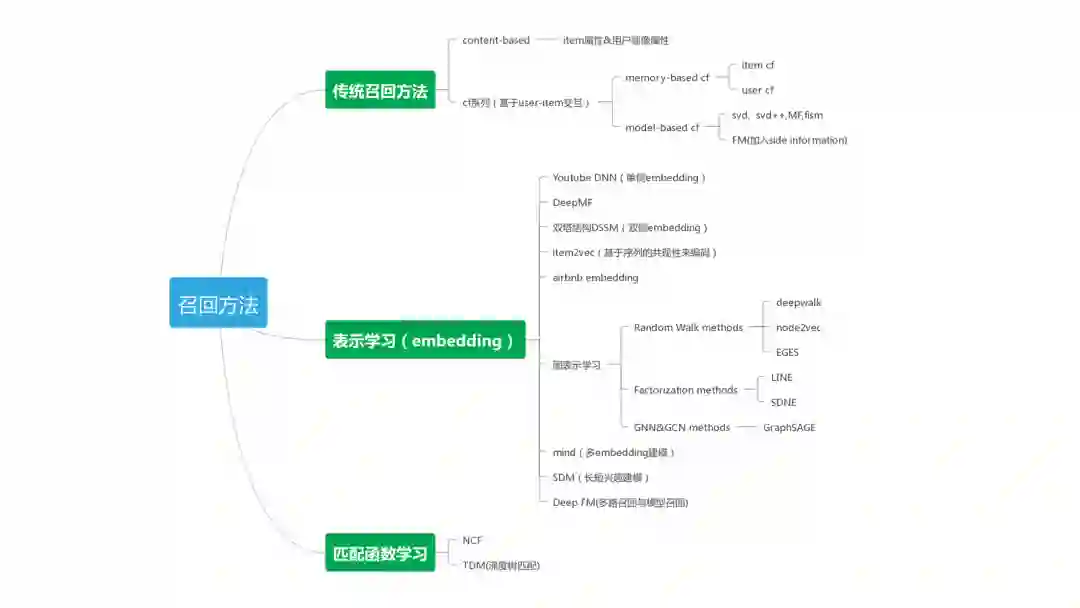
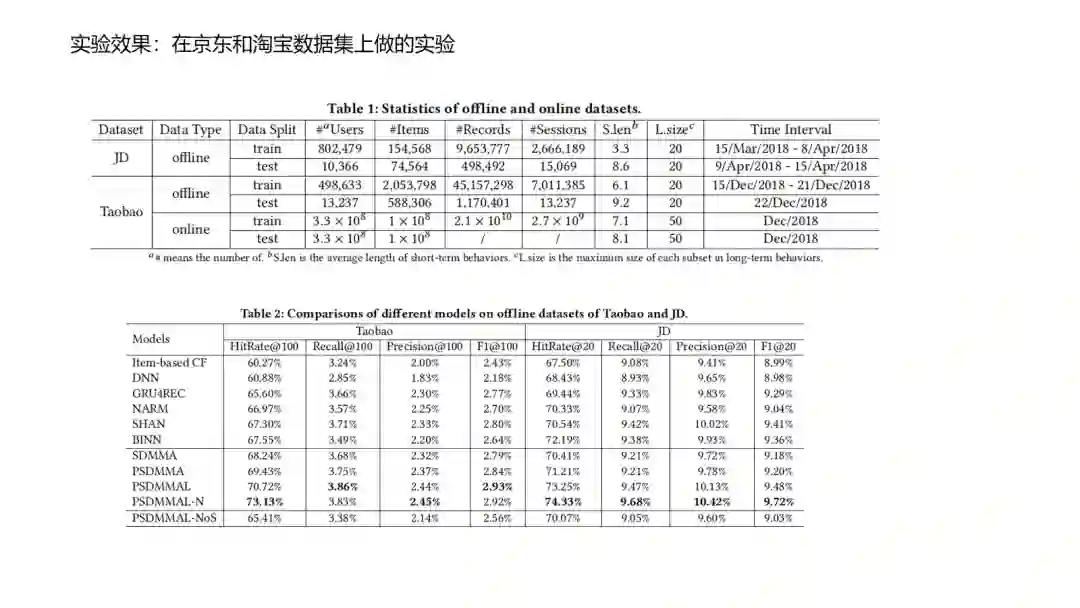
“ 本文主要梳理了近年来推荐系统中的主流召回方法,包括传统召回方法,基于表示学习的方法(Youtube DNN,DMF,DSSM,item2vec,graph embedding,MIND,SDM等),以及基于匹配函数学习的方法(TDM,NCF等),非常适合大家学习! ”
作者: 陈小白1037,华中科技大学人工智能学院在读硕士,先后在小米和腾讯实习推荐相关方向工作,推荐系统新兵成长中。
