在企业中,我们做模型的目的就是为了能够让它来更好的解决产品在实际生产过程中所遇到的具体的问题,而模型训练好之后,下一步要做的就是将其部署上线。AI对于很多企业来讲是一个新的领域,所以很多企业在训练好一个模型之后,对于模型部署方面总是会显得束手无策。
在企业中,我们所做的AI项目,从大的方面来分,可以分成在线模型和离线模型两种,每一种类型的模型根据业务场景的不同会有不同的选择,例如,我们在推荐系统中,很多任务并不是要求实时得出结果的,尤其是在做召回的这个阶段,有时候一天做一次召回,有时候可能一周做一次召回都可以,针对于这类的模型,我们就没有必要去关注他的实时效率问题。再比如,有些文本审核平台,需要实时审核用户的发帖信息和一些在线的言论,有一些敏感的内容一旦发出去,就很有可能导致一些非常严重的后果,那么这个时候,我们就需要模型能够进行实时预测,此时,对于模型预测的效率要求就非常高了,甚至对于并发量还有一定的要求;还有一种情况,就是我们可能不一定需要实时给用户进行反馈,但是可能需要在几分钟只能告诉用户一个结果,对于这样的情况,我们一般叫做nearline模型,那么下面我们就针对于这几种模型的部署来做一个简单的探讨。
离线模型存在于很多业务场景中,其中最常见的业务场景就是用在推荐系统的召回阶段,由于在推荐系统中,召回并不要求是实时的,可以根据业务的需要,调整成每天一次,或者每几个小时跑一次即可,因此,这类的模型,一般我们只需要使用Linux下的crontab定时任务脚本,每隔一段时间来启动一次就可以,然后将log文件输出到指定的文件下即可。这种方式一般来讲仅限离线模型的部署,其本质上就是一段定时任务的代码。在这里我们不做过多的展开。
在线(Online)/近似在线(NearLine)模型
在线模型或者说是实时模型是我们这次要重点来说的一种模型的部署。在生产系统中,实时推理和预测是最常见的需求,也是对于很多深度学习模型来说所必须达到的点。下面我们来说一下深度学习模型在实时预测时常见的几种部署方法:
将模型直接打包成一个http接口的形式是在企业中比较常见的模型上线的方式,所谓的将预测直接打包成http接口实际上一般是指将我们训练好的模型直接在线上进行预测。我们来试想一个场景,当一个模型训练好之后,我们如果想要验证这个模型的好坏,我们首先能想到的办法就是找一批数据来测试一下。实际上,将模型预测直接打包成http接口也是利用了这样的思路。
在这里,我们可以将训练好的模型提前进行加载,并初始化若干个消息队列和worker,当有新的待预测数据进入的时候,我们直接将数据通过消息队列传入到模型中进行推理和预测,最终得到结果。
而对于外层接收输入,我们一般可以将接收的地方使用flask打包成一个http接口,等待传入即可。
使用这种方式直接打包成http接口的好处在于打包和部署相对比较方便,对于一些相对比较轻量级且对并发量要求不是很高的情况下相对还是比较好用的。使用值得注意的是,如果对于一个相对比较大的模型来讲,这种方式推理的时间相对就会比较长,从用户输入到结果返回可能需要200ms左右。
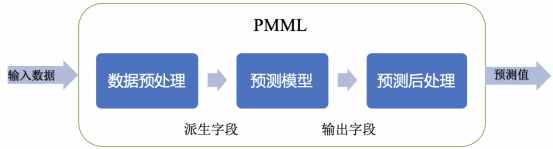
PMML是一套通用的且与平台和环境无关的模型表示语言,也是目前机器学习在模型部署方面的一种标准部署方案,其形式是采用XML语言标记形式。我们可以将自己训练的机器学习模型打包成PMML模型文件的形式,然后使用目标环境的解析PMML模型的库来完成模型的加载并做预测。
PMML是一套基于XML的标准,通过 XML Schema 定义了使用的元素和属性,主要由以下核心部分组成:
数据字典(Data Dictionary),描述输入数据。
数据转换(Transformation Dictionary和Local Transformations),应用在输入数据字段上生成新的派生字段。
模型定义 (Model),每种模型类型有自己的定义。
输出(Output),指定模型输出结果。
目前,大部分机器学习库都支持直接打包成PMML模型文件的相关函数,例如在Python中的LightGBM库,XGBoost库,Keras库等,都有对PMML的支持,直接使用相应的命令就可以生成,而在Java、R等语言中,也有相关的库可以进行PMML文件生成的命令。
由于其平台无关性,导致PMML可以实现跨平台部署,是企业中部署机器学习模型的常见解决方案。
使用TensorFlow Serving进行模型部署对于TensorFlow开发者而言是一件非常nice的事情,其实网上有很多关于TensorFlow Serving的介绍,也有专门讲如何使用TensorFlow Serving进行模型部署的。实际上,我们使用TensorFlow Serving进行服务部署,一般需要2台以上机器,其中一台作为TensorFlow Serving的服务器,这台服务器是专门来做模型部署和预测用,对于这台服务器,一般我们建议使用GPU服务器,这样会使整个推理预测的过程变得很快;另外一台服务器是业务服务器,也就是接收用户的输入以及其他业务处理的服务器。我们可以把模型部署到TensorFlow Serving的服务器上,而一般我们只需要先在服务器上使用docker创建一个TensorFlow Serving服务,然后将模型文件上传上去,当有请求进来的时候,业务服务会直接对模型所在的服务器发起服务调用,并得到模型预测的结果。一般来讲,整个流程如下:
这种方式对于一直在使用TensorFlow进行模型开发的同学来说非常方便,只需要简单的几行代码就能搞定。