【重磅最新】ICLR2023顶会376篇深度强化学习论文得分出炉(376/4753,占比8%)
排版:OpenDeepRL
声明:本文整理自顶会ICLR-2023官方,强化学习相关文章大约共计376篇(376/4753), 占比8%,整理难免有不足之处,还望交流指正。

历年ICLR接收投稿数量(引自AI科技评论)

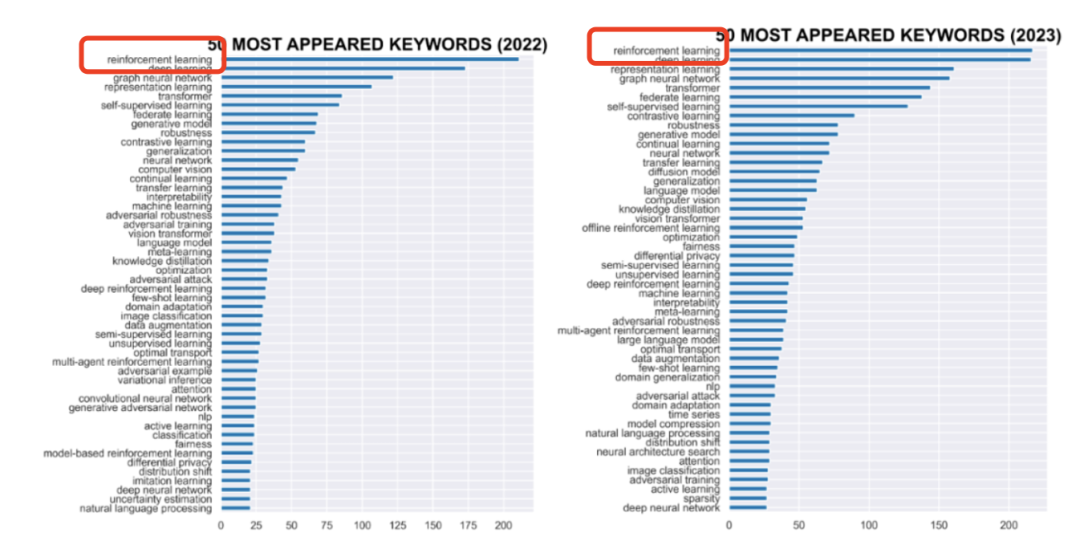
2022 年和 2023 年 ICLR 论文投稿关键词频率比较(引自AI科技评论)
强化学习相关论文
1.DEP-RL: Embodied Exploration for Reinforcement Learning in Overactuated and Musculoskeletal Systems
平均分:8.50 标准差:0.87 评分:10, 8, 8, 8
2.Mastering the Game of No-Press Diplomacy via Human-Regularized Reinforcement Learning and Planning
平均分:8.00 标准差:0.00 评分:8, 8, 8
3.Provably Efficient Neural Offline Reinforcement Learning via Perturbed Rewards
平均分:7.50 标准差:0.87 评分:8, 8, 8, 6
4.Symbolic Physics Learner: Discovering governing equations via Monte Carlo tree search
平均分:7.50 标准差:0.87 评分:8, 8, 8, 6
5.The In-Sample Softmax for Offline Reinforcement Learning
平均分:7.33 标准差:0.94 评分:8, 6, 8
6.Disentanglement of Correlated Factors via Hausdorff Factorized Support
平均分:7.33 标准差:0.94 评分:8, 6, 8
7.Soft Neighbors are Positive Supporters in Contrastive Visual Representation Learning
平均分:7.33 标准差:0.94 评分:8, 6, 8
8.A General Framework for Sample-Efficient Function Approximation in Reinforcement Learning
平均分:7.33 标准差:0.94 评分:6, 8, 8
9.Offline Q-learning on Diverse Multi-Task Data Both Scales And Generalizes
平均分:7.25 标准差:1.92 评分:8, 6, 10, 5
10.Diffusion Policies as an Expressive Policy Class for Offline Reinforcement Learning
平均分:7.25 标准差:1.30 评分:5, 8, 8, 8
11.Extreme Q-Learning: MaxEnt RL without Entropy
平均分:7.25 标准差:1.92 评分:8, 5, 10, 6
12.ResAct: Reinforcing Long-term Engagement in Sequential Recommendation with Residual Actor
平均分:7.25 标准差:1.30 评分:8, 8, 8, 5
13.The Role of Coverage in Online Reinforcement Learning
平均分:7.00 标准差:1.41 评分:8, 5, 8
14.Is Reinforcement Learning (Not) for Natural Language Processing?: Benchmarks, Baselines, and Building Blocks for Natural Language Policy Optimization
平均分:7.00 标准差:1.00 评分:6, 6, 8, 8
15.Spectral Decomposition Representation for Reinforcement Learning
平均分:7.00 标准差:1.41 评分:8, 8, 5
16.Certifiably Robust Policy Learning against Adversarial Multi-Agent Communication
平均分:7.00 标准差:1.41 评分:8, 8, 5
17.Pink Noise Is All You Need: Colored Noise Exploration in Deep Reinforcement Learning
平均分:7.00 标准差:1.41 评分:5, 8, 8
18.Self-supervision through Random Segments with Autoregressive Coding (RandSAC)
平均分:7.00 标准差:1.41 评分:5, 8, 8
19.Benchmarking Offline Reinforcement Learning on Real-Robot Hardware
平均分:7.00 标准差:1.00 评分:8, 8, 6, 6
20.Outcome-directed Reinforcement Learning by Uncertainty & Temporal Distance-Aware Curriculum Goal Generation
平均分:7.00 标准差:1.41 评分:8, 8, 5
21.In-context Reinforcement Learning with Algorithm Distillation
平均分:6.75 标准差:1.30 评分:8, 8, 6, 5
22.User-Interactive Offline Reinforcement Learning
平均分:6.75 标准差:2.59 评分:8, 3, 6, 10
23.Discovering Generalizable Multi-agent Coordination Skills from Multi-task Offline Data
平均分:6.75 标准差:1.30 评分:8, 5, 6, 8
24.Does Zero-Shot Reinforcement Learning Exist?