前言: 本文是我在实习期间针对当前业界的主流召回方式所做的一个综述, 由于本人水平有限, 希望各位大佬在评论区多多拍砖指正, 也希望有机会和各位老师交流学习, 这是我的微信号zyws_2020.
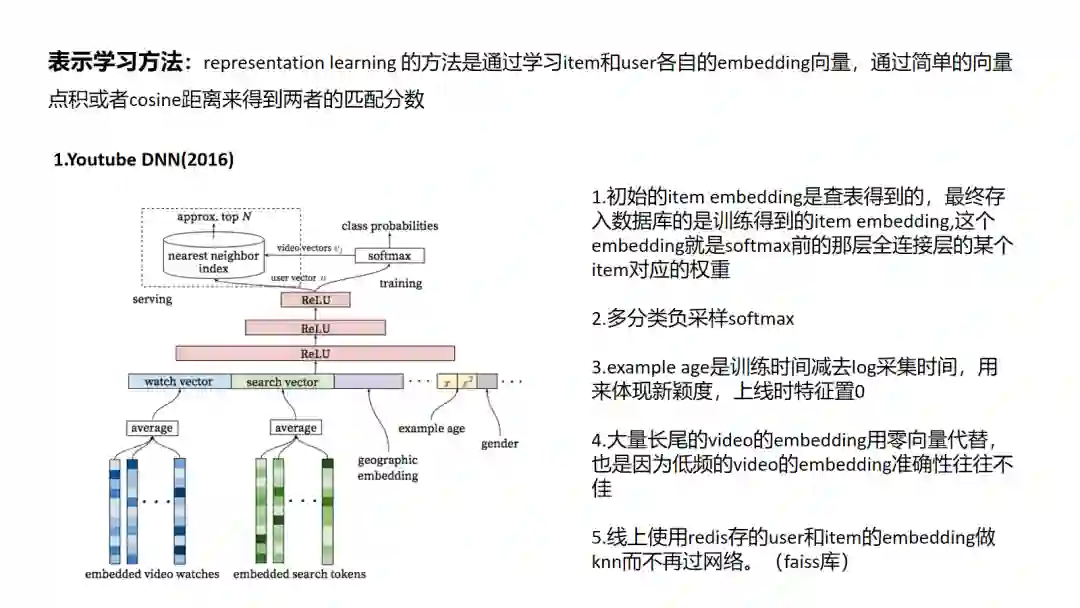
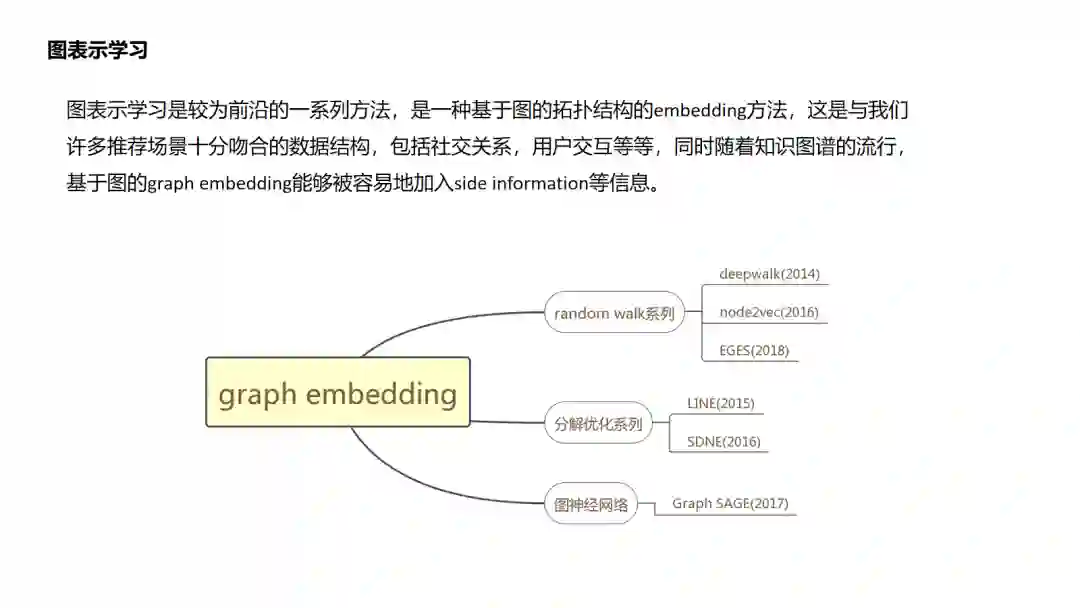
1 Youtube DNN
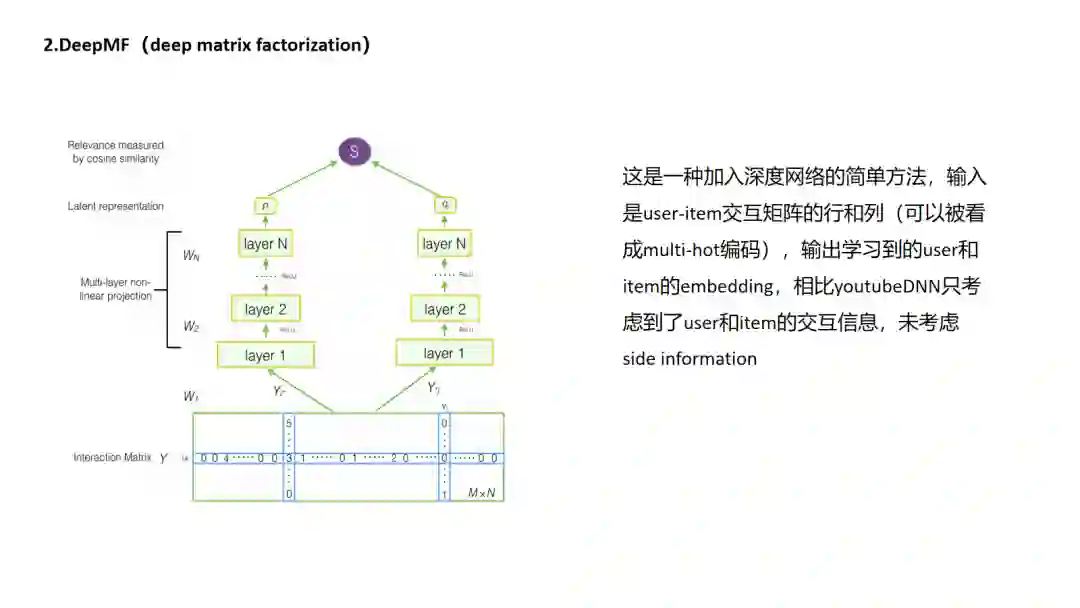
