盘点图像分类的窍门

本文为 AI 研习社编译的技术博客,原标题 :
A Bag of Tricks for Image Classification
作者 | George Seif
翻译 | dongburen、老赵
校对 | 邓普斯•杰弗 审核| 酱番梨 整理 | 菠萝妹
原文链接:
https://towardsdatascience.com/a-big-of-tricks-for-image-classification-fec41eb28e01
注:本文的相关链接请点击文末【阅读原文】进行访问
盘点图像分类的窍门

你最近一次了解到深度学习理论百分百与实际验证相匹配是什么时候?这种情况很少发生。研究论文阐明的是一种情况,但实际生活中的结果却与之有所不同。
这不完全是研究论文的问题。实验是科学研究的重点,基于特定的环境,特定数据集,我们得到相应结果。一旦你在实际中应用这些模型,处理噪声和野生数据的挑战就必须考虑。理论并不是经常和现实世界中所发生的完全契合,但理论确实提供了一个基准。
那么造成理论和实际之间差距的原因是什么——现实生活中没有足够多的新数据。主要的区别来自于深度学习专家为了提供额外性能提升处理模型所使用的''技巧''。你可以通过对模型进行大量实验,或者只是从已拥有模型的人那里学习得到这些均衡模型性能的隐藏技巧。来自亚马逊研究团队的最新研究定量指出对同一模型使用这些处理技巧最大可得到4%的准确度性能提升。
在本文中,你会了解到专家对其深度学习模型提升额外性能的处理技巧。我将为你提供在实际应用设置中使用这些技巧的观察点。
大批量尺寸
在理论中,一个较大的mini-batch尺寸有助于网络收敛到较好的最小值,最终得到较好的准确性。由于GPU内存的原因,人们经常会在这里受阻,因为消费者最大能买到的GPU高达12GB(对于Titan X)和16GB云端(对于V100)。 我们有两种方法可以应对这一挑战:
(1).分布训练:将训练数据划分到多块GPU上。在每个训练阶段,会将批拆分到空闲的GPU。举例来说,假设你有批尺寸为8的图像和8个GPU,然后每个GPU处理一副图像。你可以将各自最终的梯度和输出分别结合起来。你确实从GPU之间的数据传输中花费了轻微的代价,但仍然可以通过并行处理获得大幅速度提升。许多开源的深度学习库(包括Keras)都支持这个函数。
(2).在训练中改变批和图像尺寸:大量研究论文报告大批量广泛使用的部分原因是许多标准研究数据集的图像尺寸都不是很大。 例如,在ImageNet上训练网络时,大多数最先进的网络都使用了像素在200p到350p之间的图像; 当然如此小图像尺寸可以使用大批量!实际上,由于目前的照相技术,我们大多数都在处理1080p或与1080p相差不大的图像。
为了克服这点小困难,你可以小图像大批量开始训练。通过降采样训练图像得到。然后,你可以将更多的它们组合成一个批次。使用大批量+小图像,你应该能得到一些不错的结果。为了完成网络训练,使用较小的学习速率和较小批量的大图像对网络进行微调。这有助于网络重新适应高分辨率,并且低学习速率使网络不会跳离从大批量发现的良好最小值。因此,你的网络可以从大批量训练中获得最佳效果,并且可以很好地处理来自微调的高分辨率图像。
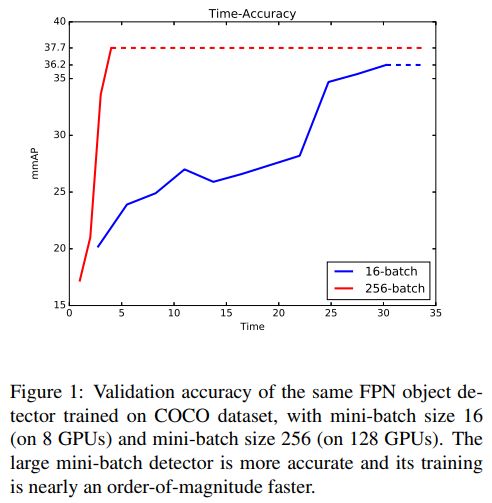
大型小批量训练对物体探测器的影响
模型微调
研究报告并不总能告诉你全部情况。作者通常会在论文中给出他们的官方代码链接,这是一个学习算法比论文本身更好的资源!当您阅读代码时,您可能会发现他们遗漏了一些小的模型细节,而这些细节实际上造成了很大的准确性差异。
我鼓励大家看一下研究论文的官方代码,这样你就可以看到研究人员用来获得结果的确切代码。这样做还可以为您提供一个很好的模板,以便您可以快速地进行自己的小调整和修改,以查看它们是否改进了模型。探索一些模型的公开的二次实现也是很有帮助的,因为这些模型可能包含其他人已经试验过的代码,这些代码最终在原始模型的基础上得到了改进。看看下面的ResNet架构,以及在一些公共代码中发现的3处更改。它们看起来很小,但是每一个都在运行时几乎没有变化的情况下提高了不可忽略的准确性;ResNet-D在Top-1准确率上整整提高了1%。
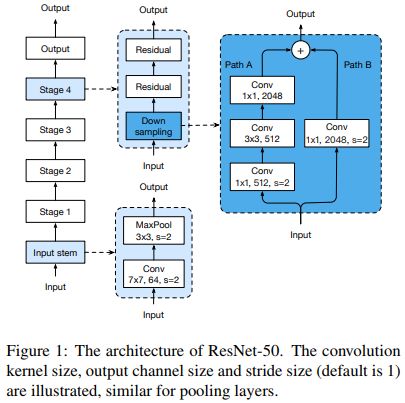
