NeurIPS 2021 | AP-10K:学界最大动物姿态估计数据集问世,更多数量、更多种类、更多任务

极市导读
最近,京东探索研究院联合西安电子科技大学、悉尼大学提出了AP-10K[1]:第一个大规模的哺乳动物姿态数据集。AP-10K中包含大约1万张标记有姿态信息的哺乳动物图片,这些图片从生物学的角度,又被归纳为23科,54个物种。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

AP-10K数据集下载地址为:https://github.com/AlexTheBad/AP-10K
论文链接:https://openreview.net/forum?id=rH8yliN6C83
准确的动物姿态估计是理解动物行为的关键,它为诸如野生动物保护之类的许多下游任务创造了基础。先前的工作只包含了有限的动物种类,忽略了动物的多样性,这限制了神经网络的泛化能力。最近,京东探索研究院联合西安电子科技大学、悉尼大学提出了AP-10K[1]:第一个大规模的哺乳动物姿态数据集。AP-10K中包含大约1万张标记有姿态信息的哺乳动物图片,这些图片从生物学的角度,又被归纳为23科,54个物种。我们在该数据集的基础上研究了动物姿态估计问题,研究的问题包括:有监督学习下的动物姿态估计;人体姿态估计和动物姿态估计模型的迁移性能;属于同科的物种和不同科之间的物种与泛化性能的关系等。这些实验有力地证明了动物多样性对有监督姿态估计问题带来的准确率和泛化能力的提升。AP-10K数据集为动物姿态估计的未来研究开辟了新的方向。目前AP-10K数据集已经集成到mmpose框架。
01 研究背景
姿态估计问题是一个很有应用前景的领域[2],它的目的是在识别目标的基础上标记出一系列具有语义信息的关键点。先前的工作主要关注的都是人体姿态估计问题,自2014年以来,已经有一系列人体姿态估计算法得到发表,人体姿态估计的性能也在不断提升,典型的人体姿态估计模型有Hourglass,SimpleBaseline和HRNet。然而除了人体之外,自然界中还有丰富的动物类别,姿态估计算法对于动物姿态的识别效果如何?