EBR: Facebook在向量检索上的探索

广告推荐算法系列文章:
-
莫比乌斯: 百度的下一代query-ad匹配算法 -
百度凤巢分布式层次GPU参数服务器架构 -
DIN: 阿里点击率预估之深度兴趣网络 -
基于Delaunay图的快速最大内积搜索算法 -
DIEN: 阿里点击率预估之深度兴趣进化网络 -
EBR: Facebook基于向量的检索
Overall
开始之前,先简单了解下Facebook的搜索业务,如下有三种,用过社交网络的大概都能理解。
-
People Search: 找人 -
Groups Search: 找组 -
Events Search: 找事件
之前Facebook的做法是字符串匹配和类似SQL query的形式。但这都2020年了,显然需要考虑用深度学习的方式去改进。
论文[1]介绍了Facebook中搜索业务是如何从bool匹配到基于embedding的检索的,包括了各个方面的技巧,值得一看。
通常在搜索引擎中会分为两个层次,这点我们在莫比乌斯: 百度的下一代query-ad匹配算法也有所介绍。
-
Retrieval层,也称召回层,用来在占用较少计算资源和较低延迟的要求下快速检索出一部分相关文档。 -
Ranking层,也称精确层,用一些较为复杂的方法对Retrival层检索得到的文档进行排序。
理论上说,Embedding在这两个层次上都可以应用,但一般情况下会在Retrival层应用,因为这一层在最底部,能最大限度的提升系统的效果。在,Retrival层上应用Embedding称之为Embedding-Based Retrieval,或者缩写EBR。
EBR架构如下:

在Retrival层应用有两个挑战:
-
Retrival层需要处理数十亿甚至数千亿的文档,数据量很大,做索引耗时。 -
搜索引擎需要将EBR和字符串匹配的方法结合起来。
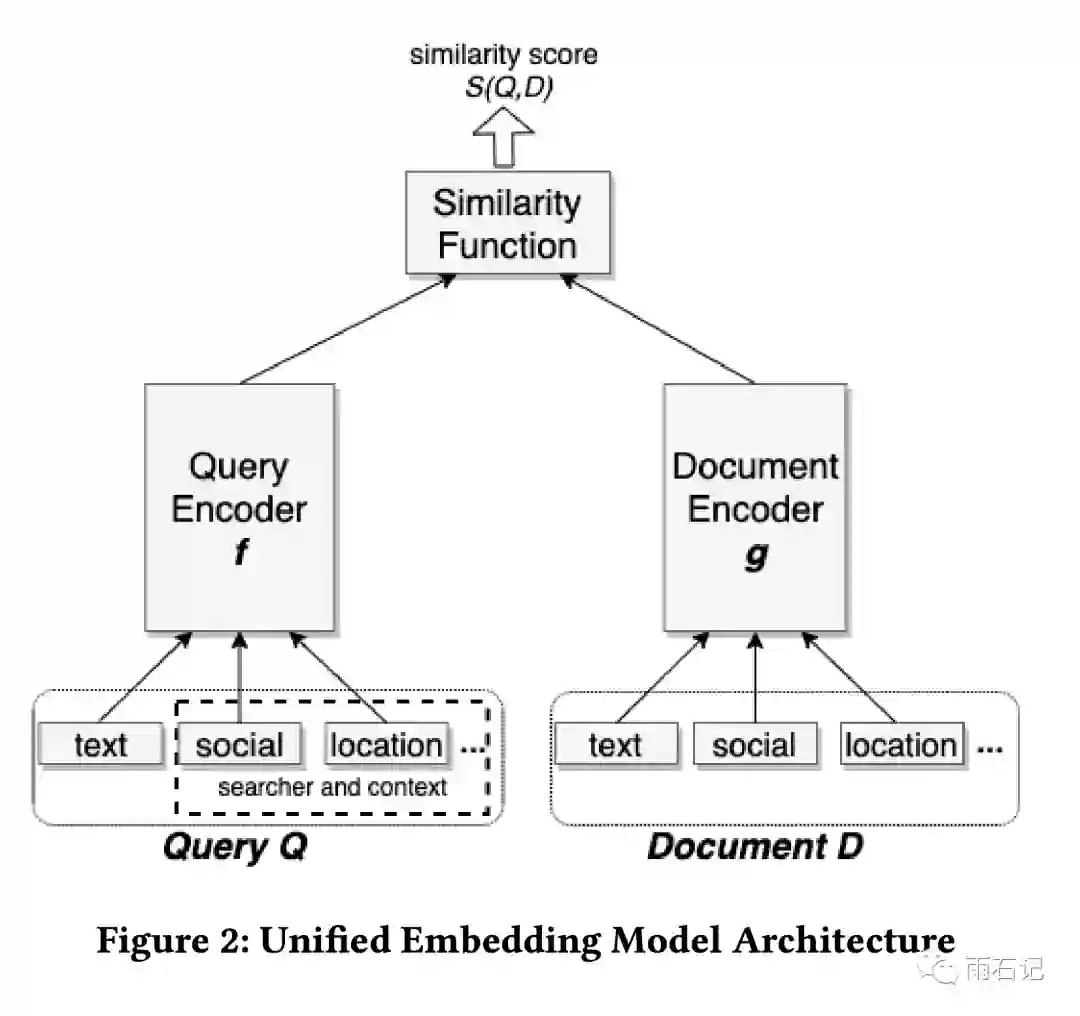
作为一个社交搜索引擎,Facebook上应用EBR还有另外一个难处,那就是搜索意图不仅仅依赖于query文本,还和用户本身和上下文相关。因此,在模型方面,提出了Unified Embedding,即一个双边模型,一边是文档,另一边是搜索请求,搜索请求是query文本,搜索者和上下文的联合embedding。
为了能更好更快的训练EBR,探索了两个方向,也是本论文的精华所在。
-
Hard mining: 让训练更加高效。 -
Ensemble Embedding: 将模型分为多个阶段,每个阶段有不同的recall / precision tradeoff,另一种思路则是拼接。
得到模型以后,很自然的会考虑模型独立运行,然后将结果和已有的Retrival和embedding KNN合并起来,但这样做不好,因为:
-
性能会有较大的降低 -
维护困难,需要维护双索引 -
两种方法得到的候选重叠可能很大,不高效。