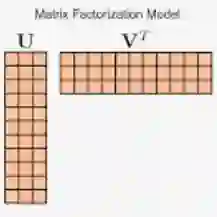
2 DeepMF
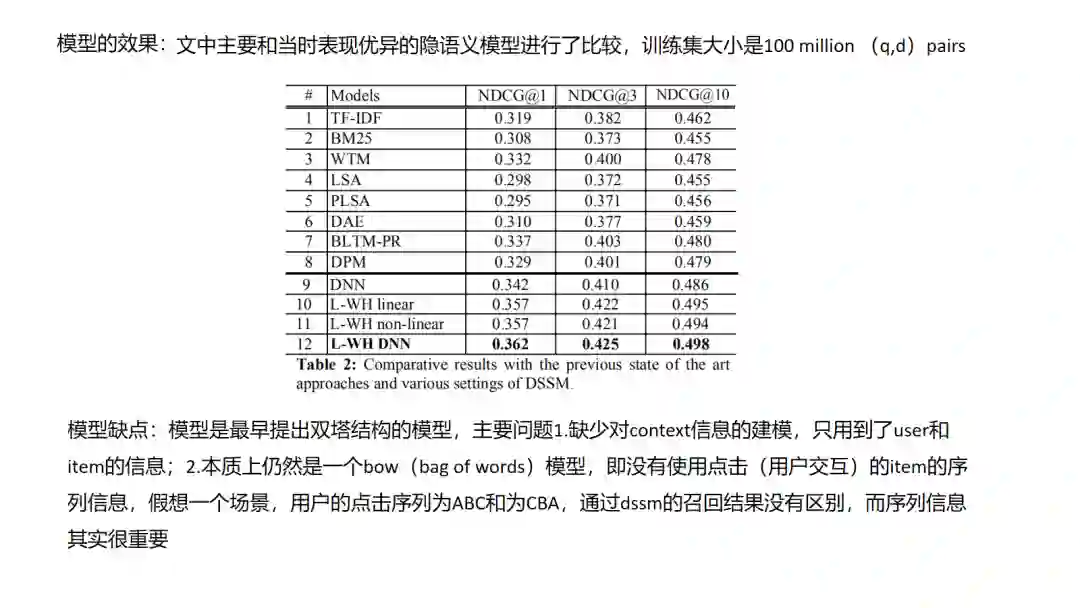
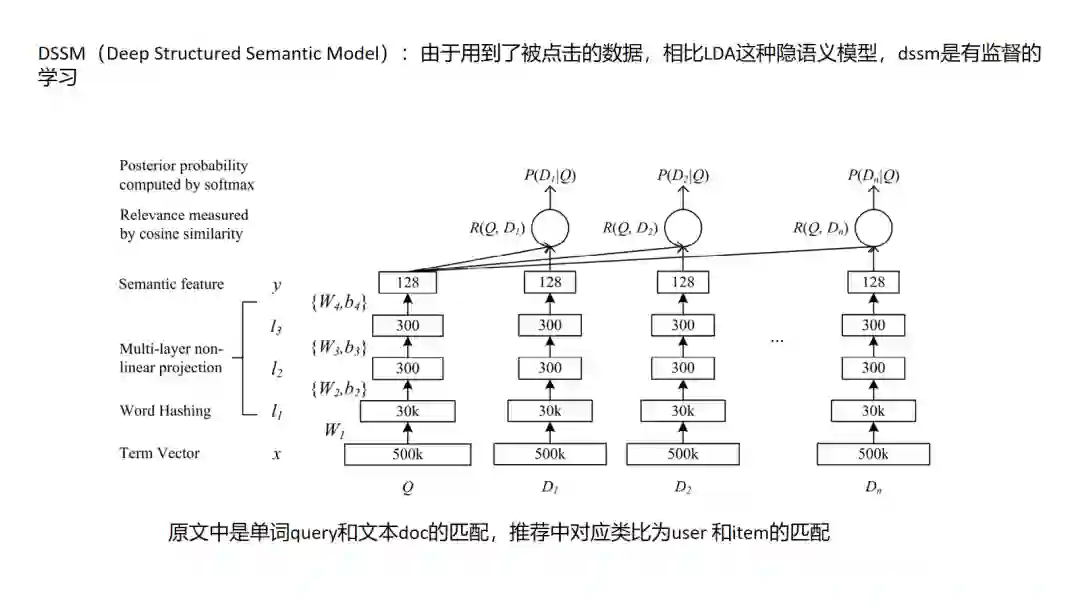
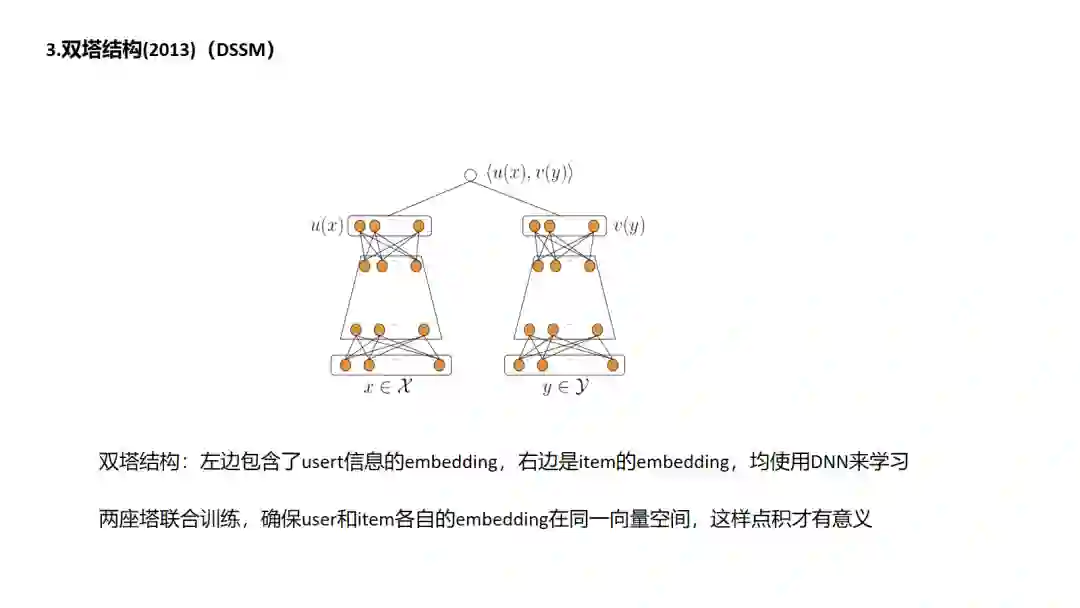
3. DSSM
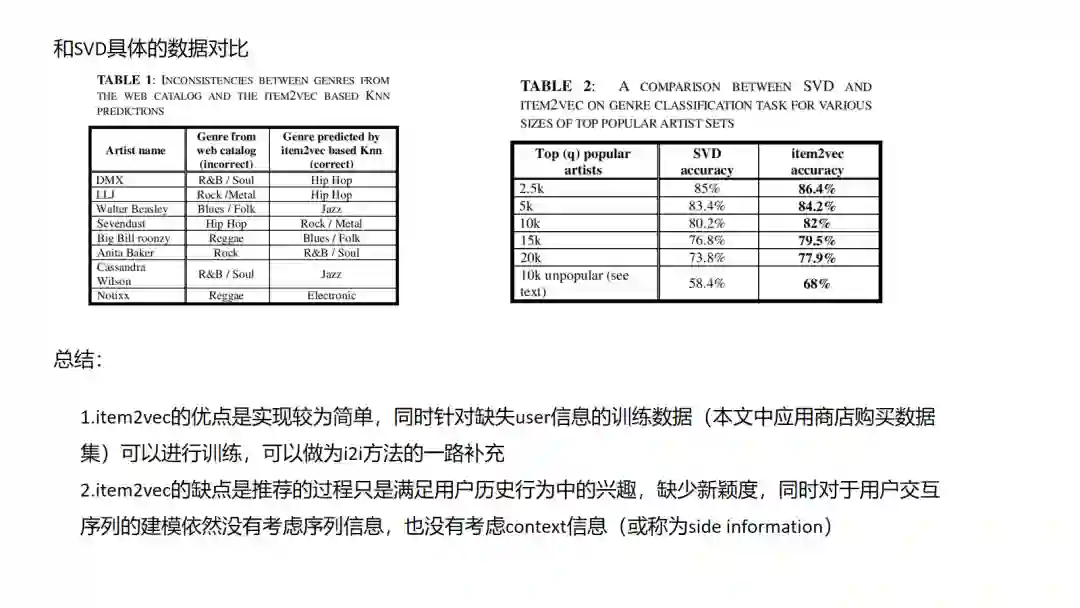
4.Item2vec