平均分:6.75 标准差:2.59 评分:6, 3, 8, 10
25.RLx2: Training a Sparse Deep Reinforcement Learning Model from Scratch
平均分:6.75 标准差:1.30 评分:5, 6, 8, 8
26.Efficient Deep Reinforcement Learning Requires Regulating Statistical Overfitting
平均分:6.67 标准差:0.94 评分:6, 6, 8
27.Revisiting Populations in multi-agent Communication
平均分:6.67 标准差:0.94 评分:6, 6, 8
28.MAESTRO: Open-Ended Environment Design for Multi-Agent Reinforcement Learning
平均分:6.67 标准差:0.94 评分:6, 8, 6
29.Quality-Similar Diversity via Population Based Reinforcement Learning
平均分:6.67 标准差:0.94 评分:6, 8, 6
30.Hyperbolic Deep Reinforcement Learning
平均分:6.67 标准差:0.94 评分:6, 8, 6
31.Sample-Efficient Reinforcement Learning by Breaking the Replay Ratio Barrier
平均分:6.67 标准差:0.94 评分:6, 6, 8
32.Hungry Hungry Hippos: Towards Language Modeling with State Space Models
平均分:6.67 标准差:0.94 评分:6, 8, 6
33.Near-optimal Policy Identification in Active Reinforcement Learning
平均分:6.67 标准差:0.94 评分:6, 8, 6
34.LS-IQ: Implicit Reward Regularization for Inverse Reinforcement Learning
平均分:6.50 标准差:1.50 评分:5, 8, 5, 8
35.Offline Reinforcement Learning with Differentiable Function Approximation is Provably Efficient
平均分:6.50 标准差:0.87 评分:6, 6, 8, 6
36.Learning Achievement Structure for Structured Exploration in Domains with Sparse Reward
平均分:6.50 标准差:1.50 评分:8, 8, 5, 5
37.Conservative Bayesian Model-Based Value Expansion for Offline Policy Optimization
平均分:6.50 标准差:0.87 评分:6, 8, 6, 6
38.Wasserstein Auto-encoded MDPs: Formal Verification of Efficiently Distilled RL Policies with Many-sided Guarantees
平均分:6.50 标准差:1.50 评分:5, 5, 8, 8
39.Causal Imitation Learning via Inverse Reinforcement Learning
平均分:6.33 标准差:1.25 评分:6, 8, 5
40.Human-level Atari 200x faster
平均分:6.33 标准差:2.36 评分:3, 8, 8
41.Risk-Aware Reinforcement Learning with Coherent Risk Measures and Non-linear Function Approximation
平均分:6.33 标准差:1.25 评分:6, 8, 5
42.POPGym: Benchmarking Partially Observable Reinforcement Learning
平均分:6.33 标准差:2.36 评分:8, 8, 3
43.Revocable Deep Reinforcement Learning with Affinity Regularization for Outlier-Robust Graph Matching
平均分:6.33 标准差:1.25 评分:8, 6, 5
44.Learnable Behavior Control: Breaking Atari Human World Records via Sample-Efficient Behavior Selection
平均分:6.33 标准差:2.36 评分:3, 8, 8
45.Is Model Ensemble Necessary? Model-based RL via a Single Model with Lipschitz Regularized Value Function
平均分:6.25 标准差:2.05 评分:8, 3, 8, 6
46.Solving Continuous Control via Q-learning
平均分:6.25 标准差:1.09 评分:8, 5, 6, 6
47.Value Memory Graph: A Graph-Structured World Model for Offline Reinforcement Learning
平均分:6.25 标准差:1.09 评分:6, 8, 6, 5
48.Pareto-Efficient Decision Agents for Offline Multi-Objective Reinforcement Learning
平均分:6.25 标准差:1.09 评分:8, 5, 6, 6
49.MoDem: Accelerating Visual Model-Based Reinforcement Learning with Demonstrations
平均分:6.25 标准差:1.09 评分:6, 5, 6, 8
50.PD-MORL: Preference-Driven Multi-Objective Reinforcement Learning Algorithm
平均分:6.25 标准差:2.05 评分:8, 8, 6, 3
51.How to Train your HIPPO: State Space Models with Generalized Orthogonal Basis Projections
平均分:6.25 标准差:1.09 评分:8, 6, 6, 5
52.Generalization and Estimation Error Bounds for Model-based Neural Networks
平均分:6.25 标准差:1.09 评分:8, 5, 6, 6
53.Breaking the Curse of Dimensionality in Multiagent State Space: A Unified Agent Permutation Framework
平均分:6.25 标准差:1.09 评分:6, 5, 6, 8
54.CLARE: Conservative Model-Based Reward Learning for Offline Inverse Reinforcement Learning
平均分:6.25 标准差:2.05 评分:6, 8, 8, 3
55.Near-Optimal Adversarial Reinforcement Learning with Switching Costs
平均分:6.25 标准差:2.05 评分:8, 8, 6, 3
56.Provably Efficient Risk-Sensitive Reinforcement Learning: Iterated CVaR and Worst Path
平均分:6.25 标准差:2.05 评分:6, 3, 8, 8
57.Dynamic Prompt Learning via Policy Gradient for Semi-structured Mathematical Reasoning
平均分:6.20 标准差:0.98 评分:5, 6, 8, 6, 6
58.Guarded Policy Optimization with Imperfect Online Demonstrations
平均分:6.00 标准差:2.12 评分:8, 3, 5, 8
59.Greedy Actor-Critic: A New Conditional Cross-Entropy Method for Policy Improvement
平均分:6.00 标准差:1.41 评分:5, 8, 5
60.Order Matters: Agent-by-agent Policy Optimization
平均分:6.00 标准差:1.10 评分:5, 6, 5, 6, 8
61.Achieve Near-Optimal Individual Regret & Low Communications in Multi-Agent Bandits
平均分:6.00 标准差:0.00 评分:6, 6, 6
62.Provably efficient multi-task Reinforcement Learning in large state spaces
平均分:6.00 标准差:1.41 评分:5, 5, 8
63.A Unified Approach to Reinforcement Learning, Quantal Response Equilibria, and Two-Player Zero-Sum Games
平均分:6.00 标准差:2.12 评分:5, 8, 8, 3
64.On the Data-Efficiency with Contrastive Image Transformation in Reinforcement Learning
平均分:6.00 标准差:1.22 评分:6, 5, 5, 8
65.In-sample Actor Critic for Offline Reinforcement Learning
平均分:6.00 标准差:1.22 评分:8, 5, 6, 5
66.Harnessing Mixed Offline Reinforcement Learning Datasets via Trajectory Weighting
平均分:6.00 标准差:1.22 评分:6, 5, 5, 8
67.Simplifying Model-based RL: Learning Representations, Latent-space Models, and Policies with One Objective
平均分:6.00 标准差:1.10 评分:5, 6, 8, 6, 5
68.Cheap Talk Discovery and Utilization in Multi-Agent Reinforcement Learning
平均分:6.00 标准差:1.22 评分:8, 6, 5, 5
69.Pessimism in the Face of Confounders: Provably Efficient Offline Reinforcement Learning in Partially Observable Markov Decision Processes
平均分:6.00 标准差:0.00 评分:6, 6, 6, 6
70.Pareto-Optimal Diagnostic Policy Learning in Clinical Applications via Semi-Model-Based Deep Reinforcement Learning
平均分:6.00 标准差:0.00 评分:6, 6, 6
71.Sparse Q-Learning: Offline Reinforcement Learning with Implicit Value Regularization
平均分:6.00 标准差:1.41 评分:5, 5, 8
72.The Benefits of Model-Based Generalization in Reinforcement Learning
平均分:6.00 标准差:1.22 评分:5, 5, 6, 8
73.Sample Complexity of Nonparametric Off-Policy Evaluation on Low-Dimensional Manifolds using Deep Networks
平均分:6.00 标准差:1.22 评分:6, 5, 8, 5
74.Transport with Support: Data-Conditional Diffusion Bridges
平均分:5.75 标准差:0.43 评分:6, 6, 5, 6
75.Neuroevolution is a Competitive Alternative to Reinforcement Learning for Skill Discovery
平均分:5.75 标准差:1.79 评分:3, 6, 8, 6
76.Gray-Box Gaussian Processes for Automated Reinforcement Learning
平均分:5.75 标准差:1.30 评分:5, 5, 5, 8
77.Safe Reinforcement Learning From Pixels Using a Stochastic Latent Representation
平均分:5.75 标准差:0.43 评分:6, 6, 6, 5
78.Reinforcement Learning-Based Estimation for Partial Differential Equations
平均分:5.75 标准差:0.43 评分:6, 5, 6, 6
79.Towards Interpretable Deep Reinforcement Learning with Human-Friendly Prototypes
平均分:5.75 标准差:0.43 评分:5, 6, 6, 6
80.Uncovering Directions of Instability via Quadratic Approximation of Deep Neural Loss in Reinforcement Learning
平均分:5.75 标准差:1.30 评分:8, 5, 5, 5
81.Can Wikipedia Help Offline Reinforcement Learning?
