以感官神经元为转换器:用于强化学习的置换不变神经网络

- Paul Bach-y-Rita,引用自 Livewired
人类有一种神奇的能力,可以用一种感官方式(如触觉)为另一种感官(如视觉)收集通常由后者提供的环境信息。这种适应能力被称作是“感官替代”,是神经学中的常见现象。更加困难的感官替代则需要学习几周、几个月甚至几年的时间才能掌握,比如阅读 上下颠倒的文字、学习 倒着骑自行车,或者是通过分析放在舌头上的一根电极网格释放出的视觉信息来“看”东西。


感官替代的例子。上:舌尖显示装置(Maris&Bach-y-Rita,2011;Kaczmarek,2011)。下:“上下颠倒”的护目镜,最初由 Erismann 与 Kohler 于 1931 年构思,图片源于维基百科。
相比人类,大多数的神经网络 完全 无法适应感官的替换。
举例来说,多数强化学习(RL)代理需要特定的输入格式,否则将无法进行学习。它们需要特定大小的输入,并假定输入中的每一个元素都准确包含特定含义,比如指定位置的像素数、位置或速率的状态信息。
在常见的 RL 基准任务中(比如 蚂蚁 或 倒立摆),如果感官的输入发生变化,或者使用与目前任务无关的额外噪音输入,那么使用当前 RL 算法 训练的代理将会失败。
在 NeurIPS 于 2021 年 发布的一篇 重点论文,《以感官神经元为转换器:用于强化学习的无空间相关性的神经网络》中,作者探讨了无空间相关性的神经网络代理是如何不再假定含义固定不变的输入,而是要求其每一个感官神经元(从环境中接受感官输入的感受器)来判断输入信号的含义和语境。实验证明,这类代理对包含噪音或多余且重复的,缺失不完整的的观测输入具有鲁棒性。


无空间相关性的强化学习代理适应感官替代。上:蚂蚁运动的 28 种观测排序在每 200 time-step 后随机洗牌。与标准策略不同,作者的策略不受输入突然置换的影响。下:添加过多重复噪音输入后的倒立摆代理(网页互动 demo)。
除了在状态观测环境中适应感官替代(如前文中提到的蚂蚁和倒立摆),这些代理还可以在复杂的视觉观测环境(如只使用像素观测的 赛车游戏)中适应感官替代,并在输入图像流不断变化时,依旧可以运行。

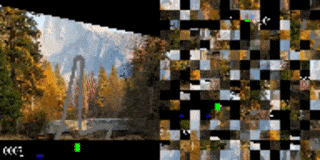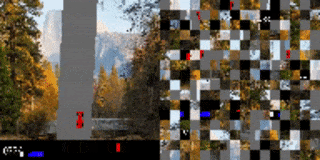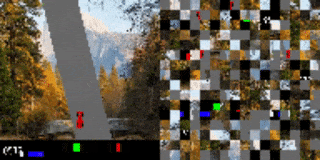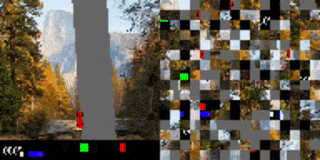
作者将赛车游戏中的视觉输入分散至多个 2D 网格,并打乱顺序。在无额外训练的情况下,代理在原始训练背景(上)被替换为新的图像(下)后,依旧表现出色。
作者采用的方法是,在每个 time-step 时从环境中获取观测结果,并将观测到的每个元素输入不同但又相同的神经网络(感觉神经元)中,每个神经元之间没有固定关系。而随着时间的推移,每个感觉神经元只会接受它们特定的感觉输入通道的信息。而因为每个感觉神经元只会接受全部输入中的一小部分,它们需要通过交流并进行 自我的调整,以保证全局行为的 一致性。
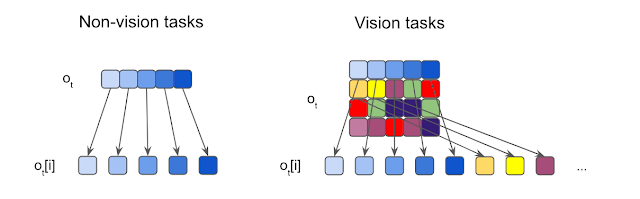
观测分割的图示。作者将每个输入都分割为元素,并输入到各个独立的感觉神经元中。对于非视觉的任务,输入通常为 1D 向量,每个元素都是一个标量。而对于视觉任务,作者则将所有输入图片切割为不重叠的小块。
作者训练神经元通过广播传递信息,激励其进行互相之间的交流。在接受本地信息的同时,每个感觉神经元会同时在每个 time-step 不断广播一个输出信息。这些信息会被整理并合并为一个输入向量,作者称之为全局隐代码(global latent code),使用的方法类似 转换器 架构中应用的注意力机制。随后,作者使用一个策略网络将这些全局隐代码所生成的动作应用于代理与环境间的互动。这个生成的动作也会在下一个 time-step 中反馈给各个感觉神经元,从而结束通信的循环。

