机器学习开放课程(终):基于Facebook Prophet预测未来
编者按:Mail.Ru Search数据分析负责人Egor Polusmak介绍了Facebook出品的时序分析库Prophet.

时序预测在数据分析中有广泛应用,例如:
在线服务明年需要的服务器数量
指定日期超市的日用品需求量
可交易的金融资产明天的收盘价
有相当多预测未来趋势的不同方法,例如,ARIMA、ARCH、回归模型、神经网络。
本文将介绍Prophet,Facebook在2017年2月23日开源的时序预测库。我们也将用它预测Medium每天发表的文章数。
概览
导言
Prophet预测模型
Prophet实践
安装
数据集
探索性可视分析
进行预测
预测质量评估
可视化
Box-Cox变换
总结
相关资源
导言
据Facebook研究院的文章所言,Prophet原本是为创建高质量的商业预测而研发的。Prophet尝试处理许多商业时序数据中常见的困难:
人类行为导致的季节性效应:周、月、年循环,公共假期的峰谷;
新产品和市场事件导致的趋势变动;
离群值。
据称在许多情形下,默认配置的Prophet就可以生成媲美经验丰富的分析师的预测。
此外,Prophet有一些直观而易于解释的定制功能,以供逐渐改善预测模型。特别重要的是,即使不是时序分析的专家,也可以理解这些参数。
据文章所言,Prophet的适用对象和场景很广泛:
面向广泛的分析师受众,这些受众可能在时序领域没有很多经验;
面向广泛的预测问题;
自动估计大量预测的表现,包括标出可能的问题,以供分析师进一步调查。
Prophet预测模型
下面让我们仔细看看Prophet是如何工作的。本质上,这个库使用的是加性回归模型:y(t) = g(t) + s(t) + h(t) + ϵt
其中:
趋势g(t)建模非周期性变动;
季节性s(t)建模周期性变动;
假日成分h(t)提供关于假日和事件的信息。
下面我们将讨论这些模型成分的一些重要性质。
趋势
Prophet库实现两种趋势模型。
第一种是非线性饱和增长。它可以用逻辑增长模型表示:
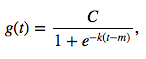
其中:
C是承载量(曲线的最大值)
k是增长率(曲线的“陡峭程度”)
m是偏置参数
这一逻辑回归等式可供建模非线性饱和增长,即数值的增长率随增长而下降。一个典型的例子是应用或网站的用户增长。
C和k实际上不一定是常量,可能随着时间而发生变动。Prophet支持自动和手动调整这两个参数,既可以通过拟合提供的历史数据自行选择最佳的趋势改变点,也可以让分析师手动指定增长率和承载量变动的时间点。
第二种趋势模型是增长率恒定的简单分段线性模型,最适合不存在饱和的线性增长。
季节性
周季节性通过虚拟变量建模:monday、tuesday、wednesday、thursday、friday、saturday(周一到周六)。这些变量的值为0还是为1取决于是星期几。sunday(周日)变量没有加入,因为上述六个变量都取0即可表示周日。相反,如果再引入周日变量,那么每个变量都可以通过另外六个变量的线性组合表示,这种变量之间的相关性会对模型产生不利影响。
年季节性通过傅里叶级数建模。
0.2版加入了新的日季节性特性,可以使用日以下尺度的时序数据并做出日以下尺度的预测。
假日和事件
h(t)表示每年的可预测反常日期,例如黑色星期五。
分析师需要提供定制的事件列表以利用这一特性。
误差
最后的误差项ϵt表示模型未反映的信息,通常建模为高斯噪声。
Prophet评测
Facebook的论文(见相关资源)对比了Prophet和其他几种时序预测方法。根据他们的研究,相比其他模型,Prophet显著降低了预测误差(使用平均绝对百分误差测量预测精确度)。
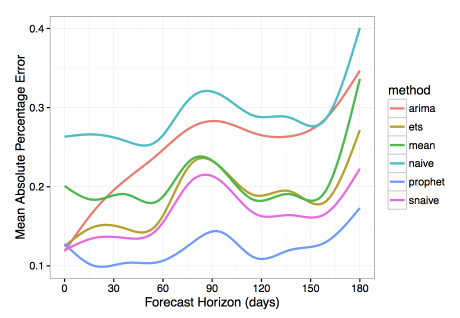
为了便于理解上面的评测结果,下面简单温习下平均绝对百分误差(MAPE)的概念。
将实际(历史)值记为yi,模型给出的预测值记为ŷi。那么预测误差ei = yi - ŷi,相对预测误差pi = ei/yi.
