BAT机器学习面试题及解析(291-295题)

本系列作为国内首个AI题库,囊括绝大部分机器学习和深度学习的笔试面试题、知识点,可以作为机器学习自测题,也可以当做查漏补缺的资料库。七月在线AI题库(网页版及APP版)见“阅读原文”
291.下面有关序列模式挖掘算法的描述,错误的是?(C)
A AprioriAll算法和GSP算法都属于Apriori类算法,都要产生大量的候选序列
B FreeSpan算法和PrefixSpan算法不生成大量的候选序列以及不需要反复扫描原数据库
C 在时空的执行效率上,FreeSpan比PrefixSpan更优
D 和AprioriAll相比,GSP的执行效率比较高
@CS青雀,本题解析来源:http://blog.csdn.net/ztf312/article/details/50889238
1. Apriori算法 :关联分析原始算法,用于从候选项集中发现频繁项集。两个步骤:进行自连接、进行剪枝。缺点:无时序先后性。
AprioriAll算法:AprioriAll算法与Apriori算法的执行过程是一样的,不同点在于候选集的产生,需要区分最后两个元素的前后。
AprioriSome算法:可以看做是AprioriAll算法的改进
AprioriAll算法和AprioriSome算法的比较:
(1)AprioriAll用 去计算出所有的候选Ck,而AprioriSome会直接用 去计算所有的候选 ,因为 包含 ,所以AprioriSome会产生比较多的候选。
(2)虽然AprioriSome跳跃式计算候选,但因为它所产生的候选比较多,可能在回溯阶段前就占满内存。
(3)如果内存占满了,AprioriSome就会被迫去计算最后一组的候选。
(4)对于较低的支持度,有较长的大序列,AprioriSome算法要好些。
2. GPS算法:类Apriori算法。用于从候选项集中发现具有时序先后性的频繁项集。两个步骤:进行自连接、进行剪枝。缺点:每次计算支持度,都需要扫描全部数据集;对序列模式很长的情况,由于其对应的短的序列模式规模太大,算法很难处理。
3. SPADE算法:改进的GPS算法,规避多次对数据集D进行全表扫描的问题。与GSP算法大体相同,多了一个ID_LIST记录,使得每一次的ID_LIST根据上一次的ID_LIST得到(从而得到支持度)。而ID_LIST的规模是随着剪枝的不断进行而缩小的。所以也就解决了GSP算法多次扫描数据集D问题。
4. FreeSpan算法:即频繁模式投影的序列模式挖掘。核心思想是分治算法。基本思想为:利用频繁项递归地将序列数据库投影到更小的投影数据库集中,在每个投影数据库中生成子序列片断。这一过程对数据和待检验的频繁模式集进行了分割,并且将每一次检验限制在与其相符合的更小的投影数据库中。
优点:减少产生候选序列所需的开销。缺点:可能会产生许多投影数据库,开销很大,会产生很多的
5. PrefixSpan 算法:从FreeSpan中推导演化而来的。收缩速度比FreeSpan还要更快些。
292.下列哪个不属于常用的文本分类的特征选择算法?
A 卡方检验值
B 互信息
C 信息增益
D 主成分分析
常采用特征选择方法。常见的六种特征选择方法:
1)DF(Document Frequency) 文档频率
DF:统计特征词出现的文档数量,用来衡量某个特征词的重要性
2)MI(Mutual Information) 互信息法
互信息法用于衡量特征词与文档类别直接的信息量。
如果某个特征词的频率很低,那么互信息得分就会很大,因此互信息法倾向"低频"的特征词。
相对的词频很高的词,得分就会变低,如果这词携带了很高的信息量,互信息法就会变得低效。
3)(Information Gain) 信息增益法
通过某个特征词的缺失与存在的两种情况下,语料中前后信息的增加,衡量某个特征词的重要性。
4)CHI(Chi-square) 卡方检验法
利用了统计学中的"假设检验"的基本思想:首先假设特征词与类别直接是不相关的
如果利用CHI分布计算出的检验值偏离阈值越大,那么更有信心否定原假设,接受原假设的备则假设:特征词与类别有着很高的关联度。
5)WLLR(Weighted Log Likelihood Ration)加权对数似然
6)WFO(Weighted Frequency and Odds)加权频率和可能性
http://blog.csdn.net/ztf312/article/details/50890099
293.类域界面方程法中,不能求线性不可分情况下分类问题近似或精确解的方法是?(D)
A 伪逆法-径向基(RBF)神经网络的训练算法,就是解决线性不可分的情况
B 基于二次准则的H-K算法:最小均方差准则下求得权矢量,二次准则解决非线性问题
C 势函数法-非线性
D 感知器算法-线性分类算法
294.机器学习中做特征选择时,可能用到的方法有? (E)
A、卡方
B、信息增益
C、平均互信息
D、期望交叉熵
E 以上都有
295.下列方法中,不可以用于特征降维的方法包括(E)
A 主成分分析PCA
B 线性判别分析LDA
C 深度学习SparseAutoEncoder
D 矩阵奇异值分解SVD
E 最小二乘法LeastSquares
特征降维方法主要有:PCA,LLE,Isomap
SVD和PCA类似,也可以看成一种降维方法
LDA:线性判别分析,可用于降维
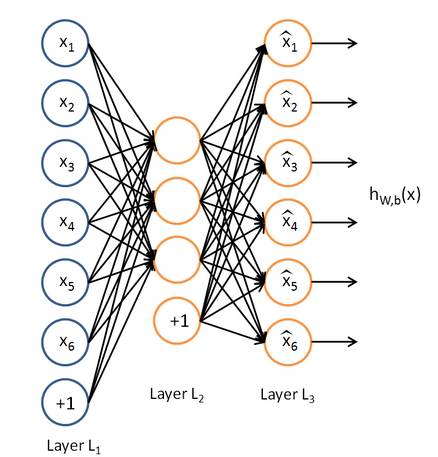
AutoEncoder:AutoEncoder的结构与神经网络的隐含层相同,由输入L1,输出 L2组成,中间则是权重连接。Autoencoder通过L2得到输入的重构L3,最小化L3与L1的差别 进行训练得到权重。在这样的权重参数下,得到的L2可以尽可能的保存L1的信息。
Autoencoder的输出L2的维度由输出的神经元个数决定。当输出维度大于L1时,则需要在训练目标函数中加入sparse 惩罚项,避免L2直接复制L1(权重全为1)。所以称为sparseAutoencoder( Andrew Ng提出的)。
结论:SparseAutoencoder大多数情况下都是升维的,所以称之为特征降维的方法不准确。
往期题目:







