智能推荐算法在花椒直播中的应用

分享嘉宾:王洋 花椒直播 高级算法架构师
编辑整理:陈家辉
内容来源:将门线上直播189期
出品平台:将门、DataFun
注:欢迎转载,转载请留言。
导读:随着移动互联网泛娱乐化行业的发展,直播与短视频越来越深入人们的生活,人们对于直播与短视频的质量要求也越来越高。是否能够匹配用户的兴趣,满足用户的需求,已经成为决定平台增长的关键因素。今天会和大家分享下花椒直播平台在直播场景中运用推荐算法,怎么样从0到1建立推荐系统。
本次分享会围绕下面两点展开:
❶ 推荐系统介绍
❷ 花椒直播应用案例
▌推荐系统介绍
首先和大家介绍一些推荐系统的基本知识。
1. 推荐系统是什么
现代移动互联网娱乐充斥着各种各样的信息,如新闻,短视频,直播等等,经常使用户迷失在海量的内容中,而无法找到真正感兴趣的内容。平台搭建推荐系统则是帮助用户发现内容,克服信息过载的重要工具。它通过分析用户行为,对用户兴趣建模。通俗来讲就是通过用户过去的喜好来分析现在的喜好,从而预测用户的兴趣并给用户做推荐。
早期的花椒推荐系统是基于热度推荐的,即根据观看人数、送礼人数、互动人数等因素来进行加权得到相应的分数代表热度,然后根据热度进行推荐。这样做的好处是热度高的直播质量有保证。但是坏处也很明显,流量全部集中在头部主播,小主播难以得到有效曝光,这样对于平台的利益也是一种损害。对于用户来说,也难以做到“千人千面”的个性化推荐效果。
因此现代的推荐系统应运而生,一般分为以下几个阶段:
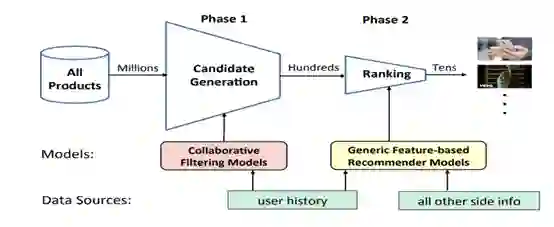
首先从百万级别的内容中,根据历史行为,运用协同过滤等算法召回千百级别的内容, 再经过feature-based精排模型排序,选取百十级别内容推荐给客户。召回阶段会用些成本低、易实现、速度快的模型 ( 如协同过滤 ) 进行初步筛选。排序阶段则用更全面的数据、更精细的特征、更复杂的模型进行精挑细选。
2. 召回算法介绍
① 基于领域的协同过滤
以电影推荐为例,我们知道用户对于历史观看过的电影的评分,将原始数据格式转化为评分矩阵,如下所示:
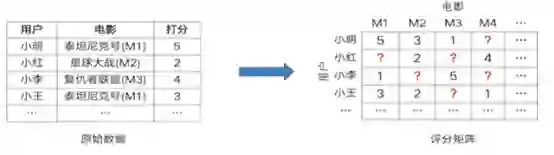
用户只看过少部分电影,我们想要知道对于未看过的电影,用户可能对其的喜爱程度 ( 打分 ) 是多高。建模的过程就是填充空白项的过程,这样就得到了所有用户对所有电影的评分 ( 喜好程度 ),然后就可据此进行个性化推荐。
这种协同过滤方法基于场景一般采用user-based 或者item-based model。花椒直播用的是item ( 主播 ) based model,即基于主播的协同过滤算法。主要基于以下原因:
1. 主播数量远小于用户数量,相似度矩阵维度小,计算少、易存储 (𝑂(𝑛2))
2. 根据用户的历史行为推荐,可以让用户比较信服 ( 可解释性强 )
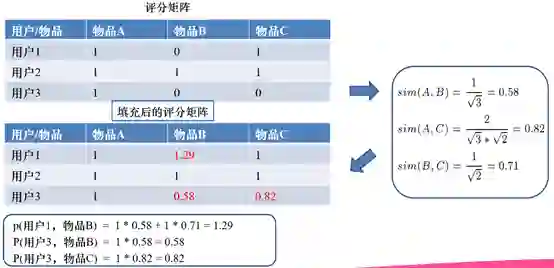
3. 新用户只要看过一个主播,就可以很快得到其他相似主播的推荐。计算方法如下所示:
但是这种方法存在一些缺点:
1. 这是一种基于统计的方法,不是优化学习的方法,没有学习过程和设立指标进行优化得到最优模型的过程
2. 没有用到全局数据,只用了局部数据计算相似度、进行推荐
3. 当用户或物品维度很大时,会占用很大的内存
基于这些原因,后面出现了基于隐向量的协同过滤方法进行推荐。
② 基于隐向量的协同过滤
隐向量的生成方式一般分为两类:
1. 基于矩阵分解生成隐向量。
2. 基于深度学习生成隐向量。
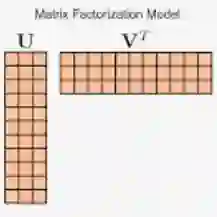
和基于邻域的方法一样,基于矩阵分解方法建模的目的也是补全缺失值。在介绍矩阵分解之前,我们先来看看推荐系统的两种反馈方式:

显式反馈一般采用评分矩阵来提取隐向量, 方法如下所示:
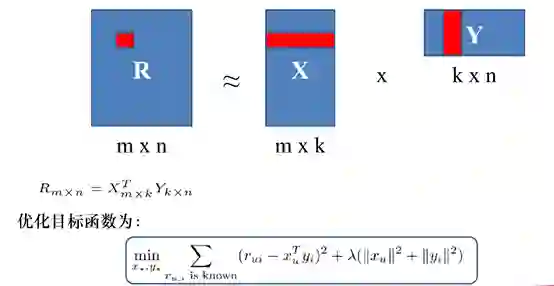
这种方法就是标准的MF,通过评分矩阵分解出代表用户的隐向量矩阵和代表物品的隐向量矩阵。但是缺点也很明显,在实际的应用场景中, 不可能用户每使用一次物品就要求用户打分。所以在实际场景中,隐式反馈使用的更多,在直播场景里,用户对于视频的喜好表现为观看时长和点击次数等等。
以观看时长作为用户对于商品的偏好为例,在观看时长大于某个程度作为喜好的标准,设定评分为1,否则为0。同时设置偏好的可信度作为损失函数的权重,理解为偏好越大,权重越大。则隐向量计算方法如下所示:
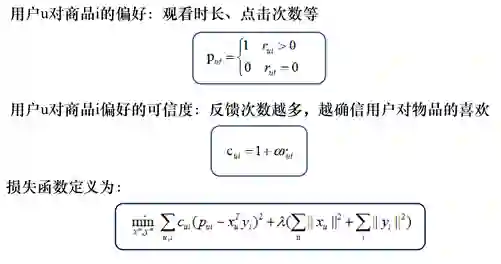
线上的部署很简单,X中每行为一个用户的隐向量,Y中每列为一个物品的隐向量。离线训练好将X,Y两个矩阵存起来,线上用时直接取对应向量做内积即可得到任一用户对任一物品的得分 ( 即喜好程度 )。
矩阵分解的思想很简单,优点也很明显:
1. 模型简单易实现。
2. 线上速度快:可以离线训练,线上只需要做点积。
3. 存储少 ( 高维评分矩阵映射为两个低维隐向量矩阵 )。同样的,传统的矩阵分解也存在着可解释性较差,未用到其他特征,综合性较差的缺点。
总结一下基于领域的协同过滤和基于矩阵分解的协同过滤的异同点:

有些示例表明,学到用户/物品的隐向量后,直接用内积描述用户-物品交互关系 ( matching function ) 有一定的局限性,即内积函数 ( inner product function ) 限制了 MF的表现力。
随着深度学习的兴起,有学者提出了新的模型:即借鉴深度学习中的方 法,使用深度神经网络 ( DNN ) 从数据中自动学习用户/物品隐向量的交互函数,在增强表现力的同时也可以引入一定的泛化能力。
以NCF为例,通过对user_id和item_id的one-hot编码,经过嵌入形成隐向量,用DNN取代内积,输出目标预测值,通过损失函数求梯度进行反向传播训练模型。如下图所示:
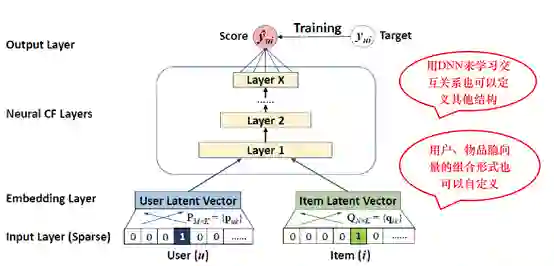
NeuMF则提出了GMF层来提取用户、物品潜在特征之间的相互作用 ( MF的特性 ),同时采用了MLP进行非线性的特征融合,具体如下所示:
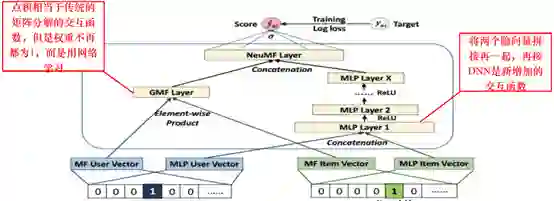
但是仅仅运用到id类特征并没有充分使用用户和物品的属性特征,因此随时技术进步,越来越多平台开始把属性特这个加入到深度学习中来提取隐向量。以下是youtube的召回模型结构:
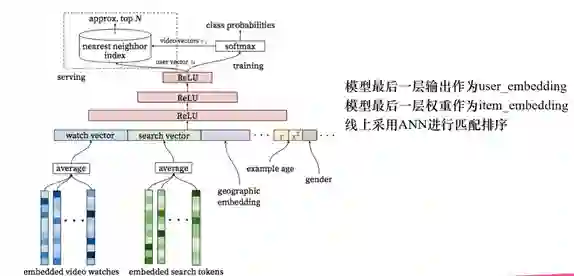
随着业界对于深度学习的不断探索,目前召回模型也越来越复杂和精妙, 如:
双塔模型 ( Sampling-Bias-Corrected Neural Modeling for Large Corpus Item Recommendations )
知识图谱模型 ( RippleNet: Propagating User Preferences on the Knowledge Graph for Recommender Systems )
图神经网络等 ( GraphSAGE: Inductive Representation Learning on Large Graphs )。
3. 精排 ( Ranking ) 算法介绍
① 特征工程
特征的选择和建造对于模型的效果起着至关重要的作用,在直播领域,考虑的特征一般包括如下几个方面:
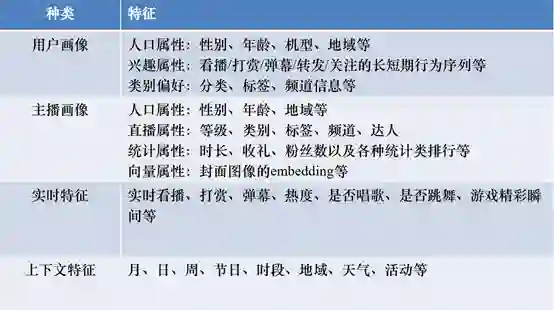
在训练数据的生成上,我们根据当天的用户与主播的交互程度形成征服样本,根据之前的历史数据组成用户画像和行为特征。在生成数据的时候,要注意不能有数据穿透,基本流程如下图所示:
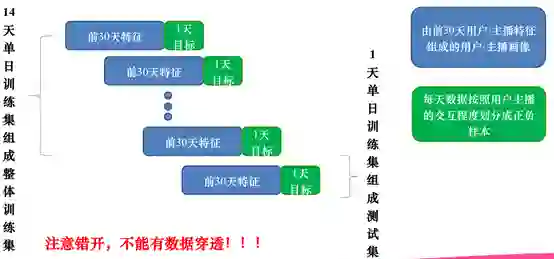
选择14日组成整体训练集,这样既可以保证数据量的要求,又可以保证用户和主播覆盖度的要求。
② 排序模型