ResNet-50的原始结构
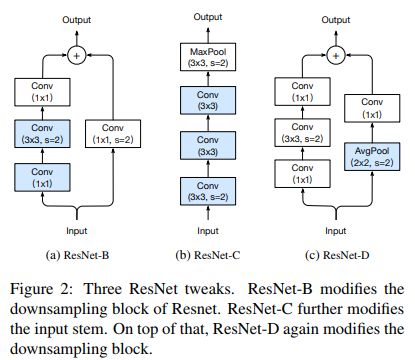
ResNet-50的改进和提高版本
训练方法改进
根据实际的应用和研究团队设置训练的不同,深度网络的训练方式往往不尽相同。知道如何正确地训练神经网络可以让你的准确率提高3-4%。这种技能,既需要来自于对深度网络的了解,也来自于一些简单的实践。
不幸的是,大多数人不太重视训练,并期望网络神奇地给他们带来很棒的结果。
请注意在最新研究中使用的具体训练策略。你会经常看到他们中的大多数不会仅仅默认为一个单一的学习率,而是使用像Adam或RMSProp这样的自适应方法采用动态的学习率。他们使用诸如热身训练、速率衰减和优化方法的组合来获得他们可能达到的最高准确率。
下面是我个人最喜欢的方法。
Adam optimiser非常容易使用,而且它可以自动得到适合的学习率。另一方面,SGD通常会比Adam提高1-2%,但是很难调参。那么,从Adam开始:只要设置一个学习速率,它不是高得离谱的,通常默认值是0.0001,你通常会得到一些非常好的结果。然后,一旦您的模型使用Adam效果达到极限,就可以用SGD从较小的学习率开始进行微调,以实现准确率最后的提升!
迁移学习
除非你在做前沿研究,试图打最先进的基础技术,否则转移学习应该是默认的实际的方法。从头开始对新数据进行网络培训是具有挑战性、耗时,有时还需要一些额外的领域专家才能真正做好。
迁移学习提供了一种既能加速训练又能提高准确性的简单方法。大量的研究和实践证据一致表明,迁移学习使模型比从头开始的训练更容易训练,并提高了准确性。它将完全简化事情,使您更容易获得一些不错的基线结果。
一般来说,具有更高准确率的模型(相对于同一数据集上的其他模型)将更有利于转移学习,并获得更好的最终结果。唯一需要注意的事情是,要根据你的目标任务选择相关的网络进行转移学习。例如,在医学成像数据集上使用一个为自动驾驶汽车预先培训的网络不是一个好主意;由于数据本身是非常不同的,所以域之间存在巨大的差异。你最好从头开始训练,不要在开始的时候就带来数据的偏差,因为带来偏差的数据和医疗影像完全不同。
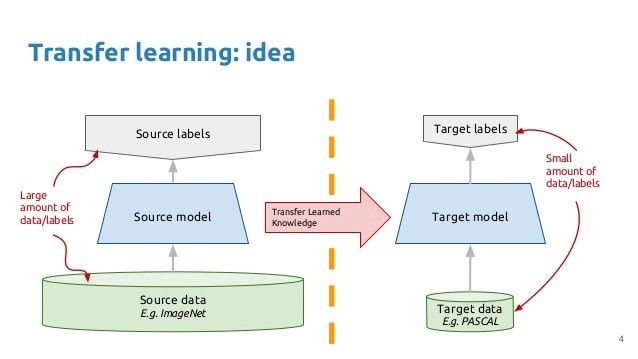
迁移学习的主要思想
精选的数据增强
数据增强是另外一种大幅提高准确率的方法。大部分人只关注经典的旋转和裁切,这样也可以。如果你有时间去等待在这些额外的图像训练的时间,他们可以潜在的给你额外的几个百分点的准确率的提高,而且无需增加训练时间。
但是最先进的方法不仅如此。
一旦你开始开始更深入的研究,你会发现更多先进的数据增强方法,这些方法可以给深度神经网络带来最后的提高。缩放,比如图像乘以图像像素的颜色或者亮度的值,可以使训练图像比原始图像更广泛的暴露在训练网络。它有助于解释这些变化,特别是,根据房间或天气的不同光照条件,这些在现实世界中变化非常频繁。
另外一个技巧,裁剪正则化(Cutout Regularisation),在最新的ImageNet上广泛应用。尽管名为裁剪(cutout),但它实际上可以看作是采取遮挡的方式进行数据增强。在现实世界的应用中,遮挡是一个非常常见的挑战,尤其是在机器人和自动驾驶汽车的热门计算机视觉领域。通过对训练数据应用某种形式的遮挡,我们可以有效地调整我们的网络,使其更加具有鲁棒性。

裁剪正则化/数据增强
想要继续查看该篇文章相关链接和参考文献?
长按链接点击打开或点击底部【阅读原文】:
https://ai.yanxishe.com/page/TextTranslation/1392
AI研习社每日更新精彩内容,观看更多精彩内容:
盘点图像分类的窍门
深度学习目标检测算法综述
生成模型:基于单张图片找到物体位置
AutoML :无人驾驶机器学习模型设计自动化
等你来译:
如何在神经NLP处理中引用语义结构
你睡着了吗?不如起来给你的睡眠分个类吧!
高级DQNs:利用深度强化学习玩吃豆人游戏
深度强化学习新趋势:谷歌如何把好奇心引入强化学习智能体

2月2日至2月12日,AI求职百题斩之每日挑战限时升级,赶紧来答题吧!
0209期 答题须知
请在公众号菜单【每日一题】→【每日一题】进入,或发送【0209】即可答题并获取解析。

点击阅读原文,查看更多内容



