干货 | 解密美图大规模多媒体数据检索技术DeepHash
雷锋网 AI 科技评论按:本文为美图云视觉技术部门哈希项目团队向AI科技评论提供的独家稿件,未经许可不得转载。
「美图短视频实时分类挑战赛 MTSVRC」也于近日正式启动,本次挑战赛由中国模式识别与计算机视觉学术会议主办,由美图公司承办,中科院自动化所协办,详情可点击「阅读原文」了解往期内容。在雷锋网旗下学术频道AI科技评论数据库产品「AI 影响因子」中,美图云视觉技术部门凭借 AAAI 2018 oral 论文和举办相关赛事表现不俗,本次凭借独家技术解读也获得了相应加分。
美图是一家拥有海量多媒体数据的公司,如何有效分析理解这些数据内容并从中挖掘出有效信息,对我们提出了重大挑战。本文以美拍业务为例,介绍我们在海量短视频数据的内容分析理解和大规模检索技术方向的探索和实践。
多媒体数据相似性检索可以简单理解为用不同媒体素材将其进行特征表达,然后在相应的特征空间里进行查找和排序。特征表达有两种方式:一种是通过传统方法提取的视觉特征,比如关键点特征、颜色直方图等;另一个是基于深度学习提取它的底层基础特征或高层语义特征(深度特征)。美图 DeepHash 是基于深度哈希技术的大规模多媒体数据检索系统。系统依托于海量多媒体数据,分为算法和服务两大模块。
/ DeepHash 视频哈希算法 /
我们针对美拍短视频内容特性,从标签制定,数据处理到算法网络设计等层面提出一系列定制化的算法优化策略。
在讨论具体技术方案之前,我们先来思考一个问题:如何描述一个视频?在使用视频哈希技术之前,我们采用的是用标签体系来描述视频。图 1 所展示的是美拍最常见的标签体系,音乐、宠物、舞蹈、教程等,用标签体系描述视频的缺陷是:标签主要是对视频内容进行概括、描述性的词汇,包含信息量较少,一些细节的信息是无法体现的,标签是离散型的描述。而人类是如何描述一个视频呢?以左上角视频截图为例,人类看了会说:它是两个穿着淡蓝色衣服的小女孩在弹着吉他唱歌。由此可发现,人类是用视觉特征来描述视频,所包含的信息丰富、维度多样,是连续型的描述,显然这是一种更合理的描述方式。
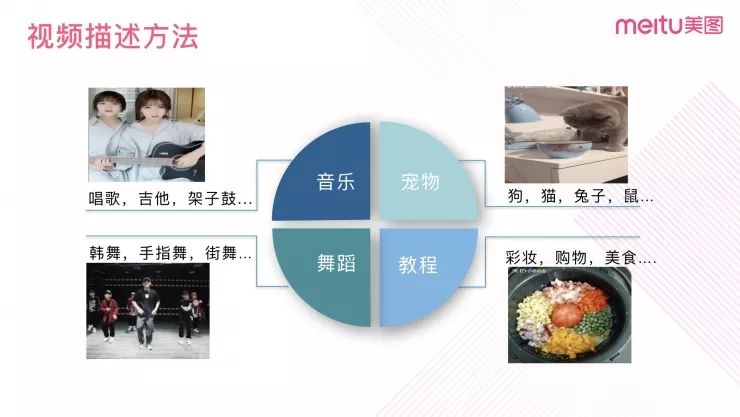
图 1
进一步说,用标签来描述视频存在以下问题。