因此,实现了一种将Embedding KNN和Bool Match混合起来的方法,这种方法除了能解决上述的问题之外,还有两个优势:
-
Embedding和Term Match可以联合优化 -
支持有Term Match约束的Embedding KNN搜索,不仅提高系统性能,还可以提升准确率。
搜索是多阶段的事情,Retrival是其中的第一步,接下来是多个排序和过滤模型。在将Retrival层优化了之后,后面的各个阶段都需要调整以适应前面的优化。这就是所谓的Full-Stack Optimization。
模型
给定一个query,如果target集合是T = {t1, ..., tN},而返回的结果是 {d1, d2, ..., dK},那么召回率recall@K按照如下方式计算
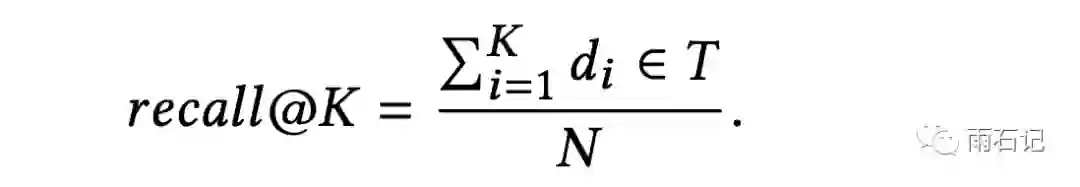
损失函数采用triplet loss, 其中q为query,d+为正例,d-为负例。m为Margin Value,用来控制query和正例的距离至少与query和负例的距离大多少。

Margin Value的设置非常重要,可以引发5-10%的KNN召回率的变化。
模型结构如下,虽然query和document是分开用NN去做embedding的,但是模型结构的有些部分可以共享。可以看到,embedding是多种信息的综合。
距离的计算使用余弦距离。
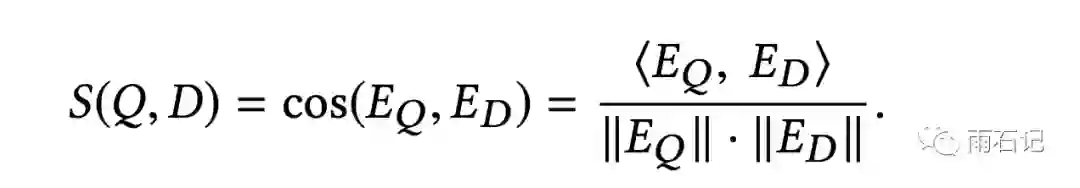
训练数据
正例和负例的定义对搜索问题至关重要。对于正例,比较明显,选择点击过的样本为正例;对于负例而言,尝试了两种方法:
-
随机采样: 对每个query,随机从文档池中选择文档作为负例。 -
没有点击过的曝光文档: 对每个query,从曝光过但没有点击的文档中随机选择作为负例。
第二种会比第一种差很多,原因在于第二种所采样得到的样例都属于hard examples,即有一个或多个因素是可以match上的;但大多数的文档是easy examples,因为没有能match上的因素;所以如果全部采用hard examples会导致结果变差,因为此时train和inference的数据分布是不同的。
另外,对正例也做了探索,尝试了两种方法:
-
clicks: 点击即正例 -
impressions: 曝光即正例,在这里,将Retrieval层作为Ranker层的近似,并且希望retrival层能给出和ranker层结果类似的结果。
实验表明,两种方法的效果都很好。
特征工程
特征提取很重要,在迁移到Unified Embedding之后,Events search的召回率提升了18%,Groups search的召回率则提升了16%。下图给出了一些特征添加后带来的提升情况:
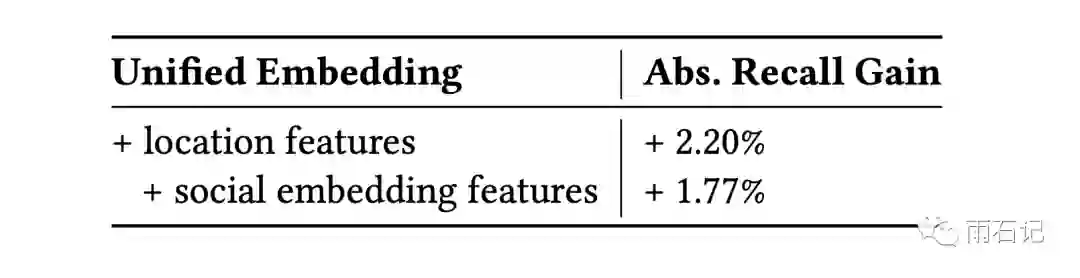
有三种特征比较重要:
-
文本特征: 采用Character n-gram特征,能够解决模糊匹配和可选文本的匹配。相对于word n-gram来说,更灵活,可以兼容OOV,且效果更好。 -
