如何使用高大上的方法调参数

本文原作者袁洋,原载于知乎专栏理论与机器学习。AI研习社已获得作者授权。
本文主要介绍作者与 Elad Hazan, Adam Klivans 合作的最新论文:
Hyperparameter Optimization: A Spectral Approach(https://arxiv.org/abs/1706.00764)
那么,在介绍具体算法之前,我们先要理解一个很重要的问题:
调参数这个东西,关我 x 事?
因为它非常有用。 调参数是指这么个问题:你有 n 个参数,每个参数需要赋一个值。赋完值之后,你用这些参数做一个实验,可以看到一个结果。根据这个结果,你可以修改你的参数,然后接着做实验,看结果,改参数…… 最后你希望得到一个非常好的结果。
这个框架适用于几乎一切场景。比如说,它可以用来指导你做饭。每次放多少盐?多少糖?火开多大?开多久放料?先放什么再放什么?各放多少? 平底锅还是炒锅?油放多少?要不要放胡椒粉?等等。
Jasper Snoek 就在一次报告中(http://t.cn/RpXNsCs)讲述如何用调参数方法(贝叶斯优化)炒鸡蛋。他只花了大概 30 个鸡蛋就得到了一个很好的菜谱。当然了,调参数方法还可以用来炒虾米,炒猪肉,炖茄子,烤羊腿,或者酿酒,和面,撒农药,养鸡养鸭,做生物化学实验,基因优化,空气动力学结构设计,机器人参数优化等等,不一而足。只要你独具慧眼,其实生活中太多的问题可以用这一类方法来解决。
------------------ 我是分割线 ------------------
在机器学习里面,这个问题尤其重要。比如说,你哪天想要拿神经网络来做个什么,应该怎么弄?有些同学可能知道,神经网络,作为一个高科技的东东,其实还是相当复杂的。它需要用户做很多决策。而对于初学者来说,这些决策往往令人望而生畏。例如:
网络有多深?
网络有多宽?
每一层是要用什么结构?线性层还是卷积层?
层与层之间应该如何连接?
应该使用什么样的 Activation?
应该使用什么样的优化算法?
优化算法的初始步长是多少?
初始步长在训练过程中应该如何下降?
应该使用什么样的初始化?
是否需要使用 Momentum 算法?如果是,具体速率是多少?
卷积层里面是否要加入常数项?
是否需要使用 Dropout?
是否需要使用 Batch norm?是否需要自动调整 Batch norm 的参数?
是否需要使用 Weight decay?
Weight decay 速度是多少?
Mini batch 的大小是多少?
这些问题,有些是重要的,有些是不那么重要的。有些如果设错了没有什么关系,有些设错了会导致神经网络直接就没用了。尤其是对于一个新的应用场景而言,找到那些对它最关键的问题并给予正确的答案,至关重要。
好了,讲到这里,大家应该都理解了,这是一个非常有意义的问题。那么,
现在大家是怎么调参数的呢?
现在大家都用 GSS 算法,全称是 Graduate Student Search 算法。翻译成中文就是博士生人肉搜索算法,又称炼丹算法。