由此,我们定义MAPE = mean(|pi|)
MAPE广泛用于测量预测精确性,因为它将误差表示为百分比,因此可以用于不同数据集上的模型评估。
此外,评估预测算法时,为了了解误差的绝对值,可以计算平均绝对误差(MAE):MAE = mean(|ei|)
稍微讲下和Prophet作对比的算法。大多数都相当简单,经常用作基线:
naive是一个过度简化的预测方法,仅仅根据上一时间点的观测预测所有未来值。snavie,类似naive,不过考虑了季节性因素。例如,在周季节性数据的情形下,用上周一的数据预测未来每周一的数据,用上周二的数据预测未来每周二的数据,以此类推。mean,使用数据的平均值作为预测。arima是自回归集成移动平均的简称,参见第9课了解这一算法的细节。ets是指数平滑的简称,参见第9课了解详情。
Prophet实践
安装
首先安装Prophet库。Prophet支持Python和R语言。选择哪种语言取决于个人偏好和项目需求。我们这里将使用Python。
Python下可以通过pip安装:
pip install fbprophet
R也有对应的CRAN包。
引入所需模块并初始化环境:
import warnings
warnings.filterwarnings('ignore')
import numpy as np
import pandas as pd
from scipy import stats
import statsmodels.api as sm
import matplotlib.pyplot as plt
%matplotlib inline
数据集
我们将预测Medium上每天发布的文章数。
首先载入数据集(数据集下载地址见文末):
df = pd.read_csv('../../data/medium_posts.csv', sep='\t')
接着,我们丢弃除了published(发布日期)和url(可以作为文章的唯一标识)之外的所有特征,顺便移除可能存在的重复值和缺失值。
df = df[['published', 'url']].dropna().drop_duplicates()
接下来我们需要转换published为时间日期格式,因为pandas默认视为字符串。
df['published'] = pd.to_datetime(df['published'])
根据时间排序dataframe,然后查看前三条记录。
df.sort_values(by=['published']).head(n=3)
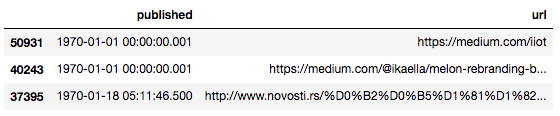
Medium是从2012年8月15日起开放的。然而,如你所见,至少有一些行的发布日期更早,这些极可能是不合法的。我们将清洗时序数据,限制一下时间范围:
df = df[(df['published'] > '2012-08-15') &
(df['published'] < '2017-06-26')].
sort_values(by=['published'])
df.head(n=3)

最后3条:
df.tail(n=3)

由于需要预测发布文章数,我们将聚合、计数给定时间点的不同文章数。我们将相应的新增列命名为posts(帖子):
aggr_df = df.groupby('published')[['url']].count()
aggr_df.columns = ['posts']
实践中我们感兴趣的是一天发布的文章数,但是当前数据属于日尺度以下的时序:
aggr_df.head(n=3)
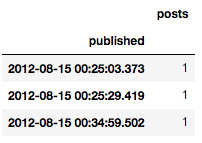
为了修正这一点,我们需要根据时间“箱”聚合文章数。在时序分析中,这一过程称为重采样。并且,如果我们降低了数据的采样率,那么这称为降采样。