位置特征: 位置特征对本地的business、groups、events效果非常好。 -
社交特征: 构建了一个独立的模型可以基于社交网络为用户提取特征
ANN
ANN的相关知识我们在基于Delaunay图的快速最大内积搜索算法也进行过讲解。
当embedding训练好之后,需要对其进行部署,部署分为两步:
-
Embedding做量化 -
构建倒排索引
做量化主要有两种方式:
-
coarse quantization,使用K-means算法来将vector聚合成cluster -
product quantization,是细粒度的量化,可以快速计算embedding的距离。
Product quantization需要后续关注。
针对这两种方法,有三个重要参数需要调整:
-
coarse quantization算法的选择,主要在IMI和IVF之间做选择,另有num_cluster参数需要谨慎调整 -
product quantization算法的选择,包括vanilla PQ, OPQ, PQ with PCA。PQ算法的字节数是一个重要的参数。 -
nprobe,决定有多少簇可以赋给query embedding,从而决定有多少簇需要被扫描
调参的技巧:
-
调整Recall和扫描的文档数目,一般来说,扫描的文档越多,recall越大,如下图
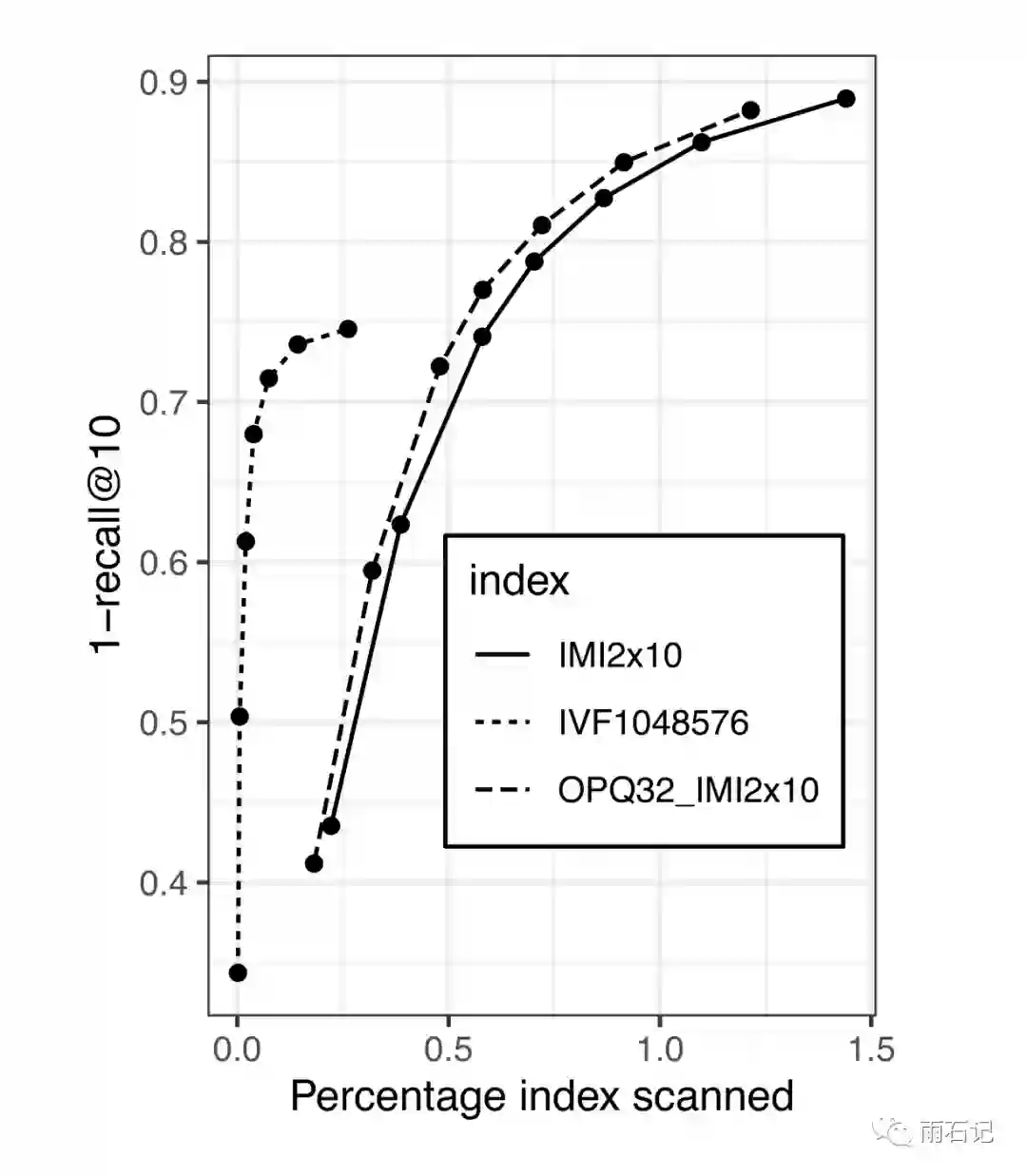
-
当模型有大的变化时,要调整ANN参数 -
一定要尝试OPQ,在做量化之前对数据做转化一般很有用。 -
选择让pq_bytes = d/4,从实验结果中看,pq_bytes > 4时提升有限。 -
在线调整nprobe,num_clusters, pq_bytes来理解真实的影响。
系统实现
没有embedding之前,facebook的搜索系统是一个名为Unicorn的引擎,Unicorn将每篇文章表示为bag of terms,其中term带有属性,比如用户John住在Seattle将会被表达成 text:jonh, location:Seattle。
query也会被转化为boolean表达式,例如,查询John smithe live in Seattle 或者Menlo Park会被表达成:

为了支持embedding,添加一个operator (nn

这样,就将embedding添加进入系统中来,使得系统同时支持term匹配和embedding匹配,同时还可以利用系统原有的实时更新,高效查询等特性。
关于Unicorn引擎,后续会进行介绍。
当模型训练好之后,模型会被分解为query embedding模型和document embedding模型,其中,query embedding模型会被部署到在线服务去做线上inference;document embedding模型会被Spark使用,离线计算所有document的embedding。