平均分:5.75 标准差:1.79 评分:8, 6, 3, 6
82.Model-based Causal Bayesian Optimization
平均分:5.75 标准差:1.30 评分:5, 8, 5, 5
83.Near-Optimal Deployment Efficiency in Reward-Free Reinforcement Learning with Linear Function Approximation
平均分:5.75 标准差:0.43 评分:6, 6, 5, 6
84.Latent Variable Representation for Reinforcement Learning
平均分:5.75 标准差:1.79 评分:3, 6, 8, 6
85.Enforcing Hard Constraints with Soft Barriers: Safe Reinforcement Learning in Unknown Stochastic Environments
平均分:5.75 标准差:1.30 评分:5, 8, 5, 5
86.Towards Minimax Optimal Reward-free Reinforcement Learning in Linear MDPs
平均分:5.75 标准差:0.43 评分:6, 5, 6, 6
87.Jump-Start Reinforcement Learning
平均分:5.75 标准差:1.79 评分:6, 8, 6, 3
88.Learning Adversarial Linear Mixture Markov Decision Processes with Bandit Feedback and Unknown Transition
平均分:5.75 标准差:0.43 评分:6, 6, 6, 5
89.Diminishing Return of Value Expansion Methods in Model-Based Reinforcement Learning
平均分:5.75 标准差:1.30 评分:5, 8, 5, 5
90.Posterior Sampling Model-based Policy Optimization under Approximate Inference
平均分:5.75 标准差:1.79 评分:3, 8, 6, 6
91.Multi-Objective Reinforcement Learning: Convexity, Stationarity and Pareto Optimality
平均分:5.75 标准差:1.79 评分:8, 6, 3, 6
92.Learning Human-Compatible Representations for Case-Based Decision Support
平均分:5.75 标准差:0.43 评分:6, 5, 6, 6
93.Robust Multi-Agent Reinforcement Learning with State Uncertainties
平均分:5.75 标准差:0.43 评分:6, 6, 5, 6
94.Priors, Hierarchy, and Information Asymmetry for Skill Transfer in Reinforcement Learning
平均分:5.75 标准差:1.30 评分:8, 5, 5, 5
95.ERL-Re$^2$: Efficient Evolutionary Reinforcement Learning with Shared State Representation and Individual Policy Representation
平均分:5.75 标准差:1.79 评分:8, 6, 6, 3
96.Performance Bounds for Model and Policy Transfer in Hidden-parameter MDPs
平均分:5.67 标准差:2.05 评分:3, 8, 6
97.PAC Reinforcement Learning for Predictive State Representations
平均分:5.67 标准差:0.47 评分:6, 5, 6
98.Temporal Disentanglement of Representations for Improved Generalisation in Reinforcement Learning
平均分:5.67 标准差:0.47 评分:6, 6, 5
99.Graph-based Deterministic Policy Gradient for Repetitive Combinatorial Optimization Problems
平均分:5.67 标准差:2.05 评分:6, 8, 3
100.Coordination Scheme Probing for Generalizable Multi-Agent Reinforcement Learning
平均分:5.67 标准差:2.05 评分:3, 8, 6
101.More Centralized Training, Still Decentralized Execution: Multi-Agent Conditional Policy Factorization
平均分:5.67 标准差:0.47 评分:6, 5, 6
102.Efficient Offline Policy Optimization with a Learned Model
平均分:5.67 标准差:0.47 评分:6, 6, 5
103.Asynchronous Gradient Play in Zero-Sum Multi-agent Games
平均分:5.67 标准差:0.47 评分:6, 5, 6
104.An Adaptive Entropy-Regularization Framework for Multi-Agent Reinforcement Learning
平均分:5.67 标准差:2.05 评分:3, 8, 6
105.Offline Reinforcement Learning with Closed-Form Policy Improvement Operators
平均分:5.67 标准差:0.47 评分:5, 6, 6
106.Conservative Exploration in Linear MDPs under Episode-wise Constraints
平均分:5.50 标准差:0.50 评分:5, 5, 6, 6
107.Faster Last-iterate Convergence of Policy Optimization in Zero-Sum Markov Games
平均分:5.50 标准差:1.80 评分:3, 5, 6, 8
108.Replay Memory as An Empirical MDP: Combining Conservative Estimation with Experience Replay
平均分:5.50 标准差:0.50 评分:6, 5, 5, 6
109.Confidence-Conditioned Value Functions for Offline Reinforcement Learning
平均分:5.50 标准差:1.80 评分:6, 8, 5, 3
110.TEMPERA: Test-Time Prompt Editing via Reinforcement Learning
平均分:5.50 标准差:0.50 评分:5, 5, 6, 6
111.Parallel $Q$-Learning: Scaling Off-policy Reinforcement Learning
平均分:5.50 标准差:1.80 评分:5, 8, 3, 6
112.Investigating Multi-task Pretraining and Generalization in Reinforcement Learning
平均分:5.50 标准差:1.80 评分:5, 6, 8, 3
113.Accelerating Hamiltonian Monte Carlo via Chebyshev Integration Time
平均分:5.50 标准差:1.80 评分:8, 6, 5, 3
114.HiT-MDP: Learning the SMDP option framework on MDPs with Hidden Temporal Variables
平均分:5.50 标准差:1.80 评分:6, 8, 3, 5
115.Unsupervised Model-based Pre-training for Data-efficient Control from Pixels
平均分:5.50 标准差:1.80 评分:8, 3, 5, 6
116.A GENERAL SCENARIO-AGNOSTIC REINFORCEMENT LEARNING FOR TRAFFIC SIGNAL CONTROL
平均分:5.50 标准差:0.50 评分:5, 6, 6, 5
117.A Connection between One-Step Regularization and Critic Regularization in Reinforcement Learning
平均分:5.50 标准差:1.80 评分:3, 5, 8, 6
118.Achieving Sub-linear Regret in Infinite Horizon Average Reward Constrained MDP with Linear Function Approximation
平均分:5.50 标准差:1.80 评分:6, 8, 3, 5
119.Observational Robustness and Invariances in Reinforcement Learning via Lexicographic Objectives
平均分:5.50 标准差:1.50 评分:5, 3, 8, 5, 6, 6
120.On the Feasibility of Cross-Task Transfer with Model-Based Reinforcement Learning
平均分:5.50 标准差:0.50 评分:5, 6, 6, 5
121.Distributional Meta-Gradient Reinforcement Learning
平均分:5.50 标准差:1.80 评分:5, 8, 6, 3
122.CBLab: Scalable Traffic Simulation with Enriched Data Supporting
平均分:5.50 标准差:1.80 评分:8, 5, 6, 3
123.EUCLID: Towards Efficient Unsupervised Reinforcement Learning with Multi-choice Dynamics Model
平均分:5.50 标准差:0.50 评分:5, 6, 6, 5
124.Bringing Saccades and Fixations into Self-supervised Video Representation Learning
平均分:5.50 标准差:0.50 评分:6, 6, 5, 5
125.LPMARL: Linear Programming based Implicit Task Assignment for Hierarchical Multi-agent Reinforcement Learning
平均分:5.50 标准差:0.50 评分:5, 5, 6, 6
126.Constrained Hierarchical Deep Reinforcement Learning with Differentiable Formal Specifications
平均分:5.50 标准差:1.80 评分:3, 5, 6, 8
127.On the Robustness of Safe Reinforcement Learning under Observational Perturbations
平均分:5.50 标准差:0.50 评分:5, 6, 5, 6
128.On the Interplay Between Misspecification and Sub-optimality Gap: From Linear Contextual Bandits to Linear MDPs
平均分:5.40 标准差:0.49 评分:5, 5, 6, 5, 6
129.Raisin: Residual Algorithms for Versatile Offline Reinforcement Learning
平均分:5.33 标准差:0.47 评分:5, 5, 6
130.Offline Reinforcement Learning from Heteroskedastic Data Via Support Constraints
平均分:5.33 标准差:0.47 评分:6, 5, 5
131.ESCHER: Eschewing Importance Sampling in Games by Computing a History Value Function to Estimate Regret
平均分:5.33 标准差:0.47 评分:5, 5, 6
132.The Challenges of Exploration for Offline Reinforcement Learning
平均分:5.33 标准差:0.47 评分:5, 6, 5
133.MACTA: A Multi-agent Reinforcement Learning Approach for Cache Timing Attacks and Detection
平均分:5.33 标准差:0.47 评分:6, 5, 5
134.Causal Mean Field Multi-Agent Reinforcement Learning
平均分:5.33 标准差:0.47 评分:5, 5, 6
135.A CMDP-within-online framework for Meta-Safe Reinforcement Learning
平均分:5.33 标准差:2.05 评分:3, 5, 8
136.Faster Reinforcement Learning with Value Target Lower Bounding
平均分:5.33 标准差:0.47 评分:5, 6, 5
137.Deep Evidential Reinforcement Learning for Dynamic Recommendations
平均分:5.33 标准差:2.05 评分:3, 8, 5
138.Benchmarking Constraint Inference in Inverse Reinforcement Learning
平均分:5.33 标准差:0.47 评分:5, 5, 6
139.Behavior Prior Representation learning for Offline Reinforcement Learning
平均分:5.33 标准差:2.05 评分:3, 5, 8
140.On the Fast Convergence of Unstable Reinforcement Learning Problems
平均分:5.33 标准差:0.47 评分:5, 6, 5
141.Linear Convergence of Natural Policy Gradient Methods with Log-Linear Policies
平均分:5.33 标准差:0.47 评分:6, 5, 5
142.Nearly Minimax Optimal Offline Reinforcement Learning with Linear Function Approximation: Single-Agent MDP and Markov Game
平均分:5.33 标准差:0.47 评分:5, 5, 6
143.Learning Representations for Reinforcement Learning with Hierarchical Forward Models
平均分:5.25 标准差:1.30 评分:3, 6, 6, 6
144.Theoretical Study of Provably Efficient Offline Reinforcement Learning with Trajectory-Wise Reward
平均分:5.25 标准差:0.43 评分:6, 5, 5, 5
145.When is Offline Hyperparameter Selection Feasible for Reinforcement Learning?
