资源 | 价值迭代网络的PyTorch实现与Visdom可视化
选自GitHub
作者:Xingdong Zuo
机器之心编译
参与:吴攀
《价值迭代网络(Value Iteration Networks)》是第 30 届神经信息处理系统大会(NIPS 2016)的最佳论文奖(Best Paper Award)获奖论文,机器之心曾在该论文获奖后第一时间采访了该论文作者之一吴翼(Yi Wu),参见《独家 | 机器之心对话 NIPS 2016 最佳论文作者:如何打造新型强化学习观?(附演讲和论文)》。吴翼在该文章中介绍说:
VIN 的目的主要是解决深度强化学习泛化能力较弱的问题。传统的深度强化学习(比如 deep Q-learning)目标一般是采用神经网络学习一个从状态(state)到决策(action)的直接映射。神经网络往往会记忆一些训练集中出现的场景。所以,即使模型在训练时表现很好,一旦我们换了一个与之前训练时完全不同的场景,传统深度强化学习方法就会表现的比较差。在 VIN 中,我们提出,不光需要利用神经网络学习一个从状态到决策的直接映射,还要让网络学会如何在当前环境下做长远的规划(learn to plan),并利用长远的规划辅助神经网络做出更好的决策。
该研究得到了广泛的关注,在原来 Theano 实现之外也出现了 TensorFlow 等其它版本的实现。近日,GitHub 用户 Xingdong Zuo 又公开发布了一个 PyTorch 的版本和另一个 TensorFlow 版本,机器之心在本文中对前者进行了介绍。
项目地址:
PyTorch 版本:https://github.com/zuoxingdong/VIN_PyTorch_Visdom
TensorFlow 版本:https://github.com/zuoxingdong/VIN_TensorFlow
相关项目地址:
原作者的 Theano 实现:https://github.com/avivt/VIN
TensorFlow 实现:
https://github.com/TheAbhiKumar/tensorflow-value-iteration-networks
原论文地址:https://arxiv.org/abs/1602.02867
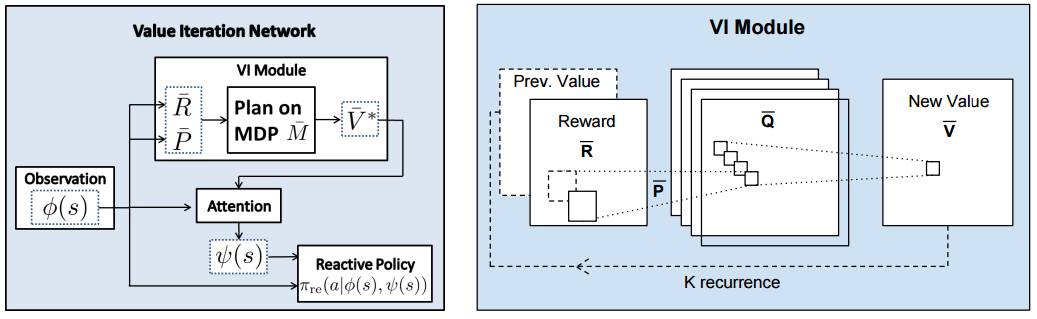
关键想法
一个完全可微分的神经网络,带有一个「规划(planning)」子模块
价值迭代 = 卷积层+面向信道的最大池化(Value Iteration = Conv Layer + Channel-wise Max Pooling)
用于新的未见过的任务时,能比反应策略更好地泛化
学习到的奖励图像(Reward Image)和其每次 VI 迭代时的价值图像(Value Images,访问原项目查看动图)

依赖包
该项目需要以下软件包:
Python >= 3.6
Numpy >= 1.12.1
PyTorch >= 0.1.10
SciPy >= 0.19.0
Visdom >= 0.1
数据集
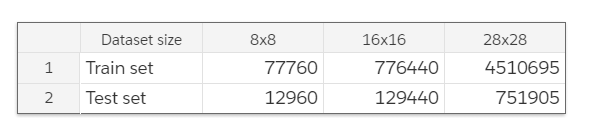
每一个数据样本都由网格世界中当前状态的 (x, y) 坐标构成,后面跟着一张障碍图像(obstacle image)和一张目标图像(goal image)。
运行试验:训练
网格世界 8×8
python run.py --datafile data/gridworld_8x8.npz --imsize 8 --lr 0.005 --epochs 30 --k 10 --batch_size 128
网格世界 16×16
python run.py --datafile data/gridworld_16x16.npz --imsize 16 --lr 0.008 --epochs 30 --k 20 --batch_size 128