图文无关! [Andy Greenspon, a PhD student in Applied Physics at Harvard, aligns a green laser for characterizing optical properties of diamond. (Photo by David Bracher) ]
好吧,其实除了 GSS 算法,我们也有一些别的算法,比如之前提到的贝叶斯算法(Bayesian Optimization),还有 Hyperband 算法,等等,其实都是一些很优美的算法。那么,既然之前提到贝叶斯算法可以用来炒鸡蛋,为什么现在大家仍然使用博士生人肉搜索这种原始的方法做调参数问题呢?
答案是来自高维度的诅咒。当需要考虑的参数个数过多的时候,可能性就会呈指数级别增长,而已有的算法却没有很好的机制来处理这个问题。对于调参数的问题来说,每一次实验的代价都很大(想想炒鸡蛋,每次实验都会要牺牲一个鸡蛋),因此一旦需要做的实验数量随着参数个数指数增长之后,算法就会失效。一般来说,已有的算法只能够处理不到 20 个参数的问题。
而博士生人肉搜索则不然。像小蜜蜂一样的博士生们通过辛勤的劳动,往往能够从众多参数中找到若干最重要的 10 个 20 个参数,然后再把它们塞到已有算法里面自动调一调,往往就能够得到很好的结果。
有没有办法把人肉搜索这一步自动化呢?这就是我们论文的主要贡献:
Harmonica —— 我们的算法
[在介绍算法之前,我想要提一下,我们的算法适用于离散参数的情况。对于连续参数,可以使用赌博机 (Multi-armed Bandit)+ 最速下降法 (Gradient Descent) 方法(https://arxiv.org/abs/1502.03492),或者把它们离散化成为离散参数。由于离散参数都可以转化为布尔参数,以下我们只考虑参数是布尔的情况。但是其实一切的实际问题都可以转换成这个情况,并不只是一个理论上的简化。]
我们先简单谈谈拉锁(Lasso)算法。
拉锁算法是一个非常常用、非常简单、非常基本的线性回归的算法。问题大致是这样的:已知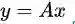

