AI技术流黑马“出道”,清博AI团队屡获重大赛事奖项

新智元报道
新智元报道
【新智元导读】近日,虚假新闻检测论坛暨2019虚假新闻检测挑战赛颁奖仪式在京举行。清博AI团队夺得此次比赛的第三赛道——多模态(文本+图像)虚假新闻检测赛冠军;本次比赛共有包括微软、腾讯、阿里、华为、武大、中科大等在内的上百支国内外顶尖AI团队参赛。来 新智元AI朋友圈 和AI大咖们一起讨论吧。
近日,虚假新闻检测论坛暨2019虚假新闻检测挑战赛颁奖仪式在北京中科院计算技术研究所举行。清博AI团队在此次比赛的第三赛道——多模态(文本+图像)虚假新闻检测中脱颖而出,获得第一名;本次比赛共有包括微软、腾讯、阿里、华为、YOHO、武大、中科大等在内的上百支国内外顶尖AI团队参赛。

颁奖仪式现场,清博AI团队代表陈生分享了此次比赛的参赛过程:“比赛期间,清博的小伙伴们不断地进行新的尝试和探索,包括搭建不同的模型获取图像和文本、通过数据进行特征、字段的分析,实现特征的拼接与模型的融合。之后,在不断地训练和多角度的特征抽取下,最终实现了线上效果达到99%的f1值。”
清博AI团队提出虚假新闻多模态识别模型,实现线上成绩f1达99%
具体来说,在此次比赛中,清博AI团队提出了GDBT-based-DenseNet-Bert的GDB虚假新闻多模态识别模型,并通过实验证明基于改模型从多模态角度提取比单领域的特征提取效果更好;同时也证明GDB框架识别虚假新闻的优势,最终实现线上的成绩f1达到了99%。具体思路(节选自现场答辩)如下:
1、数据探索与分析
训练样本一共38471条,正负样本比例接近1:1,给出的信息字段包括以下字段。
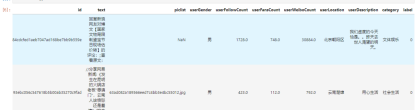
图1.部分信息字段
其中piclist为新闻中嵌入的图片路径,通过cv库可以读取相应的图像文件。通过python对原始特征数据以及构造的特征进行数据分析。
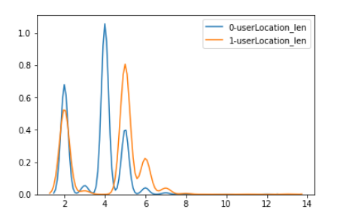
图2.字段长度地域分布差异
图2展示的是正负样本不同地域字段长度上面的分布差异,横坐标表示的是不同的地域,纵坐标表示的是字段长度的大小。
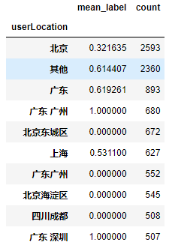
图3.虚假新闻在部分userLocation字段的分布差异
从图中可以看出样本中不同区域发的新闻有偏向,部分地区的多媒体新闻几乎全为假新闻,还有部分地区的多媒体新闻几乎全部为真新闻。
上面展示了部分对比赛数据分析的过程,同理清博AI团队还对其余的字段进行了数据分布上面的探索和分析。这些结构化的原始特征以及构造的相关统计特征,对后面使用GDBT-based模型训练帮助很大。
2、数据预处理
本道赛题的数据预处理主要是针对非结构化数据的text文本数据字段,使用了jieba分词库对text进行了分词,为后面通过词袋模型提取ngram特征做准备。
3、模型部分
多媒体新闻主要包含三类特征,第一类是图像特征,训练数据中含有图片的样本占了80%以上;第二类是文本特征;第三类是多媒体新闻的发布或者转发者的用户信息特征,比如粉丝数目,关注数,用户简介等用户画像特征。根据新闻多种特征信息,清博AI团队提出一种多模态虚假新闻识别模型,结构如下:
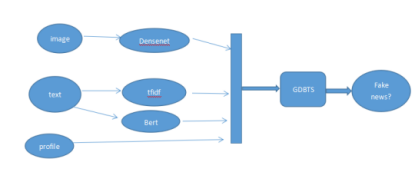
图4.GDB模型框架
在这里清博AI团队使用了GDBT-based的模型,其中针对图像特征,使用densenet121预训练模型的最后一个全连接层的输出作为图像的语义特征。针对text文本字段使用了tfidf提取ngram特征。最后把图像的语义特征,ngram和bert提取的文本特征以及用户画像特征拼接到一起输入GDBT-based模型,进行训练,最终得到一个虚假新闻判断模型。
AI技术流黑马“出道”,清博AI团队屡获大奖

其实,这已经不是清博AI团队第一次在国内外重大AI赛事上崭露头角了。作为AI技术流领域的一匹黑马,清博AI团队今年10月份刚刚斩获了第十八届中国计算语言学大会CCL单项赛事中文幽默计算第一名,在文本分析、情感度识别方面表现出强大的研发能力,获得第二名的是来自华为机器翻译小组的“Huawei MT Squsd”。

再往前,8月29日,在2019世界人工智能大会黑客马拉松(WAIC)AutoNLP大赛上,清博NLP小组以初赛第11名的成绩入围决赛,历经48个小时,在与阿里团队、南京大学团队、两支欧洲队伍、一支韩国队伍、一支日本队伍同场竞技中获胜,并最终取得大赛第三名的好成绩;获得第一的是Deepblue团队,联想研究院团队取得第二名。

封闭式比赛现场
据清博大数据CTO朱旭琪介绍,清博AI团队是一个非常年轻的队伍,组员都是从公司的研发队伍中遴选出来的,以90后为主,平均年龄只有25岁;能屡次在AI重大赛事上取得优异的成绩,一方面是因为清博AI团队本身的开发和应变能力较为突出;另一方面得益于公司80人研发队伍在背后的大力支持。清博大数据研发团队致力于大数据关键技术、核心算法的研究,目前已开展20余个行业大数据的深度研究。

此外,清博研发队伍强大的开发能力还体现在产品方面。依托多维的数据分析、便捷的创新功能,刚刚升级到5.0版本的清博舆情在舆情分析、事件追踪、品牌传播、市场调研等多领域应用方面实现了重大突破,在北京市海淀区委宣传部联合西街传媒、《数据》杂志共同举办的“2019大数据产业十大应用案例”发布会上被评为“2019大数据产业十大应用案例”。
作为新媒体大数据评价体系和影响力标准的研究制定者,清博大数据目前已研发了100余种指数模型,其独有的WCI、BCI、TGI算法公式已成为业界的评价标准。与算法相匹配的是亿量级的数据优势:每日1.2亿条资讯数据、12亿次场景行为数据、6亿个短视频账号数据、3亿社交媒体账号数据……正如清博大数据CTO朱旭琪所指出,“算法和数据的结合优势是清博整个研发队伍努力的成果,同时,也构成了我们不断实现技术突破,取得好成绩的坚实基础。”
寒冬里,这个最酷AI创新平台招人啦!新智元邀你2020勇闯AI之巅
在新智元你可以获得:
-
与国内外一线大咖、行业翘楚面对面交流的机会 -
掌握深耕人工智能领域,成为行业专家 -
远高于同行业的底薪 -
五险一金+月度奖金+项目奖励+年底双薪 -
舒适的办公环境(北京融科资讯中心B座) -
一日三餐、水果零食




