【ACMMM2022最佳论文】搜索导向的短视频描述

该获奖论文介绍如下:
这篇论文主要研究如何为“没有视频描述的短视频”自动生成一个文本描述的问题。为了给38%没有文字描述的短视频自动生成有一个抽象的文本描述,研究者通过建立相关模型,从针对用户搜索需求的角度自动生成文本去描述一个短视频,以满足用户搜索视频的多样化需求。
以往工作致力于以内容为导向的视频字幕工作,从创作者的角度生成相关的句子来描述给定视频的视觉内容。这项工作的目标则是以搜索为导向,通过用户的角度生成关键词来总结给定的视频。除了相关性,多样性对于从不同角度描述用户的搜索意向也至关重要。
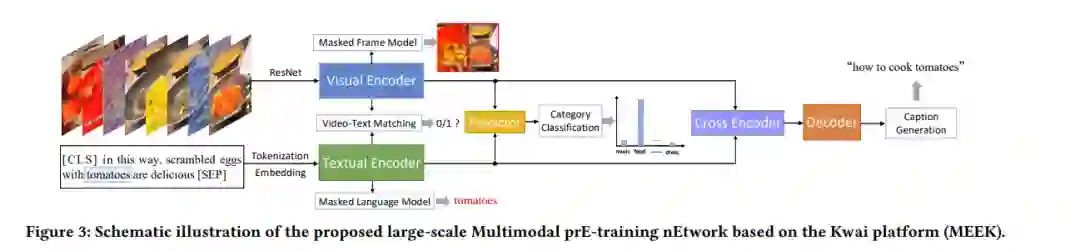
为此,研究团队设计了一个大规模多模态的预训练网络,通过五个任务来加强下游视频表征,该网络在研究团队收集的 1100 万个微视频上训练。之后,研究团队提出了一种基于流的多样化字幕模型,以根据用户的搜索需求生成不同的字幕。该模型通过重建损失在先验和后验之间的KL分歧进行优化。通过构建由 69 万个<查询,短视频>对组成的黄金数据集合,作者验证了他们的模型,实验结果也证明了其优越性。
据了解,这项工作所研发的“短视频摘要生成算法”在快手得到落地,已平稳运行半年,每日处理约 3 千万个短视频。
参考链接:
https://mp.weixin.qq.com/s/dkKOmwta1olBAlrsSwUhOg
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“M173” 就可以获取《【牛津大学博士论文】多模态概率推理的机器学习预测与协调,173页pdf》专知下载链接



登录查看更多
相关内容
Arxiv
0+阅读 · 2022年12月4日




相关VIP内容
相关资讯