1. 信息表达能力弱,无法体现更细粒度的信息。如图 2 所示的视频截图,是一个穿着绿色汉服的女生在公园里跳舞。它的内容标签是舞蹈,很难通过标签读取出其他信息。如果尝试更复杂的标签体系,比如加上场景、物体、性别等维度,可以发现很难穷举出所有的状况,即使做到标注成本也非常大。

图 2
2. 很难比较信息之间的相似性,信息难以度量。如图 3 所示的三个视频标签都是「狗」,很难通过标签去辨别哪两个视频更相似,如果用视觉特征很容易就发现左边的视频与右上角的视频更相似。当然我们可以用狗的种类和数量来计算两幅图之间的相似性,但是当图片内容比较复杂,物体较多时,这种方式难以适用。

图 3
使用特征表达视频
视频哈希算法使用视觉特征来描述视频,它具有以下几个特性:
1. 多样性。特征包含更多维度的信息,信息量更多,可表达的内容是多样的;
2. 鲁棒性。如果两个视频比较相似,它们表达出来的特征也比较相似,提取出来的特征也应该是稳定的;
3. 距离可计算。特征之间是可以计算距离的,用距离描述两个特征的相似性,距离越小,视频内容越相似。
基于特征的视频检索技术的应用场景广泛,如视觉相似视频推荐,特定视频检索,视频审核,视频去重等等;此外,还可以利用提取的视频特征进行特征聚类和内容挖掘,挖掘其中的热点内容和发现新类。
特征表达方式
常用特征表达方式有两种:浮点型特征和二进制特征。
二进制特征在存储、检索速度两方面有显著优势:使用二进制存储,十分高效;计算距离使用汉明距离,检索速度更快。而浮点型特征距离计算一般使用欧式距离或余弦距离,计算复杂度较高,检索速度较慢;另外浮点特征还存在极值干扰的问题,会影响距离计算。二进制特征都是 0 和 1,特征较为稳定。基于以上情况,我们业务中采取了基于二进制形式的特征表达方式。
哈希特征提取
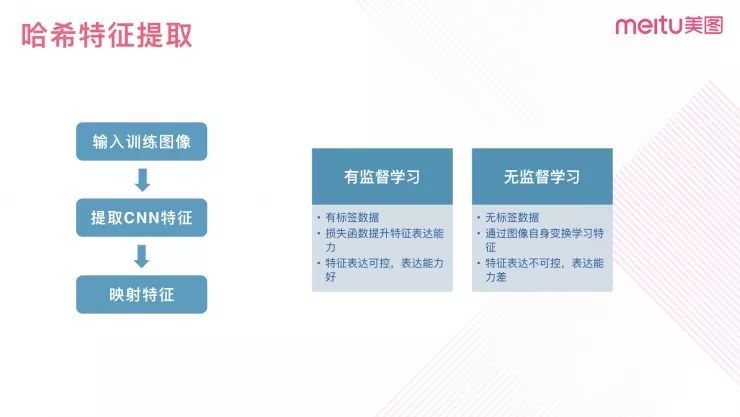
图 4
视频哈希特征的一般提取流程为:卷积神经网络提取视频特征,将特征映射成固定长度的浮点型特征,在浮点型特征后面接 sigmoid 层映射到 [0,1] 区间范围内,通过阈值化量化为二进制形式。