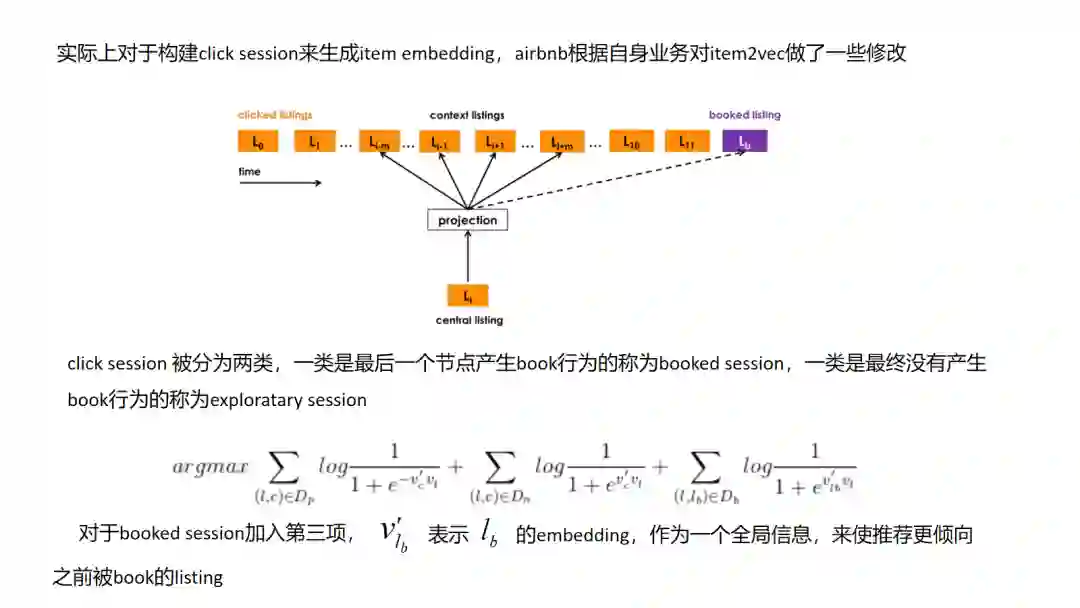
5.Airbnb Embedding
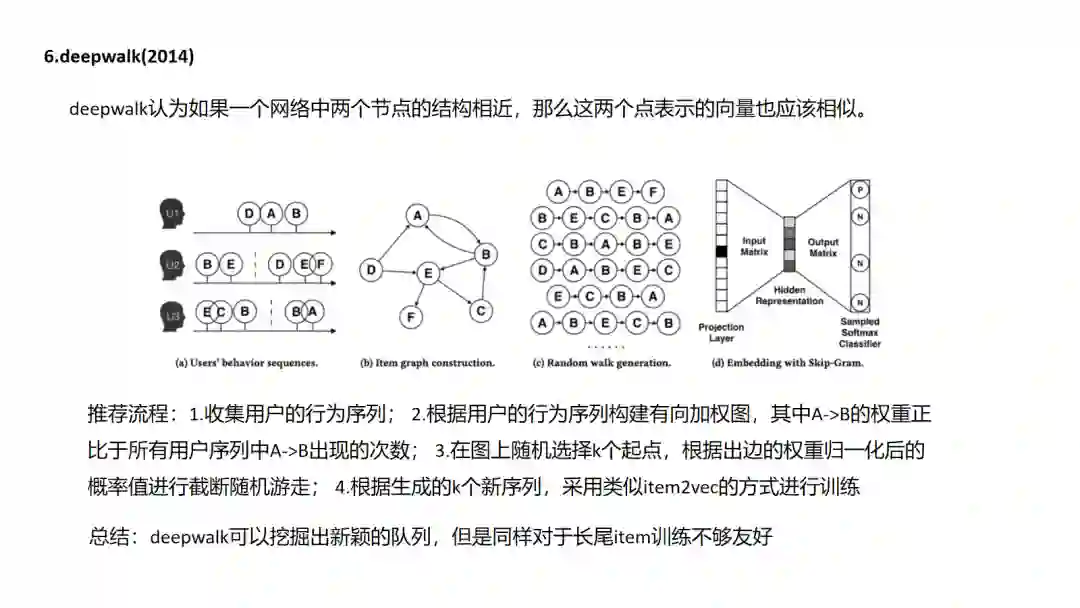
6.DeepWalk
幻灯片22
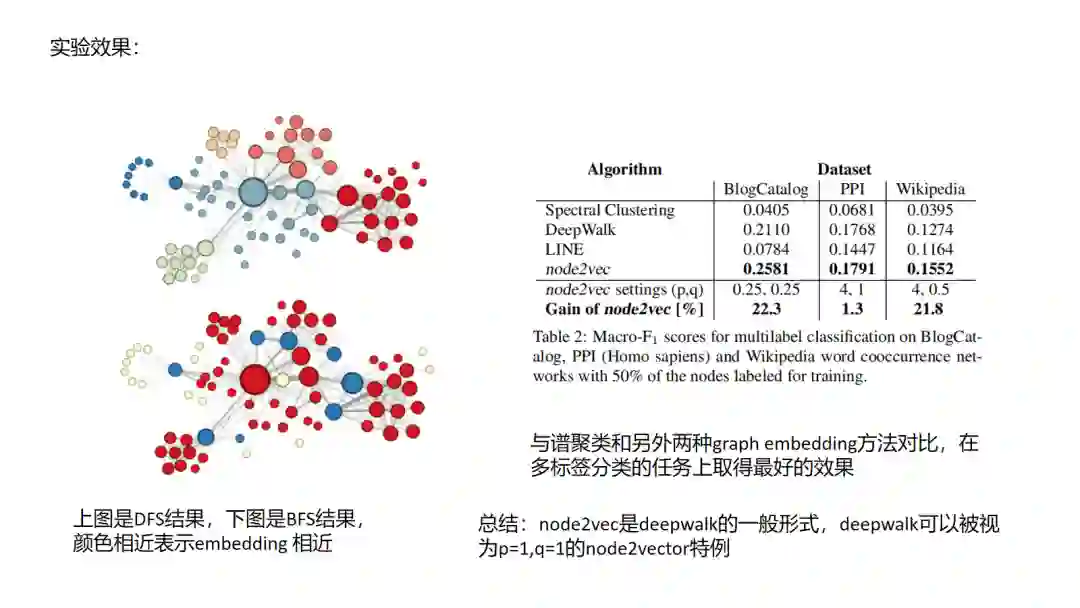
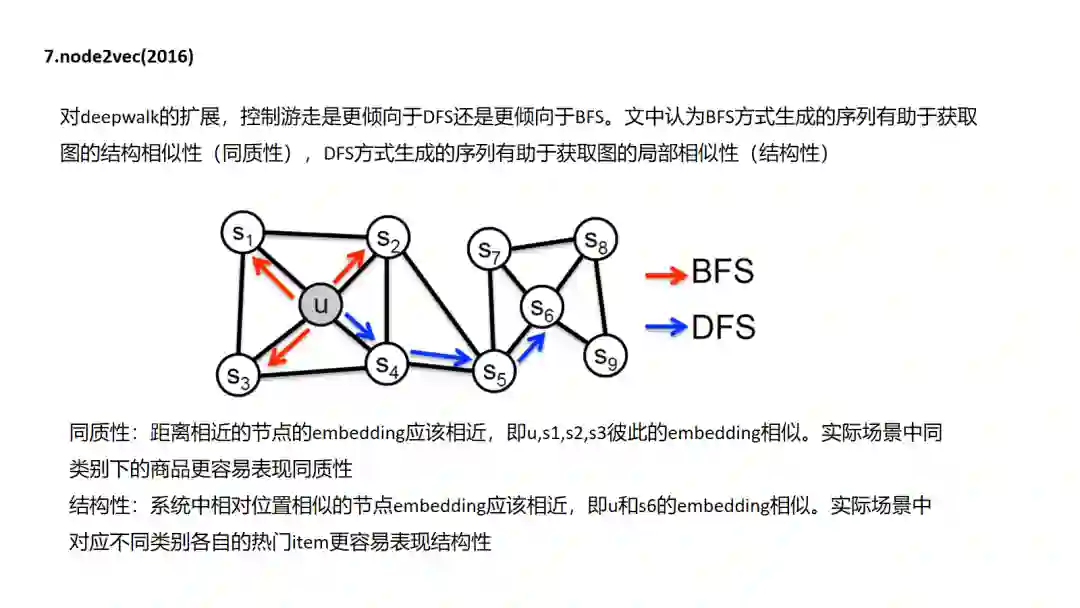
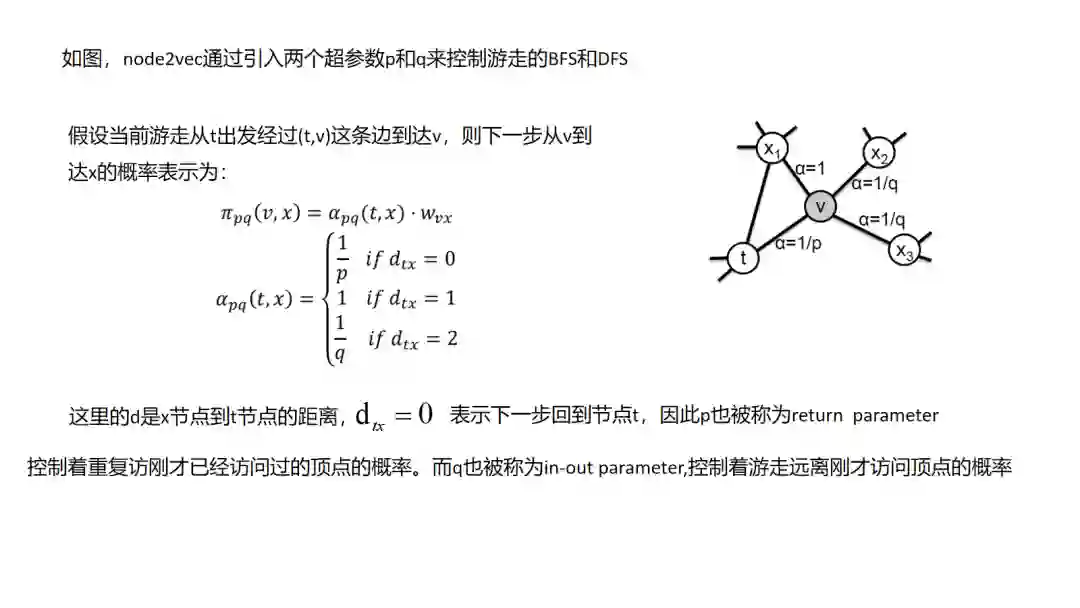
7.Node2Vec
