AAAI 2019 Oral | 让TA说你想听的—基于音/视频特征解离的讲述者人脸生成

你是否希望照片上的偶像、男神女神,甚至动画人物对着你说出你想听的那句话?又或是希望伪造明星说他们没说过话的视频?
作者丨Lovely Zeng
学校丨CUHK
研究方向丨Detection
香港中文大学 MMLab 提出通过解离的听觉和视觉信息进行说话人脸视频的生成,使得生成高分辨率且逼真的说话视频成为可能,而系统的输入可以仅仅是一张照片和一段任何人说话的语音,无需先对人脸形状建模。
论文的效果如下:

甚至对于动画人物和动物也能取得很好的效果:

论文已经被 AAAI 2019 收录为 Oral Presentation,接下来就将对论文进行详细的讲解,在此将着重于本文的背景和技术,细节部分详见论文,本文代码已经开源,长按识别下方二维码即可查看论文和源码。


背景介绍
多数研究基于音频的说话人脸视频生成问题都是基于图形学的方法,比如在论文 [1] 中,超逼真的奥巴马说话视频已经被成功的合成出来。但是这类方法通常需要对特定的目标对象的大量视频进行训练和建模。
而最近基于深度学习的方法 [2] 和 [3] 使用了 Image-to-Image 的方式,通过单张图像生成整个人脸说话的视频。这种方式已经足以得到很好的与提供的语音匹配的唇形,但是生成图像的质量却大打折扣,生成的结果不但分辨率不高,甚至可能出现人物的面部特征丢失或是出现色差等问题。
问题出现的原因则是因为,由于人脸的身份特征和唇形的语义特征没有完全解离,所以当身份特征被保存完好,也就是希望输出高质量图像的时候,其原来的唇形特征也会被保存下来,难以受音频信息影响。
本文旨在生成与音频完美契合,同时对人脸的细节特征保存完好的高质量的说话视频。因为在方法中同时编码了视频和音频信息,从而使一个单独的模型获得了既可以使用音频又可以使用视频进行进行说话人视频生成的特性。
文章解决的问题如图 1 所示:
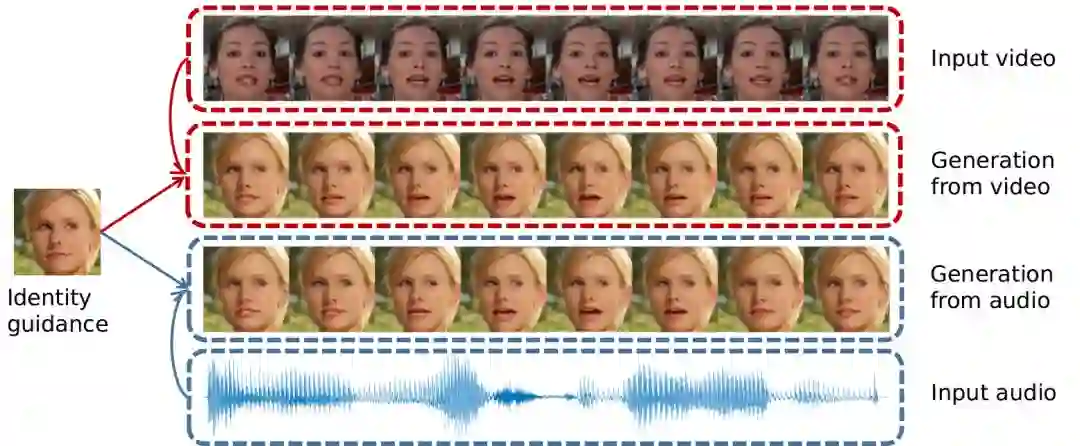
▲ 图1
解决方案
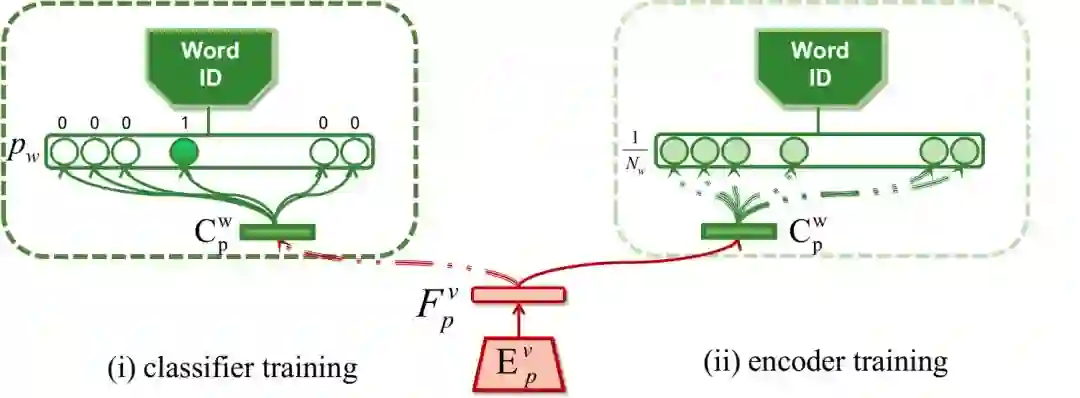
在本文中,解决问题的思路是将一段说话的视频映射到两种互补的人脸信息表示空间上,一种是人脸身份特征的表示空间(PID),另一种就是说话内容的表示空间(WID)。
