©作者 | 张宋扬、彭厚文等
来源 | 机器之心
当时间的维度从一维走向二维,时序上的建模方式也需要相应的改变。本文提出了多尺度二维时间图的概念和多尺度二维时域邻近网络(MS-2D-TAN)用于解决视频时间定位的问题。本文拓展自 AAAI 2020 [1],并将单尺度的二维时间建模拓展成了一个多尺度的版本。新模型考虑了多种不同时间尺度下视频片段之间的关系,速度更快的同时精度也更高。本文在基于文本的视频时间定位任务中验证了其有效性。相关内容将发表在 TPAMI上。
我们常常将物理世界定义为三维空间,将时间定义为一维空间。但是,这不是唯一的定义方式。最近,罗切斯特大学和微软亚洲研究院的学者们大开脑洞,提出了一种新的时间表示方式,将时间定义成了二维的!
在二维空间里,时间是如何表达的呢?童鞋们给出的答案是这样的:在二维空间中,我们定义其中一个维度表示时间的开始时刻,另外一个维度表示持续的时间;从而,二维空间中的每一个坐标点就可以表达一个时间片段(例如,从 A 时刻开始持续 B 秒的时间片)。
在这种二维空间定义下,如果我们把单位时间刻度设置的越小,那么可以观测到时域上更加局部和微观的关系。而如果把单位时间刻度设置的较大,那么观测到的关系将更加全局和宏观。如果能有效地结合两者,将会对片段间的关系有更丰富的描述。
(参考自 https://www.msra.cn/zh-cn/news/features/aaai-2020-2d-tan)
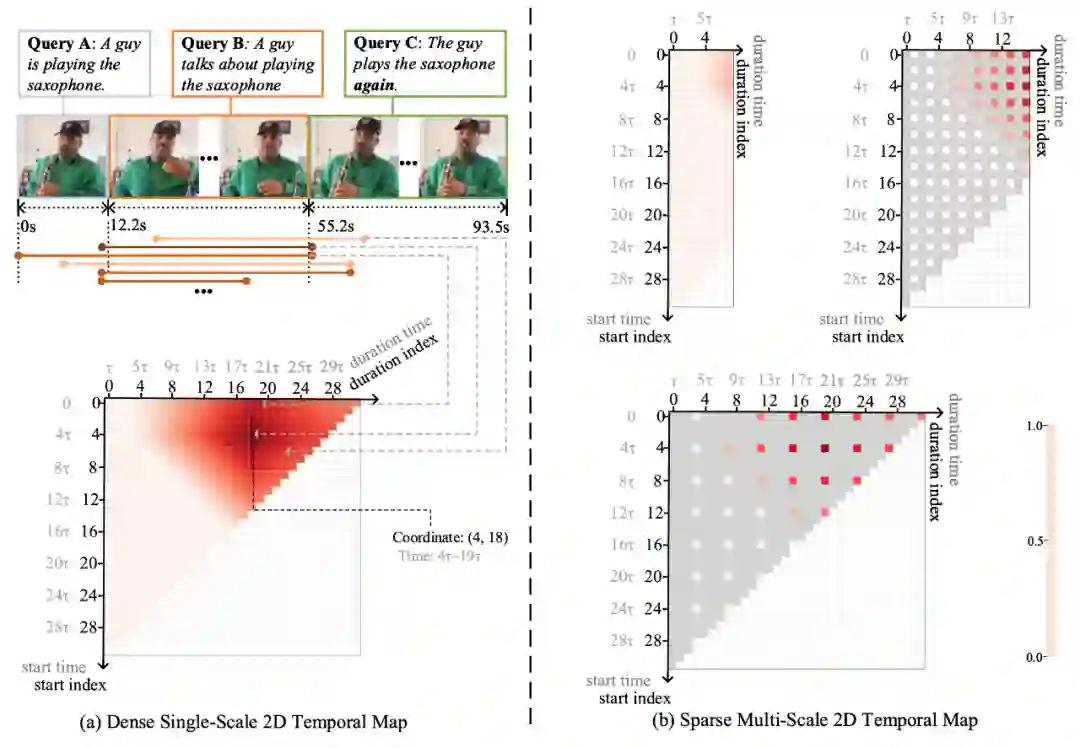