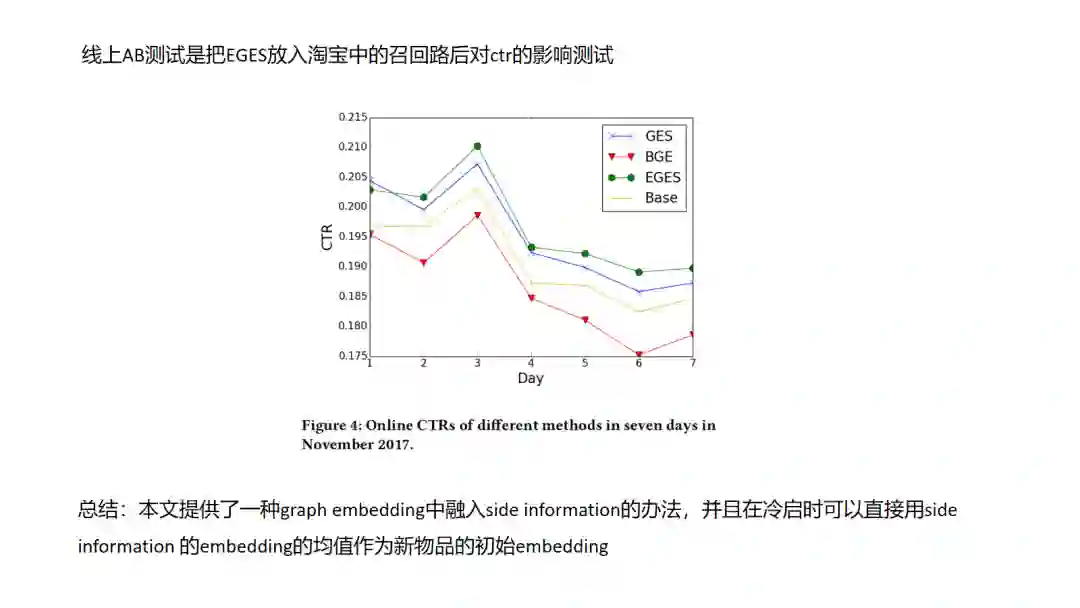
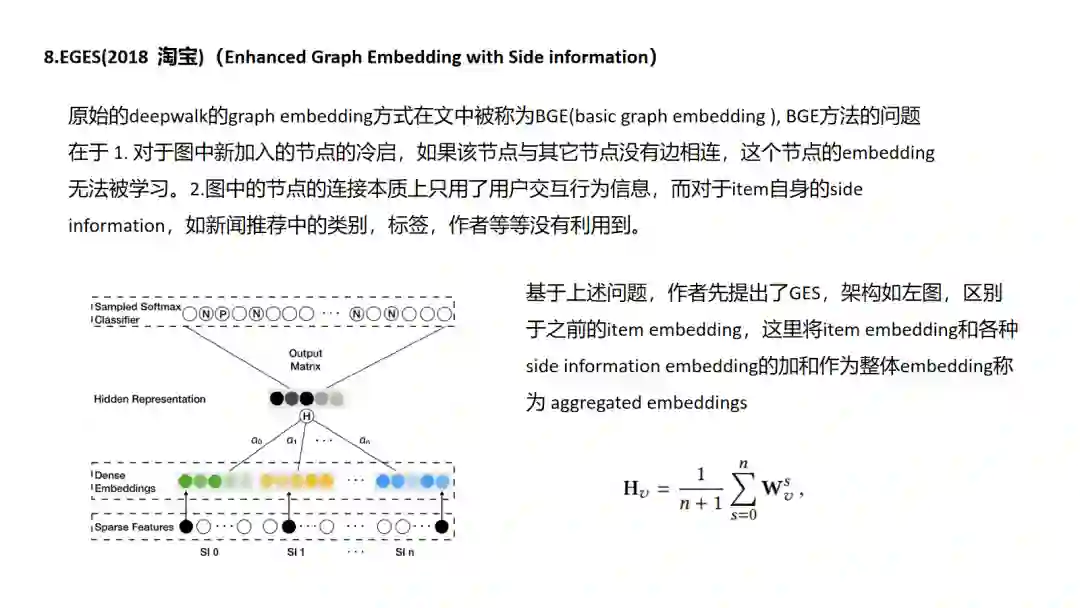
8.EGES
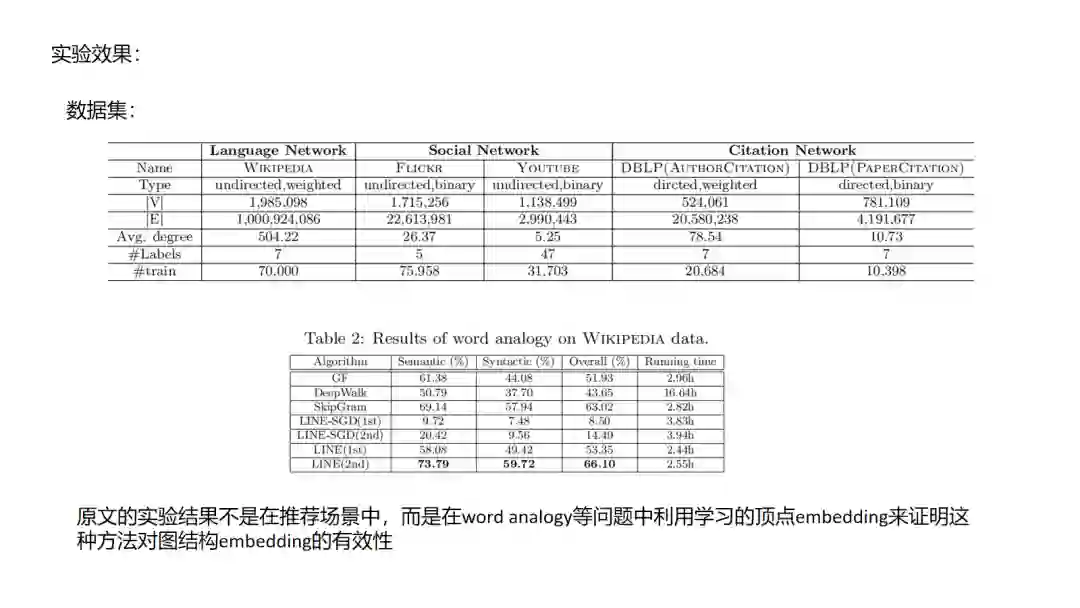
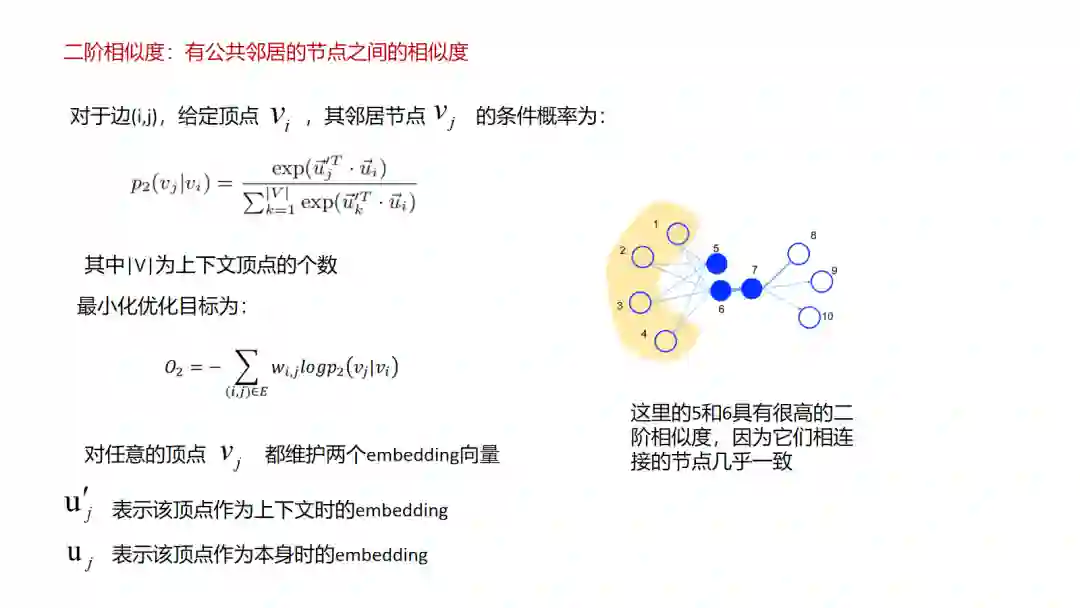
9.LINE
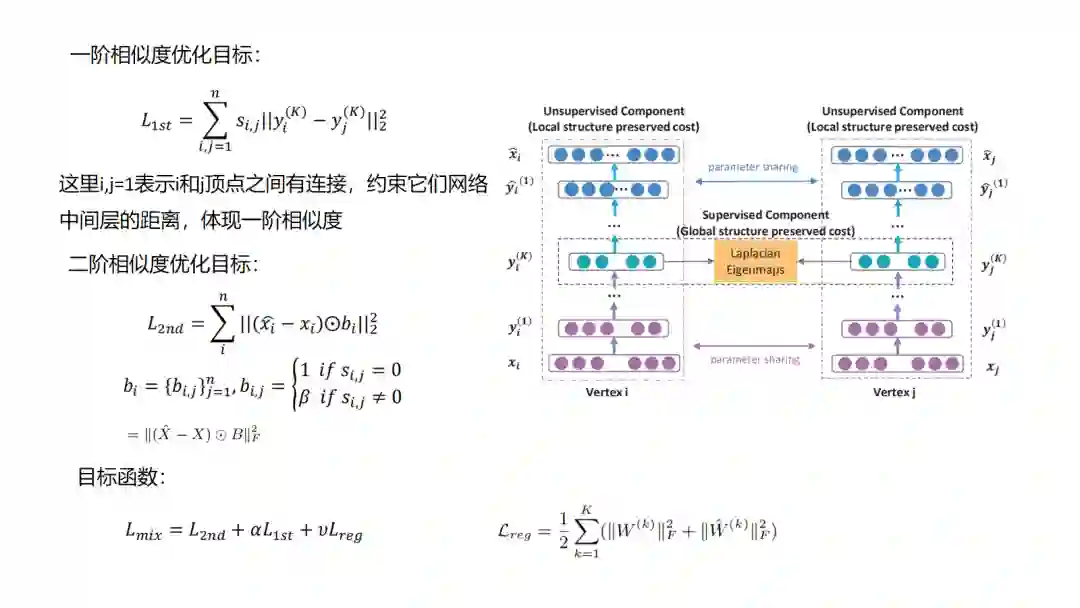
10.SDNE
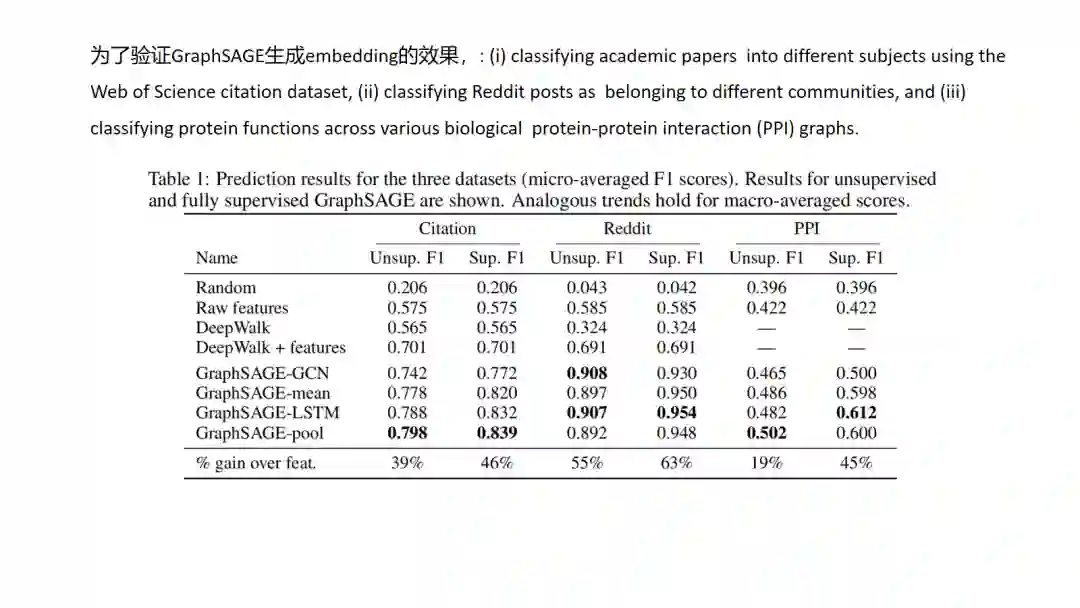
