LSTM之父发文:2010-2020,我眼中的深度学习十年简史

来源:Jürgen Schmidhuber

作为LSTM发明人、深度学习元老,Jürgen Schmidhuber于2月20日发表了一篇博文,着重介绍了近十年来基于作者研究工作最重要的开发和应用,最后对2020年代进行了展望,也提及到了数据隐私和市场。下面是本篇文章的目录:
第1部分:长短期记忆网络的十年
第2部分:前馈神经网络的十年
第3部分:LSTM和FNN / CNN,LSTM与FNN的对比
第4部分:GAN,基于好奇心产生的技术
第5部分:2010-2020十年其他的热门话题:深度强化学习、元学习、世界模型、蒸馏网络、神经架构搜索、注意力学习、快速权重、自发明问题...
第6部分:数据市场和隐私的未来
第7部分:展望:2010年代与2020年代,虚拟AI还是现实 AI(Real AI)?

长短期记忆网络的十年
在最近十年,大部分AI都是关于长期短期记忆(LSTM)的神经网络。世界本质上是序列性的,而LSTM彻底改变了序列数据处理,例如语音识别、机器翻译、视频识别,联机手写识别、机器人、视频游戏、时间序列预测、聊天机器人、医疗保健应用等。到2019年,LSTM每年获得的引用量超过过去一千年间任何其他计算机科学论文。下面,作者列出了一些最明显的应用。

2009:联机手写识别。作者的博士生亚历克斯·格雷夫斯(Alex Graves)在ICDAR 2009(著名的文档分析和识别会议)上赢得了三项手写体比赛(法语、波斯语、阿拉伯语)。他使用了作者在慕尼黑工业大学和瑞士AILab IDSIA研究小组开发的两种方法的组合:LSTM(1990s-2005)(它克服了我的博士生Sepp Hochreiter [VAN1]分析出的梯度消失问题)和联结主义时间分类法(CTC)(2006年)。采用CTC训练的LSTM是第一个赢得国际比赛的递归神经网络或RNN 。
采用CTC训练的LSTM也是第一台端到端神经语音识别器。早在2007年,我们的团队就已经将CTC-LSTM成功应用于语音,同时也将其应用于分层LSTM堆栈。自1980年代以来,这与以前的混合方法有很大的不同,后者主要是将神经网络和传统方法结合起来,例如隐马尔可夫模型(HMM)。 Alex在多伦多做博后时,都还在一直使用CTC-LSTM。
CTC-LSTM在工业上产生了巨大的影响。到2015年,它大大改善了Google的语音识别。而现在几乎所有智能手机上都有此功能。到2016年,Google数据中心所有这些Tensor处理单元的功能中有四分之一以上都是用于LSTM(其中卷积神经网络使用了5%)。2019年谷歌的语音识别设备(不再在服务器上)仍然是基于LSTM。微软、百度、亚马逊、三星、苹果和许多其他的著名公司也在使用LSTM。
2016年:首个端到端神经机器翻译也是基于LSTM。我的博士生Felix Gers早在2001年就证明LSTM可以学习传统模型(例如HMM)无法学习的语言。也就是说,“亚符号”的神经模型突然擅长学习“符号”任务!这得益于计算硬件的提升,到2016-17年,Google Translate和Facebook Translate都基于两个相连的LSTM,其中一个用于传入文本,一个用于传出翻译的文本。到2017年,基于LSTM,Facebook的用户每周会进行300亿次的翻译。做个对比:最受欢迎的youtube视频(歌曲“ Despacito”)在两年内仅获得了60亿次点击。
基于LSTM的机器人。到2003年,我们的团队将LSTM用于强化学习(RL)和机器人。在2010年代,RL和LSTM的组合已成为标准。例如,在2018年,经过RL训练的LSTM是OpenAI公司Dactyl的核心,该Dactyl学会了在没有老师的情况下控制灵巧的机器 人手臂。
2018-2019年:用于视频游戏的LSTM。在2019年,DeepMind使用RL+LSTM训练的Alphastar,在星际争霸游戏中击败了职业玩家,而该游戏在许多方面比国际象棋都难。采用RL训练的LSTM(占模型总参数的84%)也是OpenAI Five的核心,它在Dota 2电子游戏(2018年)中击败了人类职业玩家。
2010年代出现了许多其他LSTM应用,例如LSTM用于医疗保健、化学分子设计、唇读、股市预测、自动驾驶汽车、将大脑信号映射到语音,预测核聚变反应堆中发生了什么等等。