基于文本的视频时间定位的目标是,给一段文字,在视频中找到文本所对应视频片段,并给出片段的开始时间和结束时间。如图 1 Query A 所示,给一段文字 「一个人吹起了萨克斯」和一段视频,这个任务希望找到与文字描述最匹配的那个片段。许多前人的工作都是独立考虑片段和文本之间的相似程度,而忽略了片段与片段之间的上下文信息。如图 1 Query C 所示,为了定位「这个人再一次吹起了萨克斯」, 如果只看后半段的视频是很难定位「再」 这个词的。此外,如图 1 Query B 所示, 很多高度重合的片段有相似的内容,如果不对这些片段进行对比的话,很难区分哪个片段与文字描述最匹配。
为了解决这一问题,该研究在 AAAI 2020 的论文中提出了一个二维时域邻近网络(2D-TAN)。该网络的核心思想是在一个二维时间图上做视频的时间定位。如图 1(a)所示,图中(i,j) 表示的是一个从 i 开始持续 j+1 的时间片段。对于不同长度的片段,我们可以通过坐标上的远近来定义他们之间的邻近关系。有了这些关系,我们就可以用 2D-TAN 对这种依赖关系进行建模。此外,因为 2D-TAN 是将这些片段当成一个整体来考虑,学出来的片段特征也更具有区分性。
![]()
这里二维时间图的单位时间长度τ决定了定位精细程度。为了让定位更精细,该研究设计了一个多尺度的二维时间图,如图1(b) 。该研究选取不同的单位时间长度来构造不同精细度的二维时间图。这种方式可以让模型在更大的时间范围上学习片段间的依赖关系,同时也让每个片段获得更丰富的上下文信息。另一个好处是,这种多尺度建模也可以看作是一种稀疏采样的方式,从而降低片段特征抽取和片段间建模所带来的计算开销,将计算复杂度从二次方降到了线性 。
![]()
