诺丁汉大学提出使用GAN进行「人脸识别」中的「人脸特征点定位」
作者:Adrian Bulat、Georgios Tzimiropoulos
「雷克世界」编译:嗯~是阿童木呀、KABUDA、EVA
摘要:现如今,人脸识别在实际生活中有着越来越多的应用。可是,对于一些低分辨率的人脸图像来说,如何对其中的人脸特征点进行精确定位是一个挑战。最近,英国诺丁汉大学计算机视觉实验室的科学家们提出了一种Super-FAN,这是首个集成人脸超分辨率和特征点定位的端到端系统。能够提高低分辨率人脸图像的质量,同时还能够对图像上的人脸特征点进行精确定位。
本文提出了两个具有挑战性的任务:提高低分辨率人脸图像的质量,并精确定位这些低分辨率图像上的人脸特征点。为此,我们做出了以下5个贡献:
1. 我们提出了Super-FAN:第一个能够同时解决这两个任务的端到端系统,即改善人脸分辨率和检测人脸特征点。Super-FAN的新颖性在于:通过将一个人脸对齐(face alignment)的子网络集成到热图回归(heatmap regression)中,并优化新的热图损失(heatmap loss),从而将结构信息整合到基于GAN的超分辨率算法(GAN-based super-resolution algorithm)中。
2. 我们通过在正面图像(如先前的研究)和整体人脸姿势光谱上,以及在合成低分辨率图像(如先前的研究)和现实世界的图像上,都显示出良好的结果,从而说明了训练这两个网络的好处。
3. 我们通过提出一种新的基于残差的架构,改进了人脸超分辨率最先进的技术。
4. 定量地看,我们大大提高了人脸超分辨率和人脸对齐的最先进技术。
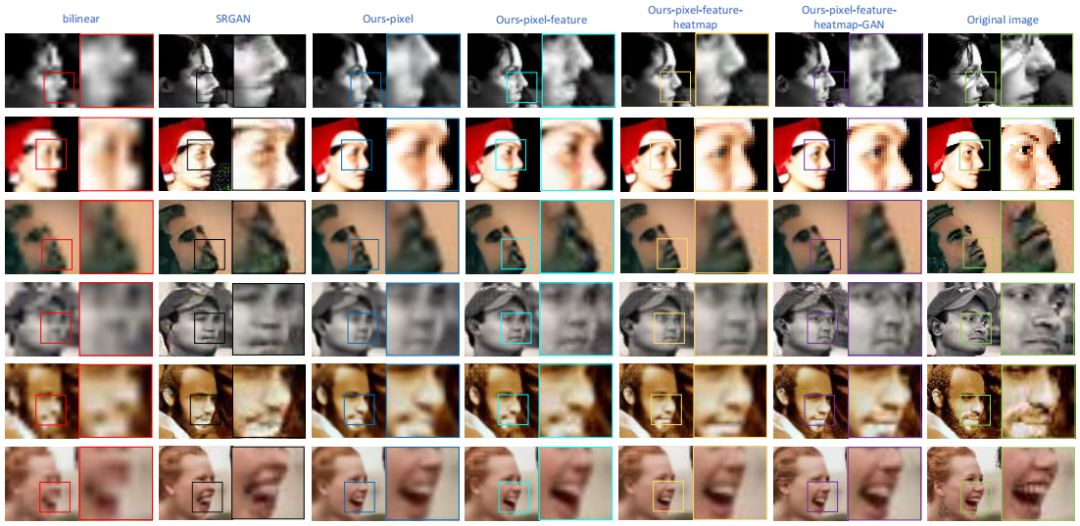
5. 定性地看,我们首次在现实世界的低分辨率图像上得到良好的结果,如图1所示。

图1:我们的系统在来自WiderFace的真实低分辨率人脸上生成的一些视觉效果的样本图片。
本文的目的是改进非常低分辨率的人脸图像的质量和理解。这在许多应用程序中很重要,比如人脸编辑监视/安全。在质量方面,我们的目标是提高分辨率,并恢复现实世界低分辨率人脸图像的细节,如图1的第一行所示;该任务也被称为“人脸超分辨率(face super-resolution)”(当输入的分辨率太小时,该任务有时被称为“人脸幻觉(face hallucination)”)。
在理解方面,我们希望通过使用语义(semantic meaning)定位一组预定义的人脸特征点(如鼻尖、眼角),从而提取中高级的人脸信息;这个任务也被称为“人脸对齐(face alignment)”。
试图同时解决这两项任务实际上是一个“先有鸡还是先有蛋”的问题:一方面,能够检测到人脸特征点已经被证明有利于人脸超分辨率;然而,如何在任意姿势的低分辨率人脸中完成它仍是一个尚待解决的问题。另一方面,如果能够在整体人脸姿势光谱上有效地解决低质量和低分辨率的人脸,那么人脸特征点就可以被精确定位。
因为很难在非常低分辨率的人脸中检测特征点(如在本研究中所注意和验证的那样),当人脸特征点定位不良时,基于此想法的先前的超分辨率方法会产生带有伪像(artifact)的模糊图像。
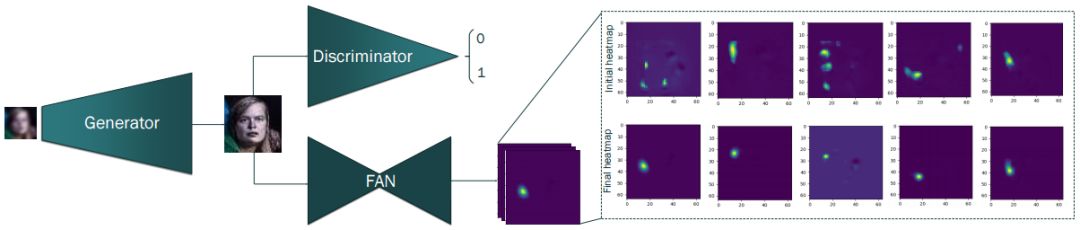
图2:本文所提出的Super-FAN架构包含三个相连的网络:第一个是刚刚提出的超分辨率网络。第二个网络是基于WGAN的鉴别器,用于区分超分辨率和原始HR图像。第三个网络是FAN,这是一个人脸对齐网络,用于定位超分辨率人脸图像上的面部特征点,并通过新引入的热图失真来提高超分辨率。