人体姿态估计的神经网络模型能在多大程度上迁移到动物姿态估计领域?目前对这些问题的研究还比较少。现有的研究创建了一些小规模的动物数据集,Horse-10和ATRW分别收集了基于马和老虎的图片数据,Animal Pose Dataset提出了一个包含5类动物(猫、狗、牛、羊、马)的数据集。然而动物姿态估计的一个重要的问题在于:目前还不存在一个规模较大,动物种类丰富的数据集能够用来作为基准,来验证姿态估计算法的性能和泛化能力。
为不同种类的动物标记姿态不仅需要大量的人力工作,还需要生物学相关的领域知识作为标记依据。丰富的动物种类带来的外貌和骨骼的差异性,使得标记动物的过程也会存在误差。AP-10K数据集为解决上述问题迈出了建设性的一步。在AP-10K数据集中,我们类比人体关键点,同时考虑到不同动物的骨骼差异性,定义了17个关键点来描述不同种类的哺乳动物。这些关键点从动物的骨骼位置和运动特点角度作了权衡,最大程度上描述了这些动物的外形和运动特点。为了促进泛化性能的研究,我们将所有动物按照科和物种的生物学概念整理为了一个23科,54物种的集合。我们的实验初步证明了,姿态估计模型对于生物学关系相近,外形相近的物种具有较好的泛化性能。下图展示了AP-10K的部分标记案例(图1)。

02 数据集的构建和特点
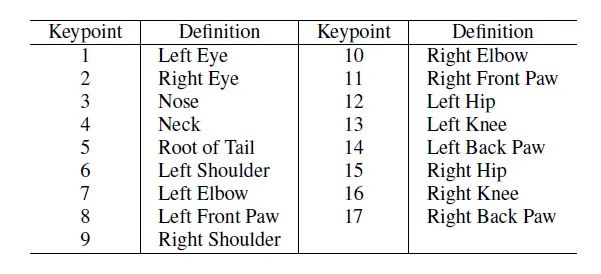
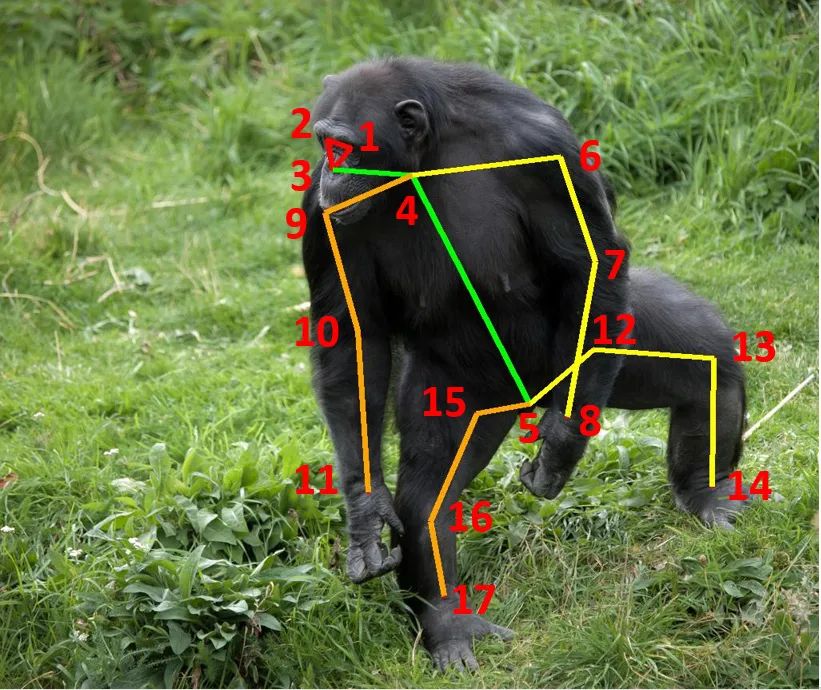
互联网上已经存在了一些公开发布的动物图片数据集,这些数据集中的大部分用于图像分类任务,充分利用这些数据集不失为一个较好的方法。我们以9个公开发布的动物数据集作为基础,经过仔细清洗、鉴别、再组织和标记,构建了一个包含59658张图片的动物数据集,在这里不同的动物按照科和物种的生物学概念进行了最大程度的划分,物种之间的生物学关系得到了更进一步的体现。在此基础上,我们经过仔细分析和挑选,本着“每个物种选取200张作为基础,稀有物种充分标记”的原则,对其中50类动物进行标记,最终得到了10015张包含姿态信息的图片。下面展示了17个关键点的定义(表1)和一幅黑猩猩图片及其对应的标记(图2)。