用于提取哈希特征的网络模型的训练可以分为有监督和无监督两种形式。有监督学习基于有标签的数据进行训练,加以特定的损失函数提升特征的表达能力。它的特点是特征表达是可控的,可以通过标签来告诉这个网络重点学习哪些特征;无监督学习基于无标签数据进行训练,通常通过图像自身变换学习特征表达能力,所以特点就是特征表达不好控制,较难干预网络应该学习哪种特征。无监督学习目前还处于学术研究阶段,业务难以直接应用。因此,我们当前采用的方案也是基于有监督的视频哈希算法。
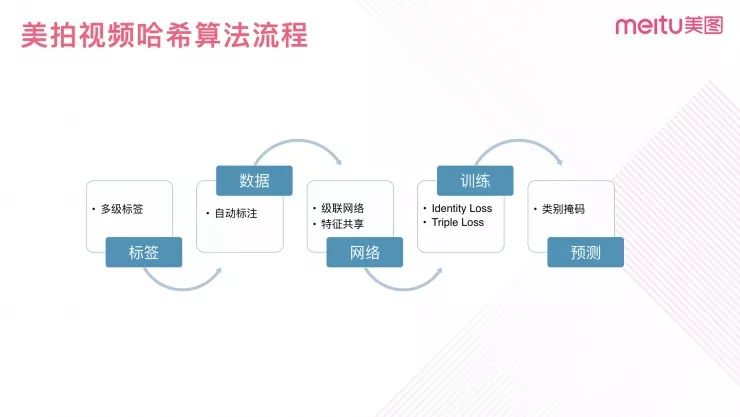
图 5
美拍视频哈希算法流程主要分为五个模块:标签、数据、网络、训练和预测。对于每个模块,我们都基于美拍的数据特点和业务逻辑做出了一些定制化的优化策略。下面分别介绍这五个模块的相关工作。
标签
美拍有上百类的标签体系用于内容运营,涵盖了美拍短视频常见的内容和类别。但这些现业务标签并不适合直接拿来做算法的训练,主要存在以下问题:
1. 数据不均衡
图 6 是美拍热门视频的标签分布,可以看出各个类别数据量极度不均衡。而在算法训练的时候如果有一些类别数据量比较小,那么网络就很难学习到这些类别的特征学习表达能力。
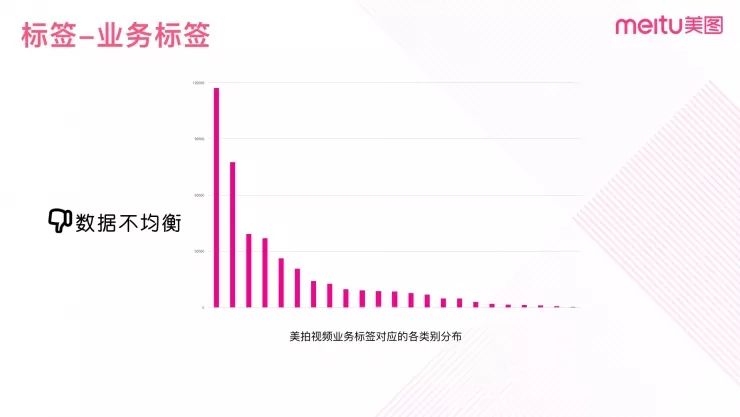
图 6
2. 视觉不可分
业务标签体系没有针对视觉特性进行划分,造成不同类别的视频在视觉上不可分。直接拿这种标签进行训练就会造成很多误分,网络难以学到各个类别之间的特点。

图 7
3. 维度单一
业务标签体系是针对最主要语义内容上的划分,无法体现其它维度的信息。如服饰、场景、性别等维度不能通过这个标签体系来体现。通过这个标签体系训练网络无法学习到其它维度的特征表达。
针对以上三个问题我们提出了多维度多级标签体系。「多维度」指可以根据业务需求给标签体系增加维度;「多级」体现在它是分级的,建立第一层级时要在视觉上是可分的,如刺绣、美妆、手指舞等这些类别在视觉上都和自拍比较相似,就将这些类别在第一层级分为一个类,保证视觉可分性。
但是,多维度多级标签体系会带来一些新的问题。首先,海量数据都进行多维度打标,标注成本太高。其次,我们采取的模型网络结构是级联的方式,每个第一层级的类别都有相应的第二层级模型进行特征提取,模型数量很多,计算复杂度也会很高。为解决这两个问题,我们在数据标注和网络设计两方面进行了优化。
数据