无空间关联的 RL 方法概况。作者首先将每个单独的观测(o)输入到一个特定的感觉神经元中(同时输入的还有代理的前一步动作,a)。然后,每个神经元会独立生成并广播一个消息,注意力机制将这些消息整理为一个全局隐代码(m)并传递到代理的下游策略网络(),以生成代理的行动 a。
为什么说这个系统是无空间关联的呢?因为所有的感觉神经元都是一模一样的神经网络,而这些神经元所处理的信息并不局限于一个特定的感觉输入。
事实上,在实验的设置中,每个感觉神经元的输入都是没有定义的。每个神经元必须对其收到的输入信号进行判断,不能直接假设某个固定的含义,而是要通过对比其他感觉神经元所接收的消息才能够确定。
这种设置鼓励代理将完整的输入当作是一个 无序集合 来处理,让系统与其输入之间无空间关联。此外,代理原则上可以根据需要接触尽可能多的感觉神经元,从而可以处理无固定长度的观测。这两个特性都对代理适应感官替换起到了协助的作用。
作者在简单的状态观测环境中的测试展示了该方法的鲁棒性与灵活性。在这些测试中,代理所接收的观测输入都是低维度向量,其中包含了代理的诸如组件位置或速率之类的状态信息。
在常用的蚂蚁运动任务中,代理使用了总共 28 个包含位置和速率信息的输入。在测试中,作者多次打乱输入向量的排列顺序,每次代理都能够迅速适应,并继续向前行走。
在 倒立摆 的实验中,代理的目标是将小车中心底部固定的杆保持垂直向上的平衡状态。通常情况下,代理只会只能接受到五个输入,但作者调整了倒立摆的环境,并提供了 15 个打乱后的输入信号,其中有 10 个是纯噪音,剩下的则是实际来自环境的观测。
这种情况下,代理依旧可以正常运行,证明了系统有能力在大量 信号输入的情况下工作,并可以做到只关注它认为有效的频道。这种灵活性在处理含有大量不确定信号、其中多数都是来自未明确系统的噪音信号这类应用时,会有大作用。
作者还将这种方法应用在了一个于基于视觉的高维环境中,其中的观测对象是像素图像流。作者研究的是图像打乱后的、基于视觉的 RL 环境,每个观测帧都被分割为一个网格块。而就像是解密卡一样,代理需要首先将打乱后的小块全部处理完,才能确定要采取的行动方案。为证明该方法在基于视觉的任务上的可行性,作者创建了一个打乱顺序的 Atari Pong 游戏。

乱序 Atari 乒乓游戏结果。经过训练的乒乓代理在只使用 30% 图像块的情况下,已经可以和 Atari 对手旗鼓相当。
在这个实验案例中,代理面对的输入是一个长度可变的图像块列表,它只能“看见”画面中的一部分图像块。在乱码后乒乓实验中,作者将画面中的随机图像块样本作为输入传递给了代理,而被选择传递的图像块位置在整场游戏中保持不变。
实验证明,在扔掉 70% 的图像块(都是固定位置的随机块)后训练出的代理仍然可以在和内置 Atari 对手比赛时表现良好。有趣的是,如果向代理传递更多的信息(如,允许它访问更多的图像块),无需更多训练,代理的性能就可以得到提高。如果代理可以接收到所有的图像块,那么即使输入是乱序的,它也可以做到百分百的胜率,这点与观测到全部屏幕的代理训练结果相同。
作者发现,使用无序的观测来增加训练难度会有额外的收获;比如提高对未见过变种任务的一般概括性,或者适应 赛车 训练环境的背景被替换成全新图像的情况。

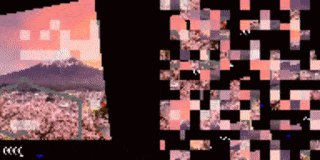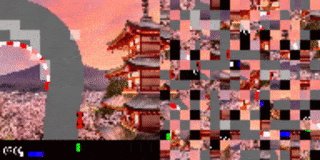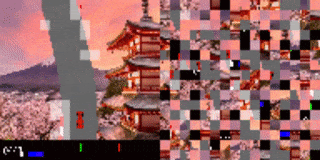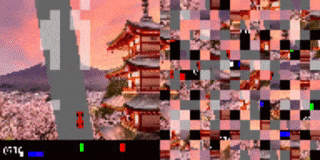
打乱顺序后的赛车测试结果。代理已学会如何将重点(图中显示为高亮的小块)放在道路边界线上。左:训练环境。右:更换全新背景后的测试环境。
文中提出的无空间关联的神经网络代理可以处理未明确的或不断变化的观测空间。作者训练的代理在面对包含冗余或嘈杂信息的,或者是缺失不完整的观测时具有鲁棒性。作者相信,这种无空间关联的系统将会为强化学习提供更多的可能性。
如果你对这个项目感兴趣,欢迎阅读作者的互动文章(https://attentionneuron.github.io/)(以及pdf(https://arxiv.org/abs/2109.02869)版本),或者点击该视频(https://youtu.be/7nTlXhx0CZI)。如果希望能重现该实验,可参见作者公开发布的代码(https://github.com/google/brain-tokyo-workshop)。
作者:
东京 Google 研究院科学家 David Ha,软件工程师 Yujin Tang
原文链接:
https://ai.googleblog.com/2021/11/permutation-invariant-neural-networks.html

你也「在看」吗?👇




