RNN 在初始潜伏状态 z0 下编码过去的轨迹(在下图中为绿色)。与所有变分自动编码器一样,它通过分布的参数(在本例中,满足均值为μ、标准差为σ的高斯分布)来捕获潜在状态分布。从这个分布中,抽取一个样本并由 ODESolve 进行处理。
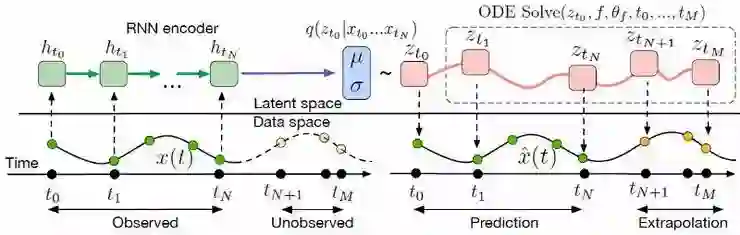
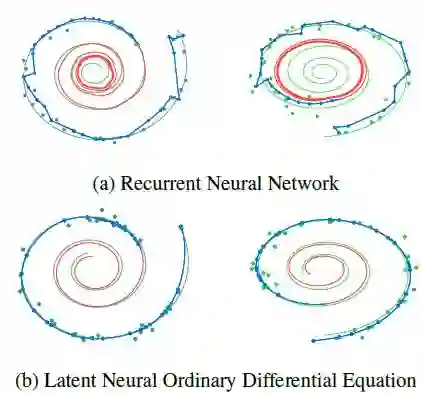
该体系结构在一个双向二维螺旋的合成数据集上进行了测试,该数据集在不规则的时间点采样,并且数据中有高斯噪声。下图定性地显示了 Latent Neural ODE 模型的优越建模性能:
结论
本文提出了一种非常有趣和新颖的神经网络思维方法。这可能是一篇开启深度学习新进化的里程碑式论文。我希望随着时间的推移,越来越多的研究人员开始从不同的角度来思考神经网络,正如本文所做的那样。
文中的方法是否确实适用于现有的各种模型、是否会被时间证明是有效的,仍有待观察。作者也提到了他们方法的一些局限性:
小批量可能是这种方法的一个问题,然而作者提到,即使在整个实验过程中使用小批量,评估的数量仍然是可以管理的。
只有当网络具有有限的权值并使用 Lipschitz 非线性函数(如 tanh 或 relu,而不是阶跃函数)时,才能保证 ODE 解的唯一性。
前向轨迹的可逆性可能会受到前向模式求解器中的数值误差、反向模式求解器中的数值误差以及由于多个初始值映射到同一结束状态而丢失的信息的综合影响。
作者还提到,他们的方法是不唯一的,残差网络作为近似的 ODE 求解器的想法已经过时了。此外,还有一些论文试图通过神经网络和高斯过程来学习不同的方程。
本文提出的方法的一个重要优点是,在评估或训练过程中,通过改变数值积分的精度,可以自由地调节速度和精确度之间的平衡。此外,该方法也非常适用(只要求神经网络的非线性是 Lipschitz 连续的),并且可以应用于时间序列建模、监督学习、密度估计或其他顺序过程。
来源:https://towardsdatascience.com/paper-summary-neural-ordinary-differential-equations-37c4e52df128





