教程 | 搜喵输入法:用seq2seq训练自己的拼音输入法
选自GitHub
作者:Guan Wang
微信@crownguanwang
项目代码:https://github.com/crownpku/Somiao-Pinyin
对于中文文本数据,我们每天都在为腾讯贡献着聊天记录,或者为百度贡献着搜索记录。而中文文本数据最大的入口,我觉得其实是搜狗输入法。这些年看上去,搜狗已经基本统治了中文输入法。PC,Mac,iPhone,安卓都装上了搜狗输入法,甚至码农朋友们装上 ubuntu 后的第一反应也是去装个 linux 版本的 Sougou Input(虽然很多 bug)。搜狗输入法真的好用,而且越用越顺手,背后一定是数据驱动的算法。
然而我对于把我的所有输入数据,包括各种密码,都不知不觉贡献给了搜狗还是觉得不舒服。搜狗完全有能力在我输入我复杂的前半部分密码的时候自动跳出和推荐我的后半部分密码。貌似现在只有 iPhone 的 iOS 系统能在识别出用户输入密码的时候自动跳转成为苹果自己的(我们窃以为安全的)输入法键盘。
Github 上有一个韩国大神的 project Kyubyong/neural_chinese_transliterator,用 seq2seq 训练自己的中文拼音输入法。这是这篇博客的主题。我们的代码完全基于这个开源项目,加入了交互式的拼音测试环境。感谢韩国大神!而未来是希望能将这个偏 research 的项目做成一个真正可用的产品,一个模型和数据本地化(别把数据上传云端)、根据输入内容手动甚至自动选择预训练模型(想象正在 B 站发弹幕或者在写毕业论文的不同场景)、根据用户输入数据不断更新越来越好用的拼音输入法。我把它暂且叫做「搜喵输入法」。
seq2seq 模型
拼音输入的本质上就是一个序列到序列的模型:输入拼音序列,输出汉字序列。所以天然适合用在诸如机器翻译的 seq2seq 模型上。
模型初始输入是一个随机采样的拼音字母的 character embedding,经过一个 CBHG 的模型,输出是五千个汉字对应的 label。
这里使用的 CBHG 模块是 state-of-art 的 seq2seq 模型,用在 Google 的机器翻译和语音合成中,结构如下:
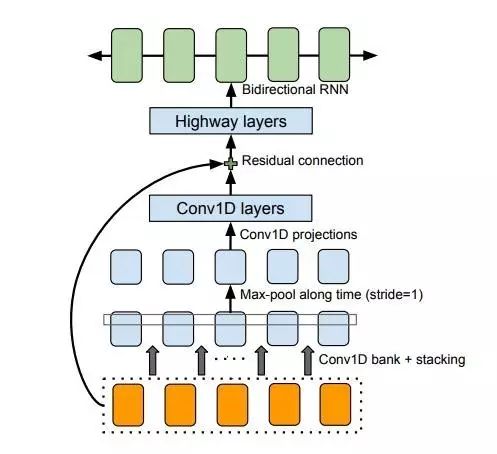
图片来自 Tacotron: Towards End-to-End Speech Synthesis
值得注意的几点:
1. 模型先使用一系列的一维卷积网络,有一系列的 filter,filter_size 从 1 到 K,形成一个 Conv1D Bank。这样的作用相当于使用了一系列的 unigrams, bigrams 直到 K-grams,尽可能多的拿到输入序列从 local 到 context 的完整信息。其实这样的模型,与之前我们提到过的 IDCNN(Iterated Dilated Convolutionary Nerual Network) 有异曲同工之妙。而 IDCNN 相比较起来有更少的参数,不知道如果把 CBHG 的 Conv1D Bank 换成 IDCNN 是怎样的效果。
2. 模型在最终的 BiGRU 之前加入了多层的 Highway Layers,用来提取更高层次的特征。Highway Layers 可以理解为加入了本来不相邻层之间的「高速公路」,可以让梯度更好地向前流动;同时又加入一个类似 LSTM 中门的机制,自动学习这些高速公路的开关和流量。Highway Networks 和 Residual Networks、Dense Networks 都是想拉近深度网络中本来相隔很远的层与层之间的距离,使很深的网络也可以比较容易地学习。
3. 模型中还使用了 Batch Normalization(继 ReLU 之后大家公认的 DL 训练技巧),Residual Connection(减少梯度的传播距离),Stride=1 的 Max-pooling(保证 Conv 的局部不变性和时间维度的粒度)以及一个时髦的 BiGRU。Tacotron: Towards End-to-End Speech Synthesis 这篇文章发表在 2017 年 4 月,最潮的 DL 技术用到了很多。
语料获取