平均分:5.25 标准差:0.43 评分:5, 5, 5, 6
146.Model-free Reinforcement Learning that Transfers Using Random Reward Features
平均分:5.25 标准差:1.79 评分:5, 3, 5, 8
147.Joint-Predictive Representations for Multi-Agent Reinforcement Learning
平均分:5.25 标准差:1.30 评分:6, 6, 6, 3
148.Memory-Efficient Reinforcement Learning with Priority based on Surprise and On-policyness
平均分:5.25 标准差:1.79 评分:5, 5, 8, 3
149.Provably Efficient Lifelong Reinforcement Learning with Linear Representation
平均分:5.25 标准差:0.43 评分:6, 5, 5, 5
150.Variational Latent Branching Model for Off-Policy Evaluation
平均分:5.25 标准差:0.43 评分:5, 5, 5, 6
151.On the Geometry of Reinforcement Learning in Continuous State and Action Spaces
平均分:5.25 标准差:0.43 评分:6, 5, 5, 5
152.CAMA: A New Framework for Safe Multi-Agent Reinforcement Learning Using Constraint Augmentation
平均分:5.25 标准差:0.43 评分:5, 5, 5, 6
153.Improving Deep Policy Gradients with Value Function Search
平均分:5.25 标准差:0.43 评分:5, 5, 6, 5
154.DPMAC: Differentially Private Communication for Cooperative Multi-Agent Reinforcement Learning
平均分:5.25 标准差:0.43 评分:5, 5, 6, 5
155.Memory Gym: Partially Observable Challenges to Memory-Based Agents
平均分:5.25 标准差:1.79 评分:5, 8, 5, 3
156.RPM: Generalizable Behaviors for Multi-Agent Reinforcement Learning
平均分:5.25 标准差:0.43 评分:5, 5, 6, 5
157.Unravel Structured Heterogeneity of Tasks in Meta-Reinforcement Learning via Exploratory Clustering
平均分:5.25 标准差:0.43 评分:6, 5, 5, 5
158.The Impact of Approximation Errors on Warm-Start Reinforcement Learning: A Finite-time Analysis
平均分:5.25 标准差:1.30 评分:6, 6, 3, 6
159.Correcting Data Distribution Mismatch in Offline Meta-Reinforcement Learning with Few-Shot Online Adaptation
平均分:5.25 标准差:0.43 评分:5, 5, 6, 5
160.Entity Divider with Language Grounding in Multi-Agent Reinforcement Learning
平均分:5.25 标准差:1.30 评分:6, 6, 6, 3
161.Revisiting Higher-Order Gradient Methods for Multi-Agent Reinforcement Learning
平均分:5.25 标准差:0.43 评分:5, 5, 6, 5
162.Beyond Reward: Offline Preference-guided Policy Optimization
平均分:5.00 标准差:2.12 评分:8, 3, 3, 6
163.Offline Reinforcement Learning via Weighted $f$-divergence
平均分:5.00 标准差:0.00 评分:5, 5, 5, 5
164.Stateful Active Facilitator: Coordination and Environmental Heterogeneity in Cooperative Multi-Agent Reinforcement Learning
平均分:5.00 标准差:1.22 评分:6, 5, 3, 6
165.ORCA: Interpreting Prompted Language Models via Locating Supporting Evidence in the Ocean of Pretraining Data
平均分:5.00 标准差:1.22 评分:3, 6, 6, 5
166.Minimal Value-Equivalent Partial Models for Scalable and Robust Planning in Lifelong Reinforcement Learning
平均分:5.00 标准差:1.22 评分:3, 6, 6, 5
167.Feasible Adversarial Robust Reinforcement Learning for Underspecified Environments
平均分:5.00 标准差:2.12 评分:3, 3, 6, 8
168.Blessing from Experts: Super Reinforcement Learning in Confounded Environments
平均分:5.00 标准差:1.41 评分:6, 6, 3
169.PALM: Preference-based Adversarial Manipulation against Deep Reinforcement Learning
平均分:5.00 标准差:1.10 评分:6, 5, 3, 6, 5
170.Optimistic Exploration with Learned Features Provably Solves Markov Decision Processes with Neural Dynamics
平均分:5.00 标准差:1.41 评分:3, 6, 6
171.Offline Reinforcement Learning via High-Fidelity Generative Behavior Modeling
平均分:5.00 标准差:0.00 评分:5, 5, 5
172.Q-learning Decision Transformer: Leveraging Dynamic Programming for Conditional Sequence Modelling in Offline RL
平均分:5.00 标准差:1.41 评分:3, 6, 6
173.When Data Geometry Meets Deep Function: Generalizing Offline Reinforcement Learning
平均分:5.00 标准差:1.22 评分:6, 6, 5, 3
174.Energy-based Predictive Representation for Reinforcement Learning
平均分:5.00 标准差:2.12 评分:3, 6, 8, 3
175.Skill-Based Reinforcement Learning with Intrinsic Reward Matching
平均分:5.00 标准差:1.22 评分:3, 6, 6, 5
176.Scaling Laws for a Multi-Agent Reinforcement Learning Model
平均分:5.00 标准差:1.22 评分:6, 6, 3, 5
177.Population-Based Reinforcement Learning for Combinatorial Optimization Problems
平均分:5.00 标准差:0.00 评分:5, 5, 5
178.Centralized Training with Hybrid Execution in Multi-Agent Reinforcement Learning
平均分:5.00 标准差:0.00 评分:5, 5, 5, 5
179.On the Importance of the Policy Structure in Offline Reinforcement Learning
平均分:5.00 标准差:1.22 评分:6, 3, 6, 5
180.Finite-time Analysis of Single-timescale Actor-Critic on Linear Quadratic Regulator
平均分:5.00 标准差:1.41 评分:6, 6, 3
181.Offline Reinforcement Learning with Differential Privacy
平均分:5.00 标准差:1.41 评分:6, 6, 3
