简单介绍 TF-Ranking

本文为 AI 研习社编译的技术博客,原标题 :
Introducing TF-Ranking
作者 | Jesus Rodriguez
翻译 | Lemon_Sophia
校对 | 邓普斯•杰弗 审核 | 酱番梨 整理 | 立鱼王
原文链接:
https://towardsdatascience.com/introducing-tf-ranking-f94433c33ff
注:本文的相关链接请访问文末二维码

排序是机器学习场景中最常见的问题之一。从搜索到推荐系统,排名模型是许多主流机器学习体系结构的重要组成部分。在机器学习理论中,排序方法通常使用像learning-to-rank(LTR)或machine learning ranking机器学习排序(LTR)这样的术语。尽管具有相关性,但是在大多数机器学习框架中,大规模开发LTR模型仍然是一个挑战。最近,来自谷歌的人工智能(AI)工程师引入了TF-Ranking,这是一个基于TensorFlow的框架,用于构建高度可伸缩的LTR模型。几周前发表的一篇研究论文详细阐述了TF-Ranking背后的原则。
从概念上讲,排序问题定义为对一组样本(或示例)进行排序的派生,这些示例可以最大化整个列表的效用。这个定义听起来类似于分类和回归问题,但排序问题从根本上是不同的。分类或回归的目标是尽可能准确地预测每个示例的标签或值,而排序的目标是对整个示例列表进行优化排序,以便最先显示相关度最高的示例。为了推断相关性,LTR方法尝试学习一个评分函数(valued scores),该函数将示例特征向量映射到标记数据的实值评分(real-valued scores)。
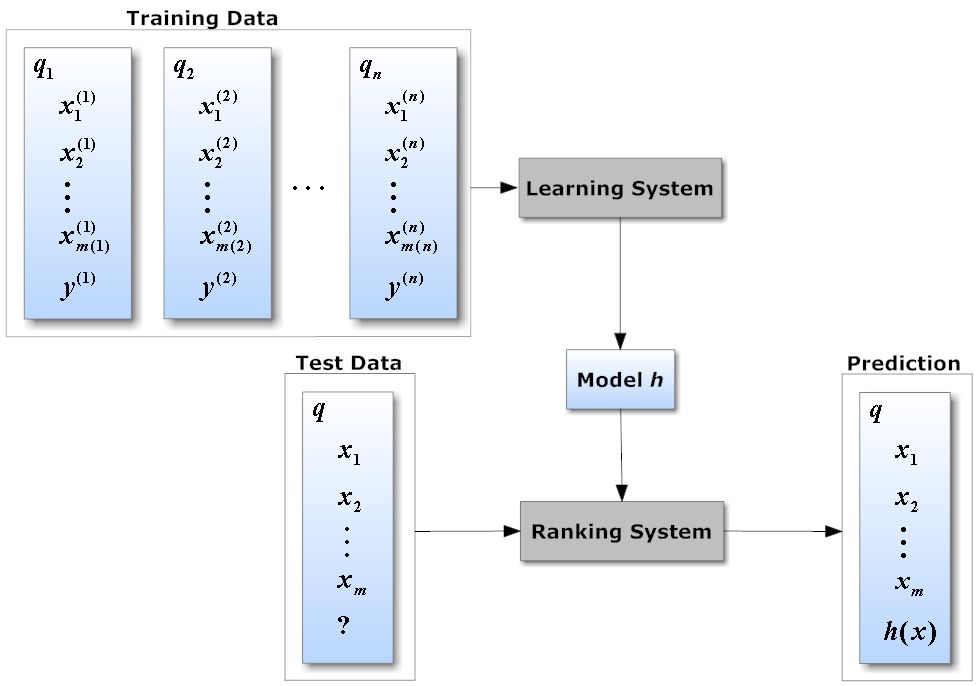
这种简单的体系结构已经成为大多数排名算法以及RankLib或LightGBM等库的基础。虽然这些库提供了有效的排序方法,但它们是针对小型数据集实现的,这使得它们在依赖于大量训练数据的实际场景中不切实际 。除此之外,现有的LTR库还没有为在深度学习场景中常见的稀疏和多维数据集而设计。
现有LTR stacks(LTR栈)的局限性使得LTR方法在深度学习场景中的实现越来越复杂。由于缺乏对主流深度学习框架(如TensorFlow、MxNet、PyTorch或Caffe2)中的排名模型的支持,这个问题变得愈加严峻。
进入 TF-Ranking
TF-Ranking是一个基于tensorflow的框架,它支持在深度学习场景中实现TLR方法。该框架包括实现流行的TLR技术,如成对pairwise或列表listwise损失函数、多项目评分、排名指标优化和无偏学习排名。
TF-Ranking的实现非常复杂,但使用起来也非常简单。该实现的核心组件是一个model_fn函数,它接受特征和标签作为输入,并根据模式(TRAIN、EVAL、PREDICT)返回损失、预测、度量指标和训练操作。使用TF-Ranking构建model_fn函数是基于两个基本组件的组合: 评分函数(scoring function)和排名头(ranking head)。