由于embedding也确实耗时的计算,所以在query和index的时候,会有所选择。在query端,对于那些明确的embedding没有提升的query,不去做embedding搜索,比如有明确意图的query,用户之前输过且有过点击的query等等。在index端,也会做选择来加速,比如只选择月活跃用户、最近的事件、流行的组和网页等。
后续阶段优化
Retrival层是整个架构最底层的模块,在它里面加了embedding后,要及时更新后续的ranking和filtering模块,如何更新后续的模块呢?提出了两种方法:
-
将Embedding作为ranking层的feature,比如将embedding之间的相似度score作为feature提供给ranking层 -
Training data feedback loop,构建一个流程来让human raters标注返回的结果中哪些是相关的,哪些不是。这个方法因为有人工的参与,对效果的提升非常明显。
Hard Mining
为了使模型训练的更强更好,Hard Mining还是需要做的,但Hard Mining之前的工作主要集中在图像分类问题上,对于Facebook这个排序的问题,即不是图像也没有类别,因此要另外想别的策略。
在论文中,分别对负样本和正样本做了Hard Mining。
在people search中,发现top K结果一般都是同一个名字的人,即使有些结果上已经有了社交信息,仍然不能排在前面,说明社交特征没有被正确的使用,究其原因,就可能是训练样本不够hard的锅。
提出了两种方法来做负样本的hard mining:
-
Online hard negative Mining -
Offline hard negative mining
其中,对于online来说,对于每个query,都会有一个小的样本池,除了正样本之外,其他的都是负样本,在负样本中找出分数最高的来作为hard example。有了这个之后,people search的召回增加8.38%,groups search 增加7%,event search增加5.33%。并且观测到,一个正样本找两个hard负样本效果最好。
online hard negative mining的缺点就是有可能样本池中没有足够hard的样本。这就需要扩大样本池去寻找样本,也就引出offline hard negative examples。
offline的方式可能避免online可能存在的不够hard的问题,但是为每一个样本去全局找hard negative examples会导致性能问题,因而会使用近似搜索,这样这个方法可能只能称作是半hard mining了。
在offline上只用hard样本去进行训练并不能直接达到好的结果。因为这样反而会在那些能用text match就能处理的easy样本上表现不好。所以,需要对样本的选取策略做一些改进:
-