数据方面我们采用自动标注的方法,降低标注成本。如对一批已经标注了内容标签的视频数据,我们需要对它进行服饰维度的打标。那么自动标注的流程是:
1. 标注少量的数据。
2. 用少量数据训练单独的分类器,通过调整置信度等方式使分类器的准确率在 99% 以上,即该分类器输出结果置信度高于某阈值则结果是可信的。
3. 用这个分类器对数据进行自动标注,置信度高的部分保留它们的服饰标签。置信度低的这部分由于不确信服饰标签是否准确,所以服饰标签统一记为 -1。在网络更新的时候这部分数据只更新内容标签的损失,不更新服饰标签损失。
网络
为了使视频特征可以包含多维度的信息,训练时采用多标签联合训练的方法,减少多维度的模型复杂度。
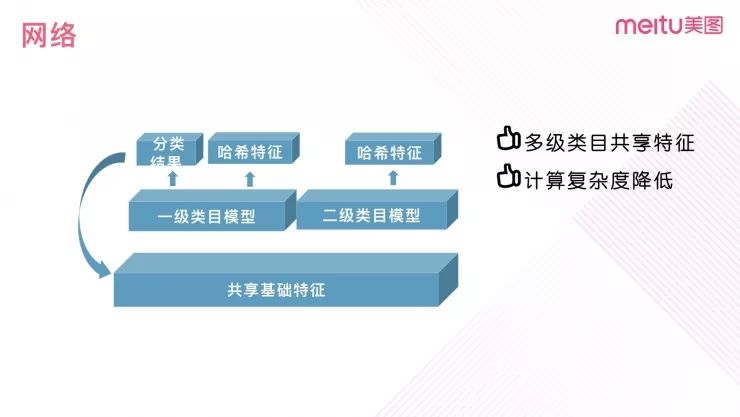
图 8
针对上文提到的二级模型计算复杂度高的问题,我们采用共享特征的方法进行优化。即对视频网络提取共享的基础特征,共享特征先送入一级类目模型进行分类和特征提取,根据一级类目模型分类结果调用相应的二级类目模型进行特征提取。采用 MobileNet 作为基础网络,每个视频提取 5 帧数据,推理两级模型,在 Titan X 上可以到达 100 个视频/秒的处理速度。
训练
在网络训练的阶段采取 Triplet loss 的方式增强特征的表达能力。Triplet loss 会拉近相似视频之间特征的距离,拉远不相似视频间的距离。
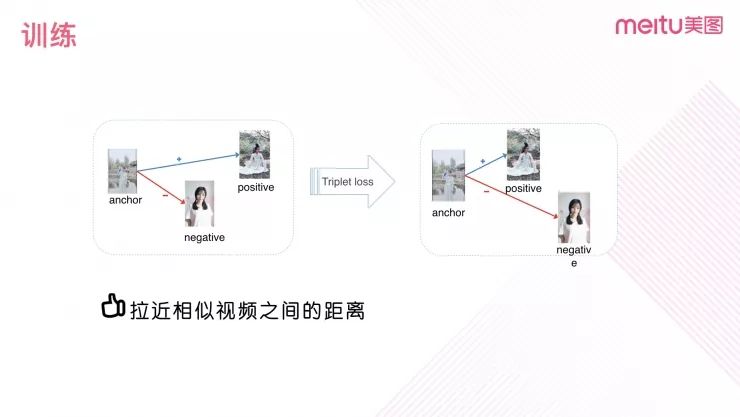
图 9
训练 Triplet loss 的时候如何有效选取正负样本对是一个比较关键的问题。我们通过提取间隔帧的方式选取正样本视频,假设一个视频提取 10 帧,其中第 1、3、5、7 、9 帧作为目标视频截帧,第 2、4、6、8、10 帧作为正样本视频截帧,而负样本视频截帧来自不同类别的其它视频。这样做的好处有两点:1. 正样本视频与目标视频比较相似,容易收敛;2. 无需标注,减少标注成本。
预测
在得到特征哈希码之后,我们通过类别掩码的处理方式提高检索准确率。类别掩码的作用是隐去低贡献度的特征位,保留重要的特征位。
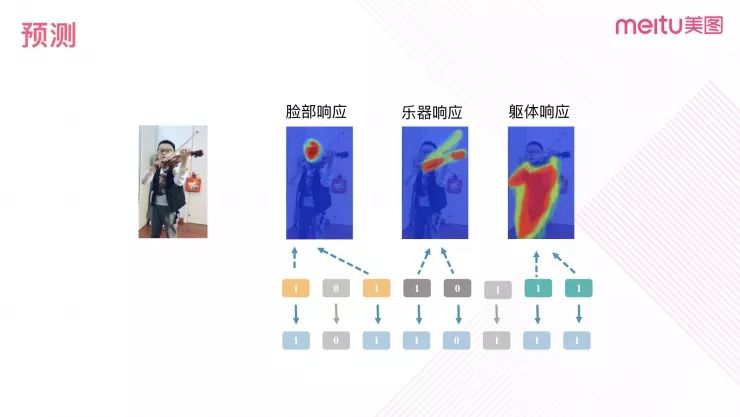
图 10