182.In-Context Policy Iteration
平均分:5.00 标准差:1.22 评分:6, 5, 3, 6
183.Multi-Agent Policy Transfer via Task Relationship Modeling
平均分:5.00 标准差:1.22 评分:5, 6, 3, 6
184.Reinforcement learning for instance segmentation with high-level priors
平均分:5.00 标准差:0.00 评分:5, 5, 5
185.Online Policy Optimization for Robust MDP
平均分:5.00 标准差:1.22 评分:3, 6, 5, 6
186.Revisiting Domain Randomization Via Relaxed State-Adversarial Policy Optimization
平均分:5.00 标准差:1.22 评分:6, 6, 3, 5
187.Multi-Agent Sequential Decision-Making via Communication
平均分:5.00 标准差:1.22 评分:6, 6, 3, 5
188.Highway Reinforcement Learning
平均分:5.00 标准差:1.22 评分:6, 3, 6, 5
189.Critic Sequential Monte Carlo
平均分:5.00 标准差:1.22 评分:6, 5, 3, 6
190.Mutual Information Regularized Offline Reinforcement Learning
平均分:5.00 标准差:1.22 评分:3, 5, 6, 6
191.Curiosity-Driven Unsupervised Data Collection for Offline Reinforcement Learning
平均分:5.00 标准差:1.22 评分:6, 5, 6, 3
192.Provable Benefits of Representational Transfer in Reinforcement Learning
平均分:5.00 标准差:1.41 评分:6, 3, 6
193.Bidirectional Learning for Offline Model-based Biological Sequence Design
平均分:5.00 标准差:0.00 评分:5, 5, 5
194.Multi-User Reinforcement Learning with Low Rank Rewards
平均分:5.00 标准差:1.10 评分:3, 5, 5, 6, 6
195.Actor-Critic Alignment for Offline-to-Online Reinforcement Learning
平均分:4.80 标准差:0.98 评分:5, 5, 3, 5, 6
196.Evaluating Robustness of Cooperative MARL: A Model-based Approach
平均分:4.80 标准差:0.98 评分:3, 5, 5, 5, 6
197.Entropy-Regularized Model-Based Offline Reinforcement Learning
平均分:4.80 标准差:0.98 评分:6, 3, 5, 5, 5
198.Supervised Q-Learning can be a Strong Baseline for Continuous Control
平均分:4.75 标准差:1.09 评分:5, 6, 3, 5
199.Self-Supervised Off-Policy Ranking via Crowd Layer
平均分:4.75 标准差:1.09 评分:6, 3, 5, 5
200.When and Why Is Pretraining Object-Centric Representations Good for Reinforcement Learning?
平均分:4.75 标准差:1.09 评分:3, 6, 5, 5
201.Multi-Agent Reinforcement Learning with Shared Resources for Inventory Management
平均分:4.75 标准差:1.09 评分:5, 3, 6, 5
202.Pre-Training for Robots: Leveraging Diverse Multitask Data via Offline Reinforcement Learning
平均分:4.75 标准差:1.09 评分:5, 5, 6, 3
203.AsymQ: Asymmetric Q-loss to mitigate overestimation bias in off-policy reinforcement learning
平均分:4.75 标准差:2.05 评分:5, 3, 8, 3
204.Effective Offline Reinforcement Learning via Conservative State Value Estimation
平均分:4.75 标准差:2.05 评分:8, 3, 5, 3
205.$epsilon$-Invariant Hierarchical Reinforcement Learning for Building Generalizable Policy
平均分:4.75 标准差:1.09 评分:5, 5, 6, 3
206.SDAC: Efficient Safe Reinforcement Learning with Low-Biased Distributional Actor-Critic
平均分:4.75 标准差:1.09 评分:5, 3, 5, 6
207.Offline RL of the Underlying MDP from Heterogeneous Data Sources
平均分:4.75 标准差:1.09 评分:3, 5, 6, 5
208.Improved Sample Complexity for Reward-free Reinforcement Learning under Low-rank MDPs
平均分:4.75 标准差:1.09 评分:6, 3, 5, 5
209.Uncertainty-Driven Exploration for Generalization in Reinforcement Learning
平均分:4.75 标准差:1.09 评分:3, 5, 6, 5
210.Collaborative Symmetricity Exploitation for Offline Learning of Hardware Design Solver
平均分:4.75 标准差:1.09 评分:6, 5, 3, 5
211.Policy Expansion for Bridging Offline-to-Online Reinforcement Learning
平均分:4.75 标准差:1.09 评分:5, 3, 6, 5
212.Multi-Agent Multi-Game Entity Transformer
平均分:4.75 标准差:1.09 评分:3, 5, 6, 5
213.Skill Machines: Temporal Logic Composition in Reinforcement Learning
平均分:4.75 标准差:1.09 评分:5, 3, 5, 6
214.Understanding Curriculum Learning in Policy Optimization for Online Combinatorial Optimization
平均分:4.75 标准差:1.09 评分:6, 5, 5, 3
215.Complex-Target-Guided Open-Domain Conversation based on offline reinforcement learning
平均分:4.75 标准差:2.05 评分:5, 8, 3, 3
216.Proximal Curriculum for Reinforcement Learning Agents
平均分:4.75 标准差:1.09 评分:5, 5, 3, 6
217.Curriculum Reinforcement Learning via Morphology-Environment Co-Evolution
平均分:4.75 标准差:1.09 评分:5, 3, 5, 6
218.Deep autoregressive density nets vs neural ensembles for model-based offline reinforcement learning
平均分:4.67 标准差:1.25 评分:5, 6, 3
219.Pseudometric guided online query and update for offline reinforcement learning
平均分:4.67 标准差:1.25 评分:6, 3, 5
220.Provably Efficient Reinforcement Learning for Online Adaptive Influence Maximization
平均分:4.67 标准差:1.25 评分:5, 3, 6
221.Achieving Communication-Efficient Policy Evaluation for Multi-Agent Reinforcement Learning: Local TD-Steps or Batching?