理论上所有的中文文本语料,我们都可以通过 xpinyin 这样的工具转化为拼音数据。这相当于只要有中文文本,我们就有了带标注的训练数据。
Kyubyong/neural_chinese_transliterator 中使用了德国一个研究所的 2007-2009 的中文新闻语料。我们也可以使用中文维基百科 dump 和百度百科这样的语料。
再开脑洞,我们可以用所有中文的研究论文作为语料,训练学术版搜喵输入法;
用所有文言古文作为语料,训练文言文版搜喵输入法;
用所有 Bilibili 弹幕作为语料,训练网络鬼畜版搜喵输入法;
用所有自己的聊天记录作为语料,训练准确吻合自己语气的搜喵输入法;
等等等等。
模型训练
Clone 搜喵输入法项目: https://github.com/crownpku/Somiao-Pinyin
系统要求
Python (>=3.5)
TensorFlow (>=r1.2)
xpinyin (中文拼音标注)
distance (在测试集上测试时计算预测结果和真实结果的差别)
tqdm
训练:
1. 下载 Leipzig Chinese Corpus。解压缩,把 zho_news_2007-2009_1M-sentences.txt 拷贝到 data/ 文件夹。当然你也可以用你自己的中文语料,改成一样的格式,或者修改一下 build_corpus.py 里面的解析部分.
2. 建立拼音-汉字的平行语料。
#python3 build_corpus.py
3. 建立词典和生成训练数据。
#python3 prepro.py
4. 训练模型,模型存在 log/ 文件夹中。所有的参数都在 hyperparams.py 中。如果有好的 GPU,可以把 Batch size 调大一些。现有的默认参数,一个 Epoch 要跑一个多小时。
#python3 train.py
命令行输入拼音测试:
运行下面的命令,进行命令行输入拼音的测试
#python3 eval.py
如果你不想自己训练数据…
预训练好的模型放在百度网盘。
链接:http://pan.baidu.com/s/1pLhuRkJ 密码:psbk
将解压缩生成的 /log 和 /data 放在工程的根目录下。记住要覆盖掉 /data 下面的 pickle 文件,因为 pickle dump 有随机性,自己运行 prepro.py 生成的 pickle 文件会和预训练模型起冲突。
然后运行下面的命令,进行命令行输入拼音的测试
#python3 eval.py
一些结果
预训练的模型是在 2007-2009 的老新闻语料上训练的。可以想象这十年来中文语言的变化也非常之多。
我尝试了一些拼音输入,也鼓励大家尝试在上面提到的大开脑洞的中文语料上训练模型看看结果。
请输入测试拼音:nihao
你好
请输入测试拼音:chenggongle
成功了
请输入测试拼音:wolegequ
我了个曲
请输入测试拼音:taibangla
太棒啦
请输入测试拼音:dacolehuizenmeyang
打破了会怎么样
请输入测试拼音:pujinghehujintaotongdianhua
普京和胡锦涛通电话
请输入测试拼音:xiangbuqilaishinianqianfashengleshenme
想不起来十年前发生了什么
请输入测试拼音:meiguohongzhawomenzainansilafudedashiguan
美国轰炸我们在南斯拉夫的大事馆
请输入测试拼音:liudehuanageshihouhaonianqing
刘德华那个时候好年轻
请输入测试拼音:shishihouxunlianyixiabilibilideyuliaole
是时候训练一下比例比例的预料了
原文链接:http://www.crownpku.com/2017/09/10/%E6%90%9C%E5%96%B5%E8%BE%93%E5%85%A5%E6%B3%95-%E7%94%A8seq2seq%E8%AE%AD%E7%BB%83%E8%87%AA%E5%B7%B1%E7%9A%84%E6%8B%BC%E9%9F%B3%E8%BE%93%E5%85%A5%E6%B3%95.html
本文为机器之心经授权转载,转载请联系本文作者获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com