图 1 二维时间图的示意图。(a) 表示的是稠密单尺度二维时间图。黑色坐标轴分别表示的是开始和时长的标号,而灰色坐标轴表示的是与之对应的开始时刻和持续时间。二维图中红色的程度表示目标片段和候选片段的匹配程度。这里是一个预先定义好的单位时长。白色格子表示无效的视频片段。(b)表示的是稀疏多尺度二维时间图。稀疏多尺度二维时间图由多个二维时间图构成,各个二维时间图的单位时长不相同()。灰色格子表示有效但非候选的视频片段。其他颜色定义同上。通过在多个小尺寸图上建模,可以减少计算开销。
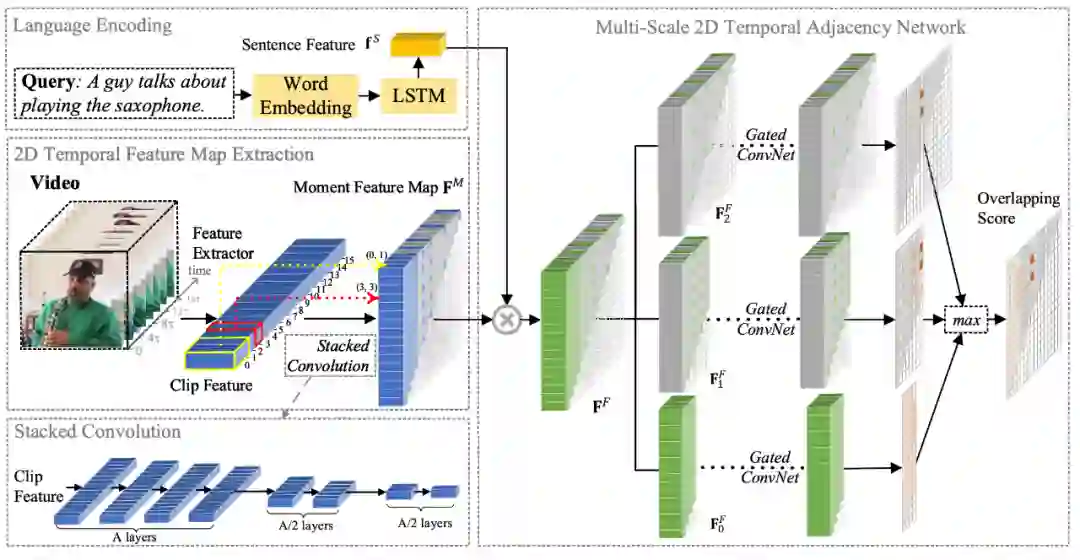
本文提出的模型如图 2 所示。该模型由三个模块构成:文本编码模块,视频的二维时间特征图模块和多尺度二维时间邻近网络。下文将逐一介绍各个模块。
![]()
该研究首先将各个单词用 GloVe 进行编码,再输入到 LSTM 中。该研究将 LSTM 的输出取平均作为语句的特征向量。
该研究首先将视频分割成N个小的单元片段(clip),再通过预训练好的模型将这些片段抽取特征,大小是N×d^V。候选片段由多个连续的单元片段所构成,且长度并不相同。为获取统一的片段特征的表示,该研究将抽取好的单元片段特征通过叠加卷积的方式获得所有候选片段特征。再根据每个候选片段的开始时刻和持续时间,将所有的候选片段排列成一个二维特征图。
当研究人员使用N - 1 个卷积层可获得所有有效片段的特征。但当N较大时,这样的计算开销也往往较大。因此,该研究采用了一个稀疏采样的方式。如图 2 所示,该研究对较短的片段进行密集的采样,而对较长的片段进行稀疏采样。先用 A 层步长为 1,核尺寸为 2 的卷积获得短片段的特征,之后每隔 A/2 个卷积层,步长增加一倍,逐步获得较长片段的特征。通过这种方式可以不用枚举出所有的片段,从而降低计算开销。前者获得的二维特征图我们称之为稠密二维特征图,而后者则称之为稀疏二维特征图。