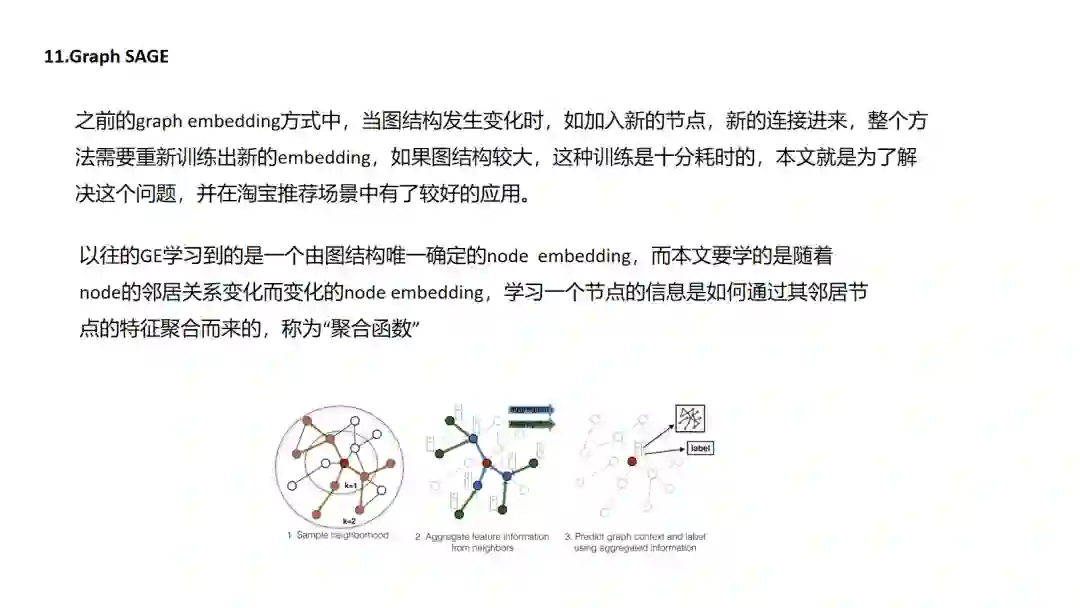
11.GraphSAGE
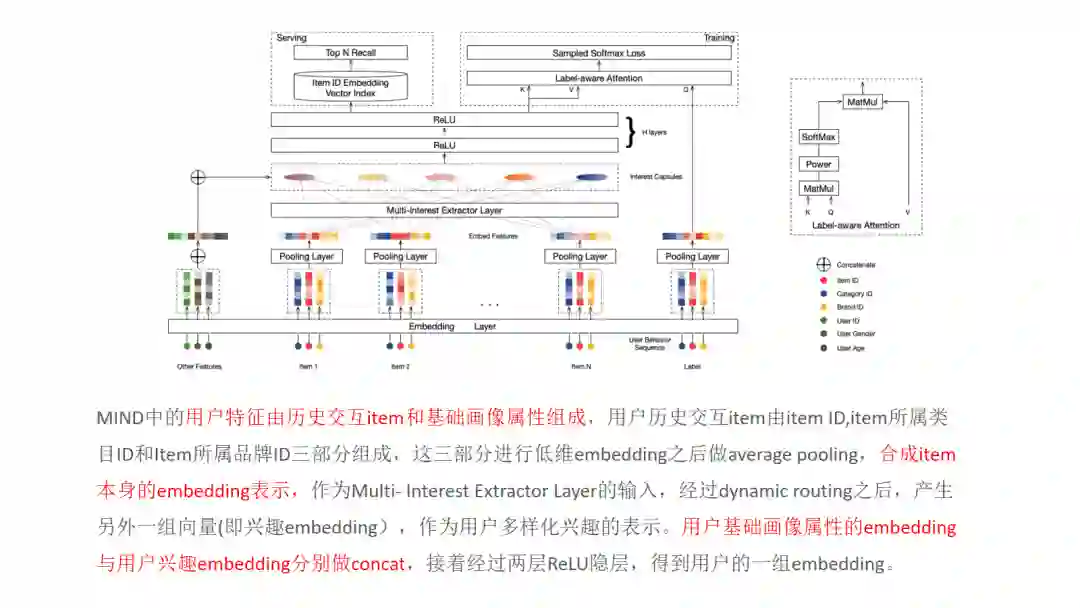
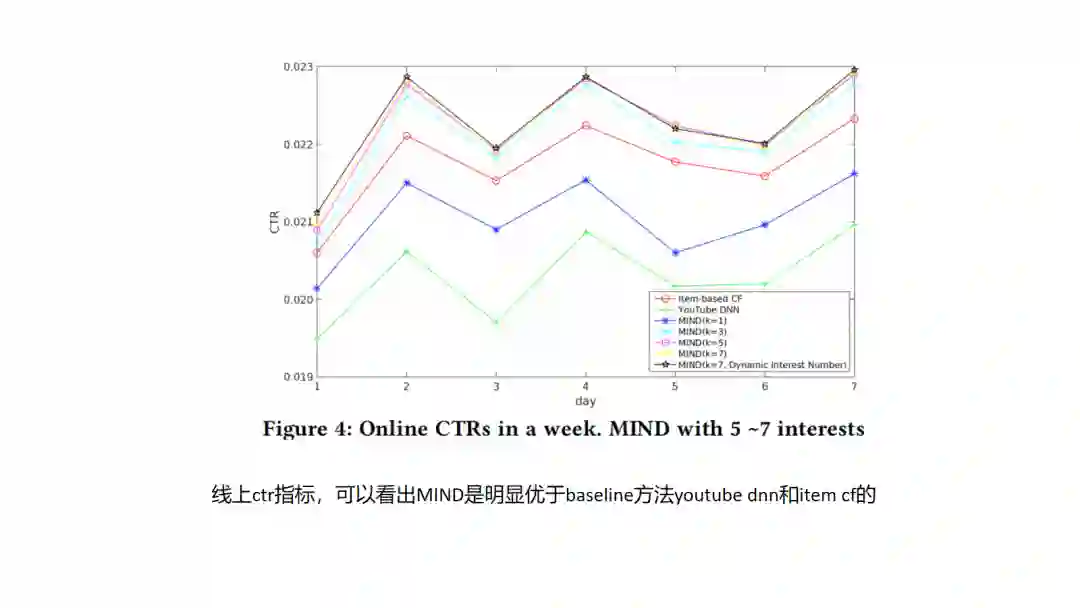
12.MIND
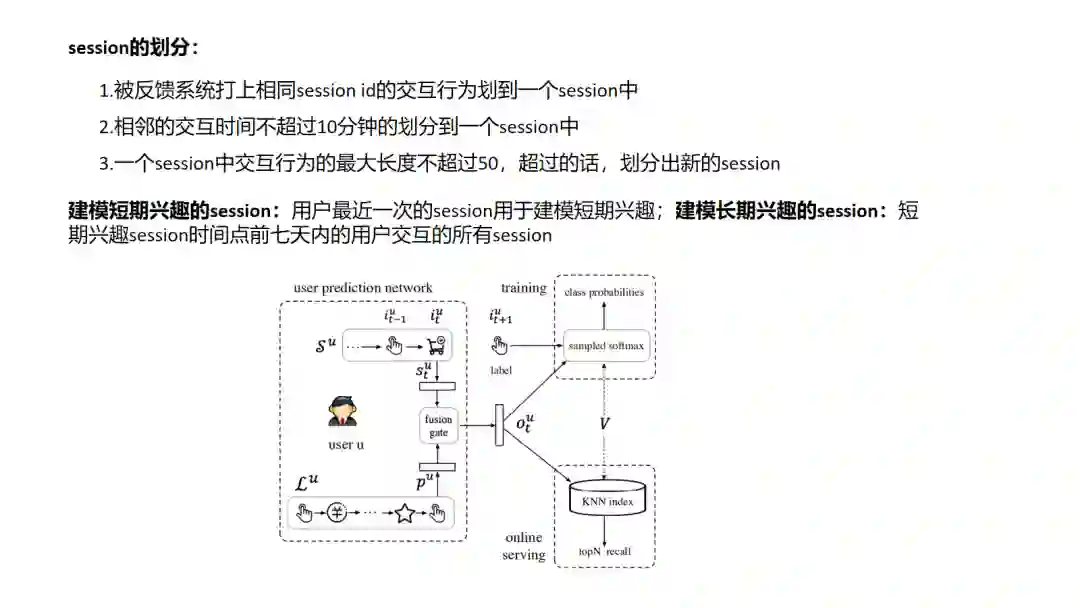
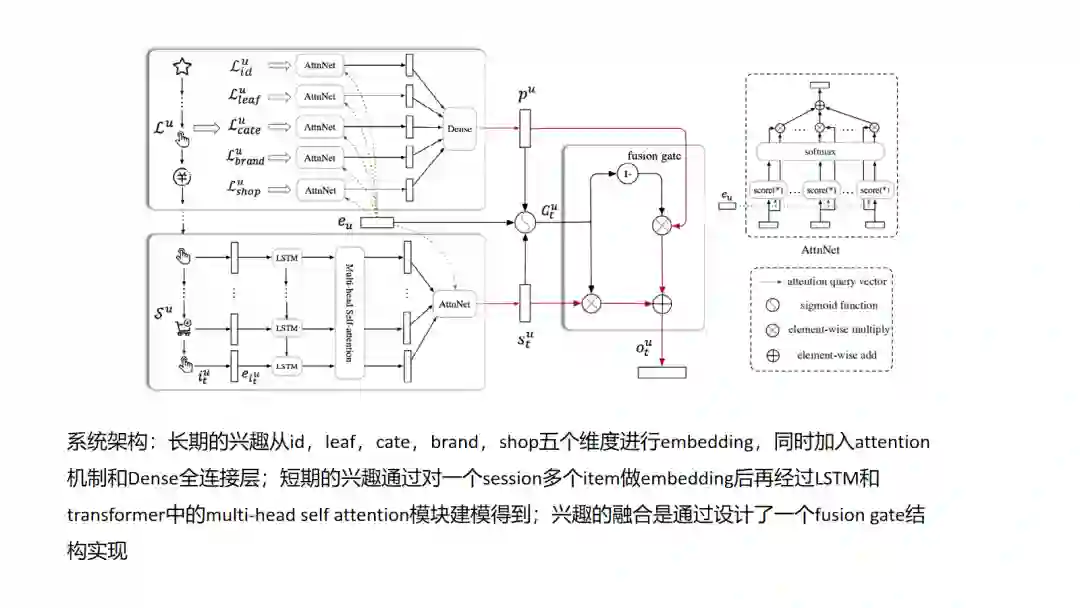
13.SDM