平均分:4.67 标准差:1.25 评分:3, 5, 6
222.Replay Buffer with Local Forgetting for Adaptive Deep Model-Based Reinforcement Learning
平均分:4.67 标准差:1.25 评分:6, 3, 5
223.$ell$Gym: Natural Language Visual Reasoning with Reinforcement Learning
平均分:4.67 标准差:1.25 评分:3, 5, 6
224.Model-Based Decentralized Policy Optimization
平均分:4.67 标准差:1.25 评分:6, 3, 5
225.CRISP: Curriculum inducing Primitive Informed Subgoal Prediction for Hierarchical Reinforcement Learning
平均分:4.67 标准差:1.25 评分:6, 5, 3
226.Safe Reinforcement Learning with Contrastive Risk Prediction
平均分:4.67 标准差:1.25 评分:6, 3, 5
227.Value-Based Membership Inference Attack on Actor-Critic Reinforcement Learning
平均分:4.67 标准差:1.25 评分:5, 6, 3
228.Rule-based policy regularization for reinforcement learning-based building control
平均分:4.67 标准差:1.25 评分:3, 6, 5
229.Semi-Supervised Offline Reinforcement Learning with Action-Free Trajectories
平均分:4.67 标准差:1.25 评分:5, 3, 6
230.Group-oriented Cooperation in Multi-Agent Reinforcement Learning
平均分:4.67 标准差:1.25 评分:3, 6, 5
231.Horizon-Free Reinforcement Learning for Latent Markov Decision Processes
平均分:4.67 标准差:1.25 评分:5, 3, 6
232.Robust Constrained Reinforcement Learning
平均分:4.67 标准差:1.25 评分:3, 5, 6
233.GoBigger: A Scalable Platform for Cooperative-Competitive Multi-Agent Interactive Simulation
平均分:4.67 标准差:1.25 评分:5, 3, 6
234.Simultaneously Learning Stochastic and Adversarial Markov Decision Process with Linear Function Approximation
平均分:4.67 标准差:1.25 评分:5, 6, 3
235.A Mutual Information Duality Algorithm for Multi-Agent Specialization
平均分:4.62 标准差:1.32 评分:3, 3, 5, 6, 6, 3, 6, 5
236.Linear convergence for natural policy gradient with log-linear policy parametrization
平均分:4.60 标准差:0.80 评分:5, 5, 5, 5, 3
237.Distributionally Robust Model-Based Offline Reinforcement Learning with Near-Optimal Sample Complexity
平均分:4.60 标准差:1.36 评分:3, 6, 3, 6, 5
238.QFuture: Learning Future Expectations in Multi-Agent Reinforcement Learning
平均分:4.60 标准差:1.36 评分:6, 3, 6, 3, 5
239.Optimistic Exploration in Reinforcement Learning Using Symbolic Model Estimates
平均分:4.50 标准差:1.50 评分:6, 3, 3, 6
240.ConserWeightive Behavioral Cloning for Reliable Offline Reinforcement Learning
平均分:4.50 标准差:0.87 评分:5, 5, 3, 5
241.A Simple Approach for State-Action Abstraction using a Learned MDP Homomorphism
平均分:4.50 标准差:1.50 评分:6, 3, 3, 6
242.MARLlib: Extending RLlib for Multi-agent Reinforcement Learning
平均分:4.50 标准差:0.87 评分:5, 3, 5, 5
243.Toward Effective Deep Reinforcement Learning for 3D Robotic Manipulation: End-to-End Learning from Multimodal Raw Sensory Data
平均分:4.50 标准差:0.87 评分:5, 3, 5, 5
244.Deep Transformer Q-Networks for Partially Observable Reinforcement Learning
平均分:4.50 标准差:2.06 评分:6, 6, 5, 1
245.Best Possible Q-Learning
平均分:4.50 标准差:1.50 评分:3, 6, 6, 3
246.Fairness-Aware Model-Based Multi-Agent Reinforcement Learning for Traffic Signal Control
平均分:4.50 标准差:0.87 评分:5, 5, 5, 3
247.A Risk-Averse Equilibrium for Multi-Agent Systems
平均分:4.50 标准差:1.50 评分:6, 3, 6, 3
248.Visual Reinforcement Learning with Self-Supervised 3D Representations
平均分:4.50 标准差:1.50 评分:6, 6, 3, 3
249.PRUDEX-Compass: Towards Systematic Evaluation of Reinforcement Learning in Financial Markets
平均分:4.50 标准差:2.69 评分:1, 3, 8, 6
250.Light-weight probing of unsupervised representations for Reinforcement Learning
平均分:4.50 标准差:1.50 评分:6, 3, 3, 6
251.Contextual Symbolic Policy For Meta-Reinforcement Learning
平均分:4.50 标准差:0.87 评分:5, 3, 5, 5
252.Behavior Proximal Policy Optimization
平均分:4.40 标准差:1.20 评分:5, 3, 6, 5, 3
253.Deep Reinforcement Learning based Insight Selection Policy
平均分:4.33 标准差:0.94 评分:5, 3, 5
254.MAD for Robust Reinforcement Learning in Machine Translation
平均分:4.33 标准差:0.94 评分:3, 5, 5
255.Hierarchical Prototypes for Unsupervised Dynamics Generalization in Model-Based Reinforcement Learning
平均分:4.33 标准差:0.94 评分:3, 5, 5
256.Lightweight Uncertainty for Offline Reinforcement Learning via Bayesian Posterior
平均分:4.33 标准差:0.94 评分:5, 5, 3
257.Provable Unsupervised Data Sharing for Offline Reinforcement Learning
平均分:4.33 标准差:0.94 评分:5, 5, 3
258.Implicit Offline Reinforcement Learning via Supervised Learning
平均分:4.33 标准差:0.94 评分:5, 5, 3
259.The guide and the explorer: smart agents for resource-limited iterated batch reinforcement learning
平均分:4.25 标准差:1.30 评分:6, 5, 3, 3
260.Protein Sequence Design in a Latent Space via Model-based Reinforcement Learning
平均分:4.25 标准差:2.17 评分:3, 3, 3, 8
261.Reinforcement Learning for Bandits with Continuous Actions and Large Context Spaces
平均分:4.25 标准差:1.30 评分:5, 3, 3, 6
262.How to Enable Uncertainty Estimation in Proximal Policy Optimization
平均分:4.25 标准差:1.30 评分:3, 5, 6, 3
263.Training Equilibria in Reinforcement Learning
平均分:4.25 标准差:1.30 评分:5, 6, 3, 3
264.Contextual Transformer for Offline Reinforcement Learning
平均分:4.25 标准差:1.30 评分:5, 3, 3, 6
265.DROP: Conservative Model-based Optimization for Offline Reinforcement Learning
平均分:4.25 标准差:1.30 评分:3, 5, 3, 6
266.Oracles and Followers: Stackelberg Equilibria in Deep Multi-Agent Reinforcement Learning
平均分:4.25 标准差:1.30 评分:6, 3, 5, 3
267.A Reinforcement Learning Approach to Estimating Long-term Treatment Effects
平均分:4.25 标准差:1.30 评分:6, 3, 3, 5
268.MERMADE: $K$-shot Robust Adaptive Mechanism Design via Model-Based Meta-Learning
平均分:4.25 标准差:1.30 评分:3, 5, 3, 6
269.Multitask Reinforcement Learning by Optimizing Neural Pathways
平均分:4.25 标准差:1.30 评分:3, 5, 6, 3
270.learning hierarchical multi-agent cooperation with long short-term intention
平均分:4.25 标准差:1.30 评分:6, 3, 3, 5
271.Towards A Unified Policy Abstraction Theory and Representation Learning Approach in Markov Decision Processes
平均分:4.25 标准差:1.30 评分:3, 6, 3, 5
272.Diagnosing and exploiting the computational demands of videos games for deep reinforcement learning
平均分:4.25 标准差:1.30 评分:5, 3, 3, 6
273.Uncertainty-based Multi-Task Data Sharing for Offline Reinforcement Learning
平均分:4.25 标准差:1.30 评分:3, 3, 6, 5
274.Holding Monotonic Improvement and Generality for Multi-Agent Proximal Policy Optimization
平均分:4.25 标准差:2.17 评分:3, 3, 8, 3
275.Accelerating Inverse Reinforcement Learning with Expert Bootstrapping
平均分:4.25 标准差:1.30 评分:3, 3, 6, 5