为了获得高质量的标记效果。我们招募了13名志愿者进行标记工作。我们首先对他们开展了动物标记概念的讲解工作,其中特别强调了不同动物的外形特点对标记带来的影响。然后我们又撰写了详尽的文档对于标记者可能遇到的标记状况进行了详细的解说,其中包括对于多个体、遮挡情况等情形的处理情况等。这些举措保证了多个体、遮挡等有难度的少见样本的准确标记效果,相关研究文章[3]已经证明了有难度的少见样本对于姿态估计模型性能的重要性。
为了更进一步保证标注信息的质量,我们采取了自动化和人工两种校验手段。其中自动化校验是指用代码对于标记好的坐标信息进行检查,去除一些低质量标记和错误标记。例如标记点落在检测框外侧,同一个实例出现重复的标记名称等。人工校验是指组织者和标记者进行了三轮检查,这确保了高质量的标注信息。三轮检查过程如下:首先,标记者在分配的标记工作完成后,将标记结果提交组织者进行检查,组织者将检查出的错误信息反馈给标记者,这是一轮检查;标记者根据反馈的勘误表对标记进行修改,并将二次修改结果反馈给组织者,这是二轮检查;最后组织者拿到二次标记结果,对于标记进行最后的检查,如果发现错误就进行本地修改,这是三轮检查。经过上述三轮检查,一批高质量的动物标注图片就完成了。三轮检查的过程如同TCP协议的三次握手一般,确保了标注过程的可靠性。
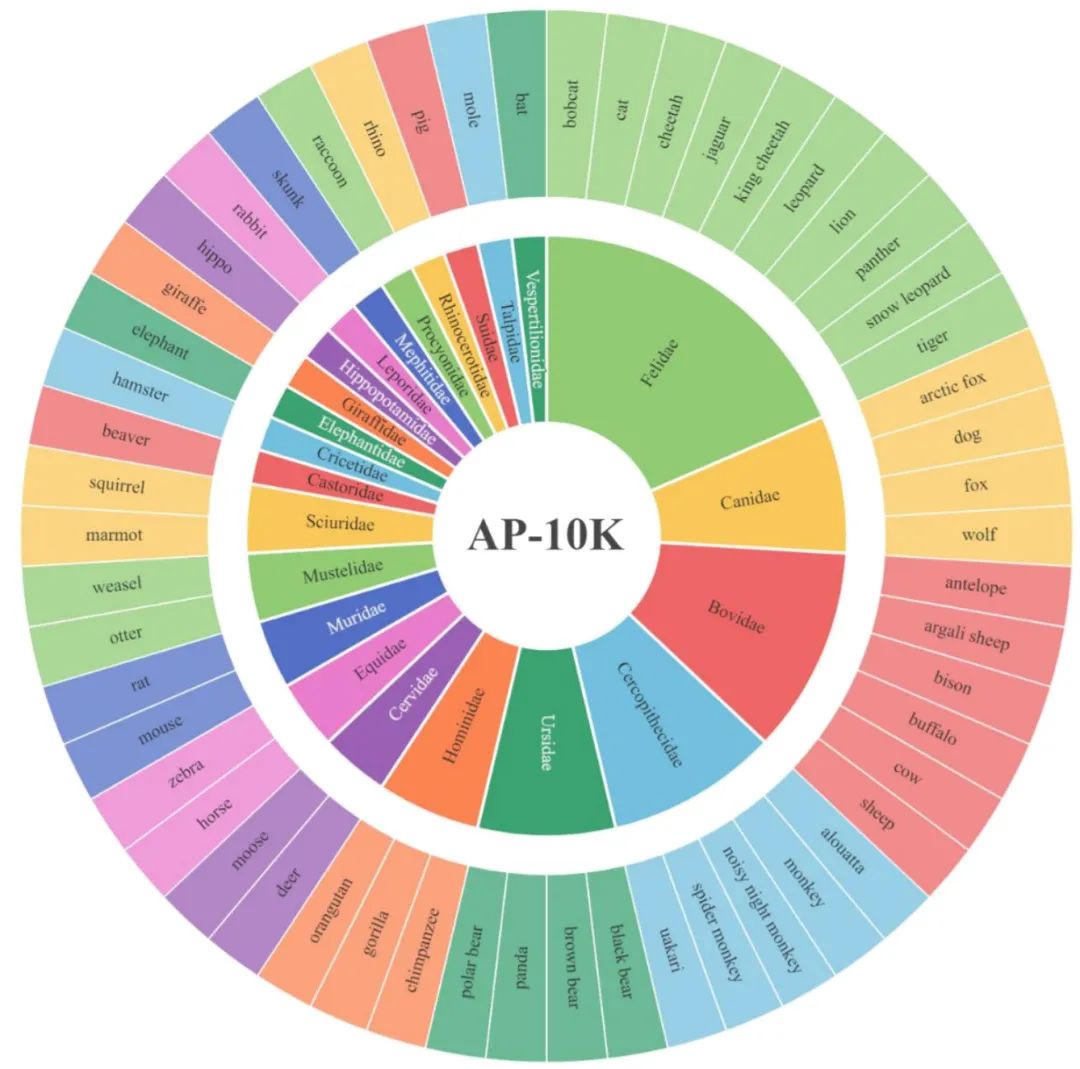
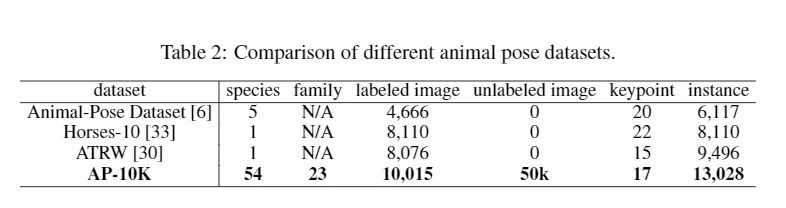
下图展示了AP-10K数据集的特点(表2)和动物种类分布(图3)。由图中可以看出,AP-10K数据集不论是在动物种类还是在标记数量均具有显著优势。值得一提的,AP-10K数据集的标记图片具有长尾分布的特点,比如对于猫科(Felidae)来说,一共有10个标记物种,1913张标记图片。而河狸科只包含1个物种,178张标记图片。这些特性对于小样本学习、零样本学习或者元学习等研究方向是很有意义的。
03 实验结果
1. 有监督学习下的动物姿态估计