第一个改进就是不使用最hard的样本,经过试验,发现rank在101-500的hard样本用起来最好。 -
第二个改进则是不全用hard样本,这里有两个策略: -
hard样本和easy样本1:100混合起来。 -
从hard模型迁移学习到easy模型,从hard到easy的迁移效果较好,反之效果不好。
对于正样本的hard Mining来说,需要识别还没有被检索过但是是正例的新样本。这个是在用户的失败搜索会话中找到,但具体怎么找的,论文并没有提及。
Embedding Ensemble
使用不同难度的样本得到的模型性能是不同的,比如使用随机负样本训练得到的模型在top-K的K比较大的时候表现比较好,而使用hard样本得到的模型在K比较小的时候表现较好,那么有没有可能将这些不同的模型组合起来达到更好的效果呢?论文提出了两种方法:
-
加权拼接: query和文档都表达为多个模型给出的embedding的拼接,计算相似度时则进行加权。
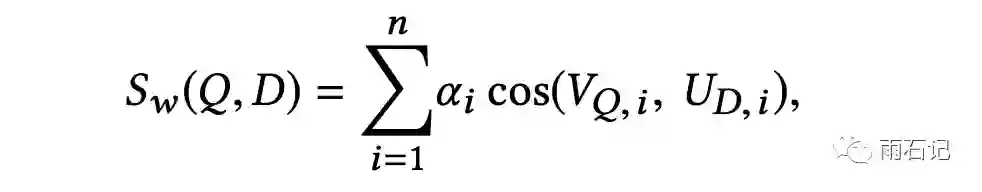
-
级联模型: 先用随机负样本得到的模型初选,然后再用hard样本得到的模型去精选。这个方式不如上一种,在第二阶段K较大的时候,效果会下降。 -
级联模型: 另一种应用级联的方式是使用text match的方式做初选,然后用unified embedding做精选。这种方式在实验中最好。
后续探索
有两个方向可以探索
-
更深: 使用更深的模型比如Bert去做unified embedding -
更广: 得到更通用的unified embedding的方式,使之应用在各种任务上。
总结与思考
本文是Facebook在search上做的比较初步的Embedding化的工作,作为一个社交网络,Search很重要但并非最重要,所以Facebook在这方面起步稍晚,论文的深度相对于之前解说的其他公司的架构显得略浅,比如ANN没有利用GPU,quantization不是直接DL训练等等。
而Search之于Facebook的地位,其实跟Search相对于抖音、快手等等的地位类似,所以在这些app中,这样做去提升Search的quality也是可以做的。但因为抖音快手等是有图像或者视频信息的,所以Unified embedding的信息会大大增加,多模态会是一个未来的发展方向。
回到论文本身,Triplet Loss从出现开始就和Hard Mining相爱相杀,论文提出的几种技巧在文本领域应该算得上很实用了。
码字不易,求关注,点赞,在看,分享四连发。
参考文献
-
[1]. Huang, Jui-Ting, et al. "Embedding-based Retrieval in Facebook Search." Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2020.
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