幸运的是,pandas内置这一功能:
daily_df = aggr_df.resample('D').apply(sum)
daily_df.head(n=3)
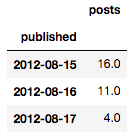
探索性可视分析
一般来说,查看数据的图形表示可能提供帮助和指引。我们将在整个时间区间上创建时序图,这可能提供季节性和明显的异常偏离的线索。
首先我们引入并初始化Plotly库,以创建美观的交互图:
from plotly.offline import init_notebook_mode, iplot
from plotly import graph_objs as go
# 初始化plotly
init_notebook_mode(connected=True)
我们还将定义一个用于绘图的帮助函数:
def plotly_df(df, title=''):
"""可视化dataframe所有列为线图。"""
common_kw = dict(x=df.index, mode='lines')
data = [go.Scatter(y=df[c], name=c, **common_kw) for c in df.columns]
layout = dict(title=title)
fig = dict(data=data, layout=layout)
iplot(fig, show_link=False)
让我们试着直接绘制数据集:
plotly_df(daily_df, title='Posts on Medium (daily)')
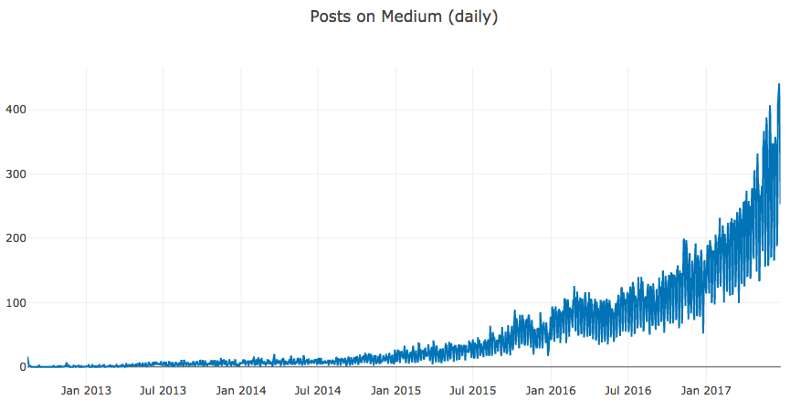
即使Plotly提供了缩放功能,这样的高频数据仍旧很难分析。除了明显的增长和加速趋势外,很难从这样的图形中推断出什么有意义的结论。
为了减少噪声,我们将按周重采样文章数。顺便提下,分箱之外,其他降噪的技术还包括移动平均平滑和指数平滑等。
我们将降采样的dataframe保存到另一个变量中,因为之后我们将按日处理数据:
weekly_df = daily_df.resample('W').apply(sum)
plotly_df(weekly_df, title='Posts on Medium (weekly)')
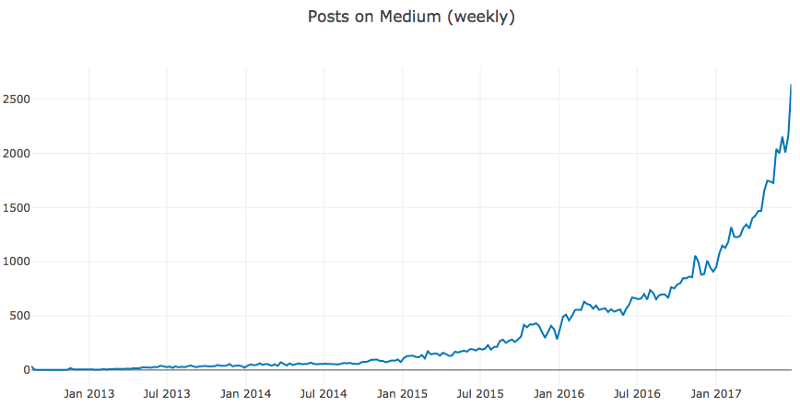
从帮助分析师预测的角度来说,这张图的效果更好。
Plotly提供的最有用的功能之一是快速深入不同时间段,这有助于更好地理解数据以及找到关于可能的趋势、周期性、反常效应的线索。
例如,放大连续几年会显示对应基督教节日的时间点,这些对人类行为有重大影响。
根据上图,我们将省略2015年之前的观测。头几年每天发布的文章数很低,可能给预测增加噪声,因为模型可能不得不拟合这些异常的历史数据而不能更好地利用最近几年更相关、更具指示性的数据。
daily_df = daily_df.loc[daily_df.index >= '2015-01-01']
daily_df.head(n=3)
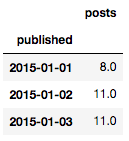
基于可视化分析,我们可以看到我们的数据集呈现出一个显著的不断增长的趋势。同时也展示了周积极性和年季节性,还有每年中的一些异常日期。
进行预测
Prophet的API和sklearn很相似。首先创建一个模型,接着调用fit方法,最后做出预测。fit方法的输入是一个包含两列的DataFrame:
ds(datestamp),类型必须是date或datetime。y是想要预测的数值。
我们先引入库并关闭不重要的诊断信息:
from fbprophet import Prophet
