谷歌开发全新监督学习模型区分讲话者声音,准确率达92.4%
▲点击上方 雷锋网 关注

雷锋网消息,将含有多人语音的音频流分割为与每个人相关联的同类片段的过程,是语音识别系统的重要部分。通过解决“谁在讲话”的问题,区分讲话者的能力可以应用于许多重要场景,例如理解医疗对话和视频字幕等。
这个过程对人类来说相当容易,但对于计算机而言则完全不同,它需要先进的机器学习算法来训练它们以便挑选出每个人的声音,使用监督学习方法训练这些系统非常具有挑战性。
谷歌的人工智能研究科学家Chong Wang在一篇博客文章中说,他们最近开发出了一种名为“全监督讲话者区分”的新模型,该模型试图以更有效的方式使用受监督的讲话者标签。这里的“全”意味着讲话者区分系统中的所有模块,包括统计讲话者数量,都以受监督的方式进行训练,以便它们可以从增加可用的标记数据量中受益。
与标准监督区分任务不同,强大的区分模型需要能够将新个体与不参与训练的不同语音段相关联,这极大的限制了在线和离线区分系统的质量,且在线系统通常会受到更多影响,因为它们需要实时的分拣结果。
在NIST SRE 2000 CALLHOME基准测试中,该系统的DER(Diarization Error Rate,区分错误率)低至7.6%,优于之前基于聚类的方法的8.8%,以及基于DNN嵌入方法的9.9%。此外该系统基于在线解码,特别适用于实时应用。为了加速沿此方向的更多研究,谷歌选择了开源核心算法。
聚类与交错态RNN
现代讲话者区分系统通常基于聚类算法,如k均值或谱聚类。这些聚类方法是无监督的,无法充分利用数据中可用的监督讲话者标签。而在线聚类算法通常在具有流式音频输入的实时应用中区分质量较差。
(雷锋网注1:k均值聚类是一种矢量量化方法,最初来自信号处理,是数据挖掘中聚类分析的常用方法。 k均值聚类的目的是将n个观测值划分为k个聚类,其中每个观测值属于具有最近均值的聚类,作为聚类的原型。)
(雷锋网注2:谱聚类技术利用数据相似矩阵的谱(特征值)进行降维,然后在更小的维数下聚类,提供相似性矩阵作为输入,并且包括对数据集中每对点的相对相似性的定量评估。)
谷歌的新模型和常见聚类算法的关键区别在于,所有讲话者的嵌入都是通过参数共享RNN建模的,并且使用了不同的RNN状态在时域内交错区分不同的讲话者。
为了了解其工作原理,谷歌制作了以下示例,其中有蓝、黄、粉、绿四种可能的讲话者,每个讲话者以其自己的RNN实例(在所有讲话者之间共享的公共初始状态)开始,并且在给定来自该讲话者的新嵌入的情况下保持更新RNN状态。
在示例中,蓝色讲话者不断更新其RNN状态,直到另一个讲话者黄色进入。如果蓝色稍后再说,它将恢复更新其RNN状态。(这只是下图中语音段y7的可能性之一,如果新的讲话者绿色进入,它将以新的RNN实例开始。)
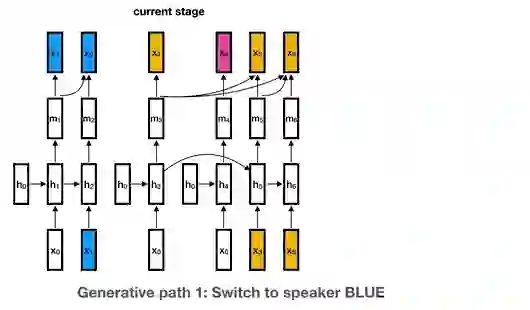
将讲话者表示为RNN状态使模型能够学习使用RNN参数在不同讲话者和话语之间共享的高级知识,这保证了更多标记数据的可用性。相比之下,常见的聚类算法几乎总是独立处理每个单独的话语,难以从大量标记数据中受益。
所有这一切的结果是,可以通过给定时间标记的讲话者标签(即知道谁在什么时候讲话),用标准的随机梯度下降算法训练模型,训练好的模型可以对没有听过的讲话者的新话语进行区分。此外,使用在线解码使其更适合对延迟敏感的应用程序。
(雷锋网注3:随机梯度下降算法也称为增量梯度下降算法,是用于优化可微分目标函数的迭代方法,是梯度下降优化的一种随机近似。被称为随机是因为样本是随机选择(或混洗)而不是作为单个组(如标准梯度下降)或按训练集中出现的顺序选择的。)
未来的工作
Constellation Research的分析师Holger Mueller表示,人类的说话速度比打字速度快,语音是一种更为自然的输入法。
“在嘈杂的环境中进行语音识别很难,特别是在多人说话时。”Holger Mueller说,“这个领域的任何进展都将进一步推动语音交互的应用,谷歌这套系统的出现,似乎正在尝试打破用户与智能设备的互动极限。”
尽管已经通过该系统取得了令人印象深刻的性能,谷歌仍在持续改进这一模型,希望可以整合上下文信息并执行离线解码,进一步降低DER,这对延迟不敏感的应用程序更有用。其次谷歌还想直接模拟声学特征而不是使用d向量,通过端到端的方式训练整个讲话者区分系统。
与此同时,Chong Wang的团队还决定将新算法开源并提供给GitHub,以便其他人参与并作出贡献。
◆ ◆ ◆
推荐阅读
价值50亿的亚马逊第2总部最终敲定 为何引发全美关注?
面对《锤子生死劫》,罗永浩愤怒了
苹果再爆严重硬件问题,高价策略使分析师看衰iPhone XR
双 11 结束各大厂纷纷晒战报:为何家家都自称第一?
1小时47分破千亿,双 11 十周年,你剁手了多少钱?

关注雷锋网(leiphone-sz)回复 2 加读者群交个朋友