前馈神经网络的十年
LSTM原则上是一个可以实现笔记本电脑上运行的任何程序的RNN。前馈神经网络(FNN)的限制更多(尽管它们在五子棋、围棋和国际象棋这样的棋盘游戏中足够好)。也就是说,如果我们要构建基于神经网络的人工智能(AGI),则其基础计算必须类似于RNN。FNN从根本上来说还不够。RNN与FNN的关系,就像一般计算机与计算器一样。尽管如此,我们的深度学习十年进展也会涉及FNN,如下阐述。
2010年:深层FNN不需要无监督的预训练。在2009年,许多人认为深层FNN如果没有未经监督的预训练就无法学到很多东西。但是在2010年,我们的团队与我的博士后Dan Ciresan 研究表明,深层FNN可以通过简单的反向传播进行训练,并且完全不需要无监督的预训练。我们的系统在当时著名的图像识别基准MNIST上创下了新的性能记录。这是通过GPU的高度并行图形处理单元上极大地加速传统FNN来实现。审稿人称此为“对机器学习社区的唤醒”。如今,很少有商业的神经网络应用仍是基于无监督的预训练。

2011年:基于CNN的计算机视觉革命。自1970年代以来,我们在瑞士的团队(Dan Ciresan等人)极大地加快了其他人发明和开发的卷积神经网络。2011年创建了第一个屡获殊荣的CNN,通常称为“DanNet”。这是一个实质性的突破。它比早期GPU加速的CNN更深,更快。早在2011年,它就表明深度学习在识别图像目标方面比现有的最新技术要好得多。实际上,它在2011年5月15日至2012年9月10日之间连续赢得了4项重要的计算机视觉竞赛,之前是类似GPU加速的Univ CNN。
在2011年硅谷的IJCNN上,DanNet是第一个在视觉模式识别竞赛中超过人类水平,甚至《纽约时报》也提到了这一点。它也是第一个获胜的深层CNN:同时赢得了中国手写竞赛(ICDAR 2011)、图像分割竞赛(ISBI,2012年5月)、大型目标检测竞赛(ICPR,2012年9月10日)关于癌症检测的医学影像比赛(这些比赛全部都在ImageNet 2012之前)。我们的CNN图像扫描仪比以前的方法快1000倍,在医疗保健等方面具有极其重要的意义。如今,IBM、西门子、谷歌和许多新兴公司都在跟随这一方法。许多现代计算机视觉的方法就是作者在2011年研究工作的扩展。
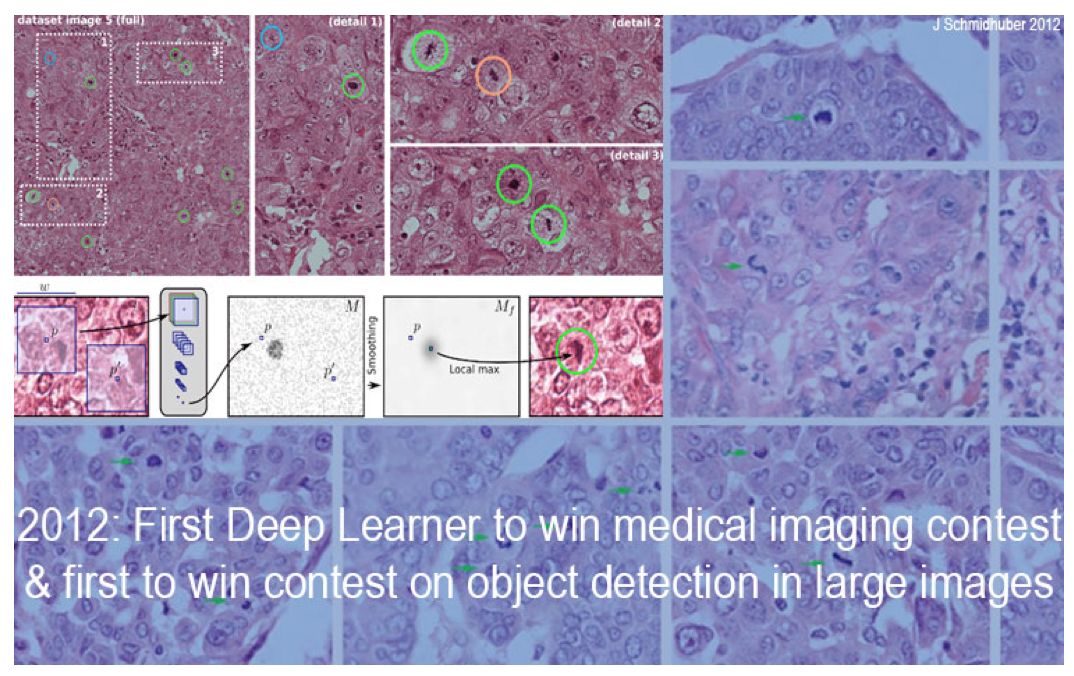
早在2010年,我们就向全球最大的钢铁生产商Arcelor Mittal推出了基于GPU的深度、快速神经网络,并能够通过CNN大大改善钢缺陷检测能力(在ImageNet 2012之前)。这可能是重工业中的首个深度学习突破,并帮助了我们公司NNAISENSE的诞生。在2010年代初,我们的深度学习方法还有其他一些应用。
通过我的学生RupeshKumar Srivastava和KlausGreff,LSTM原理还产生了我们于2015年5月发布的高速公路网络(Highway Networks),这是第一个使用数百层的非常深的FNN。微软最受欢迎的ResNets(赢得了ImageNet2015竞赛)是其中的特例。较早的公路网络的性能与ImageNet上的ResNet差不多。高速公路层也常用于自然语言处理,而较简单的残差则无法正常工作。