import logging
logging.getLogger().setLevel(logging.ERROR)
转换dataframe至Prophet要求的格式:
df = daily_df.reset_index()
df.columns = ['ds', 'y']
df.tail(n=3)
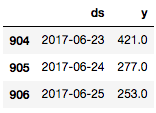
Prophet的作者建议至少根据几个月的数据进行预测,如果有超过一年的历史数据就最理想了。很幸运,我们这里有好几年的数据可供模型拟合。
为了测量预测的质量,我们需要将数据集分为历史部分(数据的前部,也是最大部分)和预测部分(时间线的最后部分)。我们从数据集中移除最后一个月的数据,作为测试目标:
prediction_size = 30
train_df = df[:-prediction_size]
train_df.tail(n=3)
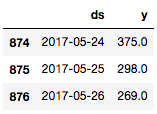
现在我们需要创建一个新的Prophet对象(模型),我们可以传入模型的参数,但是这里我们将使用默认值。接着在训练数据集上调用fit方法训练模型。
m = Prophet()
m.fit(train_df);
然后我们使用辅助函数Prophet.make_future_dataframe创建一个dataframe,其中包括所有历史日期,以及之前留置的未来30天。
future = m.make_future_dataframe(periods=prediction_size)
future.tail(n=3)

调用predict方法,传入我们想要创建预测的日期后就可以预测新值了。如果像这里一样同时提供历史数据,那除了预测之外我们还能得到历史的内拟合。
forecast = m.predict(future)
forecast.tail(n=3)

在结果dataframe中,我们可以看到很多描绘预测的列,包括趋势成分、季节性成分,还有它们的置信区间。预测本身存储于yhat列。
Prophet库内置可视化工具,方便迅速评估结果。
首先,Prophet.plot方法可以绘制所有预测的数据点:
m.plot(forecast);
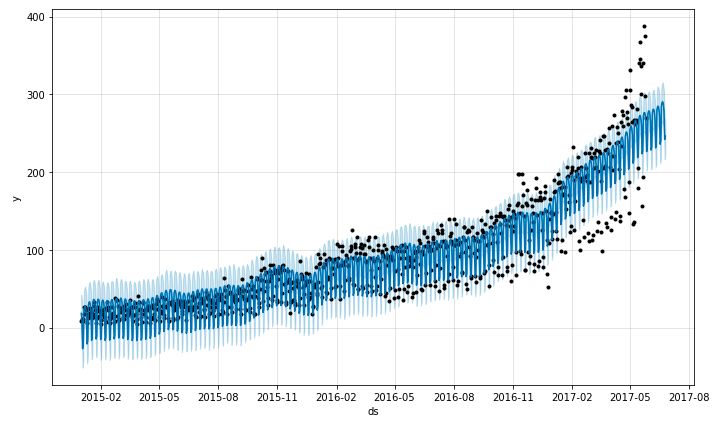
这张图没有提供多少信息。我们唯一能得出的结论是模型将许多数据点视为离群值。
在我们的情形中,Prophet.plot_components函数也许要有用得多。它让我们可以分别观察模型的不同成分:趋势、年季节性、周季节性。如果给模型提供了关于假日和事件的信息,图形也会显示相关信息。
m.plot_components(forecast);
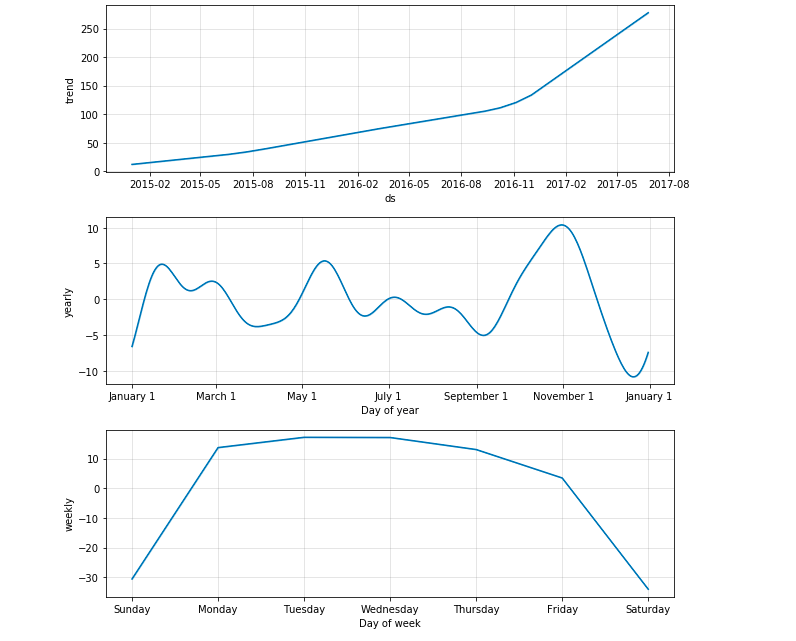
从趋势图中,我们可以看到,Prophet很好地拟合了2016年末后的加速增长趋势。从周季节性图中,我们可以得出结论,和工作日相比,周六、周日的新文章较少。而年季节性图清楚地显示了圣诞节那一天的迅猛下跌。
预测质量评估
让我们计算预测的最后30天的误差测度,以便评估算法的质量。为此,我们需要观测yi和相应的预测值ŷi。
看下Prophet为我们创建的forecast对象:
print(', '.join(forecast.columns))
结果:
ds, trend, trend_lower, trend_upper, yhat_lower, yhat_upper, seasonal, seasonal_lower, seasonal_upper, seasonalities, seasonalities_lower, seasonalities_upper, weekly, weekly_lower, weekly_upper, yearly, yearly_lower, yearly_upper, yhat
