淘宝搜索模型核心技术:用户建模篇


文章作者:龙楚、丹鸥、晨宁、元涵
内容来源:阿里机器智能
01
背景与意义
从模型分类的角度上来看,用户与商品的静态特征作用在于增强模型的泛化性,而用户实时行为的引入与建模,可以大大增强样本之间的区分性,显著地提升模型的分类精度。我们把用户建模的过程看作是对用户的信息抽象和信息组织的过程。
信息抽象方面我们不断地优化与丰富建模方式:
user profile用来表征用户的静态属性信息;
偏好标签的挖掘,从行为上预测用户的一般性偏好;
实时行为建模,更细粒度的对当前请求下的兴趣刻画与描述。
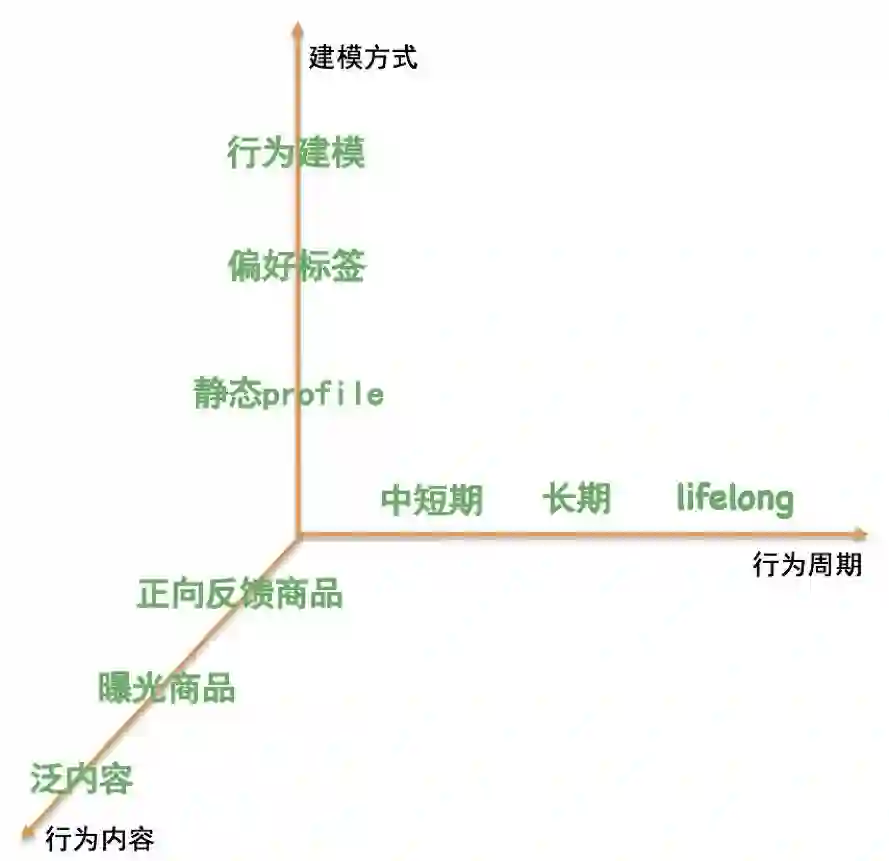
信息处理方面,我们从行为周期和行为内容方面对用户行为数据进行合理的组织:
从行为周期上,我们将行为序列划分成中短期和长期,分别使用不同的时间跨度,描述不同粒度的兴趣;
从行为内容维度上,直接行为反馈商品和曝光商品分别被用来显式和隐式的表达用户意图,与此同时,我们也将用户行为数据从传统的电商商品,延伸到一些泛内容信息。
用户行为建模也是推荐,广告等很多团队在研究的方向(比如广告团队的DIN,DIEN,Practice on Long Sequential User Behavior Modeling,推荐团队的MIND,DSIN,等等非常好的工作),我们力求从实际应用出发,和大家分享我们在搜索场景中用户建模的一些实践经验。同时将我们所观察到的现象、问题写出来,欢迎大家多讨论交流。本文后续包含的内容如下:
简要介绍大模型的整体模型结构
用户数据与行为序列的组织与处理
模型结构的改进
模型的实验和分析,相关实际问题的研究与讨论

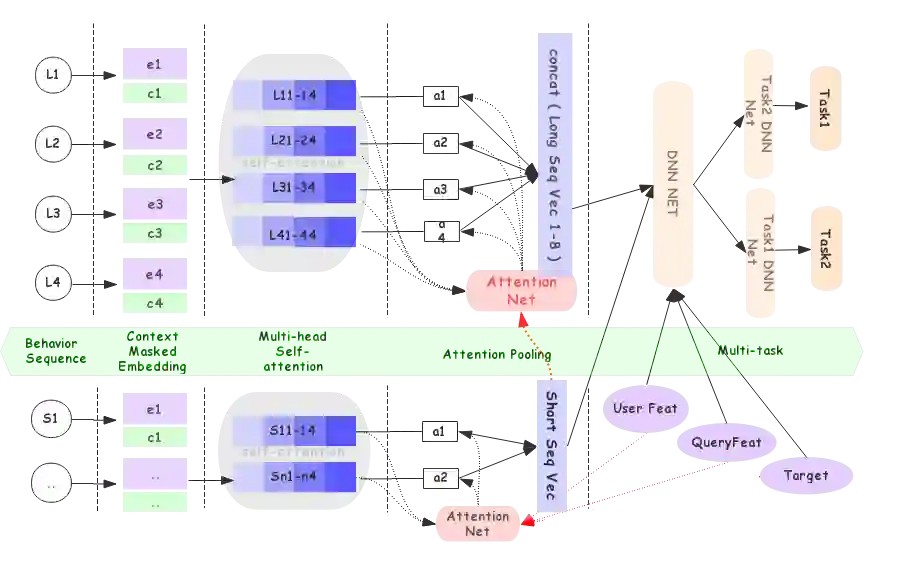
我们的模型结构大致所图所示,用户画像、多个用户行为序列特征、待打分的商品特征和一些其他的实时上下文特征(天气、网络、时间等特征),最终concat之后,进入DNN的分类器。用户行为序列建模是模型中最重要的部分之一,对于实时刻画用户兴趣尤其重要。我们这里采用self atten和atten pooling的方式来做序列建模,self atten刻画行为之间的相互关系,atten pooling对行为进行匹配激活并实现combine。这是我们一个通用化的序列建模组件。下面将基于该模型框架,进一步介绍我们今年的优化工作及其实现细节。
user profile 仅仅是一些比较静态的用户特征,这些静态特征作为对user_id的补充和泛化。近来以session-based recommendation为代表的理解用户实时兴趣的模型,越来越受到广泛的研究,大量实验表明其能够显著提升推荐的准确率。特别是用户当前越短期的行为,越能代表用户目前的兴趣状态。使用用户有过行为的商品来表征用户,有助于我们实时的捕获用户兴趣的动态性。另外,以Graph的角度来看,由user-item组成的图中,item是稠密结点,user是稀疏结点,稠密结点适合用来对稀疏结点进行表达。
我们定义统一的行为schema如下图:
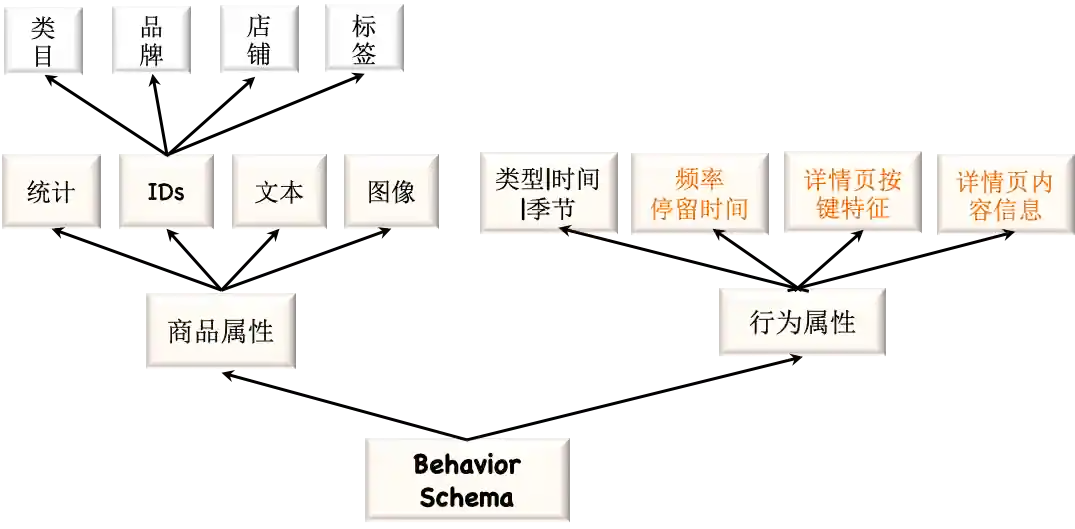
包含两个部分,商品自身的属性特征和用户对商品的行为特征。属性特征包括item_id, seller_id等一系列对商品进行描述的特征。行为特征包括用户对商品的行为类型,行为时间,序列位置等特征。
1. 中短周期