如图 10 所示,我们认为特征不同的位置之间存在分工。而找到重要特征的比特位置所需要的信息保存在网络最后一层的权重参数里。
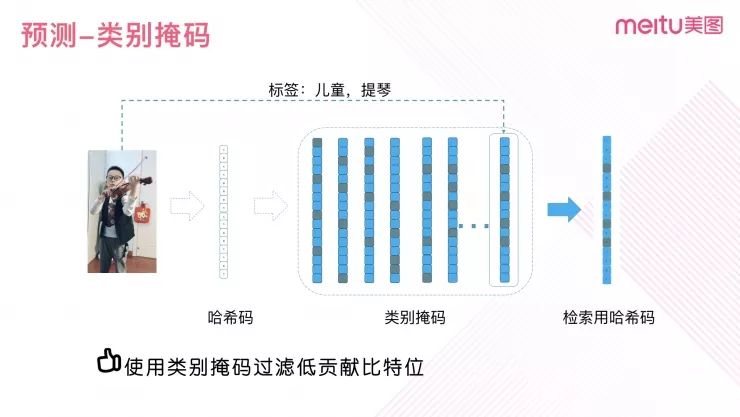
图 11
图 11 展示了类别掩码的提取方法,中间部分是网络的分类层权重参数。它的形状等于类别个数乘以特征长度,权重的每一列都代表着相应的类别。当我们把视频输入到网络里得到它的类别后就可以找出相对应的类别权重,对这列权重值取绝对值,从大到小进行排序,我们发现这些绝对值比较大的权重位置就是哈希特征中比较重要的位置。
关于类别掩码的细节描述可参考论文《Deep Hashing with Category Mask for Fast Video Retrieval》
论文地址:https://arxiv.org/pdf/1712.08315.pdf
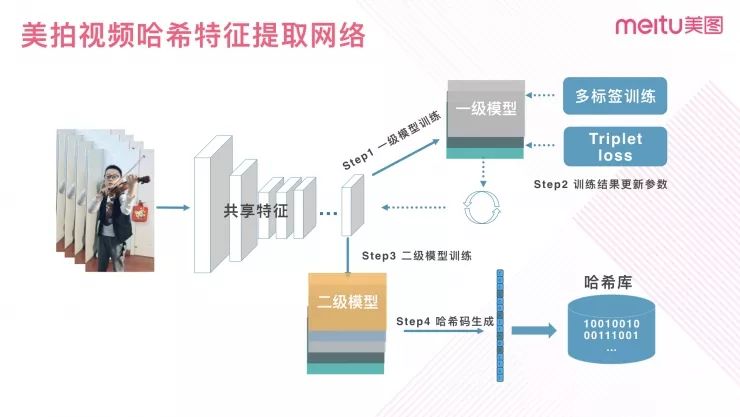
图 12
图 12 展示了网络的整体流程。采用多标签联合训练的方式,加上 Triplet loss 提升表达能力,网络结构采用级联模型以及共享特征的方法。最后采用类别掩码提高检索精度。
效果

图 13
图 13 展示了该模型的准确率和检索效果图。其中检索效果图里左上角的视频为目标视频,其后为检索结果。
/ DeepHash 多媒体检索服务 /
前面提到 DeepHash 系统包含两大模块:算法和服务。前面以美拍视频为例,介绍了我们视频哈希特征提取算法。接下来我们介绍 DeepHash 系统的服务部分。
DeepHash 服务分为离线任务和在线任务。离线任务负责生成海量视频数据的哈希码,作为目标特征库。具体内容包括模型训练和特征生成两个模块。UGC 短视频数据具有较强的时效性,不同时间段的视频主题内容不同,所以业务上需要使用最新数据定期训练并更新模型。在得到新的网络模型之后,需要批量处理历史视频生成新的哈希码,并更新到目标特征库中。
在线任务负责实时处理检索请求,并将相似结果返回给调用方。当一个检索请求过来,查询模块会先去海量目标特征库中查询当前请求的视频哈希是否存在,如果存在,则使用当前哈希码,与目标特征库的哈希码计算距离,返回 top 相似结果;如果不存在,那么服务会调用预测模型,提取该视频的哈希码,使用该哈希码到目标库里检索,同时将预测得到的哈希码加入目标特征库。