我们看到,其中没有历史值。我们需要从原数据集df中获取实际值y,然后和forecast对象中的预测值比较。为此我们定义一个辅助函数:
def make_comparison_dataframe(historical, forecast):
return forecast.set_index('ds')[['yhat', 'yhat_lower', 'yhat_upper']].join(historical.set_index('ds'))
应用这一函数:
cmp_df = make_comparison_dataframe(df, forecast)
cmp_df.tail(n=3)
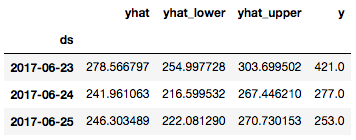
我们再定义一个计算MAPE和MAE的辅助函数:
def calculate_forecast_errors(df, prediction_size):
df = df.copy()
df['e'] = df['y'] - df['yhat']
df['p'] = 100 * df['e'] / df['y']
predicted_part = df[-prediction_size:]
error_mean = lambda error_name: np.mean(np.abs(predicted_part[error_name]))
return {'MAPE': error_mean('p'), 'MAE': error_mean('e')}
然后用它计算MAPE和MAE:
for err_name, err_value in
calculate_forecast_errors(cmp_df, prediction_size).items():
print(err_name, err_value)
结果:
MAPE 22.7243579814
MAE 70.452857085
可视化
现在让我们自行可视化Prophet创建的模型。它将包括实际值、预测值和置信区间。
首先,我们绘制较短时期内的图形,这样数据点更容易分辨。接着,我们只显示模型在预测期间内的表现(最后30天)。这两个测度看起来能带来更清晰的图形。
最后,我们将使用Plotly让图形可以交互,这对探索很重要。
我们将定义一个辅助函数show_forecast并调用它:
def show_forecast(cmp_df, num_predictions, num_values, title):
def create_go(name, column, num, **kwargs):
points = cmp_df.tail(num)
args = dict(name=name, x=points.index, y=points[column], mode='lines')
args.update(kwargs)
return go.Scatter(**args)
lower_bound = create_go('Lower Bound', 'yhat_lower', num_predictions,
line=dict(width=0),
marker=dict(color="444"))
upper_bound = create_go('Upper Bound', 'yhat_upper', num_predictions,
line=dict(width=0),
marker=dict(color="444"),
fillcolor='rgba(68, 68, 68, 0.3)',
fill='tonexty')