我们的主要贡献是证明即使对于完全任意的姿势(例如头像图像,参见图1和图5),实际上也可以共同执行人脸特征点定位和超分辨率,
总而言之,我们的贡献是:
1. 我们提出了Super-FAN:第一个能够同时解决人脸超分辨率和人脸对齐的端到端系统。它通过热图回归(heatmap regression)将人脸特征点定位的子网络集成到基于GAN的超分辨率网络中,并结合了新的热图损失(heatmap loss)。参见图2。
2. 我们展示了在任意人脸姿势的合成生成和现实世界低分辨率人脸上共同训练这两个网络的好处。
3. 我们还提出了一种改进的基于残差的超分辨率架构。
4. 定量地看,我们首次报告了LS3D-W数据集上整体人脸姿势光谱的结果,并且在超分辨率和人脸对齐方面显示出了巨大的进步。
5. 定性地看,我们首次在从WiderFace数据集获取的现实世界低分辨率人脸图像上得到良好的视觉效果(参见图1和图5)。
接下来,我们来介绍一下在图像和人脸超分辨率以及人脸特征点定位(facial landmark localization)方面的相关研究。
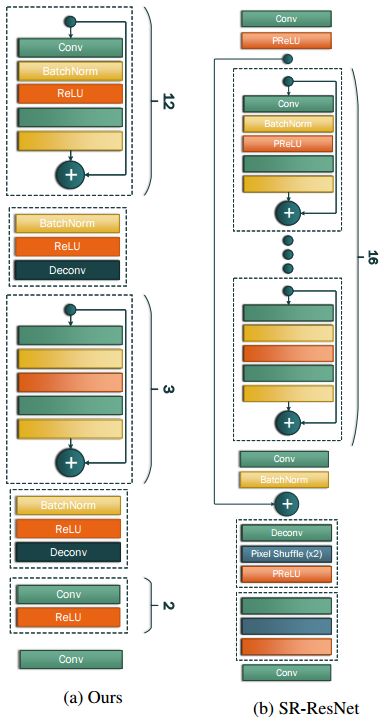
图3:本文所提出的超分辨率架构(左)与《使用生成式对抗网络实现的照片逼真的单一图像超分辨率》中描述的架构(右)之间的比较。
图像超分辨率
早期使用CNN进行的超分辨率尝试使用的是标准Lp损失进行训练的,结果导致模糊的超分辨图像。为了缓解这一问题,论文《实时风格迁移和超分辨率的感知损失》的作者提出了一个关于特征映射的MSE,提出了感知损失(perceptual loss),而不是在像素上(超分辨率和参考真实HR图像之间)使用MSE。值得注意的是,我们也在我们的方法中使用了感知损失。
最近在《使用生成式对抗网络实现的照片逼真的单一图像超分辨率》中,作者提出了一种基于GAN的方法,该方法使用鉴别器在超分辨率和原始HR图像以及感知损失之间进行区分。在《Enhancenet:通过自动纹理合成的单一图像超分辨率》中,作者提出了一种基于补丁的纹理损失,以改进重构质量。
值得注意的是,前面所提到的所有图像超分辨率方法都可以应用于所有类型的图像,因此不包含特定于人脸的信息,像在我们的研究中所提出的那样。此外,在大多数情况下,其目标是对于给定的图像,生成具有良好分辨率(通常为128×128)的高保真图像,而面部超分辨率方法通常在具有非常低分辨率(16×16或32×32)的面部上给出报告结果。
从上述所有方法中,我们的研究与《实时风格迁移和超分辨率的感知损失》和《使用生成式对抗网络实现的照片逼真的单一图像超分辨率》更为密切相关。特别是,我们的贡献之一是描述一种改进的基于GAN的超分辨率体系结构,我们将其用作一个强大的基线,在其基础上构建了我们的集成人脸超分辨率和对齐网络(alignment network)。
人脸超分辨率
最近,在《通过鉴别式生成式网络实现的极端超分辨人脸图像》的研究中,采用基于GAN的方法来分辨具有非常低分辨率的人脸图像。该方法显示,对于来自CelebA数据集的正面和预先对齐的人脸运行结果良好。
在《通过变革性的鉴别式自编码器得到极其低分辨率的未对齐和含噪声的人脸图像》中,作者提出了一个两步解码—编码器—解码器的架构,它包含一个空间转换网络以撤销转换、缩放和旋转失准(rotation misalignments)。