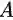
我们考虑的情况很特殊,矩阵
这个时候,如果我们加了一个额外的假设,说
这个东西和我们的问题有什么关系呢?在我们这个问题里,矩阵
小结一下。我们引入线性回归的想法,就是想要找到一些有用的特征,并且假设这些特征的线性叠加可以很好地近似最后调参数的结果。换句话说,我们认为我们需要优化的这个参数函数,本质是一个线性函数,更加确切地说,是一个稀疏的线性函数。
有些同学肯定就要开喷了,这个显然不是线性的啊,参数函数甚至都不是凸的啊,你们这些搞理论的这么总是指鹿为马啊,blabla……
嗯是的,参数函数几乎一定不是参数的线性叠加,但是它一定可以写成某些特征的线性叠加。例如,深度神经网络对图像分类的时候,从某个角度来说,可以看做是它的前 n-1 层对图片的像素进行了特征提取,得到了最后一层的特征向量。然后最后一层再做一个线性叠加(linear layer),得到了最后的答案。从这个角度来看,其实神经网络也假设图片分类的函数是一个线性函数,不过线性函数的特征向量是神经网络自己学出来的罢了。
那么言归正传,我们这里用到的特征是什么呢? 使用调和分析(Harmonic Analysis,或者 Boolean Functional Analysis)的知识,我们可以知道,任何的基于 n 个布尔参数的参数函数,都可以写成基于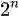
换句话说,在刚才的线性回归的式子里,如果我们把
说到这里,算法的框架已经比较清楚了。但其实仍然有两个非常实际的问题需要解决。
第一个问题:如果 n 比较大,比如有 60,那么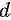
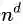
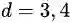
第二个问题更加严重。就算我们现在只用了
如何解决这个问题呢?我们的算法的巧妙之处在于,使用了多层拉锁!注意到,对于调参数问题,我们并不在意真的去把
这些参数固定之后,其实个数往往不多,一般也就 5、6 个。我们还剩下大量的参数的值没有确定。如果这个时候停止的话,相当于就默认这些参数对最后的函数完全不起任何作用(当然是不对的)。我们做的就是,在固定已有的 5、6 个参数的情况下,对剩下的参数重新进行随机采样,然后跑拉锁。这样我们又会得到若干个重要的参数,于是又可以重新采样跑拉锁,如此循环多次之后,即可得到一大堆重要的参数和它们的赋值。
至此,我们的算法就介绍完了。
------------------ 我是分割线 ------------------
小结一下,所谓的 Harmonica 算法大体是在做如下的事情:
在参数空间中,随机采样(比如)100 个点
对每个点计算低度数傅里叶基的特征向量,捕捉参数之间的相关性
对于计算好的 100 个特征向量,跑拉锁算法,得到(比如) 5 个重要的特征,以及这些特征对应的参数
固定这些参数的值,得到了新的调参数问题(参数个数减少,搜索空间降低)。回到第一步。
如此重复若干轮之后,固定了很多参数的值,其实已经得到了一个很好的解。剩下的参数基本上和白噪声差不多,可以调用一些已有的算法(hyperband 之类) 进行微调即可。
Harmonica 的几个优点:
对参数个数的增长不敏感
优化速度极快(跑跑拉锁即可)
非常容易并行
可以自动高效地提取重要的特征
理论解释
虽然我们的算法很简单,但是正如我之前提到的那样,其实它背后有很强的理论支持。在论文中,我们使用了调和分析和压缩感知的方法证明它的正确性与有效性。在证明的过程中,我们还顺便解决了一个存在了 20 多年的关于决策树的理论问题 。但是一来大家可能对这方面并不感兴趣,二来理解了确实也没什么用,我便把这部分可耻地略去了 -__-
实验结果
其实我们就跑了一个神经网络实验,在 Cifar10 上面跑 resnet。这个实验我选了 39 个各式各样的参数,涵盖了我能想到的一切需要手调的参数,外加 21 个无用参数(用于加大问题难度)。我们跑了 3 层的拉锁算法,使用了度数为 3 的特征向量,现在一个小的 8 层的网络上跑,得到了重要的参数们之后,将这些信息用到大的 56 层的网络上微调,得到了很好的结果。如下图:
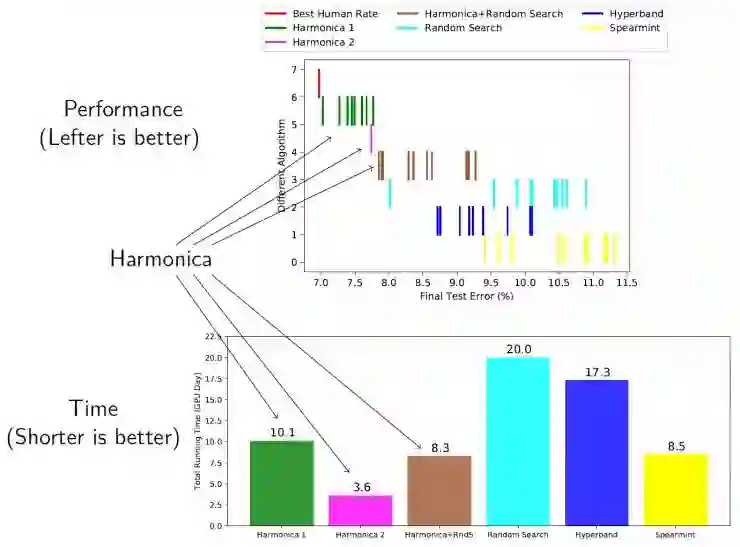
可以看到,Harmonica 得到的结果比别的算法(Random Search, Hyperband, Spearmint)都好很多,而总的时间却用得很少。其中,Harmonica 跑 10 天(我们用了 10 台机器并行,因此实际只花了 1 天)就能够得到和博士生们极为接近的结果。而 Harmonica 跑 3 天就能够得到比别的算法跑 17 天 20 天还要好很多的结果。除此之外,Harmonica 找到的特征与人们的经验是十分吻合的。比如 batch normalization, activation, learning rate 就是它找到的最重要的 3 个特征。详见论文。
这篇论文大概就是这样了。作为第一篇对调参数问题做特征提取的论文,我觉得这个方向仍然有很多可以挖掘的地方。我们把 python 版本的代码放在了 github (https://github.com/callowbird/Harmonica)上,有兴趣的同学可以试试看。


AI 研习社长期接受优秀文章投稿
同时免费为优质企业推广招聘信息
有意者请联系 jiazhilong@leiphone.com

后台回复 “我要进群” 加入 AI 技术讨论群
新人福利
关注 AI 研习社(okweiwu),回复 1 领取
【超过 1000G 神经网络 / AI / 大数据,教程,论文】
为什么说随机最速下降法 (SGD) 是一个很好的方法?
▼▼▼