forecast = create_go('Forecast', 'yhat', num_predictions,
line=dict(color='rgb(31, 119, 180)'))
actual = create_go('Actual', 'y', num_values,
marker=dict(color="red"))
data = [lower_bound, upper_bound, forecast, actual]
layout = go.Layout(yaxis=dict(title='Posts'), title=title, showlegend = False)
fig = go.Figure(data=data, layout=layout)
iplot(fig, show_link=False)
show_forecast(cmp_df, prediction_size, 100, 'New posts on Medium')
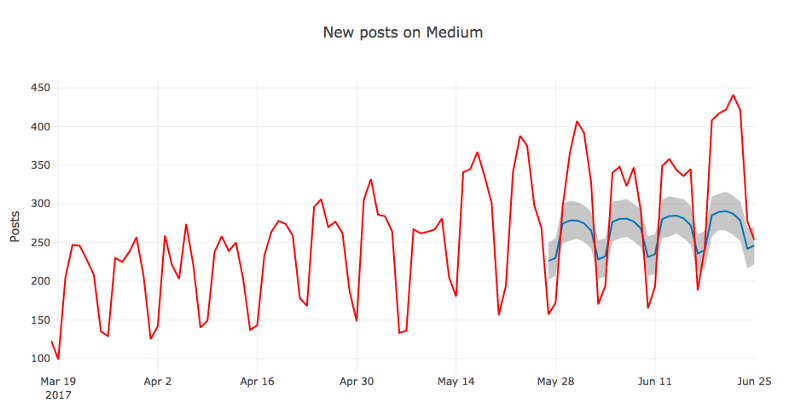
初看起来模型预测的均值还挺合理的。从图上看,之所以之前算出来的MAPE值比较高,可能是因为模型没能捕捉周季节性增长高峰的放大效应。
我们还可以从图中得出的结论是,许多实际值位于置信区间之外。Prophet也许不太适合方差不稳定的时序,至少在默认设置下是如此。我们将通过转换数据来尝试修正这一点。
Box-Cox变换
目前为止,我们使用的都是Prophet的默认设置,数据也基本上是原始数据。我们这里不打算讨论如何调整模型的参数,不过,即使在不动默认参数的情况下,还是有提升的空间。在这一节,我们将在原始时序上应用Box-Cox变换,看看会有什么效果。
简单介绍下这一变换。这一单调数据变换可以稳定方差。我们将使用单参数Box-Cox变换:
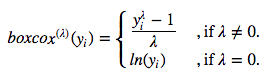
使用上式的逆函数可以还原至原数据的尺度:
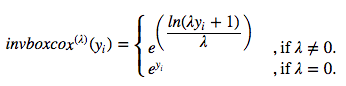
相应的Python函数:
def inverse_boxcox(y, lambda_):
return np.exp(y) if lambda_ == 0 else np.exp(np.log(lambda_ * y + 1) / lambda_)
首先,我们准备数据,设置索引:
train_df2 = train_df.copy().set_index('ds')
接着,我们应用Scipy的stats.boxcox函数(Box-Cox变换)。这里它将返回两个值,第一个值是转换后的序列,第二个值是找到的最优λ值(最大似然):
train_df2['y'], lambda_prophet = stats.boxcox(train_df2['y'])
train_df2.reset_index(inplace=True)
创建一个新Prophet模型,并重复之前的拟合-预测流程:
m2 = Prophet()
m2.fit(train_df2)
future2 = m2.make_future_dataframe(periods=prediction_size)
forecast2 = m2.predict(future2)
然后通过逆函数和已知的λ值反转Box-Cox变换:
for column in ['yhat', 'yhat_lower', 'yhat_upper']:
forecast2[column] = inverse_boxcox(forecast2[column],
lambda_prophet)
复用之前创建对比dataframe和计算误差的代码:
cmp_df2 = make_comparison_dataframe(df, forecast2)