他们的方法在来自CelebA的正面数据集中的预先对齐的、合成生成的LR图像上进行了测试。值得注意的是,我们的网络并不试图撤销失准,而是简单地学会如何进行超分辨,并同时通过集成一个特征点定位子网络解决人脸结构问题。
图4:LS3D-W中的视觉效果
与我们的方法最相似的研究是,以交替的方式执行人脸超分辨率和密集的人脸对应。他们的算法在PubFig和Helen的正面人脸图像上进行了测试,而在真实图像(总共4张)上的测试结果少有成功。
《用于人脸幻觉的的深度级联网络》与我们研究工作的主要区别在于,密集对应算法(dense correspondence algorithm)不是基于神经网络,而是基于级联回归,是从超分辨率网络中进行分离式预学习的,并保持不变。
同样地,《用于人脸幻觉的的深度级联网络》研究也面临着同样的问题,即必须检测模糊人脸上的特征标志,这在算法的第一次迭代中尤为明显。相反,我们建议以端到端的方式联合学习超分辨率和面部特征点定位,并仅用单次对焦来完成图像的超分辨和人脸特征点的定位。如图2所示,正像我们所展示的那样,这会导致性能的大幅提升,并在整个面部姿势谱中生成高保真度图像。

图5:由我们的系统、SR-GAN和CBN在来自WiderFace的真实低分辨率人脸上所产生的结果。
值得注意的是,我们的研究成果超越了现有的技术,并且通过定量和定性两种方式,对超分辨率和人脸特征点定位进行了严格评估。在此之前,人们主要利用正面的数据集(例如:CelebA、Helen、LFW和BioID)得出实验结论,与之相反,我们在实验中所使用的低分辨率图像是通过新创建的LS3D-W平衡数据集生成的,其中每个面部姿势都对应偶数张人脸图像。
我们对取自WiderFace数据集的200张真实低分辨率图像进行了定性分析,并得出了相应结论。据我们所知,这是利用真实图像对人脸超分辨率算法进行的一次最全面的评估。
人脸对齐
近期,一项有关人脸对齐的评估表明,当分辨率降至30像素以下时,采用标准人脸分辨率(198×192)训练的中、大型姿势网络的最优性能分别下降超过15%和30%。这一评估结果是我们开展此次研究的主要目标之一。
由于我们的目标不是提出一种新的人脸对齐架构,因此我们采用人脸对齐网络(Face Alignment Network,FAN),该网络由沙漏网络(Hourglass network)与残差块(residual block)构建而成。如图所示,FAN对任意面部姿势都能够表现出优异的性能,并获得清晰的图像。
正如我们在文中所展示的那样,一个被专门训练并用于将低分辨率图像中的特征点进行定位的FAN,性能表现欠佳。我们的一项贡献就是表明,当FAN进行集成并与超分辨率网络进行联合训练时,FAN可以以高精确度定位低分辨率图像中的面部特征点。
我们提出了Super-FAN:这是首个集成人脸超分辨率和特征点定位的端到端系统。我们通过集成子网络进行人脸对齐,并对新的热图损失进行优化,从而将面部结构信息整合至超分辨率体系结构中。我们展示了最先进的人脸超分辨率和全脸姿势对齐。不仅如此,我们还首次在现实世界中的低分辨率人脸图像上显示出了良好的效果。
原文链接:https://arxiv.org/pdf/1712.02765.pdf
未来智能实验室是人工智能学家与科学院相关机构联合成立的人工智能,互联网和脑科学交叉研究机构。
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)云脑研究计划,构建互联网(城市)云脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”