有了视频的稀疏二维特征图(图 2 中蓝色立方体)和文本特征(图 2 中黄色立方体),该研究将其进行融合,获得融合的稀疏二维特征图(图 2 中绿色立方体)。该研究再根据不同的时间尺度,将单一尺度的稀疏二维特征图,转化成一组稀疏的多尺度二维特征图。对于每个尺度的二维特征图,该研究使用一系列的 gated convolution 对每个片段和其邻近片段的关系进行建模,并通过一个全联接层获得各尺度中各片段最终的得分。
在训练过程中,每一个尺度都会有一个对应的损失函数,该研究将二元交互熵 (Binary Cross Entropy) 作为模型的损失函数,同时使用一个经过线性变换的 IoU (intersection over union)的值作为损失函数中的标签。该研究将所有的损失函数加在一起作为整个模型的损失函数。
在测试时,该研究根据特征的位置,得到每个片段的得分,并根据 NMS 对其进行筛选。如果一个片段存在于多个得分图中,那么选取最高的得分作为其得分。
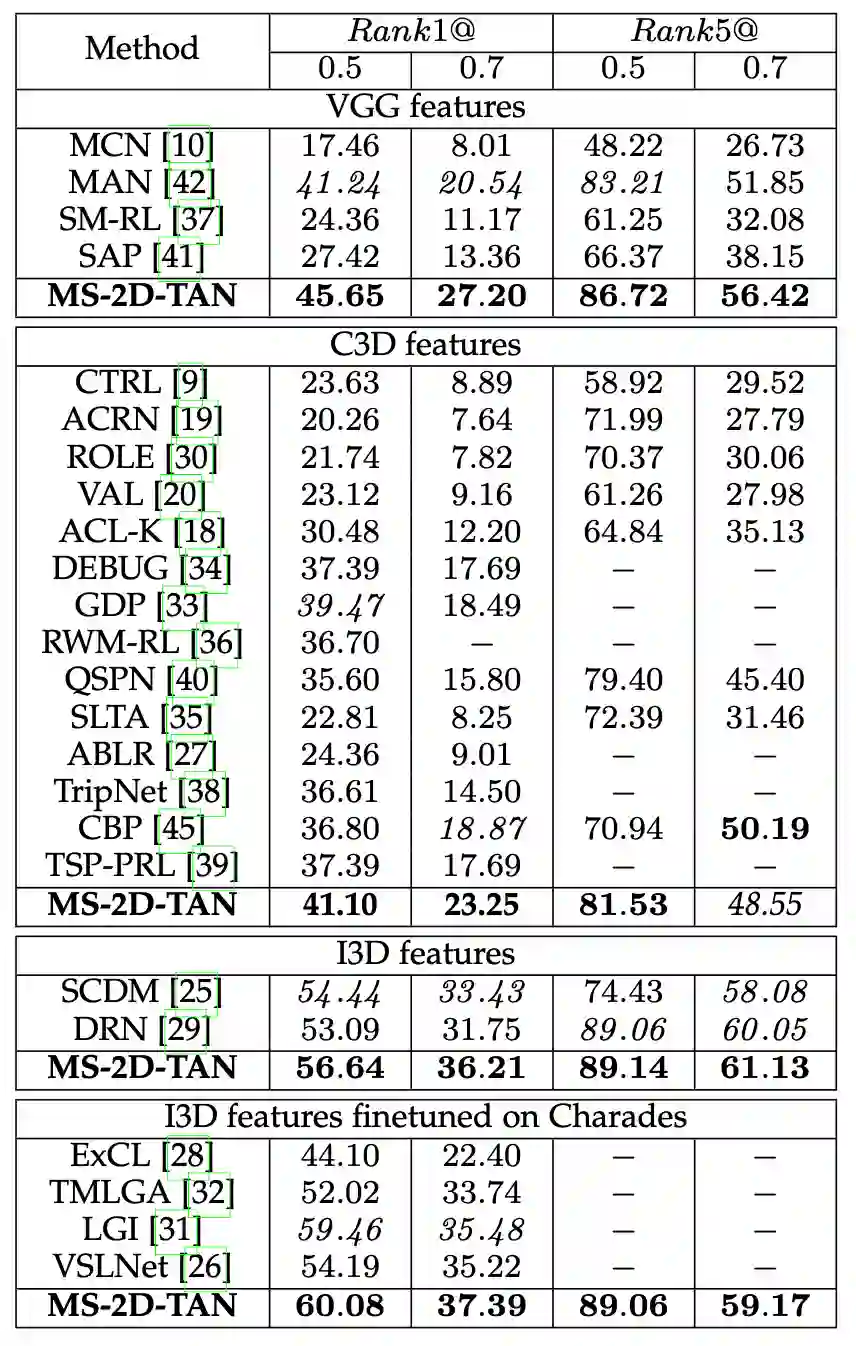
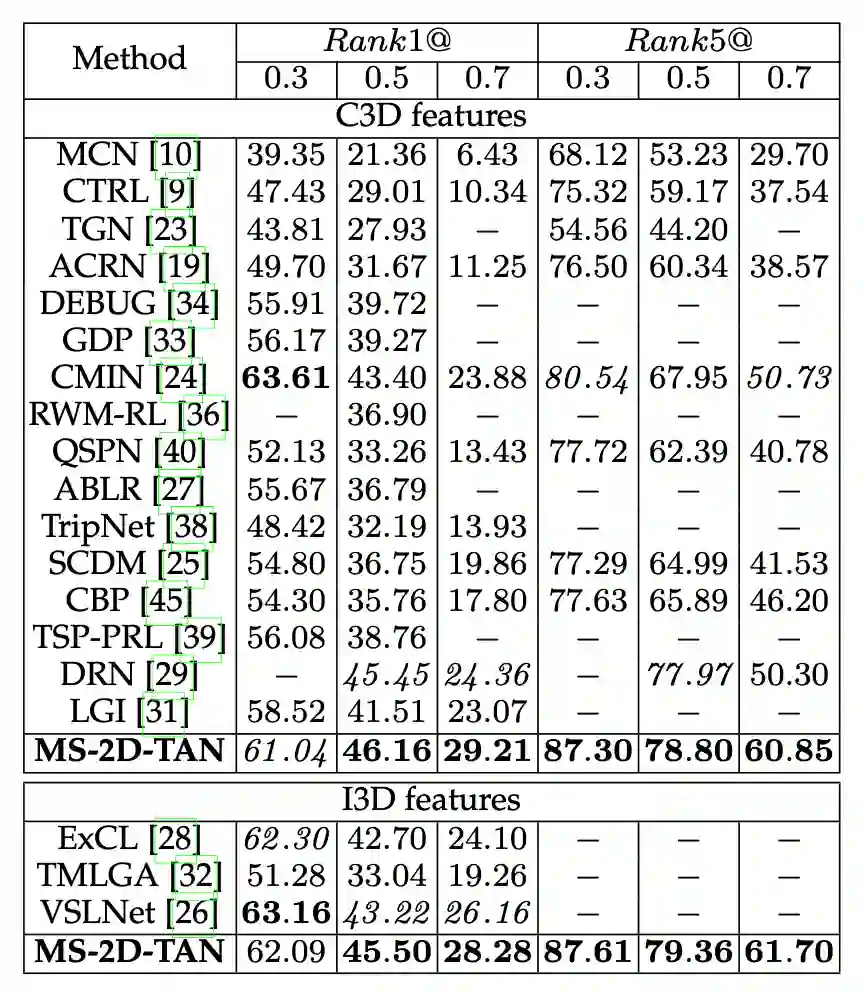
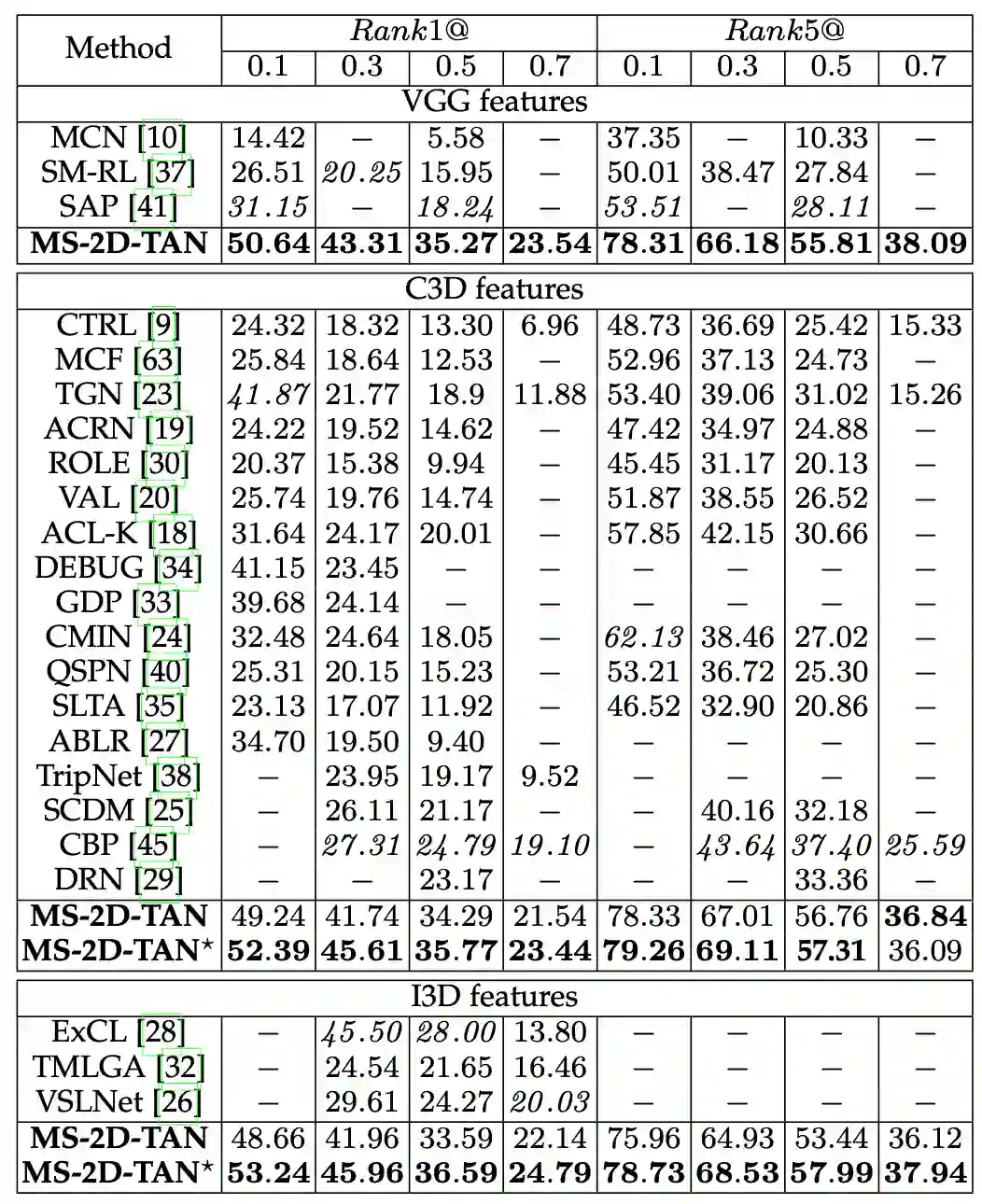
