NLP极简数据增强+源码
对于变化莫测的神经网络,虽然有时候模型表现很好,但可能把输入加一些噪声就会生成完全相反的输出,这时候数据增强就很重要,一方面可以根据当前数据分布生成更多样化的训练数据,提升模型的效果;另一方面可以生成有噪声的测试数据,评估模型的鲁棒性。
NLP的数据增强一直是个难题,本来数据的标注成本就高一些,还不好添添补补,比如情感分类,把“不高兴”的“不”字去掉了,整句话的意思就变了。相比之下,图像不仅可以翻转、平移、加噪,还有高级的GAN,不知道NLP什么时候也能gan一把。
今天分享一个很简单的、基于马尔可夫链的生成式数据增强方法,比起纯规则的增删改来说,能生成多样化的句子,比起生成模型来说又没那么难,主要用于分类任务,可以快速实现,看看在自己的任务上有没有效果。
源码已上传至:https://github.com/leerumor/nlpcab/blob/master/code/markovdataaugmentation.py
基于马尔可夫链的数据增强
马尔可夫链指具有马尔可夫性质的离散随机变量的集合,马尔可夫性质是指在随机变量的序列中,下一状态的概率分布只由当前状态决定,与之前的时间无关,即:
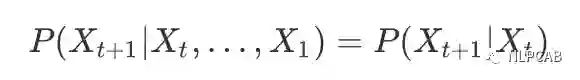
这样我们只要知道所有词之间的条件概率分布,就可以一个个地把词拼成句子。
具体的做法很简单,就是用词典(dict)保存两个词之间的关系,每个词是一个key,value是在该词后出现的所有词的列表。另外,可以只统计特定label下数据的条件概率,即每个label对应一个词典,这样就能根据label生成文本。最后,为了尽可能和数据集的分布一致,可以提前把句子的长度分布统计好,并在最后生成句子时指定长度。
大概的算法如下:
预处理:分词、统计句子长度分布
根据各个label的训练数据生成多个词典
根据词典和长度生成句子文本
用这种方法生成的数据可读性并不强,但在词向量+maxpooling这种分类场景下却比较实用,而且也可以作为带噪声的评估集查看模型效果。
效果展示
任务:新闻分类
数据:ChineseGLUE里头条新闻标题分类任务TNEWS的训练数据(链接见文末)
一共15个类,每类我都生成了一些数据,这里选取一些能看的分享下,以空格分割词语:
news_story: 救护车 当婚车 , 无意 听到 她 是 我 婚前
news_story: 想得美 ! 河北 情义 女子 离家出走 , 孩子 说
news_story: 一月 后 妻子 打工 回家 听到 儿媳 抠 ,
news_culture: 墨家 为什么 ? 黄药师 无意间 透出 答案 了 ?
news_culture: 刽子手 ? 推荐 ? 哪些 ? 原来 这么 差
news_entertainment: 大师 的 主题曲 , 马 天宇 古装 的 眼光
news_entertainment: 沦为 家妓 , 网友 : 想 与其 替身 合照
news_sports: 跌下 神坛 ? 听清哥 分析 两队 情侣 求婚 引
news_sports: 中德之战 , 索萨 信任 威廉 王子 , 如此 精明
news_finance: 第二十三 次 , 伊利 和 中国 股市 何时能 突破
news_finance: 周海江 : 马化腾 怒 怼 马斯克 豪掷 4 月
news_house: 90% 以上 ? 远 吗 ? 揭露 高房价 时间
news_house: 部委 发文 , 现在 一 楼盘 抢先 抛售 房子
news_car: 裸价 6 款 北汽 要火 ? 为啥 最 适合
news_car: 发达国家 的 SUV 车型 性价比 如何 选择 — CT6
news_edu: 伴 孩子 补 补课 , 再 不 懂得 感恩
news_tech: 亿万 身家 雷军 为什么 小商贩 小商店 都 盯上 了
news_military: 纸上谈兵 , 现在 盟友 失败 ! 伊朗 研发 核武器
news_travel: 大本营 住宿 100 元 , 上海 英式 设计 惊艳
stock: 下行 通道 , 年销售额 2000 万 , 怎么 走
news_agriculture: 强调 大力 整顿 , 农村 产业 示范园区 点名 ,
news_game: 蛇皮 走位 丝血 反杀 ! 《 剑网 三 》
目前还没有测试过在实际分类任务上的效果,但原po主在kaggle上的Uber Ride Reviews Dataset情感分析数据上得到了不错的结论。分别用这种方法生成了Augmented Train和Fake Test,用TF-IDF作为特征,感知机、逻辑回归、随机森林作为模型,效果如下:
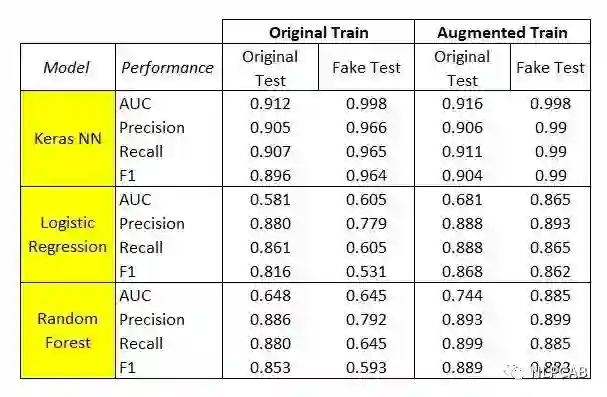
原po没用更复杂的模型,所以也不能肯定的说这种方法就好,只是对于简单模型有提升。
总结
介绍这个数据增强方法主要是因为它可以快速实现,又比纯规则的增删改强一些,可以用在简单的文本分类任务中;但具体情况也视模型而定,如果现有的数据很多、模型复杂度也够,增强训练语料可能会带来反效果,但这并不妨碍我们生成一些假样本测试模型的稳定性。另外,从生成的样本可以看出有不少地方可以改进,例如加入结束符、去重等。
感谢阅读~
参考资料:
https://towardsdatascience.com/text-data-augmentation-makes-your-model-stronger-7232bd23704
https://github.com/chineseGLUE/chineseGLUE
https://www.kaggle.com/purvank/uber-rider-reviews-dataset
本文转载自公众号: NLPCAB,作者:李如
推荐阅读
ELECTRA: 超越BERT, 19年最佳NLP预训练模型
T5 模型:NLP Text-to-Text 预训练模型超大规模探索
BERT 瘦身之路:Distillation,Quantization,Pruning
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLP君微信(id:AINLP2),备注工作/研究方向+加群目的。