早期的排序模型采用的是传统的机器学习模型,如LR/FM/GBDT+LR。
LR一般代指逻辑回归模型,是广义线性模型,一般用于解决二分类问题,模型如下:
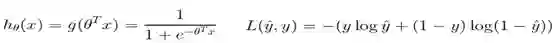
优点就是模型简单,训练速度快,消耗资源少。缺点也很明显,缺少非线性的特征交叉,泛化性较低。
为了将特征交叉考虑进去,FM模型被广泛使用,模型如下:
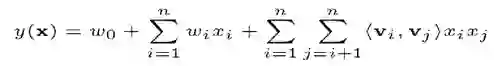
FM模型在LR模型的基础上增加了自动二阶特征交叉的部分。不同于CF类模型,只有用户、物品ID两类特征 ( 即MF ),FM可以添加任意多的特征。隐向量的引入也使得模型可以泛化到未曾出现过的特征组合中,兼顾了模型的记忆性和泛化性。但是FM只能学习二阶交叉项,遇到高阶交叉项,则会出现纬度爆炸的情况。
因此为了寻找不同特征之间的组合,人们选择了用GBDT进行特征组合,自上而下每条路径代表一种高阶特征交叉,然后叶子节点编号作为LR的输入,具体结构如下所示:
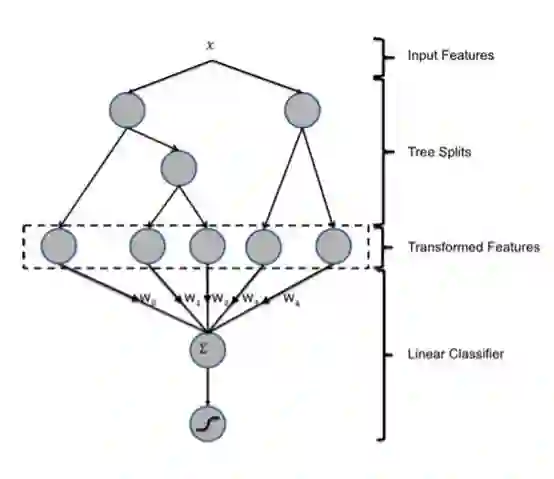
但是这种方法的缺点是可能导致过拟合高维稀疏数据,GBDT不能将数据batch输入,无法并行,因此速度慢、泛化性差。
随着深度学习的深入,人们将高阶特征交叉的工作中心转移到了DNN网络。首先最直观的改进就是通过DNN处理特征交叉,LR处理线性部分。
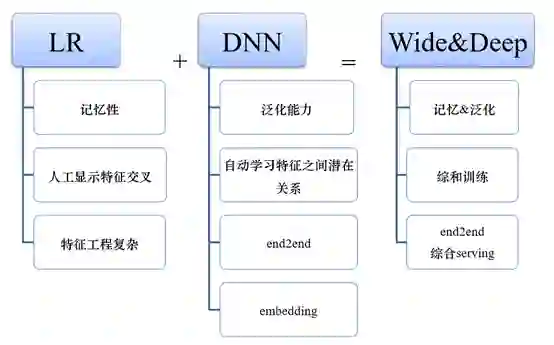
大名鼎鼎的W&D就是由此而来,其结构如下:
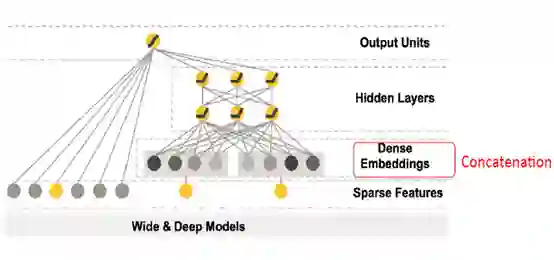
这种深浅双塔结构的提出极大的促进了后续模型的发展。如后续的DeepFM就是将FM与DNN结合起来,更加提高了交叉特征的提取能力。
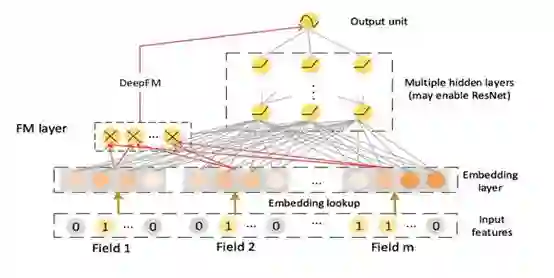
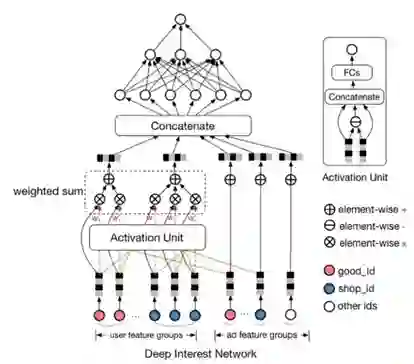
又如较新的DIN模型,引入了attention的机制,通过attention network来组合embeddings,而不是类似之前的concatenate的方式。
4. 多目标优化
推荐系统的多目标优化,是目前业界的主流之一,也是很多公司的研发现状。以我 们花椒直播为例,可以优化的目标有点击、观看、送礼、评论、关注、转发等等。
多任务模型旨在平衡不同目标的相互影响,尽量能够做到所有指标同步上涨,即使 不能,也要尽量做到在某个优化目标上涨的情况下,不拉低或者将尽量少拉低其它 指标,力求达到全局最优的效果。
