百度开源AI视频大赛夺冠模型,手把手教你用PaddlePaddle实战
AI看视频识别人类行为有多准?目前最好的成绩是错误率10%左右。
计算机视觉顶会CVPR上,有一项名叫ActivityNet Kinetics Challenge的比赛,就是这类算法的竞技场。2018年的冠军,正来自百度视觉组。
现在,他们的夺冠模型StNet开源了。百度工程师们还写了一篇文章,从架构到用法详细介绍了这个模型。
百度视觉技术部联合PaddlePaddle团队近期开源了用于视频分类的StNet框架。StNet框架为ActivityNet Kinetics Challenge 2018中夺冠的网络框架。本次开源了基于ResNet50实现的StNet模型。
该模型提出“super-image”的概念,在super-image上进行2D卷积,建模视频中局部时空相关性。另外通过temporal modeling block建模视频的全局时空依赖,最后用一个temporal Xception block对抽取的特征序列进行长时序建模。
该框架在动作识别方面优于一些最先进的方法,可以在识别精度和模型复杂性之间取得令人满意的平衡。
应用背景
视频当中的动作识别任务已经获得了许多从事计算机视觉与机器学习研究人员的重点关注。越来越多的视频录像设备的普及,让更多好玩有趣的视频丰富了人们的业余生活。但是过多的视频已经远远超过人工能够处理的范围,因此发展针对各种应用场景的自动视频理解算法变得尤为重要,比如:视频推荐、人类行为分析、视频监控等等。
深度学习在静态图像理解上取得了巨大成功,但是针对视频时空建模中最有效的网络架构是什么还尚不清楚,因此我们将新探索的用于视频中局部和全局时空建模的时空网络(StNet)架构与现有的CNN+RNN模型或是基于纯3D卷积的方法进行比对分析,来寻求更有效的网络架构。
现有方法分析
由于深度学习在图片识别中的卓越表现,该技术也被应用到了解决视频分类的场景当中。这其中就有两个主要的研究方向,一个是应用CNN+RNN框架结构来对视频序列建模,还有一个是单纯的利用卷积网络结构来识别视频当中的行为。但是在动作识别准确性方面,目前的行动识别方法仍然远远落后于人类表现。现有方法存在如下待改进之处。
CNN+RNN模型
对于CNN+RNN的方法,CNN前馈网络部分用来空间建模(spatial modeling),LSTM或者GRU用来时域建模(temporal modeling),由于该模型自身的循环结构,这导致了端到端的优化困难。
单独训练的CNN和RNN部分对于联合的时空特征表示学习(representation learning)不是最佳的。
纯卷积网络结构
2D卷积网络结构在抽取外观特征(appearance features)的时候,只利用了局部的空间信息而忽略了局部的时域信息;此外,对于时域动态,2D卷积网络仅融合了几个局部片段的分类得分并计算平均值,这种取平均的方法在捕捉时空信息方面的性能有待提高。
