【NeurIPS2021】上亿量级规模高效向量近似最近邻搜索系统 SPANN

SPANN: Highly-efficient Billion-scale Approximate Nearest Neighbor Search
https://arxiv.org/abs/2111.08566
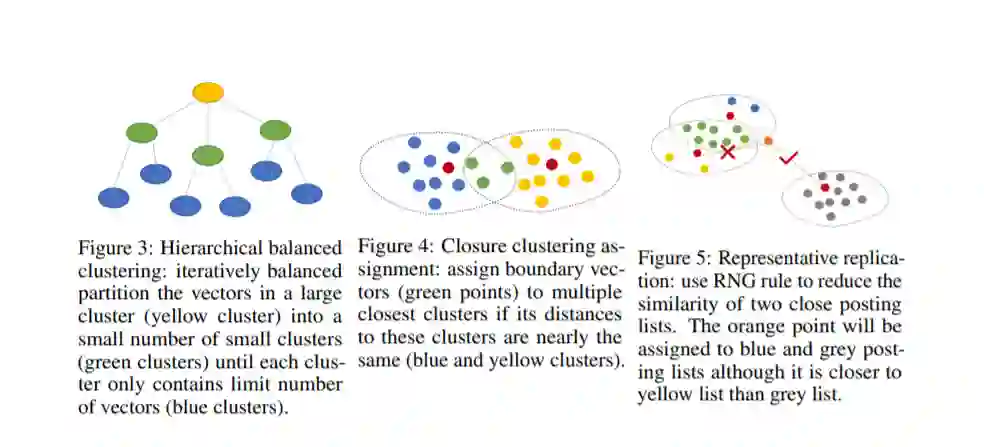
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“SPANN” 就可以获取《【NeurIPS2021】上亿量级规模高效向量近似最近邻搜索系统 SPANN》专知下载链接



登录查看更多
相关内容
专知会员服务
16+阅读 · 2022年3月17日
Arxiv
0+阅读 · 2022年4月15日





相关VIP内容
专知会员服务
16+阅读 · 2022年3月17日
相关资讯