如果能有方法将这两种表示所在的空间的信息解离开,则保持身份特征信息不变,使说话内容空间的信息根据音频流动,再将两个空间的信息组合就可以达到任意 PID 说任意 WID 的目标。大体思路如下图所示:
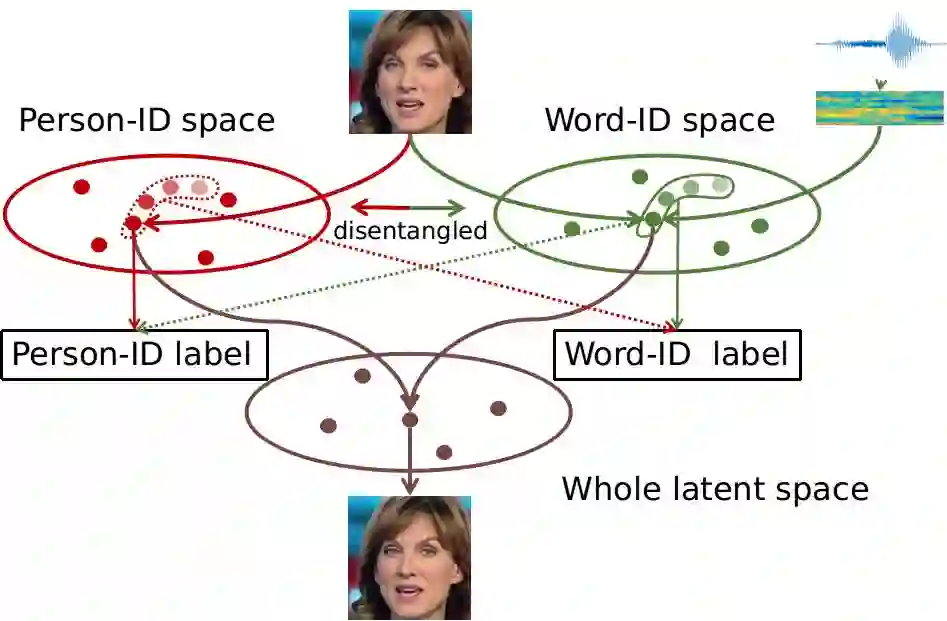
其核心思想在于使用联合视觉的语音识别(Audio-Visual Speech Recognition)(带音频的唇语识别)任务进行空间的编码和解离。包含说话人脸视频,音频和所说词语标签的唇语识别数据集天然的目标,由此文章提出了一种“协同与对抗(associate-and-adversarial)”的训练方式。
通过使用音频和视觉信息同时训练语音识别任务,有关说话内容的特征空间就可以被找到。而在此空间中,一组对应的视频和音频因为表达的是同样的信息,所以理应映射到同一个位置。
因此文章通过协同训练找到一个听视觉信息融合的表示空间(joint audio-visual representation),也就是上图中的 Word-ID space。而这样的协同空间中无论是视觉信息还是音频信息映射的特征,都可以拿来进行人脸和重构,由此又巧妙地达到了使用一个模型统一使用视频或者音频生成说话视频。
有了词语的标签之后,更有趣的是可以通过词语标签对编码人脸身份特征的网络进行对抗训练(adversarial training),将语言信息也就是唇形信息从中解离出来。同时,找到映射人脸的空间因为有大量标有人身份标签的数据集的存在,本身是一件很简单的事情。
通过使用额外的带有身份信息的数据进行训练既可以通过分类任务找到映射人脸的空间,又可以通过对抗训练将人脸信息从语言空间解离出来。
简单总结一下文章的贡献:
1. 首先通过音频和视频协同训练唇语识别,将两种信息向语言空间融合映射,协同训练的结果显示甚至相比基线可以提升唇语识别的结果;
2. 因为通过了使用识别性的任务进行映射,充分利用可判别性,使用对抗训练的方式进行了人脸特征和语言信息的解离;
3. 通过联合训练上述任务,任意一张照片都可以通过一段给定的音频或者视频,生成高质量的说话视频。
技术细节
方法的整个流程图如下,文章的整个方法被命名为“解离的音-视频系统”,Disentangled Audio-Visual System (DAVS):
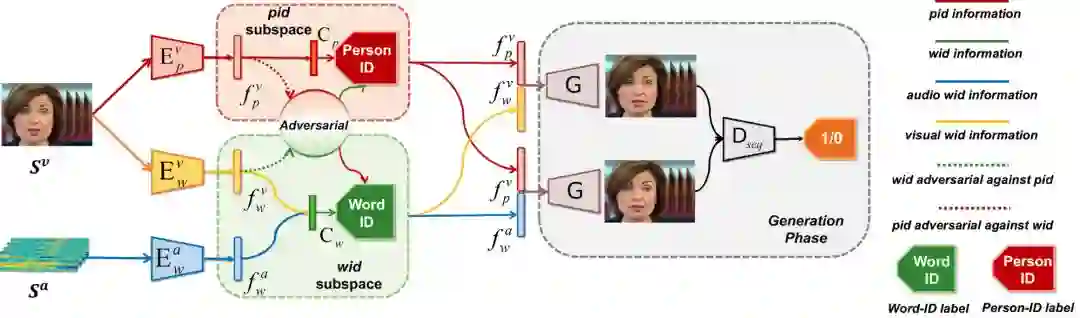