3D卷积网络结构可以同时在空间和时间上建模进而得到令人满意的识别任务结果。众所周知,浅层的神经网络与深层神经网络相比,浅层网络在大数据集中,表现出较差的表示学习能力。当进行大规模数据集中的人类行为识别任务时,一方面浅层的3D卷积网络得到的视频特征的可辨别性相对深层网络较弱,另一方面,深层的3D卷积网络会导致过大的模型以及在训练中和推理阶段中过高的计算成本。
StNet模型
局部信息和全局信息对识别视频中的行为都起着非常重要的作用。
例如,在图1(a)中,我们可以通过局部的空间信息来识别搬砖和搬石头,换而言之,在该图中,局部的空间信息(local spatial information)是我们识别行为至关重要的因素。而在图1(b)中,全局时空(global spatial-temporal)线索是用来区分”摞卡片”和”飞卡片”这两个场景行为的关键证据。

图1局部信息足以区分”搬砖”和”搬石头”;全局时空信息可以分别”摞卡片”和”飞卡牌”
StNet可以由先进的2D卷积网络改造可得,比如:ResNet、InceptionResnet等等。图2展示了如何从Resnet构建StNet。
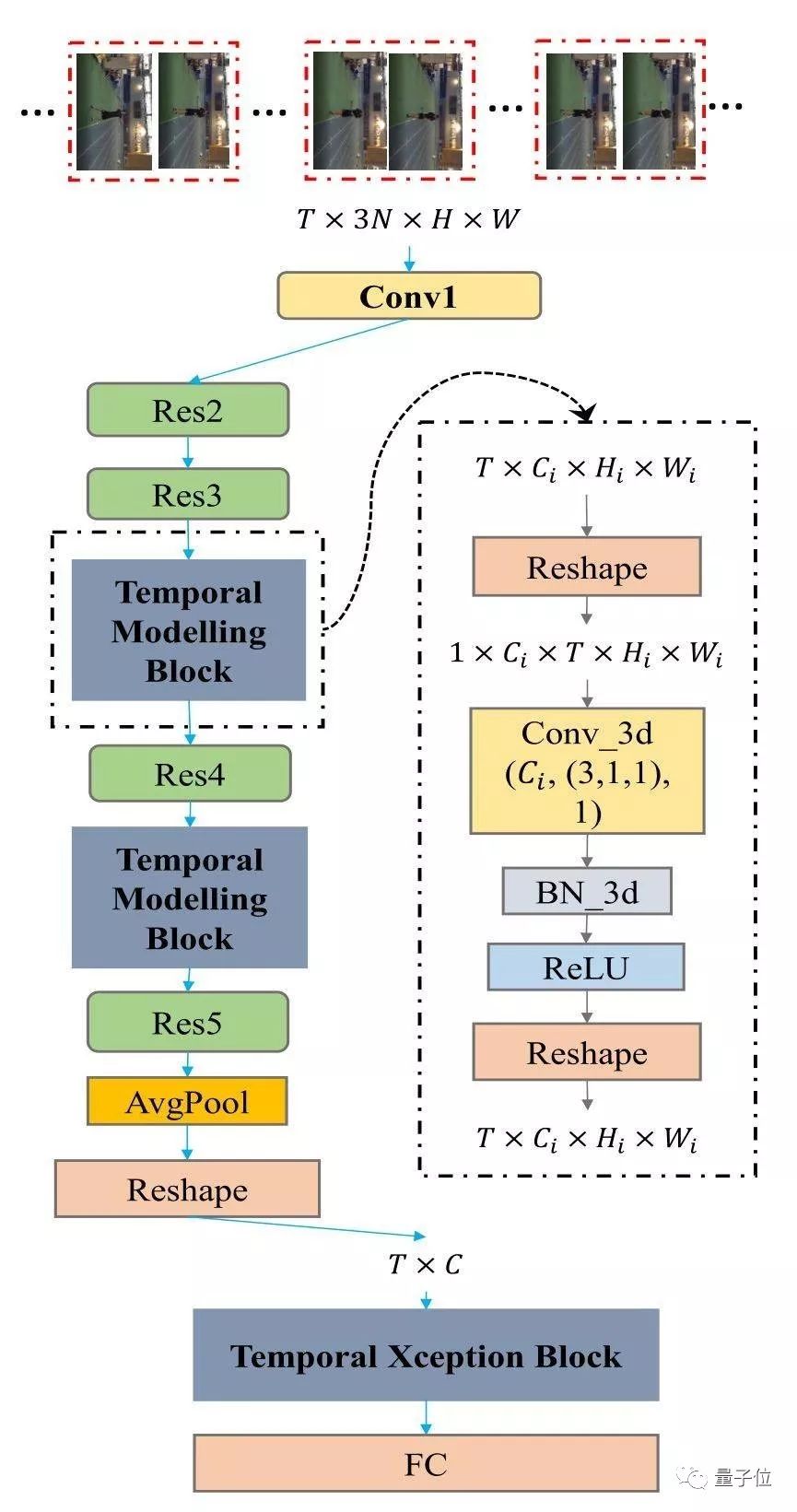
图2:基于ResNet骨架构建的StNet。
StNet的输入是T ×3N ×H ×W张量。通过2D卷积对局部时空模型进行模型。在Res3和Res4块之后插入时序卷积模块进行全局时空特征建模。最后,用时序Xception模块进一步建模时序动态信息。3D卷积的设置是(# Output Channel, (temporal kernel size, height kernel size, width kernel size), # groups) -(Ci, (3,1,1), 1)
超图像(Super-Image):
StNet的输入为均匀采样的T个局部连续N帧的视频帧。局部的连续N帧组合成一个”超图”,这使得”超图”保留原始视频各个局部的时空信息。所以网络的输入是一个尺寸为T*3N*H*W的张量。
时域建模块(Temporal Modeling Block):
采用2D卷积对T个”超图”进行局部时空关系的建模,可以避免 3D 卷积网络参数量和计算量大的问题,进而生成T个局部时空特征图。通过堆叠3D卷积/2D卷积模块,对T个局部时空特征图进行全局时空信息的建模,这对理解整个视频起到至关重要的作用。
具体而言,我们选择插入2个时域建模块在Res3和Res4块之后。时域建模块是为了捕捉视频序列内的长期时域动态,可以利用Conv_3d-BN3d-RELU架构实现。将3D卷积空间维度的kernel size设置成1以节省模型的参数量与计算量。
时域Xception模块(Temporal Xception Block):
时域Xception模块是为了在特征序列之间进行有效的时域建模,并能轻松地进行端到端优化。Xception模块的设计主要基于时序1维卷积,采用了channel-wise和temporal-wise分离的策略进一步减少计算量与模型参数量。