数据与特征: 在去年星舰项目中,我们针对用户中短期,不同行为类型的行为进行了全局建模,该序列包含了用户全网实时的点击 加购 收藏 购买等行为。鉴于用户历史行为非常丰富,而我们的序列长度有上限(L_max=50),因此我们通过query的预测类目来甄选出与当前意图类目更相关的历史行为。用户主动输入query,这是搜索和推荐最大的区别。关于query方面,query理解团队已经做了大量的工作。在此,我们利用query理解的结果,使用query的预测叶子类目,对用户行为序列做筛选。
模型结构:
Transformer模型在NLP领域取得了非常好的效果,它通过使用self atten机制,捕捉到了序列内部的依赖关系,同时它可以并行计算,提高训练和预测的速度。在CTR模型中,我们广泛地使用self atten来处理商品sequence。我们在现有self-atten的基础上进行如下两点改进。
-
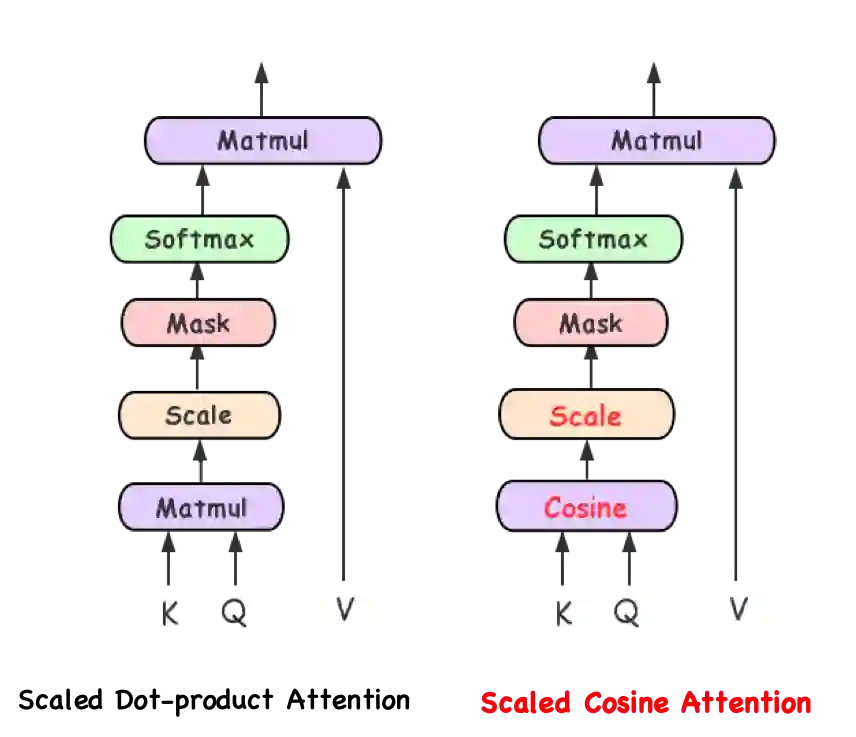
我们采用了cosine + scale up代替原来的点乘+scale down(也可以通过加入layer norm),来计算K和Q的相似度,提升softmax logits输出值的区分度。因为在套用原来的self-atten时,我们发现了一些问题:(1). softmax logits值非常小,导致atten的权重一直处于均值状态;(2). atten结构出现梯度弥散,导致几乎不能被学习。我们的CTR模型embedding从0初始化,而不是随机初始化,过小的梯度导致self atten很难被学习。为此,我们使用cosine值代替点乘,计算K与Q的距离。如下图所示: -
对self-atten的输出结果我们进行了一个query_atten_pooling。虽然我们的中短期序列尽量保证了与当前意图的类目一致性,但为了进一步保证query一致性,这里对中短期序列进行一个query_atten_pooling,激活与当前query意图和语义一致的历史行为;后续实验部分也会进一步分析为什么这里不使用通用的target attention。