本文使用了单词级别的唇语识别数据集 LRW。在此数据集中每段定长的视频拥有其所含的主要单词的 label,所以映射的说话内容空间,被命名为 Word-ID(wid)空间(词空间),对应于人脸的 Peron-ID (pid) 空间(身份空间)。
整个系统包含视频对词空间的编码网络,音频对词空间的编码网络
,和视频对身份空间的编码网络
;通过网络,人脸空间被划分成 wid 和 pid 两个互斥的空间,并使用对抗训练的方式解离开。同时 wid 空间是音频和视频协同映射的联合空间,通过同步两个空间的信息,要求对应的音频和视频映射到空间的同一位置。
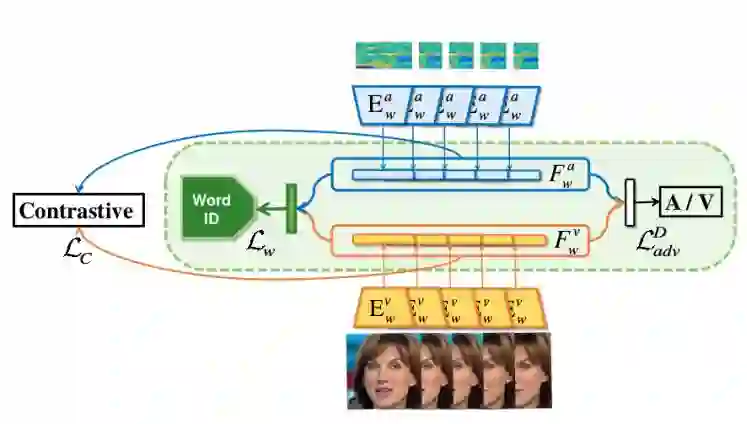
音频视频联合空间映射
联合空间的映射通过三个监督联合完成,这三个监督分别是:共享视频和音频映射到词标签的分类器;通常用于排序的 contrastive 损失函数;和一个简单的用于混淆两个空间的对抗训练器。
共享分类器这一方法,本质在于让数据向类中心靠拢,可以称之为“中心同步”[4]。而排序 Contrastive loss 用于音频和视频同步最早源于 VGG 组提出的 SyncNet [5]。
利用这一体系进行联合空间映射,所以联合空间映射模块也适用于将音-视频同步这一任务。而本身使用唇语识别这一任务做监督又意味着可以同时将唇语识别这一任何融入其中。
对抗训练空间解离
为了将身份空间和词空间解离,文章首先依托唇语识别数据集的标签,对身份空间的编码器进行语言信息的解离。在保持身份编码器权重不变的情况下,通过训练一个额外的分类器
,将
编码的视频特征
,映射到其对用的词标签上。这一步骤的意义在于尽可能的将已编码的身份特征中的语言信息提取出来。然后第二步保持分类器的权重不变,训练编码器
,此时词标签则取成总类别数的平均值。由此我们期望映射的特征向量中含有的词信息不足以让分类器
成功分类。
对于词编码器,文章使用额外的人脸识别数据 MS-Celeb-1M [6],使用同样的方式对称的提纯映射的词空间信息,完成身份空间和词空间的解离。
实验结果
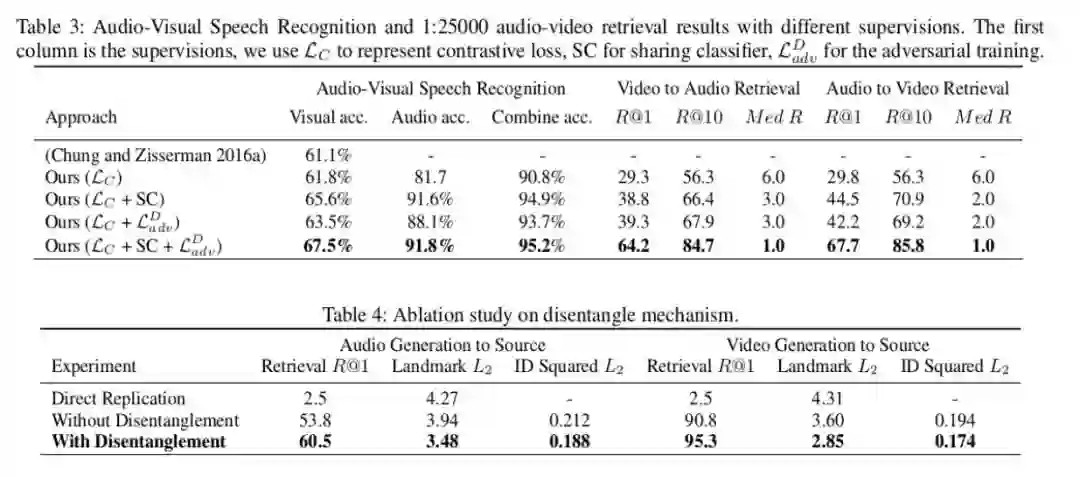
文章中进行了一些数值的对比实验证明其提出的每一个模块的有效性,但对于此任务,最重要的生成的效果。Gif 结果附在了本文开头,而长视频结果请见主页:
https://liuziwei7.github.io/projects/TalkingFace
参考文献
[1] Suwajanakorn, S., Seitz, S. M., & Kemelmacher-Shlizerman, I. (2017). Synthesizing obama: learning lip sync from audio. ACM Transactions on Graphics (TOG), 36(4), 95.
[2] Chung, J. S., Jamaludin, A., & Zisserman, A. (2017). You said that?. BMVC 2017.
[3] Chen, L., Li, Z., Maddox, R. K., Duan, Z., & Xu, C. (2018). Lip Movements Generation at a Glance. ECCV 2018.
[4] Liu, Y., Song, G., Shao, J., Jin, X., & Wang, X. (2018, September). Transductive Centroid Projection for Semi-supervised Large-Scale Recognition. ECCV 2018.
[5] Chung, J. S., & Zisserman, A. (2016, November). Out of time: automated lip sync in the wild. In ACCV workshop 2016.
[6] Guo, Y., Zhang, L., Hu, Y., He, X., & Gao, J. (2016, October). Ms-celeb-1m: A dataset and benchmark for large-scale face recognition. ECCV 2016.

点击以下标题查看更多往期内容:

让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢? 答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 下载论文 & 源码