时域Xception块结构如下:
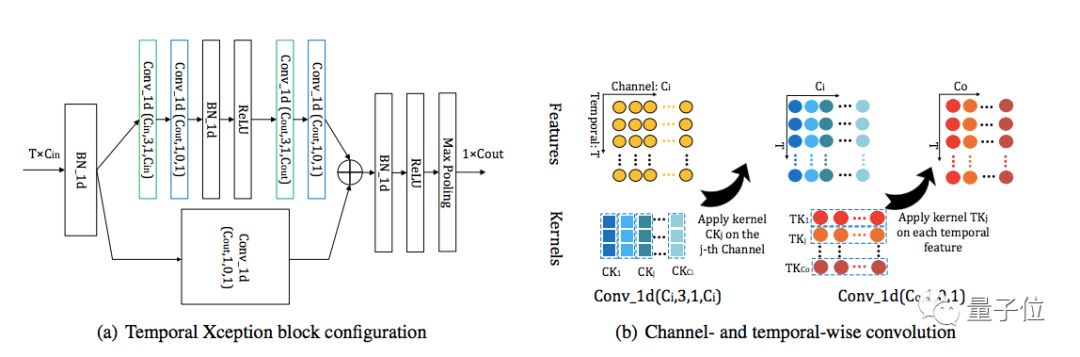
图3:时域 Xception 块(TXB)。
时域Xception 块的详细配置如(a)所示:括号中的参数表示 1D卷积的(#kernel,kernel size,padding,#groups)配置。绿色的块表示 channel-wise 的 1D 卷积,蓝色的块表示 temporal-wise 的 1D 卷积。
(b)描绘了 channel-wise 和 temporal-wise 的 1D 卷积。TXB 的输入是视频的特征序列,表示为 T×C_in 张量。Channel-wise 1D 卷积的每个卷积核仅在一个通道内沿时间维度应用。Temporal-wise 的 1D 卷积核在每个时序特征中跨所有通道进行卷积
基于PaddlePaddle 实战
环境准备:
PaddlePaddle Fluid 1.3 + cudnn5.1 。使用cudnn7.0以上版本时batchnorm计算moving mean和moving average会出现异常,此问题还在修复中。建议用户安装PaddlePaddle时指定cudnn版本。
数据准备:
Kinetics数据集是DeepMind公开的大规模视频动作识别数据集,有Kinetics400与Kinetics600两个版本。这里使用Kinetics400数据集。
ActivityNet官方提供了Kinetics的下载工具,具体参考其官方repo 即可下载Kinetics400的mp4视频集合。
将kinetics400的训练与验证集合分别下载到dataset/kinetics/data_k400/train_mp4dataset/kinetics/data_k400/val_mp4。
官方repo:https://github.com/activitynet/ActivityNet/tree/master/Crawler/Kinetics
模型训练:
数据准备完毕后,通过以下方式启动训练(方法1),同时我们也提供快速启动脚本 (方法2)
方法1
python train.py --model-name=STNET
--config=./configs/stnet.txt
--save-dir=checkpoints
--log-interval=10
--valid-interval=1方法2
bash scripts/train/train_stnet.sh
用户也可下载Paddle Github上已发布模型通过—resume指定权重存放路径进行finetune等开发。
数据预处理说明:
模型读取Kinetics-400数据集中的mp4数据,每条数据抽取seg_num段,每段抽取seg_len帧图像,对每帧图像做随机增强后,缩放至target_size。
训练策略:
采用Momentum优化算法训练,momentum=0.9
权重衰减系数为1e-4