276.DCE: Offline Reinforcement Learning With Double Conservative Estimates
平均分:4.25 标准差:1.30 评分:3, 5, 3, 6
277.Hedge Your Actions: Flexible Reinforcement Learning for Complex Action Spaces
平均分:4.25 标准差:2.59 评分:1, 3, 5, 8
278.Breaking Large Language Model-based Code Generation
平均分:4.00 标准差:1.41 评分:3, 6, 3
279.Dynamics Model Based Adversarial Training For Competitive Reinforcement Learning
平均分:4.00 标准差:1.00 评分:5, 3, 3, 5
280.Just Avoid Robust Inaccuracy: Boosting Robustness Without Sacrificing Accuracy
平均分:4.00 标准差:1.41 评分:3, 6, 3
281.Stein Variational Goal Generation for adaptive Exploration in Multi-Goal Reinforcement Learning
平均分:4.00 标准差:1.00 评分:5, 3, 3, 5
282.SeKron: A Decomposition Method Supporting Many Factorization Structures
平均分:4.00 标准差:2.16 评分:1, 6, 5
283.Reinforcement Learning using a Molecular Fragment Based Approach for Reaction Discovery
平均分:4.00 标准差:1.26 评分:3, 3, 3, 6, 5
284.Pessimistic Policy Iteration for Offline Reinforcement Learning
平均分:4.00 标准差:1.26 评分:3, 6, 3, 3, 5
285.Prototypical Context-aware Dynamics Generalization for High-dimensional Model-based Reinforcement Learning
平均分:4.00 标准差:1.00 评分:3, 3, 5, 5
286.Test-Time AutoEval with Supporting Self-supervision
平均分:4.00 标准差:1.00 评分:5, 3, 3, 5
287.MA2QL: A Minimalist Approach to Fully Decentralized Multi-Agent Reinforcement Learning
平均分:4.00 标准差:1.00 评分:5, 3, 5, 3
288.DYNAMIC ENSEMBLE FOR PROBABILISTIC TIME- SERIES FORECASTING VIA DEEP REINFORCEMENT LEARNING
平均分:4.00 标准差:1.00 评分:5, 3, 5, 3
289.Towards Solving Industrial Sequential Decision-making Tasks under Near-predictable Dynamics via Reinforcement Learning: an Implicit Corrective Value Estimation Approach
平均分:4.00 标准差:1.00 评分:3, 3, 5, 5
290.Taming Policy Constrained Offline Reinforcement Learning for Non-expert Demonstrations
平均分:4.00 标准差:1.00 评分:5, 5, 3, 3
291.SpeedyZero: Mastering Atari with Limited Data and Time
平均分:4.00 标准差:1.41 评分:3, 3, 6
292.On Convergence of Average-Reward Off-Policy Control Algorithms in Weakly-Communicating MDPs
平均分:4.00 标准差:1.41 评分:6, 3, 3
293.Robust Reinforcement Learning with Distributional Risk-averse formulation
平均分:4.00 标准差:1.00 评分:3, 5, 5, 3
294.Model-based Value Exploration in Actor-critic Deep Reinforcement Learning
平均分:4.00 标准差:1.00 评分:5, 5, 3, 3
295.Neural Discrete Reinforcement Learning
平均分:4.00 标准差:1.00 评分:5, 3, 3, 5
296.Constrained Reinforcement Learning for Safety-Critical Tasks via Scenario-Based Programming
平均分:4.00 标准差:1.41 评分:3, 3, 6
297.Planning Immediate Landmarks of Targets for Model-Free Skill Transfer across Agents
平均分:4.00 标准差:1.00 评分:5, 3, 5, 3
298.Accelerating Federated Learning Convergence via Opportunistic Mobile Relaying
平均分:4.00 标准差:1.41 评分:6, 3, 3
299.Distributional Reinforcement Learning via Sinkhorn Iterations
平均分:4.00 标准差:1.00 评分:3, 5, 3, 5
300.Never Revisit: Continuous Exploration in Multi-Agent Reinforcement Learning
平均分:4.00 标准差:1.00 评分:3, 5, 5, 3
301.Knowledge-Grounded Reinforcement Learning
平均分:3.80 标准差:0.98 评分:3, 3, 5, 5, 3
302.Thresholded Lexicographic Ordered Multi-Objective Reinforcement Learning
平均分:3.75 标准差:1.30 评分:3, 3, 3, 6
303.Model-based Unknown Input Estimation via Partially Observable Markov Decision Processes
平均分:3.75 标准差:1.92 评分:5, 1, 6, 3
304.Finding the smallest tree in the forest: Monte Carlo Forest Search for UNSAT solving
平均分:3.75 标准差:1.30 评分:3, 3, 6, 3
305.Predictive Coding with Approximate Laplace Monte Carlo
平均分:3.75 标准差:1.30 评分:3, 6, 3, 3
306.CASA: Bridging the Gap between Policy Improvement and Policy Evaluation with Conflict Averse Policy Iteration
平均分:3.75 标准差:1.30 评分:3, 3, 3, 6
307.Unleashing the Potential of Data Sharing in Ensemble Deep Reinforcement Learning
平均分:3.75 标准差:1.92 评分:3, 5, 6, 1
308.Safer Reinforcement Learning with Counterexample-guided Offline Training
平均分:3.75 标准差:1.30 评分:3, 3, 3, 6
309.System Identification as a Reinforcement Learning Problem
平均分:3.75 标准差:1.92 评分:5, 3, 1, 6
310.Projected Latent Distillation for Data-Agnostic Consolidation in Multi-Agent Continual Learning
平均分:3.75 标准差:1.30 评分:3, 3, 6, 3
311.Inapplicable Actions Learning for Knowledge Transfer in Reinforcement Learning
平均分:3.75 标准差:1.30 评分:3, 6, 3, 3
312.RegQ: Convergent Q-Learning with Linear Function Approximation using Regularization
平均分:3.75 标准差:1.92 评分:3, 1, 5, 6
313.Learning parsimonious dynamics for generalization in reinforcement learning
平均分:3.67 标准差:0.94 评分:5, 3, 3
314.Domain Invariant Q-Learning for model-free robust continuous control under visual distractions
平均分:3.67 标准差:0.94 评分:3, 3, 5
315.Automatic Curriculum Generation for Reinforcement Learning in Zero-Sum Games
平均分:3.67 标准差:0.94 评分:5, 3, 3
316.Few-shot Lifelong Reinforcement Learning with Generalization Guarantees: An Empirical PAC-Bayes Approach
平均分:3.67 标准差:0.94 评分:3, 3, 5
317.Cyclophobic Reinforcement Learning
平均分:3.67 标准差:0.94 评分:3, 3, 5
318.ACQL: An Adaptive Conservative Q-Learning Framework for Offline Reinforcement Learning
平均分:3.67 标准差:0.94 评分:5, 3, 3
319.Multi-Source Transfer Learning for Deep Model-Based Reinforcement Learning
平均分:3.67 标准差:0.94 评分:3, 3, 5
320.Continuous Monte Carlo Graph Search
平均分:3.67 标准差:0.94 评分:3, 3, 5
321.Robust Multi-Agent Reinforcement Learning against Adversaries on Observation
平均分:3.67 标准差:0.94 评分:5, 3, 3
322.Variance Double-Down: The Small Batch Size Anomaly in Multistep Deep Reinforcement Learning
平均分:3.67 标准差:0.94 评分:5, 3, 3
323.Stationary Deep Reinforcement Learning with Quantum K-spin Hamiltonian Equation
平均分:3.67 标准差:0.94 评分:3, 3, 5
324.Solving Partial Label Learning Problem with Multi-Agent Reinforcement Learning
平均分:3.67 标准差:0.94 评分:5, 3, 3
325.Efficient Reward Poisoning Attacks on Online Deep Reinforcement Learning
平均分:3.67 标准差:0.94 评分:3, 5, 3
326.Dual Ensembled Multiagent Q-Learning with Hypernet Regularizer
平均分:3.67 标准差:0.94 评分:3, 3, 5
327.Partial Advantage Estimator for Proximal Policy Optimization
平均分:3.67 标准差:0.94 评分:3, 5, 3
328.Offline Model-Based Reinforcement Learning with Causal Structure
平均分:3.67 标准差:0.94 评分:3, 5, 3
329.How Does Value Distribution in Distributional Reinforcement Learning Help Optimization?