架构演化
DeepHash 服务从最初的单库热门池视频支持到最新版本能支撑全量视频检索,经历了三个阶段的版本迭代和优化。
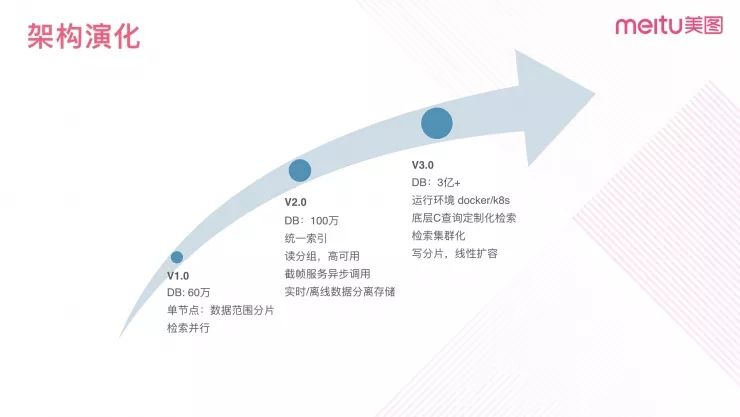
图 14
V1.0 最初版本运行在单节点上,只对于特征库进行分片、并行查找的优化,该版本支持百万以内的基础特征库检索。
V2.0 版本支持更多形态的媒体数据的检索,在这个版本我们接入了音频特征提取算法。同时支持视频和音频两种形式的相似检索。为了支持多种类型的媒体特征,V2.0 进行了索引统一,对于基础特征库进行分组分片 (分组:分类,先定位到类别,再进行数据分片查询),同时提高检索稳定性。视频截帧采用异步调用方式减少 IO 阻塞。
V3.0 是目前正在开发的版本,运行在容器化集群上,同时进行了检索集群化的优化,目标是支持亿级的海量特征基础库的实时检索。
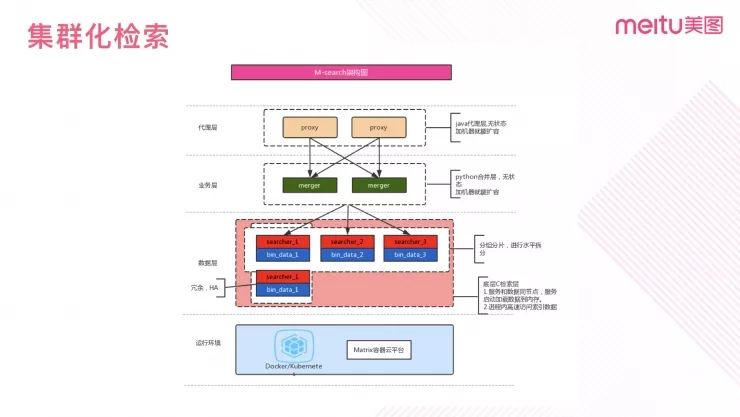
图 15
图 15 是检索集群的业务逻辑分层结构。其中,代理层负责请求分发,高并发时可无状态扩容;业务层对数据进行预处理包装、调用数据层的检索服务,并把结果封装成用户可读的形式;数据层运行检索算法,分片加载特征库数据,进行并行检索,保证检索的时效性、稳定性。
性能
接下来我们展示 DeepHash 系统的检索性能。存储性能上,使用一个 128 位的哈希码表示一个视频,存储 1 亿条视频,需要的存储空间只有不到 1.5 GB。检索速度上,运行 8 个实例,对 100 万的基础特征库进行全量视频检索,需要 0.35 S;使用 50 个实例,对 3 亿的基础特征库进行全量视频检索,只需要 3 秒。
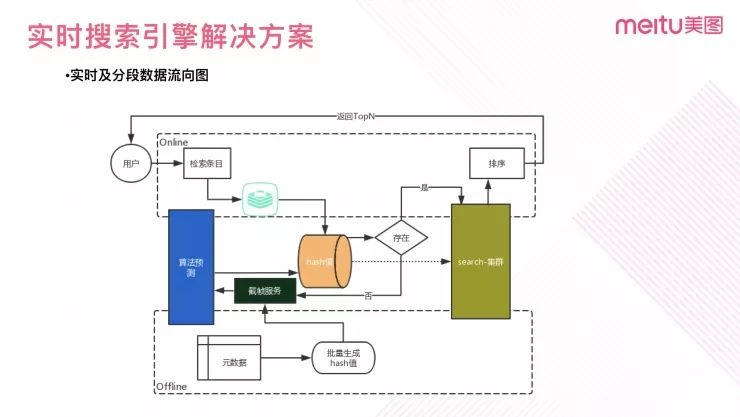
图 16:DeepHash 实时搜索引擎解决方案
展望
DeepHash 是一个通用型多媒体检索系统,除了已经支持的视频和音频相似性检索,接下来会接入更多类型的媒体数据,如增加对图像和文本等数据的检索支持。
/ 业务应用 /
目前 DeepHash 系统正在服务于推荐业务中的相似视频检索和运营业务中的视频去重。接下来也会接入审核业务。

图 17
┏(^0^)┛欢迎分享,明天见!



