REALM:将检索集成到语言表征模型,搞定知识密集型任务!

文 / Ming-Wei Chang 和 Kelvin Guu,研究员,Google Research
自然语言处理的最新进展以 无监督预训练 为基础,使用大量文本训练通用语言表征模型 (Language Representation Models),无需人工标注或标签。这些预训练模型,如 BERT 和 RoBERTa,经证明可以记忆大量世界知识,例如“the birthplace of Francesco Bartolomeo Conti”、“the developer of JDK”和“the owner of Border TV”。
RoBERTa
https://arxiv.org/abs/1907.11692经证明可以记忆大量世界知识
https://arxiv.org/pdf/1909.01066.pdf
虽然知识编码能力对于某些自然语言处理任务(如问题回答、信息检索和文本生成等)尤为重要,但这些模型是 隐式地 记忆知识,也就是说世界知识在模型权重中以抽象的方式被捕获,导致已存储的知识及其在模型中的位置都难以确定。此外,存储空间以及模型的准确率也受到网络规模的限制。为了获取更多的世界知识,标准做法是训练更大的网络,这可能非常缓慢或非常昂贵。
如果有一种预训练方法可以 显式地 获取知识,如引用额外的大型外部文本语料库,在不增加模型大小或复杂性的情况下获得准确结果,会怎么样?
例如,模型可以引用外部文集中的句子“Francesco Bartolomeo Conti was born in Florence”来确定这位音乐家的出生地,而不是依靠模型隐晦的访问存储于自身参数中的某个知识。像这样检索包含显性知识的文本,将提高预训练的效率,同时使模型能够在不使用数十亿个参数的情况下顺利完成知识密集型任务。
在 2020 ICML 我们介绍的 “REALM: Retrieval-Augmented Language Model Pre-Training”中,我们分享了一种语言预训练模型的新范例,用 知识检索器 (Knowledge Retriever) 增强语言模型,让 REALM 模型能够从原始文本文档中 显式 检索文本中的世界知识,而不是将所有知识存储在模型参数中。我们还开源了 REALM 代码库,以演示如何联合训练检索器和语言表示。
REALM: Retrieval-Augmented Language Model Pre-Training
https://arxiv.org/abs/2002.08909REALM 代码库
https://github.com/google-research/language/tree/master/language/realm
背景:预训练语言表征模型
I am so thirsty. I need to __ water.
预训练期间,模型将遍历大量样本并调整参数,预测缺失的单词(上述样本中的答案:answer: drink)。于是,填空任务使模型记住了世界中的某些事实。例如,在以下样本中,需要了解爱因斯坦的出生地才能填补缺失单词:
Einstein was a __-born scientist. (answer: German)
检索增强型语言表征模型预训练
与标准语言表征模型相比,REALM 通过 知识检索器 增强语言表征模型,首先从外部文档集中检索另一段文本作为支持知识,在实验中为 Wikipedia 文本语料库,然后将这一段支持文本与原始文本一起输入语言表征模型。
Wikipedia 文本语料库
https://archive.org/details/wikimediadownloads
REALM 的关键理念是检索系统应提高模型填补缺失单词的能力。因此,应该奖励提供了更多上下文填补缺失单词的检索。如果检索到的信息不能帮助模型做出预测,就应该进行阻拦,为更好的检索腾出空间。
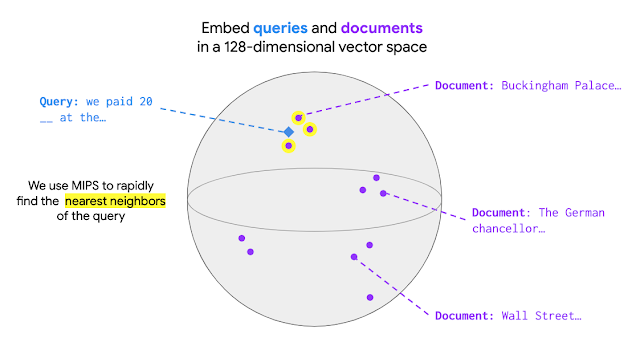
We paid twenty __ at the Buckingham Palace gift shop.
在没有检索的情况下,很难填补句子中缺失的单词 (answer: pounds),因为模型需要隐式存储白金汉宫所在国家和相关货币的知识,并在两者之间建立联系。如果提供了一段与从外部语料库中检索的必要知识显式连接的段落,模型会更容易填补缺失的单词。
Buckingham Palace is the London residence of the British monarchy.
由于检索步骤需要添加更多上下文,因此可能会有多个检索目标对填补缺失单词有所帮助,例如“The official currency of the United Kingdom is the Pound.”。下图演示了整个过程:

REALM 的计算挑战
扩展 REALM 预训练使模型从数百万个文档中检索知识具有一定挑战性。在 REALM 中,最佳文档选择为 最大内积搜索 (Maximum Inner Product Search,MIPS)。检索前,MIPS 模型需要首先对集合中的所有文档进行编码,使每个文档都有一个对应的文档向量。输入到达时会被编码为一个查询向量。在 MIPS 中,给定查询就会检索出集合中文档向量和查询向量之间具有最大内积值的文档,如下图所示:
REALM 采用 ScaNN 软件包高效执行 MIPS,在预先计算文档向量的情况下,相对降低了寻找最大内积值的成本。但是,如果在训练期间更新了模型参数,通常有必要对整个文档集重新编码文档向量。为了解决算力上的挑战,检索器经过结构化设计可以缓存并异步更新对每个文档执行的计算。另外,要实现良好性能并使训练可控,应每 500 个训练步骤更新文档向量而不是每步都更新。
将 REALM 应用于开放域问答
将 REALM 应用于开放域问答 (Open-QA) 评估其有效性,这是自然语言处理中知识最密集的任务之一。任务的目的是回答问题,例如“What is the angle of the equilateral triangle(等边三角形的一角是多少度)?”
