COLING 2020 | 一种从科学文献中提取关键词的基于自蒸馏的联合学习方法
来自:艾达AI

一、引言
二、数据集
本文采用两个目标数据集:Inspec和SemEval-2017。Inspec数据集有1000/500/500条用于Train / dev / test拆分的科学文章摘要。SemEval-2017数据集有350/50/100条关于Train / dev / test拆分的科学文章。在实验中,我们使用KP20k数据集作为源数据集,因为它包含从各种在线数字图书馆收集的500,000多篇文章。
三、模型
Problem Formulation
Baseline Models
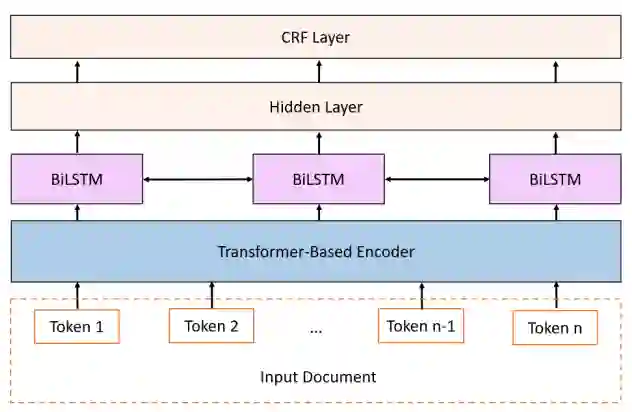 图
1
基线模型的高层次概述
图
1
基线模型的高层次概述
Joint Learning based on Self-Distillation (JLSD)
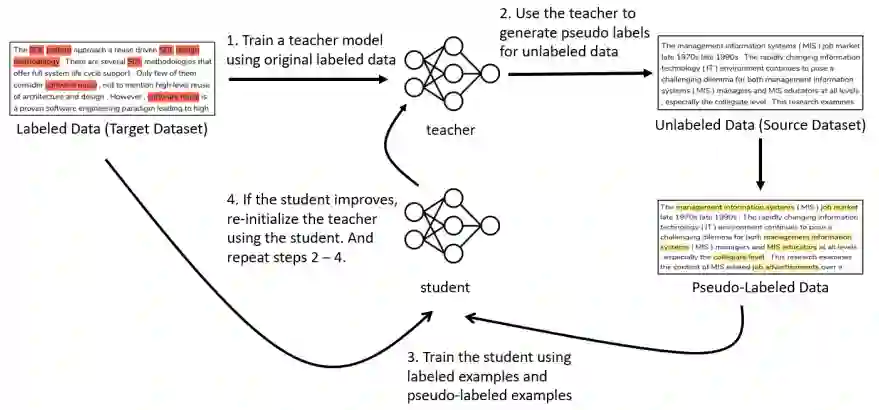

四、实验
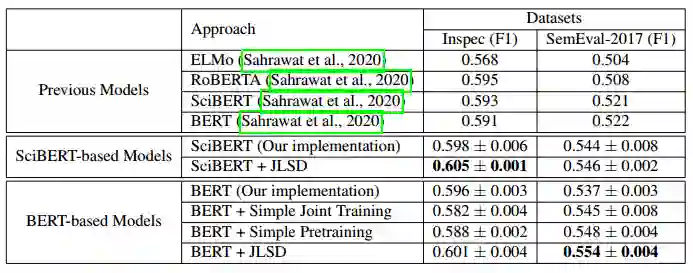
 表2 无监督模型的结果
表2 无监督模型的结果
五、结论
下载一:中文版!学习TensorFlow、PyTorch、机器学习、深度学习和数据结构五件套!
![]()
![]()
![]()
后台回复【五件套】
下载二:南大模式识别PPT
![]()
后台回复【南大模式识别】




由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!

登录查看更多
相关内容
Arxiv
20+阅读 · 2020年3月10日
Arxiv
11+阅读 · 2017年12月27日



相关VIP内容
相关资讯
相关论文
Arxiv
20+阅读 · 2020年3月10日
Arxiv
11+阅读 · 2017年12月27日