Scoring Function评分函数: TF-Ranking支持单项和多项评分功能。单项评分函数可以用函数F(X) = [F(x1);f (x2);:::;f(xn)],其中输入表示单个示例的特征,并计算一个分数作为输出。多项目评分函数扩展了一组示例的这种结构。TF-Ranking将每个示例列表分割成若干张量,张量的形状为[batch_size, group_size, feature_size]。从上面的代码示例中可以看到,评分函数是一个用户指定的闭包,它传递给了这个排名model_fn构建器。
Ranking Head排名头: TF-Ranking使用一个针对特定指标的排名头和排名逻辑的损失。从概念上讲,排名头结构计算排名指标和排名损失,给出分数、标签和可选的示例权重。通过编程的方式,排名头通过工厂方法tf .head.create_ranking_head公开。
使用TF-Ranking
从编程的角度来看,TF-Ranking实现了TensorFlow Estimator接口,该接口抽象了机器学习应用程序生命周期的不同方面,比如训练、评估、预测和模型服务。使用TF-Ranking的经验如下面的代码所示。
def get_estimator(hparams):
"""Create a ranking estimator.
Args:
hparams: (tf.contrib.training.HParams) a hyperparameters object.
Returns:
tf.learn `Estimator`.
"""
def _train_op_fn(loss):
"""Defines train op used in ranking head."""
return tf.contrib.layers.optimize_loss(
loss=loss,
global_step=tf.train.get_global_step(),
learning_rate=hparams.learning_rate,
optimizer="Adagrad")
ranking_head = tfr.head.create_ranking_head(
loss_fn=tfr.losses.make_loss_fn(_LOSS),
eval_metric_fns=eval_metric_fns(),
train_op_fn=_train_op_fn)
return tf.estimator.Estimator(
model_fn=tfr.model.make_groupwise_ranking_fn(
group_score_fn=make_score_fn(),
group_size=1,
transform_fn=None,
ranking_head=ranking_head),
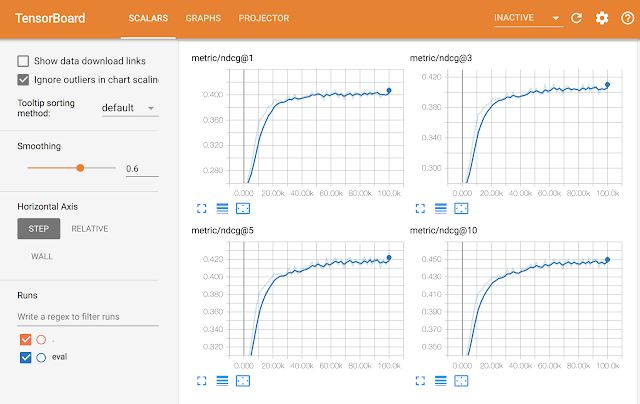
params=hparams)除了编程简单之外,TF-Ranking还集成了TensorFlow生态系统的其他部分。使用TF-Rankign开发的模型可以使用TensorBoard工具集进行可视化评估,如下图所示。
TF-Ranking在现实世界中的应用
谷歌在两个关键任务场景中评估了 TF-Ranking: 对存储在谷歌驱动器中的文档进行Gmail搜索和推荐。在Gmail搜索场景中,使用TF-Ranking对匹配特定用户查询的五个结果进行排序。用户点击等指标被用作排名的相关标签。不同排序模型的结果如下矩阵所示。
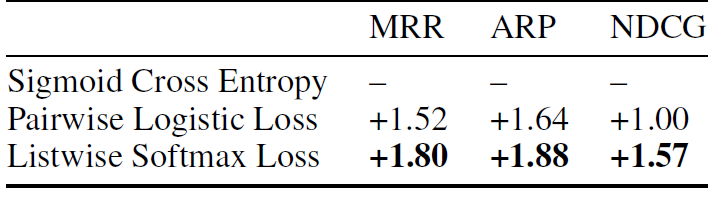
在谷歌驱动器场景中,TF-Ranking用于实现一个推荐引擎,该引擎在用户访问驱动器主屏时显示当前相关的文档。与Gmail场景类似,推荐系统会考虑用户点击量来重新评估排名模型。结果如下矩阵所示。

TF-Ranking是对TensorFlow堆栈的一个很好的补充。不同于它的前身。TF-Ranking针对需要大型数据集的模型进行了优化,并基于TensorFlow估计器提供了非常简单的开发人员体验。包含示例和教程的TF-Ranking代码可以在GitHub上找到。
想要继续查看该篇文章相关链接和参考文献?
点击底部【阅读原文】或长按下方地址/二维码访问:
https://ai.yanxishe.com/page/TextTranslation/1342


点击阅读原文,查看更多内容↙