在标准问答任务中(例如 SQuAD 或 Natural Questions),支持文档是输入的一部分,因此模型只需要在给定文档中查找答案。Open-QA 中没有给定文档,因此 Open-QA 模型需要自主查找知识,这就使 Open-QA 成为检查 REALM 有效性的绝佳任务。
SQuAD
https://arxiv.org/abs/1606.05250Natural Questions
https://ai.google.com/research/NaturalQuestions/
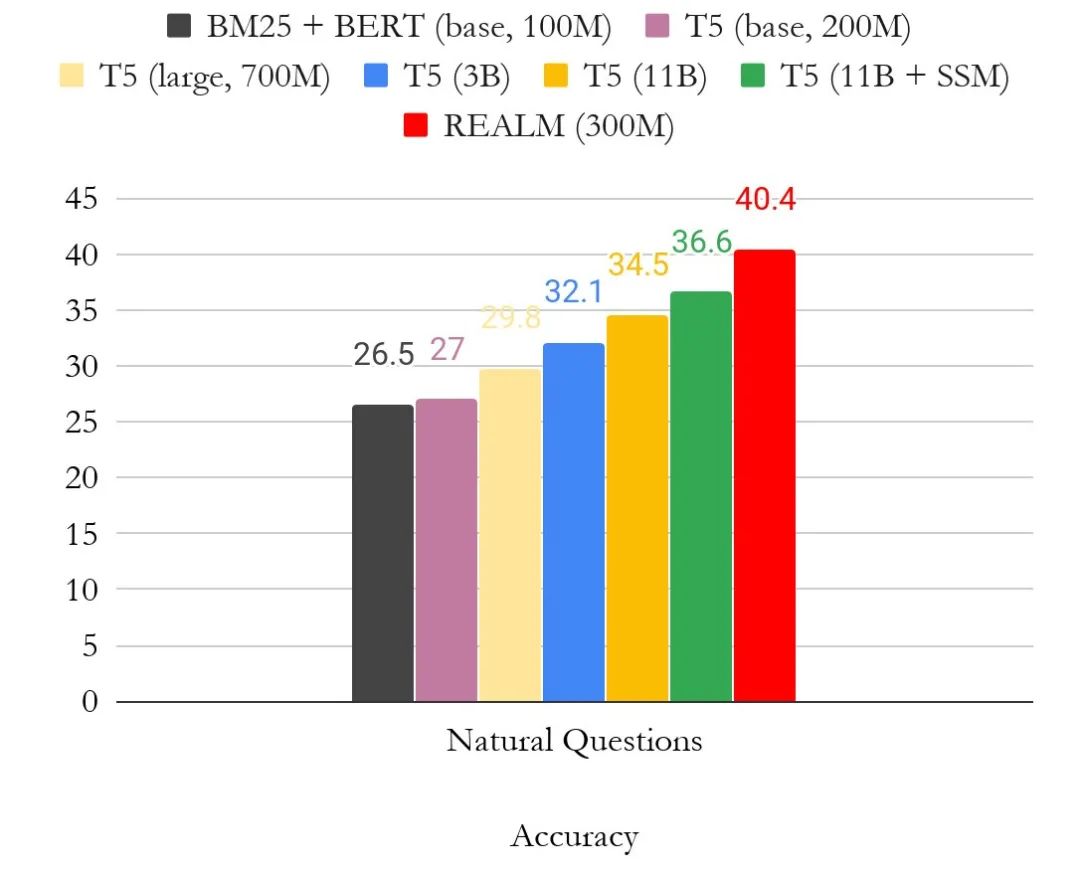
下图是 OpenQA 版本 Natural Question 的结果。我们主要将结果与 T5 进行比较,T5 是另一种无需标注文档即可训练模型的方法。从图中可以清楚地看到,REALM 预训练生成了非常强大的 Open-QA 模型,仅使用少量参数 (300M),性能就比更大的 T5 (11B) 模型要高出近 4 个点。
结论
-
将类似 REALM 的方法应用于需要知识密集型推理和可解释出处的新应用(超越 Open-QA) -
了解对其他形式的知识进行检索的好处,例如图像、知识图谱结构甚至其他语言的文本。我们也很高兴看到研究界开始使用开源 REALM 代码库!
检索增强型生成模型
https://arxiv.org/abs/2005.11401REALM 代码库
https://github.com/google-research/language/tree/master/language/realm
致谢
本研究由 Kelvin Guu、Kenton Lee、Zora Tung、Panupong Pasupat 与 Ming-Wei Chang 合作完成。