传统的CVR任务,只考虑从impression到conversion的过程,即:
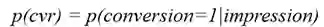
阿里的ESMM模型还考虑了点击的过程,并引入了浏览转化率 ( pCTCVR ) 的概念,即为在浏览的条件下既点击又转化的概率,即:
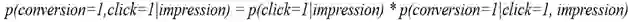
不同于CTR预估问题,CVR预估面临两个关键问题:
问题1. Sample Selection Bias ( SSB ) 转化是在点击之后才“有可能”发生的动作,传统CVR模型通常以点击数据为训练集,其中点击未转化为负例,点击并转化为正例。但是训练好的模型实际使用时,则是对整个空间的样本进行预估,而非只对点击样本进行预估。即是说,训练数据与实际要预测的数据来自不同分布,这个偏差对模型的泛化能力构成了很大挑战。
问题2. Data Sparsity ( DS ) 作为CVR训练数据的点击样本远小于CTR预估训练使用的曝光样本。
模型结构如下:
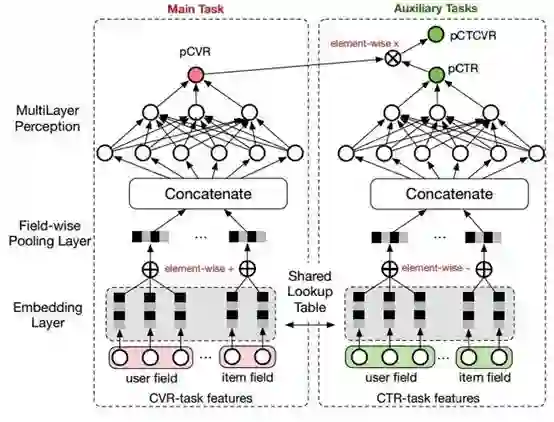
仔细观察上图,留意以下几点:
1. 共享Embedding CVR-task和CTR-task使用相同的特征和特征embedding,即两者从Concatenate之后才学习各自部分独享的参数;
2. 隐式学习pCVR 啥意思呢?这里pCVR ( 粉色节点 ) 仅是网络中的一个variable,没有显示的监督信号。
更进一步,MMoE模型为我们提供了多任务模型更加直接的思路,关于共享隐层方面,MMoE和一般多任务学习模型的区别:
一般多任务学习模型:接近输入层的隐层作为一个整体被共享
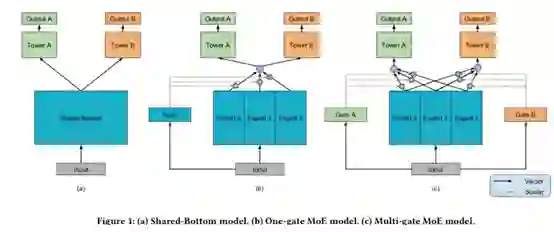
MMoE:将共享的底层表示层分为多个expert,同时设置了gate,使得不同的任务可以多样化的使用共享层。如图:
a. 是最原始的多任务学习模型,也就是base
b. 是加入单门 ( one gate ) 的MoE layer的多任务学习模型
c. 是文章提出的模型。可以看出,c本质上是将base的shared bottom换成了MoE layer,并对每个任务都加gate
▌智能推荐遇上花椒直播
直播中的推荐和商品推荐等场景有所不同,是“活的”而不是“死的”,因为直播是长时间连续性的,并 且内容是实时在变的,比如用户喜欢看跳舞直播,那么当主播不跳的时候用户可能也不想看了。因此 我们需要把直播最核心、最精彩的部分挖掘出来推荐给用户。
这就需要对多模态内容进行理解、融合,包括但不限于:
文本:如直播间标题、弹幕等