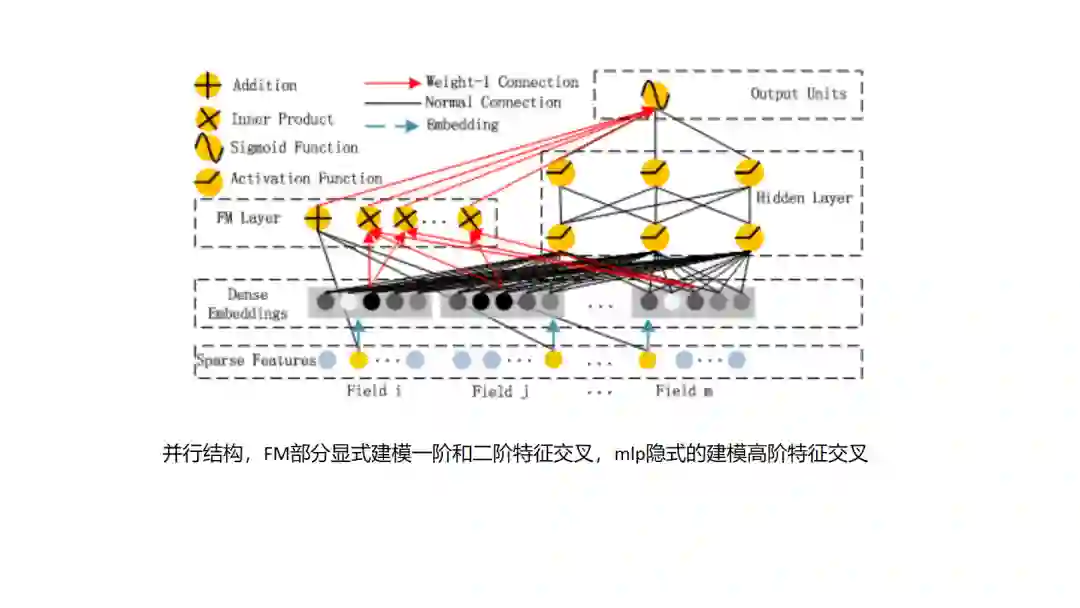
14.DeepFM
15.NCF
16.TDM
结语: 感谢浅梦学长提供这样一个平台可以和大家分享自己的调研, 自己目前还是个行业新兵,希望能和大家多多交流学习,欢迎大家加入浅梦的deepctr和deepmatch社区,一起愉快地学习和玩耍.
推荐阅读
这个NLP工具,玩得根本停不下来
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
从数据到模型,你可能需要1篇详实的pytorch踩坑指南
如何让Bert在finetune小数据集时更“稳”一点
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
Node2Vec 论文+代码笔记
模型压缩实践收尾篇——模型蒸馏以及其他一些技巧实践小结
中文命名实体识别工具(NER)哪家强?
学自然语言处理,其实更应该学好英语
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。
阅读至此了,分享、点赞、在看三选一吧🙏