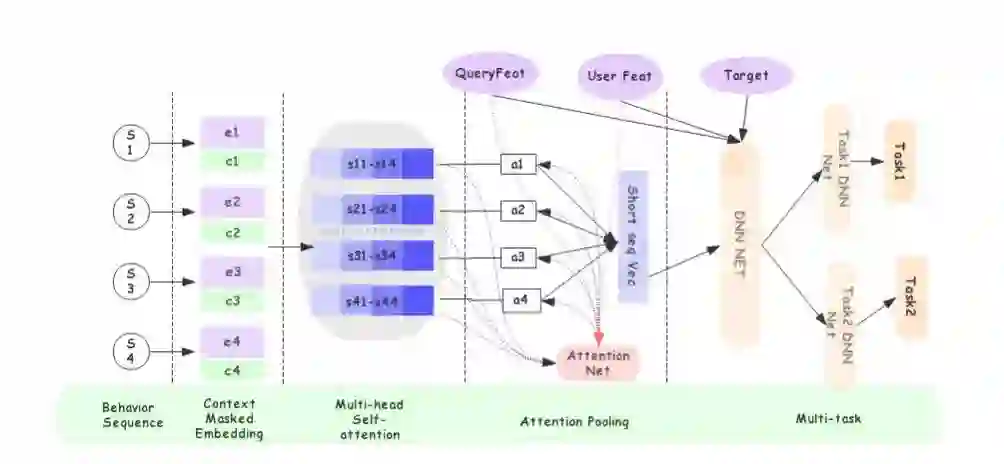
-
如下图所示,首先对长期行为item_level embedding特征用context_level embedding进行add_mask,即e1+c1。然后用一个多层建模方式,先在季度序列内通过优化后的self atten进行特征抽取和子序列的atten_pooling,得到当前季度的用户偏好表达。最后对不同季度进行concat(也尝试过atten_pooling,效果比concat稍微差一点),得到用户最终的长期偏好表达。这样做的好处在于,对于季节敏感的搜索意图,能更好的抽取与当前季度更匹配的偏好信息。 -
这里的atten_pooling是用shortseq_vec来作为查询Query的; Shortseq_vec是一个综合了用户意图和用户实时偏好的表达,比直接用原始搜索词(仅能表达用户搜索意图), 能更加全面评估历史trigger对当前搜索的重要性;同时short seq也属于序列,向量空间上也比较接近。

04
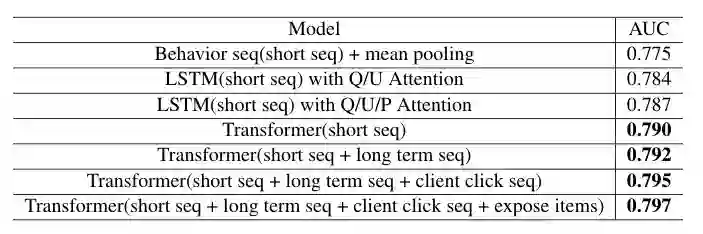
实验与分析


05
总结与展望
06
参考资料
在文末分享、点赞、在看,给个三连击呗~~

文章推荐:
关于我们:
DataFunTalk 专注于大数据、人工智能技术应用的分享与交流。发起于2017年,在北京、上海、深圳、杭州等城市举办超过100场线下沙龙、论坛及峰会,已邀请近500位专家和学者参与分享。其公众号 DataFunTalk 累计生产原创文章300+,百万+阅读,7万+精准粉丝。

🧐分享、点赞、在看,给个三连击呗!👇