LSTM和FNN/ CNN,LSTM与FNN的对比
在最近的深度学习十年中,静态模式(例如图像)的识别主要是由CNN完成的,而序列处理(例如语音、文本等)则主要是由LSTM完成的。有时也会将CNN和LSTM结合在一起,例如视频识别。FNN和LSTM有时也会入侵对方的领域。两个例子:
1.多维LSTM不受CNN固定patch大小的限制,在某些计算机视觉问题表现会更出色。尽管如此,大多数计算机视觉仍然是基于CNN。
2.在本世纪末,尽管受时序上的限制(缺少时序信息),但基于FNN的Transformers在传统的LSTM域Natural Language Processing上开始脱颖而出。尽管如此,LSTM仍然可以快速解决学习许多语言的任务,而普通的Transformers则不能。
商业周刊称LSTM“可以说是最商业化的AI成就”。如上所述,到2019年,LSTM每年获得的引用量超过过去千年的所有其他计算机科学论文。新千年的记录持有人是与LSTM相关的FNN:ResNet(2015年12月)是我们高速公路网络的一种特殊情况。

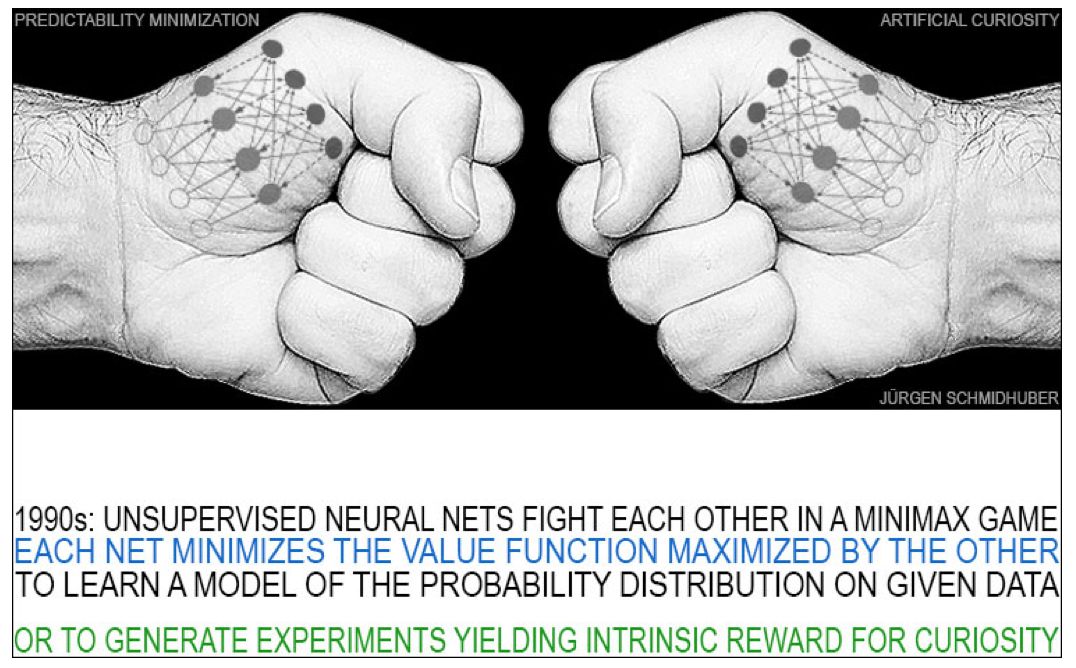
GAN:十年来由好奇心产生的最著名技术
生成对抗网络(GAN)是在2010年代非常流行的另一个概念。GAN是作者在1990年对流行的对抗好奇心原理的一个实例。该原理如下:一个神经网络概率地产生输出,另一个神经网络看到这些输出并预测对其的反应。使用梯度下降方法,将预测器NN的误差最小化,而生成器NN则使其误差最大化。一个网络的损失就是另一网络的收益。GAN是这种情况下的一种特殊情况。

2010年代的其他热门话题
2013年7月,我们的 压缩网络搜索 是第一个使用深度强化学习(RL)来直接从高维感官输入(视频)成功地学习控制策略的深度学习模型,无需进行任何无监督预训练。
几个月后,基于神经进化的RL也成功学会了玩Atari游戏。此后不久,DeepMind 公司 也有了用于高维感官输入的Deep RL系统。
到2016年,DeepMind拥有著名的超人类围棋玩家Go。该公司成立于2010年,这可算是十年来的第一年。最早的在计算机科学领域拥有AI出版物和博士学位的DeepMinders来自我的实验室。