网格世界 28×28
python run.py --datafile data/gridworld_28x28.npz --imsize 28 --lr 0.003 --epochs 30 --k 36 --batch_size 128
说明:
datafile:数据文件的路径
imsize:输入图像的尺寸,从 [8, 16, 28] 中选择
lr:使用 RMSProp 优化器的学习率,推荐 [0.01, 0.005, 0.002, 0.001]
epochs:训练的 epoch 数量,默认:30
k:价值迭代(Value Iterations)的数量,推荐 [10 for 8x8, 20 for 16x16, 36 for 28x28]
ch_i:输入层中信道(channel)的数量,默认:2,即障碍图像和目标图像
ch_h:第一层卷积层中信道的数量,默认:50,论文中有描述
ch_q:VI 模块中 q 层(~actions)中的信道数量,默认:10,论文中有描述
batch_size:批大小,默认:128
使用 Visdom 进行可视化
Visdom 地址:https://github.com/facebookresearch/visdom
机器之心介绍 Visdom 的文章:资源 | 挑战谷歌,Facebook 发布交互数据可视化工具 Visdom
我们将使用 Visdom 来为每次 VI 迭代可视化学习到的奖励图像(reward image)及其对应的价值图像(value image)。
首先启动服务器
python -m visdom.server
在浏览器中打开 Visdom:http://localhost:8097
然后运行以下代码来可视化学习的奖励和价值图像:
python vis.py --datafile learned_rewards_values_28x28.npz
注:如果你想自己产生价值图像的 GIF 动画,可使用下面的命令:
convert -delay 20 -loop 0 *.png value_function.gif
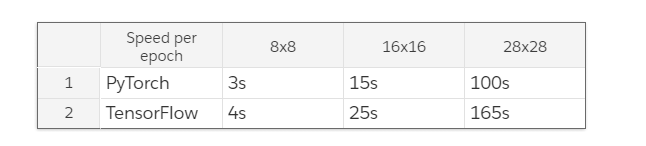
基准
GPU:Titan X
表现:测试精度
注意:这是在测试集上的精度。不同于论文中的表格,其表示了在环境中学习到的策略的 rollout 的成功率。

使用 GPU 的速度
常见问题
问:如何从观察(observation)中获得奖励图像?
答:观察图像有 2 个信道。第一个信道是障碍图像(0:无障碍,1:障碍)。第二个信道是目标图像(0:无目标,10:目标)。比如说,在 8×8 的网格世界中,批大小为 128 的输入张量的形状是 [128, 2, 8, 8]。然后其被馈送到一个带有 [3,3] 滤波器和 150 个特征图卷积层,之后又是另一个带有 [3,3] 滤波器和 1 个特征图的卷积层。输出张量的形状是 [128, 1, 8, 8]。这就是奖励图像。
问:过渡模型(transition model)到底是什么?怎么通过 VI 模块从奖励图像中获取价值图像?
答:让我们假设在 8×8 的网格世界中,批大小为 128。一旦我们获得了形状为 [128, 1, 8, 8] 的奖励图像,那么我们就可以为 VI 模块中的 q 层做卷积层。[3,3] 滤波器表示其过渡概率。存在一个有 10 个滤波器的集合,其中每一个都是为了在 q 层中生成一个特征图。每一个特征图对应于一个「action」。注意这比真实可用的动作(只有 8)大一些。然后我们做一个面向信道的最大池化,以获得形状为 [128, 1, 8, 8] 的价值图像。最后我们将这个价值图像和奖励图像堆叠在一起,以进行新一次的 VI 迭代。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com