图片:如主播头像、封面等
视频:如可以识别主播是否在跳舞、游戏、挂机等
音频:如可以识别主播是否在唱歌,在唱什么类型的歌等
除了上面所说需要对直播的多模态内容进行理解,一些实时的数据也是非常重要的,它们一定程度 上可以反映当前直播的火热程度和受欢迎程度,放到模型中作为特征可以加强推荐系统的准确性和实时性。包括但不限于:实时看播人数、打赏人数/金额、弹幕数、点赞数、分享数、新增粉丝 数、是否正在唱歌/跳舞/连麦PK、是否正在挂机、游戏精彩瞬间 ( 如吃鸡剩余人数、王者荣耀KDA ) 等。
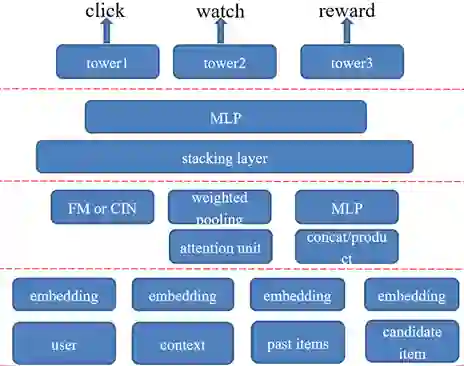
花椒直播模型的结构十分明确,原始数据包括用户特征,上下文特征,过去历史特征,当前需要预测的物品特征等。对于特征进行嵌入操作,在特征交互层可以使用上文提到的很多结构,如W&D,FM,attention。随后加入DNN结构进行特征融合,最后输出多目标预测结果。等结构如下:
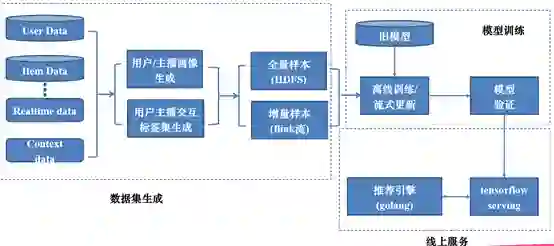
模型训练和更新的逻辑如下,将模型数据整理好,全量样本存入HDFS中,以周或者天为单位进行模型更新,增量样本flink流处理,进行离线训练和更新,以满足实时性的要求。模型验证通过线下指标对模型进行监控,训练好之后采用tensorflow serving这种框架提供服务。推荐引擎使用golang来处理用户请求,以及将请求转化为特征传入tensorflow serving中。
▌总结
本次分享总结了花椒直播沿着业内的发展路线从0到1搭建个性化推荐系统的过程,先后尝试了许多模 型,每个模型除了其典型的结构外,还有许多非常珍贵的细节,比如公式推导,参数的选择,工程上的trick等等,这些大家可以查阅相关模型论文。
要注意的是,没有“最好的模型”,只有“最适合的模型”,并不是说模型越fancy越复杂,线上效果就会越好。比如阿里提出了DIN模型,是因为工程师们首先发现了数据中“多峰分布”、“部分激活”的现象,而在直播场景中这个特点就不是很明显,因此上线了DIN模型后的提升也不是很大。
但直播场景也有其自身的特点,如多模态、实时性和热点效应等。只有深入理解了场景,并基于用户行为和数据提取出能表现这个场景的特征,再对应地开发适用于这个场景的模型,才能取得最佳的效果。
本次分享就到这里,谢谢大家。
如果您喜欢本文,欢迎点击右上角,把文章分享到朋友圈~~
欢迎加入DataFunTalk推荐算法交流群,跟同行零距离交流。如想进群,请加逃课儿同学的微信 ( 微信号:DataFunTalker ),回复:推荐算法,逃课儿会自动拉你进群。
——END——