我们以每种动物为单位,对标记图片按照7:1:2的比例将其随机划分为训练集、验证集和测试集,将这样的过程重复三次,这样我们就得到了三个训练用的有监督学习数据集。我们测试了五种主流的姿态估计模型,它们分别是HRNet-w32[4],HRNet-w48[4],SimpleBaseline(ResNet50骨干网络)[5],SimpleBaseline(ResNet101骨干网络)[5]和Hourglass[6],然后又对比了使用流行的ImageNet预训练模型和随机初始化网络进行训练的效果。实验结果(mAP)表明:使用ImageNet预训练比随机初始化的效果要更好,ImageNet预训练能够提升上述5种模型的性能。随着网络规模的增大,HRNet和SimpleBaseline的训练指标也逐渐提升,这是因为大网络具有更好的表征能力。

除此之外,我们还探究了增加训练的epoch会带来怎样的效果。我们设置了210,420和630的训练epoch,对比了使用ImageNet预训练和随机初始化网络的训练效果。实验结果表明:在开始阶段,使用预训练模型能够提供一个更优的结果,我们认为这是因为使用预训练模型能够提供一个较好的初始解。而随着训练时间的增加,随机化初始化的训练效果也逐渐逼近使用预训练模型的效果,这说明给予足够的训练时间,模型也能够收敛一个更好的解。

2. 人体姿态估计模型的迁移效果
因为人和四足动物在身体结构上的相似性,于是我们猜想:一个基于人体姿态估计的预训练模型可能会对大规模动物姿态数据集的训练效果起到促进作用,因此我们使用HRNet-w32模型,加载基于COCO的人体姿态预训练模型,然后在AP-10K数据集上进行微调并测试。实验结果(mAP)表明当训练epoch较少时,训练结果不够好,这是因为动物和人在外形和纹理上有较大的差异性。随着训练时间的增加,微调的效果也逐渐增加,并显著优于采用ImageNet预训练模型进行训练的结果。该结果证明了上述猜想并支持了以下结论:人体姿态估计和动物姿态估计任务之间域间隔(Domain Gap)相比姿态估计任务和图像分类任务之间域间隔更小。