该研究在 Charades-STA [2], ActivityNet Captions [3] 和 TACoS [4] 三个数据集上评测。实验结果如表 1-3 所示。为了公平对比,该研究使用了和前人方法相同的视频和文本特征,且所有模型的超参保持一致。从实验结果中,无论使用哪种特征,该研究提出的 MS-2D-TAN 方法均能获得前两位的成绩。而在某些数据集上,进一步调整超参可以获得更好的性能,如表 3 的 MS-2D-TAN*。
![]()
![]()
表 2 ActivityNet Captions 的实验结果
![]()
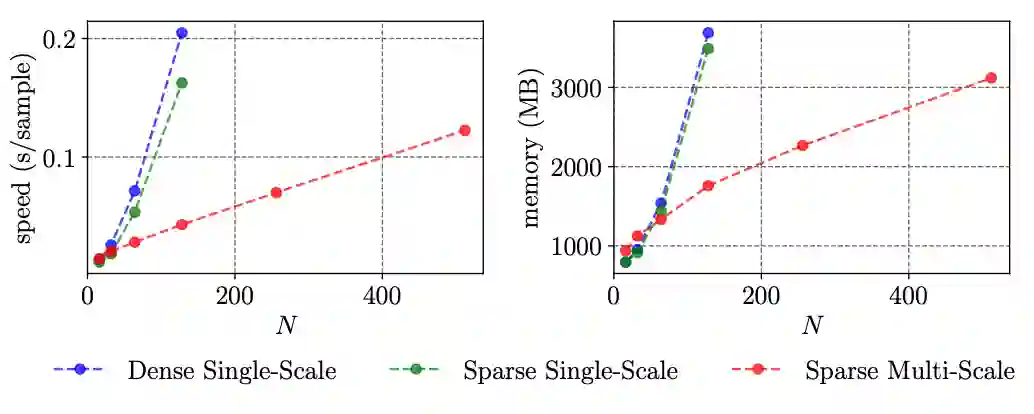
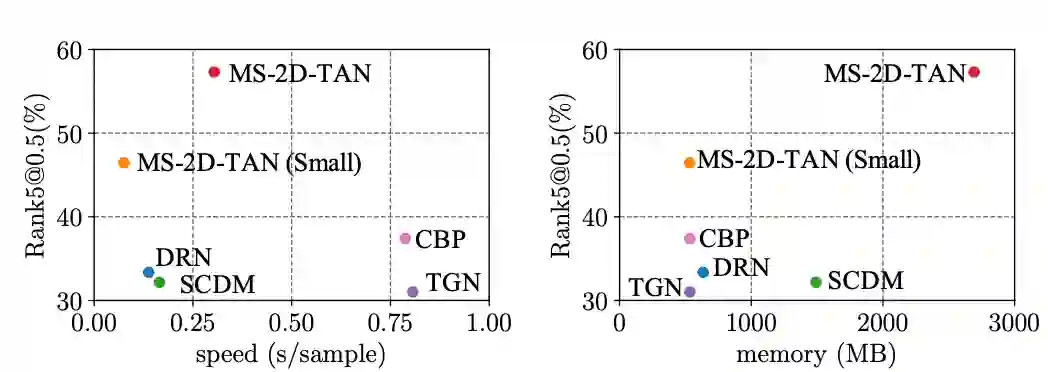
该研究还对比了时间和内存的开销。图 3 中对比了稠密单尺度二维特征图,稀疏单尺度二维特征图 [1] 以及本文提出的稀疏多尺度二维特征图。可以发现在当视频长度较长时,使用稀疏多尺度二维特征图可以大幅减少时间和内存的开销。在图 4 中该研究也与其他方法在 TACoS 上进行了对比。当研究人员使用一个隐层参数量较小的模型 MS-2D-TAN (Small) 时, 该研究的方法可以在保证速度和内存开销稍小的前提下,比其他方法获得更高的精度。而使用较大参数量的 MS-2D-TAN 可以进一步提高精度。
![]()
图 3 三种不同二维特征图时间开销的对比。N 表示多少个单元片段(clip)
![]()
本文针对基于文本的视频时间定位提出了一种全新的多尺度二维时间表示方式并提出了一种新的多尺度时域邻近网络(MS-2D-TAN)。该模型可以很好的利用邻近时域的上下文信息,并学出有区分性的视频片段特征。该研究的模型设计简单,也同时在三个数据集上取得了有竞争力的结果。
[1] Songyang Zhang, Houwen Peng, Jianlong Fu, Jiebo Luo, “Learning 2D Temporal Adjacent Networks for Moment Localization with Natural Language”, AAAI 2020
[2] Jiyang Gao, Chen Sun, Zhenheng Yang and Ram Nevatia, “TALL: Temporal activity localization via language query”, ICCV2017
[3] Ranjay Krishna, Kenji Hata, Frederic Ren, Li Fei-Fei, and Juan Carlos Niebles, “Dense-Captioning Events in Videos”, ICCV 2017
[4] Michaela Regneri, Marcus Rohrbach, Dominikus Wetzel, Stefan Thater, and Bernt Schiele, and Manfred Pinkal, “Grounding action descriptions in videos”, TACL 2013
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。
![]()
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿
![]()
△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
![]()