MMEditing:多任务图像视频编辑工具箱
点击蓝字
关注我们



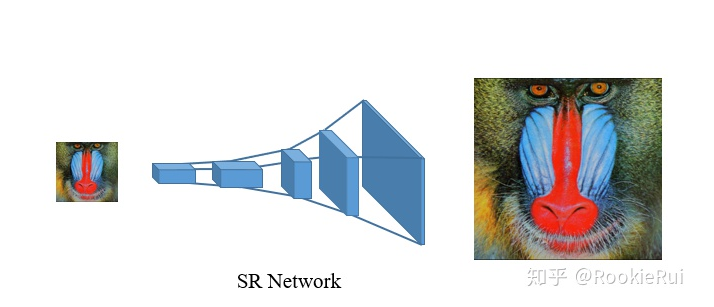
Super-Resolution 超分辨率
Inpainting修复

Matting抠像


Generation生成模型

结语
推荐阅读




登录查看更多
相关内容

专知会员服务
27+阅读 · 2019年8月10日
Arxiv
10+阅读 · 2018年12月4日
Arxiv
5+阅读 · 2018年7月6日



相关VIP内容
专知会员服务
27+阅读 · 2019年8月10日
相关资讯
相关论文
Arxiv
10+阅读 · 2018年12月4日
Arxiv
5+阅读 · 2018年7月6日