for err_name, err_value in calculate_forecast_errors(cmp_df2, prediction_size).items():
print(err_name, err_value)
结果:
MAPE 11.5921879552
MAE 39.072031256
毫无疑问,模型的质量提升了。
最后,让我们绘制最新结果的可视化图形,和之前的放一起对比下。
show_forecast(cmp_df, prediction_size, 100, 'No transformations')
show_forecast(cmp_df2, prediction_size, 100, 'Box–Cox transformation')
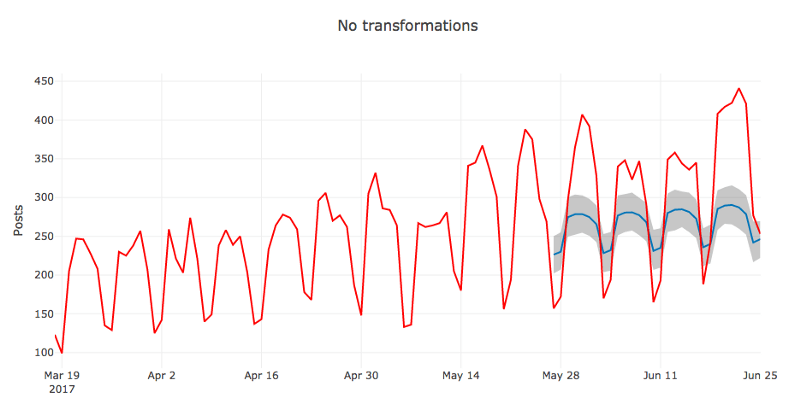
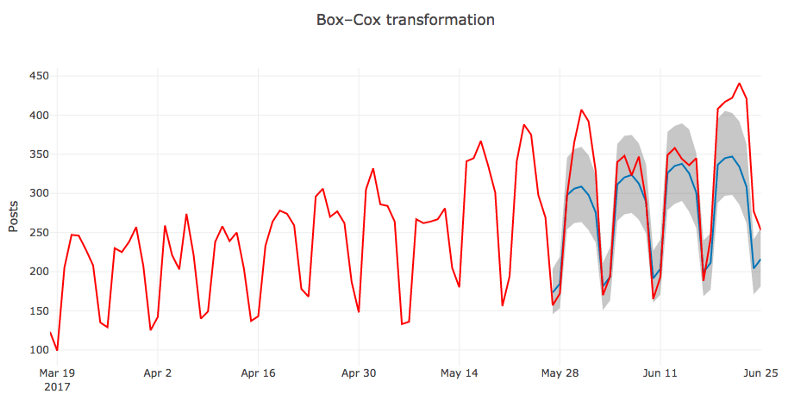
很明显,第二张图中的预测值更加接近真实值。
总结
我们介绍了Prophet这一开源的时序预测库,并进行了一些时序预测的实践。
如我们所见,Prophet并不神奇,开箱即用的预测并不理想。它仍然需要数据科学家在必要的时候探索预测结果,调整模型参数,转换数据。
不过,这一个用户友好、易于定制的库。在某些情形下,单单将分析师事先知道的异常日期纳入考虑这一功能就会带来很大的不同。
总的来说,Prophet库值得收入你的分析工具箱。
相关资源
GitHub上的Prophet官方仓库:https://github.com/facebook/prophet
Prophet官方文档:https://facebookincubator.github.io/prophet/docs/quick_start.html
Sean J. Taylor和Benjamin Letham的论文Forecasting at scale解释了作为Prophet基础的算法。
Chris Moffitt写的Prophet概览(以预测网站流量为例):http://pbpython.com/prophet-overview.html
Rob J. Hyndman和George Athanasopoulos写的Forecasting: principles and practice——很好的关于时序预测的一本书(有在线版)
本文配套的Jupyter Notebook: git.io/fpslo
Medium数据集:https://drive.google.com/file/d/1G3YjM6mR32iPnQ6O3f6rE9BVbhiTiLyU/view
课程回顾
机器学习开放课程系列至此告一段落,所以这里列下之前的十课:
配套视频(目前更新到第6课):https://youtu.be/QKTuw4PNOsU
连喵星人也被课程吸引(来源:Yulia Kameneva)
配套Kaggle竞赛:
基于网页会话检测恶意用户:https://www.kaggle.com/c/catch-me-if-you-can-intruder-detection-through-webpage-session-tracking2
预测Medium文章推荐数:https://www.kaggle.com/c/how-good-is-your-medium-article/
课程最新进展:https://mlcourse.ai/news
原文地址:https://medium.com/open-machine-learning-course/open-machine-learning-course-topic-9-part-3-predicting-the-future-with-facebook-prophet-3f3af145cdc