平均分:3.67 标准差:0.94 评分:3, 5, 3
330.Very Large Scale Multi-Agent Reinforcement Learning with Graph Attention Mean Field
平均分:3.67 标准差:0.94 评分:3, 5, 3
331.Efficient Multi-Task Reinforcement Learning via Selective Behavior Sharing
平均分:3.67 标准差:0.94 评分:3, 5, 3
332.RISC-V MICROARCHITECTURE EXPLORATION VIA REINFORCEMENT LEARNING
平均分:3.50 标准差:0.87 评分:3, 3, 3, 5
333.Opportunistic Actor-Critic (OPAC) with Clipped Triple Q-learning
平均分:3.50 标准差:0.87 评分:5, 3, 3, 3
334.MaxMin-Novelty: Maximizing Novelty via Minimizing the State-Action Values in Deep Reinforcement Learning
平均分:3.50 标准差:1.66 评分:1, 3, 5, 5
335.Efficient Exploration using Model-Based Quality-Diversity with Gradients
平均分:3.50 标准差:0.87 评分:3, 3, 5, 3
336.Guided Safe Shooting: model based reinforcement learning with safety constraints
平均分:3.50 标准差:0.87 评分:3, 3, 5, 3
337.Consciousness-Aware Multi-Agent Reinforcement Learning
平均分:3.50 标准差:1.66 评分:1, 5, 3, 5
338.A Deep Reinforcement Learning Approach for Finding Non-Exploitable Strategies in Two-Player Atari Games
平均分:3.50 标准差:1.66 评分:1, 5, 5, 3
339.Backdoors Stuck At The Frontdoor: Multi-Agent Backdoor Attacks That Backfire
平均分:3.50 标准差:1.66 评分:1, 5, 5, 3
340.Planning With Uncertainty: Deep Exploration in Model-Based Reinforcement Learning
平均分:3.50 标准差:0.87 评分:3, 3, 3, 5
341.Deep Reinforcement learning on Adaptive Pairwise Critic and Asymptotic Actor
平均分:3.50 标准差:0.87 评分:3, 5, 3, 3
342.Towards Generalized Combinatorial Solvers via Reward Adjustment Policy Optimization
平均分:3.50 标准差:1.66 评分:1, 3, 5, 5
343.Explainability of deep reinforcement learning algorithms in robotic domains by using Layer-wise Relevance Propagation
平均分:3.50 标准差:0.87 评分:3, 5, 3, 3
344.Latent Offline Distributional Actor-Critic
平均分:3.50 标准差:0.87 评分:5, 3, 3, 3
345.Interpreting Distributional Reinforcement Learning: A Regularization Perspective
平均分:3.50 标准差:0.87 评分:3, 3, 3, 5
346.Convergence Rate of Primal-Dual Approach to Constrained Reinforcement Learning with Softmax Policy
平均分:3.25 标准差:1.79 评分:6, 3, 1, 3
347.Probe Into Multi-agent Adversarial Reinforcement Learning through Mean-Field Optimal Control
平均分:3.00 标准差:1.41 评分:3, 1, 5, 3
348.LEARNING DYNAMIC ABSTRACT REPRESENTATIONS FOR SAMPLE-EFFICIENT REINFORCEMENT LEARNING
平均分:3.00 标准差:0.00 评分:3, 3, 3
349.Domain Transfer with Large Dynamics Shift in Offline Reinforcement Learning
平均分:3.00 标准差:0.00 评分:3, 3, 3
350.Pessimistic Model-Based Actor-Critic for Offline Reinforcement Learning: Theory and Algorithms
平均分:3.00 标准差:0.00 评分:3, 3, 3, 3
351.Robust Policy Optimization in Deep Reinforcement Learning
平均分:3.00 标准差:0.00 评分:3, 3, 3, 3
352.Advantage Constrained Proximal Policy Optimization in Multi-Agent Reinforcement Learning
平均分:3.00 标准差:0.00 评分:3, 3, 3, 3
353.Revealing Dominant Eigendirections via Spectral Non-Robustness Analysis in the Deep Reinforcement Learning Policy Manifold
平均分:3.00 标准差:0.00 评分:3, 3, 3, 3, 3
354.Reducing Communication Entropy in Multi-Agent Reinforcement Learning
平均分:3.00 标准差:0.00 评分:3, 3, 3, 3
355.Physics Model-based Autoencoding for Magnetic Resonance Fingerprinting
平均分:3.00 标准差:0.00 评分:3, 3, 3, 3
356.Comparing Auxiliary Tasks for Learning Representations for Reinforcement Learning
平均分:3.00 标准差:0.00 评分:3, 3, 3, 3
357.Decentralized Policy Optimization
平均分:3.00 标准差:0.00 评分:3, 3, 3
358.Coordinated Strategy Identification Multi-Agent Reinforcement Learning
平均分:3.00 标准差:0.00 评分:3, 3, 3
359.Pretraining the Vision Transformer using self-supervised methods for vision based Deep Reinforcement Learning
平均分:3.00 标准差:0.00 评分:3, 3, 3, 3, 3
360.Bi-Level Dynamic Parameter Sharing among Individuals and Teams for Promoting Collaborations in Multi-Agent Reinforcement Learning
平均分:3.00 标准差:0.00 评分:3, 3, 3, 3
361.Incorporating Explicit Uncertainty Estimates into Deep Offline Reinforcement Learning
平均分:3.00 标准差:0.00 评分:3, 3, 3
362.Deep Reinforcement Learning for Cryptocurrency Trading: Practical Approach to Address Backtest Overfitting
平均分:3.00 标准差:0.00 评分:3, 3, 3
363.Coupling Semi-supervised Learning with Reinforcement Learning for Better Decision Making -- An application to Cryo-EM Data Collection
平均分:3.00 标准差:0.00 评分:3, 3, 3
364.Farsighter: Efficient Multi-step Exploration for Deep Reinforcement Learning
平均分:2.50 标准差:0.87 评分:3, 3, 3, 1
365.Skill Graph for Real-world Quadrupedal Robot Reinforcement Learning
平均分:2.50 标准差:0.87 评分:3, 3, 1, 3
366.A sampling framework for value-based reinforcement learning
平均分:2.50 标准差:0.87 评分:1, 3, 3, 3
367.Go-Explore with a guide: Speeding up search in sparse reward settings with goal-directed intrinsic rewards
平均分:2.50 标准差:0.87 评分:1, 3, 3, 3
368.MCTransformer: Combining Transformers And Monte-Carlo Tree Search For Offline Reinforcement Learning
平均分:2.33 标准差:0.94 评分:3, 1, 3
369.Personalized Federated Hypernetworks for Privacy Preservation in Multi-Task Reinforcement Learning
平均分:2.33 标准差:0.94 评分:3, 3, 1
370.Emergence of Exploration in Policy Gradient Reinforcement Learning via Resetting
平均分:2.00 标准差:1.00 评分:1, 3, 1, 3
371.Online Reinforcement Learning via Posterior Sampling of Policy
平均分:2.00 标准差:1.00 评分:1, 1, 3, 3
372.Co-Evolution As More Than a Scalable Alternative for Multi-Agent Reinforcement Learning
平均分:2.00 标准差:1.00 评分:3, 3, 1, 1
373.State Decomposition for Model-free Partially observable Markov Decision Process
平均分:1.50 标准差:0.87 评分:1, 3, 1, 1
374.Speeding up Policy Optimization with Vanishing Hypothesis and Variable Mini-Batch Size
平均分:1.50 标准差:0.87 评分:1, 1, 1, 3
375.Quantum reinforcement learning
平均分:1.00 标准差:0.00 评分:1, 1, 1, 1
376.Manipulating Multi-agent Navigation Task via Emergent Communications
平均分:1.00 标准差:0.00 评分:1, 1, 1
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“强化学习” 就可以获取《强化学习专知资料合集》专知下载链接