自1990年以来,我们在RL和基于两个称之为控制器和世界模型的RNN组合进行规划的工作在2010年代也开始流行。
自1987年以来,很少有人关心我们的元学习或学会学习(learning to learn )工作。在2010年代,元学习终于成为热门话题。自1990年以来关于人工好奇心、创造力和POWERPLAY风格的自发明问题跟我们的工作类似。

类似于我们自2009年以来在神经架构搜索方面的工作,在某些应用方面优于普通LSTM的类LSTM架构,例如[NAS],以及我们自1991年以来在压缩或提取NNs到其他NNs的工作。
自2009年以来,我们在神经体系结构搜索方面的工作类似,在某些应用中,优于类LSTM的类似LSTM的体系结构,以及自1991年以来我们在将 NNs 压缩或提取为其他NNs方面的工作。
自1990年以来,我们在分层RL方面的工作类似,例如确定性策略梯度和合成渐变。自1991年以来我们的工作类似,即通过对抗性NNs和其他方法以及端到端通过阶乘解缠表示对数据进行编码可区分的系统,通过梯度下降学习,以快速权重快速操纵NNs,以完全神经网络的方式像传统计算机一样将存储和控制分开。
早在1990年代初期,我们就拥有了两种现在常见的神经序列注意力机制: 通过网络内的乘法单元进行端到端可区分的“软”注意里(在潜在空间中),并在RL的上下文中(在观察空间中)进行的“硬”注意力,这才产生了很多后续工作。在2010年代,许多人使用了序列注意力学习神经网络。上一个世纪的许多其他概念不得不等待2010年代更快的计算机开始流行。
正如第21节所提到的,深度学习是在英语不是官方语言的地方发明的。它始于1965年的乌克兰(当时属于苏联),具有第一个真正学习过任意深度的网络。五年后,现代反向传播在芬兰(1970年)发表。基本的深度卷积神经网络架构(现已广泛使用)是在1970年代的日本发明,后来具有卷积的神经网络(1987年)也结合了“权重分配”和反向传播。我们的成绩站在这些作者和许多其他作家的肩膀上。
当然,在大多数应用中, 深度学习只是AI的一小部分,仅限于被动模式识别。我们将其视为更通用的人工智能研究中的副产品 ,其中包括最佳通用学习机器。