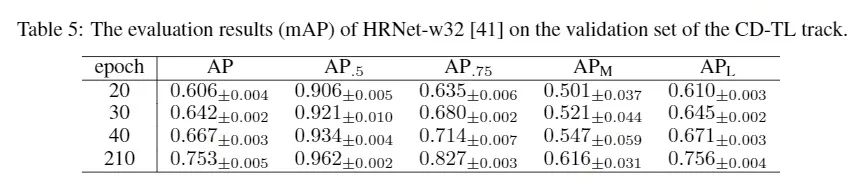
3. 模型在科内物种和科间物种的泛化性能研究
3.1 科内物种实验和科间物种实验
在科内实验中,我们选取了三个数量最多的科(牛科,狗科和猫科)进行实验。在每科中,我们选取一个物种用作测试集而剩下的物种构成训练集。在科间实验中我们采用牛科作为训练集,采用鹿科、马科和猴科作为测试集。上述两种实验设定中我们均使用HRNet-w32加载ImageNet预训练网络并保证了足够的训练代数。
科内实验结果(mAP)表明,在三个不同科中,测试物种的分数虽然不如在第一部分中使用大量物种进行训练的效果好,但是也能达到一个不错的结果。这是因为同科的物种在生物学关系和外形上具有高度的相似性。实验结果中狗(Dog)的分数偏低,首先是因为相比狐狸(Fox)和狼(Wolf),狗(Dog)包含了更多的图片。其次,狗(Dog)中包含了许多人工培育的宠物类型,它们的外形差异较大,类似的现象也存在于猫(Cat)中。我们针对狗科和猫科进行了更为细致的科内物种泛化性实验,相关结果可以参考论文补充材料中的实验结果[1]。

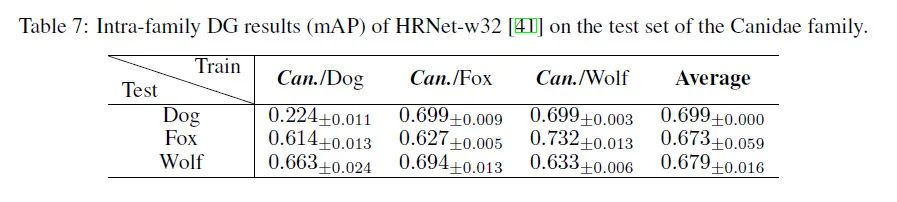
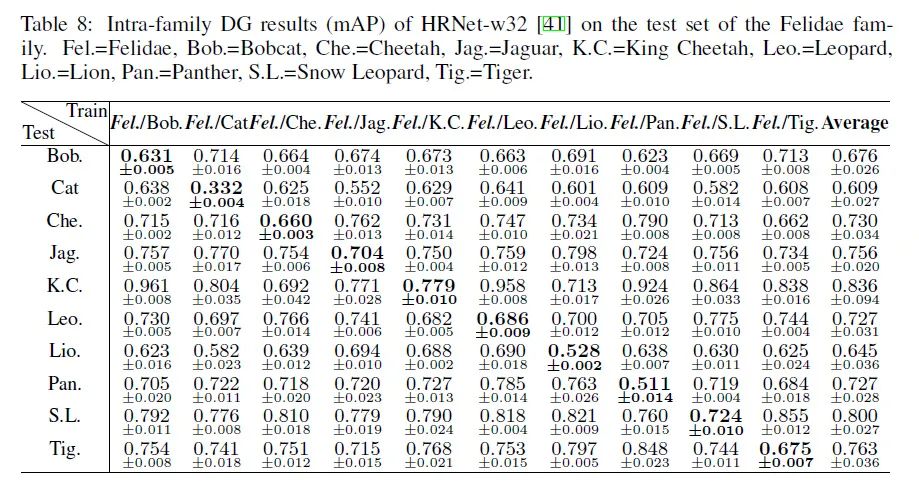
科间实验表明,使用牛科作为训练集的模型在鹿科和马科的泛化结果很好,但是在人科上泛化效果较差。因为牛科和鹿科、马科的生物学关系相近,外形差异也较小。而人科物种和牛科的生物学关系较远,外形和生存环境也差异较大,所以泛化效果不好。作为对照,表格最后一列使用了猴科作为训练集来测试人科的物种,性能得到了大幅提升,这再次证明了我们的观点:生物学关系和外形相似的物种,彼此之间的域差异也越小,这更利于姿态估计模型的泛化。
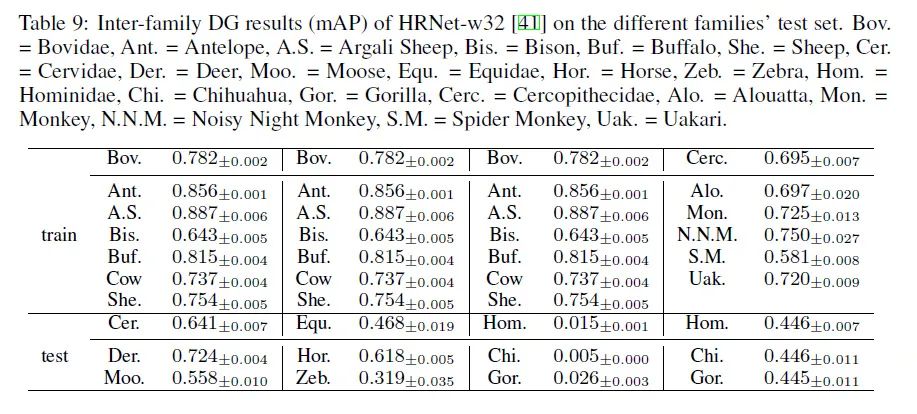
3.2 科间的迁移学习和少样本学习
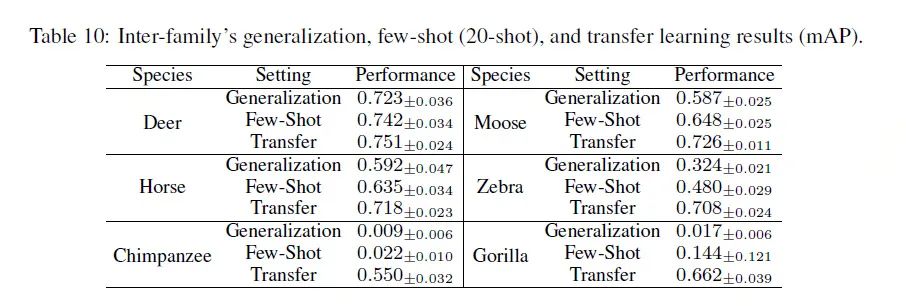