学习率在训练的总epoch数的1/3和2/3时分别做0.1的衰减
模型评估:
通过以下方式(方法 1)进行模型评估,同样我们也提供了快速启动的脚本(方法 2):
方法1
python test.py --model-name=STNET
--config=configs/stnet.txt
--log-interval=1
--weights=$PATH_TO_WEIGHTS
方法2
bash scripts/test/test__stnet.sh
使用scripts/test/test_stnet.sh进行评估时,需要修改脚本中的—weights参数指定需要评估的权重。
若未指定—weights参数,脚本会下载已发布模型进行评估。
模型推断:
可通过如下命令进行模型推断:
python infer.py --model-name=stnet
--config=configs/stnet.txt
--log-interval=1
--weights=$PATH_TO_WEIGHTS
--filelist=$FILELIST
模型推断结果存储于STNET_infer_result中,通过pickle格式存储。
若未指定—weights参数,脚本会下载已发布模型进行推断。
模型精度:
当模型取如下参数时,在 Kinetics400数据集上的指标为:
参数取值
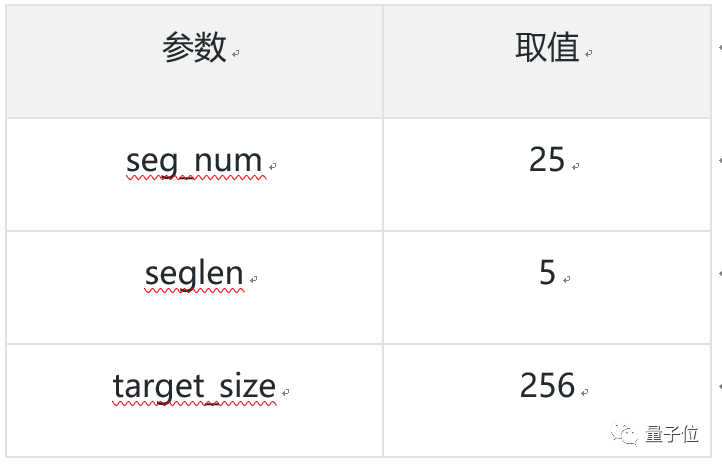
评估精度

传送门:
PaddlePaddle Github:
https://github.com/PaddlePaddle
StNet in PaddlePaddle Github:
https://github.com/PaddlePaddle/models/blob/develop/fluid/PaddleCV/video/models/stnet
Reference:Dongliang He, Zhichao Zhou, Chuang Gan, Fu Li, Xiao Liu, Yandong Li, Limin Wang, Shilei Wen,StNet: Local and Global Spatial-Temporal Modeling for Action Recognition
https://arxiv.org/abs/1811.01549
— 完 —
订阅AI内参,获取AI行业资讯

加入社群
量子位AI社群开始招募啦,量子位社群分:AI讨论群、AI+行业群、AI技术群;
欢迎对AI感兴趣的同学,在量子位公众号(QbitAI)对话界面回复关键字“微信群”,获取入群方式。(技术群与AI+行业群需经过审核,审核较严,敬请谅解)
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。

量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
喜欢就点这里吧 !