数据市场和隐私的未来
AI主要依赖于数据训练。如果数据是新石油,那么它应该像石油一样具有价格。在2010年代,主要的监视平台并没有提供任何资金来保护数据,因此会失去隐私。但是,到2020年代,应该会尝试创建有效的数据市场,以通过供需之间的相互作用来找出数据的真实经济价值。甚至某些敏感的医疗数据也不会由政府监管机构定价,而是会由拥有该数据并可能在医疗数据市场中出售的公司来定价。
日益复杂的社会是否必然导致监视和隐私的丧失?像城市、州和公司这样由许多人组成的区域,就像人由许多细胞组成一样。这些单元几乎没有隐私。它们由专门的“警察细胞”和“边境守卫细胞”不断监控:你是癌细胞吗?你是外部入侵者、病原体吗?单个细胞为了成为多细胞生物的一部分而不得不牺牲自己的自由。
类似的超级生物,例如国家。五千多年前,写作使记录的历史成为可能,因此成为其开创性和最重要的发明。但是,其最初目的是促进监视,跟踪公民及其纳税情况。超级生物越复杂,则有关其组成成分的信息收集就越全面。
200年前,每个村庄的牧师都了解所有村民,甚至包括那些不认罪的人。而且,每个人很快都知道进入村庄的那个陌生人。这样的控制机制在快速发展的城市中因匿名而暂时丢失,但现在随着新的监视设备(如智能手机)的回归,智能设备可以告诉公司和政府数十亿用户的信息。
摄像机和无人机等一直在变得越来越小,无处不在,而人脸和步态等识别正变得越来越便宜,并且很快许多人将使用它来识别地球上的其他任何地方。这是好事还是坏事?无论如何,以牺牲选民的隐私权为代价,某些国家可能会比其他国家更容易成为更复杂的超级生物。

展望:2010年代-2020年代:虚拟AI还是Real AI?
在2010年代,人工智能在虚拟世界中表现出色,例如在视频游戏、棋类游戏,尤其是在主要的WWW平台上。大部分AI利润都来自市场营销。通过NNs进行的被动(passive)模式识别帮助诸如亚马逊、阿里巴巴、谷歌、Facebook和腾讯等一些最有价值的公司让你在平台上停留更长时间,预测你可能感兴趣的项目,让你点击量身定制的广告。 但是,市场营销只是世界经济的一小部分。未来十年会带来什么?
在2020年代,活跃的AI(Active AI)将越来越多地入侵现实世界,驱动工业流程、机器和机器人,就像电影中表现的那样。尽管现实世界比虚拟世界要复杂得多,即将到来的波的 “真实世界AI(Real World AI)”或“现实AI(Real AI)”会比以前的A浪潮更大,因为它会影响到人类所有的生产,因而成为经济发展的更大部分。这就是为什么NNAISENSE都是完全关于 Real AI的原因。
有人声称,拥有许多用户大量数据的大型平台公司将主导AI。这太荒谬了,婴儿如何学会变得聪明?不是“通过从Facebook下载大量数据” ,而是它通过使用玩具进行自发明的实验来主动创建自己的数据,学会预测其行为的后果,并利用这种物理和世界的预测模型来成为越来越好的计划者和问题解决者。

——END——