在科间泛化实验的基础上,我们又进一步探究了少样本学习和迁移学习带来的性能提升效果。我们同样采用牛科的图片作为训练集,然后在鹿科、马科和人科的训练集上进行微调,最后在这三科的测试集上进行测试。其中少样本学习对每个物种抽样20张进行微调,而迁移学习采用该物种的全部训练集图片进行微调。实验结果表明少样本学习和迁移学习的效果均相对于直接泛化测试有了不同程度的提升。即便是对人科这样和训练集差距较大的测试集,采用更多的图片进行迁移也能得到性能的提升。更多不同样本数量设置下的少样本学习结果可以参见论文补充材料[1]。
3.3 跨数据集测试
我们对比了Animal Pose Dataset[7](包含5类动物)和AP-10K数据集的双向泛化效果。我们分别对源数据集进行训练,然后进行直接在目标数据集上进行泛化测试、微调并测试、训练并测试三种实验。实验结果表明采用包含更多物种的AP-10K数据集进行(预)训练的模型的泛化性能更好。

下图(图4)第一行展示了HRNet-w32网络在Animal Pose Dataset上训练后的测试效果,第二行展示了该模型在AP-10K上的训练并测试效果,第三行是图片的原标记。由图中可以看出在AP-10K上的训练效果不但更好,而且还能预测出一些未标记的关键点位置。

04 结论和展望
本文提出了AP-10K:第一个大规模的哺乳动物姿态数据集。它的物种数量、姿态多样性,以及按照生物学关系组织上的优势可以极大的促进相关领域的研究,例如动物保护和动物行为研究等。我们采用了5种经典的姿态估计模型并测试了它们的在AP-10K数据集上的表征能力,初步探究了动物和人体姿态估计之间的联系以及不同物种之间的泛化实验。总得来说,AP-10K数据集为动物姿态估计领域提供新的测试基准。
为了便于大家使用,AP-10K数据集已经集成到了mmpose[8]框架中,可以轻松实现文中提及的多种任务的训练和测试。
参考文献
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“CVPR21检测”获取CVPR2021目标检测论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~


