每日三篇 | Kaggle数据科学术语大全;机器学习特征数据库;单机大数据处理
Kaggle数据科学术语大全
数据科学有太多算法和概念需要学习,Kaggle上有大量资源(超过20万Kaggle Kernel)。数据科学家Shivam Bansal整理了一份详尽的列表,囊括了Kaggle上的众多优质资源:回归、正则化、基于决策树的模型、神经网络和深度学习、聚类、朴素贝叶斯、SVM、K近邻、推荐引擎、预处理、降维、后建模、集成、文本处理、工具、可视化、时序,等等。
地址: https://www.kaggle.com/shivamb/data-science-glossary-on-kaggle-updated
EuclidesDB多模态机器学习特征嵌入数据库
多模态机器学习特征嵌入数据库EuclidesDB最近发布了0.2.0版。EuclidesDB提供了一个后端,供查询模型特征空间中的数据。EuclidesDB使用C++编写,基于protobuf实现数据序列化,基于gRPC通讯,深度支持PyTorch,实现了Annoy、Faiss等多种索引方法。
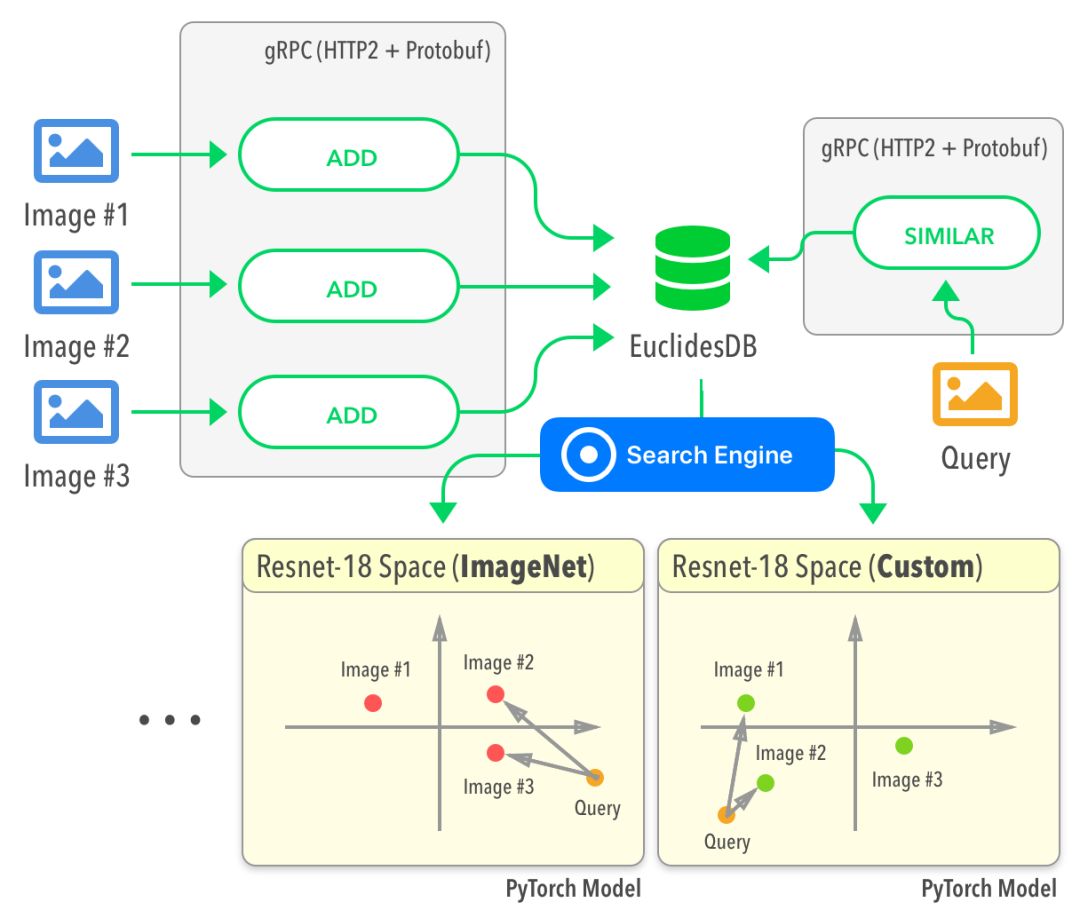
地址: https://euclidesdb.readthedocs.io/
Python for big data computation on a single computer
在日常电脑上进行大数据处理并非遥不可及。Turi Create这一优秀的Python库为此提供了便利的高层抽象。Turi Create使用SFrame作为基本数据结构。SFrame和Pandas的DataFrame很像,但支持核外计算。如果你的电脑配备了SSD,那么使用Turi Create在单台日常电脑上处理中等规模的数据集(100GB)效率不低。Yuxi Global数据分析主管Mateo Restrepo的这篇教程简明扼要地介绍了Turi Create的用法,值得一读。
地址:https://blog.usejournal.com/python-for-big-data-computation-on-a-single-computer-c232046df3c3